
 Périphériques technologiques
IA
« L'apprentissage par imitation » n'est-il qu'un cliché ? Explication affinée + 13 milliards de paramètres Orca : la capacité de raisonnement est égale à ChatGPT
Périphériques technologiques
IA
« L'apprentissage par imitation » n'est-il qu'un cliché ? Explication affinée + 13 milliards de paramètres Orca : la capacité de raisonnement est égale à ChatGPT
« L'apprentissage par imitation » n'est-il qu'un cliché ? Explication affinée + 13 milliards de paramètres Orca : la capacité de raisonnement est égale à ChatGPT

Depuis l'ouverture de l'API ChatGPT, un grand nombre d'études ont choisi d'utiliser la sortie de grands modèles de base (LFM) tels que ChatGPT et GPT-4 comme données de formation, puis d'améliorer les capacités des petits modèles grâce à l'apprentissage par imitation. .
Cependant, en raison de problèmes tels que des signaux d'imitation superficiels, des données d'entraînement insuffisantes et l'absence de normes d'évaluation strictes, les performances réelles des petits modèles ont été surestimées.
Du point de vue des effets, le petit modèle est plus enclin à imiter le style de sortie de LFM plutôt que le processus d'inférence.

Lien papier : https://arxiv.org/pdf/2306.02707.pdf
Pour relever ces défis, Microsoft a récemment publié un article de 51 pages proposant un modèle 130 The Orca avec des centaines des millions de paramètres peuvent apprendre à imiter le processus de raisonnement des LFM.
Les chercheurs ont conçu des signaux de formation riches pour les grands modèles afin qu'Orca puisse apprendre des traces d'interprétation, des processus de réflexion étape par étape, des instructions complexes, etc. à partir de GPT-4, et soit assisté et guidé par des enseignants ChatGPT et par échantillonnage ; et la sélection pour extraire des données d'imitation diverses et à grande échelle, ce qui peut encore améliorer l'effet d'apprentissage progressif.
En évaluation expérimentale, Orca a surpassé les autres modèles de réglage fin des instructions SOTA, atteignant le double des performances de Vicuna-13B dans des tests d'inférence complexes à tir nul tels que BigBench Hard (BBH), et a également atteint des performances sur AGIEval 42 % de performance amélioration.
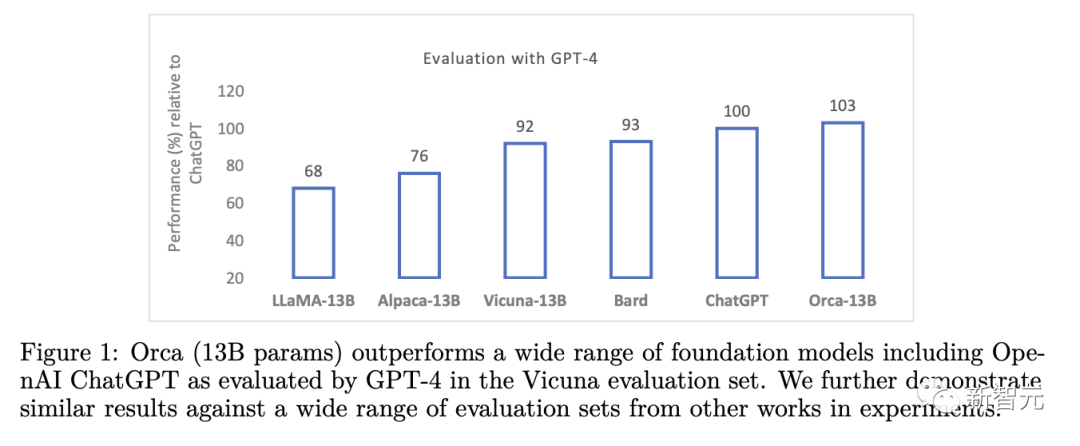
De plus, Orca a obtenu des performances comparables à ChatGPT sur le benchmark BBH, avec seulement un écart de performance de 4 % aux examens professionnels et académiques tels que SAT, LSAT, GRE et GMAT, le tout sans réfléchir. Mesuré sous le réglage à échantillon zéro de la chaîne.
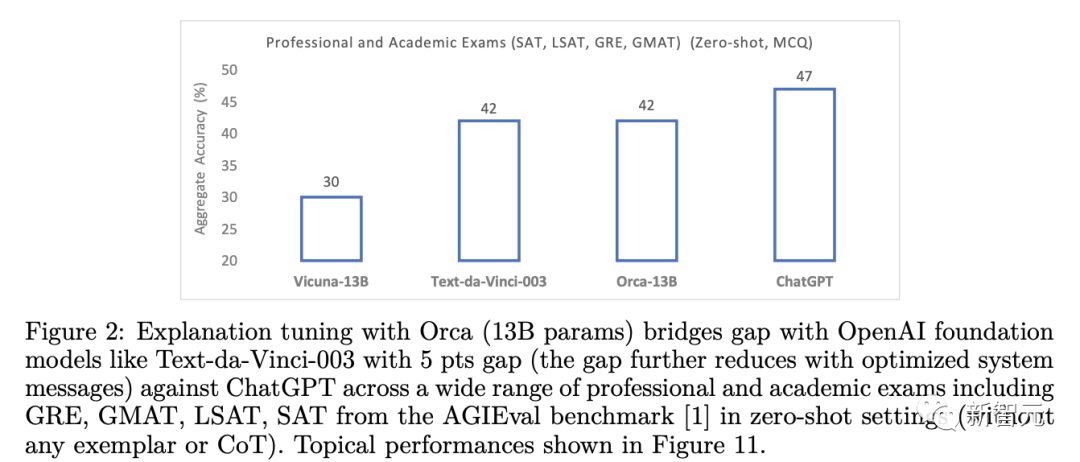
Les résultats suggèrent que laisser les modèles apprendre à partir d'explications étape par étape, qu'elles soient générées par des humains ou par des modèles d'IA plus avancés, est une direction de recherche prometteuse pour améliorer les capacités et les compétences des modèles.
Explication Tuning
Construction de l'ensemble de données
Dans les données d'entraînement, chaque instance comprend trois parties, à savoir le message système, la requête utilisateur et la réponse LFM.
Message système (message système) est placé au début de l'invite et fournit un contexte de base, des conseils et d'autres détails connexes à LFM.
Les messages système peuvent être utilisés pour modifier la longueur des réponses, décrire la personnalité de l'assistant IA, établir un comportement LFM acceptable et inacceptable et déterminer la structure de réponse du modèle IA.
Les chercheurs ont créé à la main 16 éléments d'informations système pour concevoir différents types de réponses LFM, qui peuvent générer du contenu créatif et résoudre des problèmes de requête d'informations, et, plus important encore, peuvent générer des réponses avec des explications et un raisonnement étape par étape basé sur sur les invites.

La requête utilisateur définit la tâche réelle que vous souhaitez que LFM effectue.
Afin d'obtenir un grand nombre de requêtes d'utilisateurs diverses, les chercheurs ont utilisé la collection FLAN-v2 pour extraire 5 millions de requêtes d'utilisateurs (FLAN-5M) et collecter les réponses ChatGPT, puis extraites des 5 millions d'instructions Extrait 1 ; millions d'instructions (FLAN-1M) et collecter les réponses de GPT-4.
La collection FLAN-v2 se compose de cinq sous-collections, à savoir CoT, NiV2, T0, Flan 2021 et Dialogue, où chaque sous-ensemble contient plusieurs tâches, et chaque tâche est une collection de requêtes.
Chaque sous-collection est liée à plusieurs ensembles de données académiques, et chaque ensemble de données comporte une ou plusieurs tâches, se concentrant principalement sur les requêtes zéro et peu nombreuses.
Dans ce travail, les chercheurs ont uniquement échantillonné les requêtes zéro-shot sur lesquelles Orca a été formé, et n'ont pas échantillonné le sous-ensemble Dialogue, car ces requêtes manquent souvent de contexte pour obtenir des réponses utiles de ChatGPT.
Laissez ChatGPT agir en tant qu'assistant pédagogique
Formez d'abord Orca sur les données FLAN-5M (amélioration ChatGPT), puis effectuez la deuxième étape de la formation sur FLAN-1M (amélioration GPT-4) .
Il y a deux raisons principales pour utiliser ChatGPT comme assistant enseignant intermédiaire :
1 Écart de capacité
Bien que le montant du paramètre GPT-4 n'ait pas été divulgué, les 13 milliards. Le paramètre Orca est définitivement Il est plusieurs fois plus petit que GPT-4, et l'écart de capacités entre ChatGPT et Orca est plus petit, ce qui le rend plus approprié en tant qu'enseignant intermédiaire, et il a été prouvé que cette approche améliore les performances d'apprentissage par imitation des modèles d'étudiants plus petits. dans la distillation des connaissances.
Cette approche peut également être considérée comme une forme d'apprentissage progressif ou d'apprentissage par cours, où les étudiants apprennent d'abord à partir d'exemples plus faciles, puis passent à des exemples plus difficiles, en supposant que des réponses plus longues seront meilleures que des réponses plus courtes, plus difficiles à imiter, Les compétences de raisonnement et d’explication étape par étape peuvent être améliorées à partir de modèles d’enseignants plus vastes.
2. Coût et temps
Il existe certaines limitations lors de la collecte de données à grande échelle à partir de l'API Azure OpenAI, notamment une limite de débit de requêtes par minute pour éviter un trafic excessif dû au service ; problèmes de latence. Le nombre de jetons disponibles par minute est limité ; la durée de l'invite et le coût monétaire pour l'achèvement du jeton.

En comparaison, l'API ChatGPT est plus rapide et moins chère que le terminal GPT-4, donc 5 fois plus de données sont collectées à partir de ChatGPT que GPT-4.
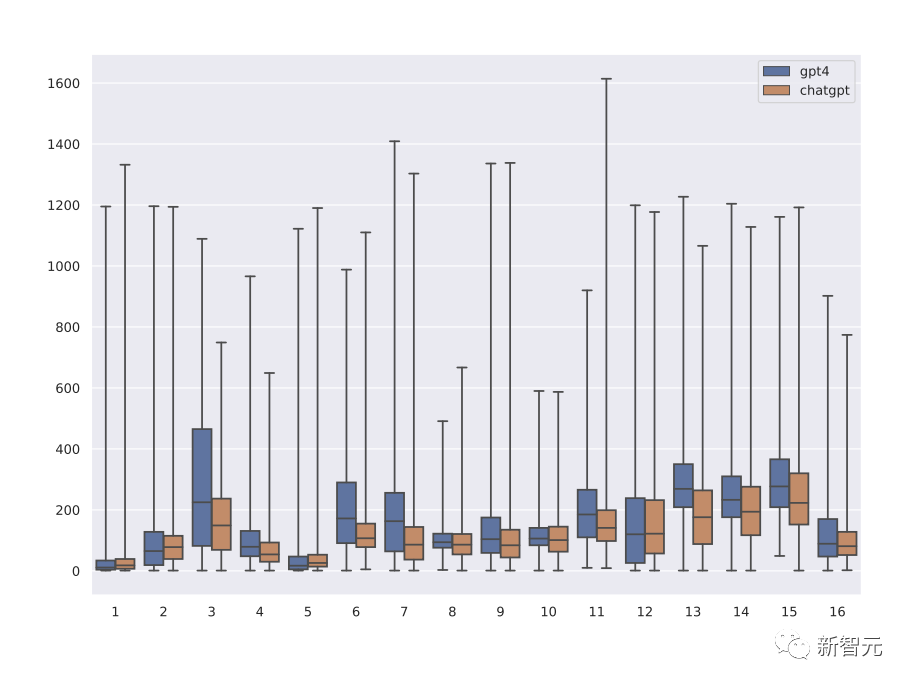
On peut observer à partir de la répartition des longueurs de réponse de ChatGPT et GPT-4 correspondant à différents messages système que les réponses de GPT-4 sont en moyenne 1,5 fois plus longues que ChatGPT, permettant à Orca d'apprendre progressivement de la complexité des explications des enseignants étudient et démontrent l'impact de l'assistance des enseignants à travers des expériences d'ablation.
Formation
Au cours de l'étape de segmentation des mots, les chercheurs ont utilisé le segmenteur de mots Byte Pair Encoding (BPE) de LLaMA pour traiter les échantillons d'entrée, dans lesquels les nombres à plusieurs chiffres seront divisés en plusieurs chiffres à un seul chiffre. . et revenons aux octets pour décomposer les caractères UTF-8 inconnus.
Afin de gérer des séquences de longueur variable, un mot de remplissage [[PAD]] est introduit dans le vocabulaire du tokenizer LLaMA. Le vocabulaire final contient 32001 jetons
Afin d'optimiser le processus de formation et de manière efficace. Utiliser Avec les ressources informatiques disponibles, les chercheurs ont utilisé la technologie de compression pour concaténer plusieurs instances d'entrée en une séquence avant d'entraîner le modèle.
Pendant le processus d'emballage, la longueur totale de la séquence concaténée ne dépasse pas max_len=2048 jetons. Les échantillons d'entrée seront mélangés de manière aléatoire et divisés en plusieurs groupes. La longueur de chaque groupe de séquences concaténées est au maximum de max_len.
Considérez Pour améliorer la répartition de la longueur des instructions dans les données d'entraînement, le coefficient de compactage de chaque séquence est de 2,7
Afin d'entraîner Orca, les chercheurs ont choisi de calculer uniquement la perte de jetons générée par le modèle enseignant, ce qui signifie que la génération d'apprentissage est basée sur les informations du système et les instructions de tâche. Les réponses conditionnelles garantissent que le modèle se concentre sur l'apprentissage à partir des jetons les plus pertinents et informatifs, améliorant ainsi l'efficience et l'efficacité globales du processus de formation.
Enfin, Orca a été formé sur 20 GPU NVIDIA A100 avec 80 Go de mémoire. Il s'est d'abord entraîné sur FLAN-5M (ChatGPT amélioré) pendant 4 époques, ce qui a duré 160 heures, puis sur FLAN-1M (GPT-4 amélioré). Continuer la formation ; pendant 4 époques
En raison des restrictions de trafic, des problèmes de charge des terminaux et de longueur de réponse, il a fallu 2 semaines et 3 semaines pour collecter les données de plusieurs terminaux de temps GPT-3.5-turbo (ChatGPT) et GPT-4 respectivement.
Partie expérimentale
Les chercheurs ont principalement vérifié la capacité de raisonnement d’Orca.
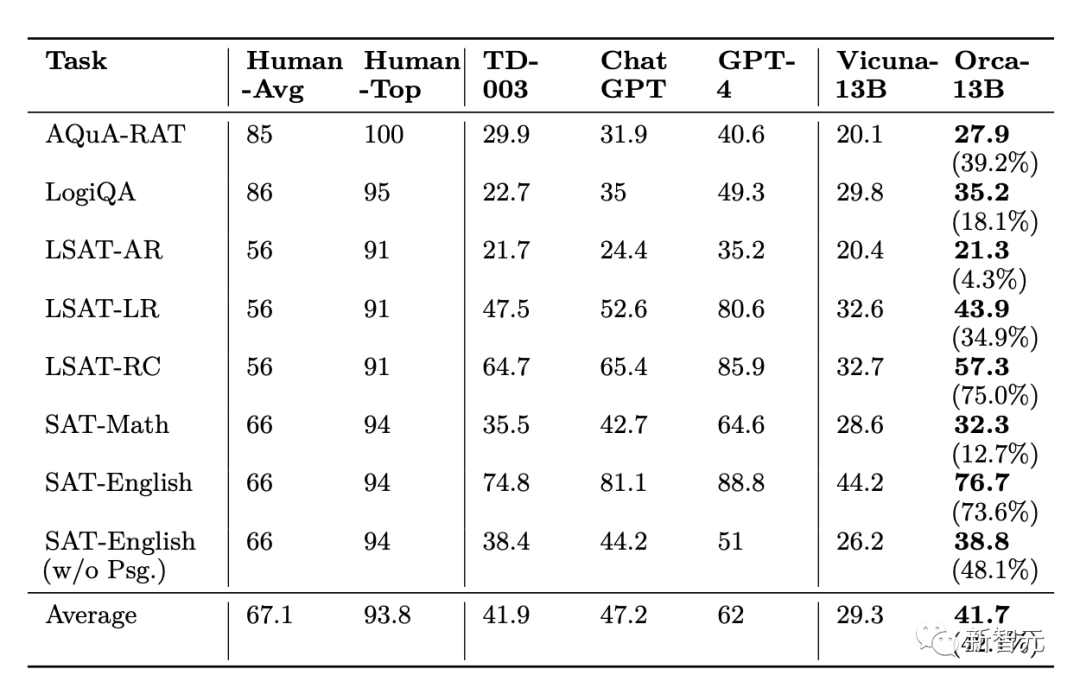
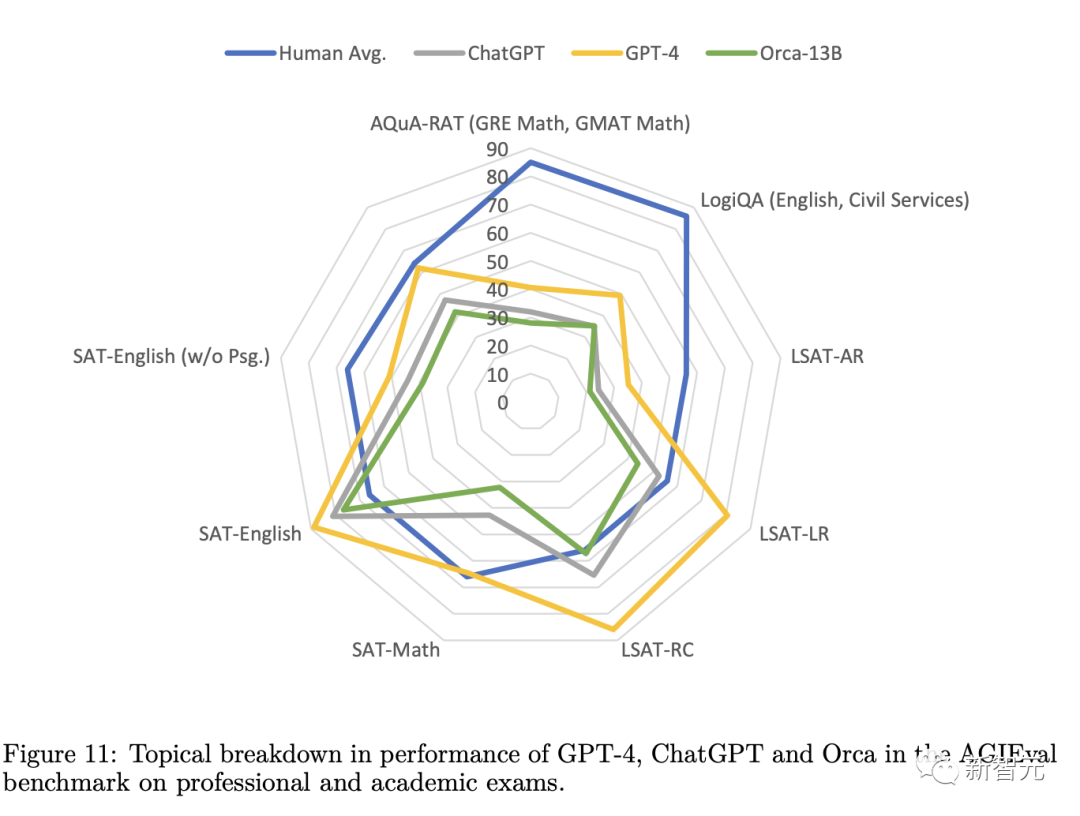
Comme on peut le voir dans l'expérience AGIEval, les performances d'Orca sont équivalentes à Text-da-Vinci-003 et atteignent 88% des performances de ChatGPT, mais il est nettement derrière GPT-4
Pour les tâches d'analyse et de raisonnement, Vicuna a obtenu des résultats nettement moins bons, ne conservant que 62 % de la qualité de ChatGPT, ce qui indique que ce modèle de langage open source a de faibles capacités de raisonnement.
Bien qu'Orca soit aussi performant avec Text-da-Vinci-003, il est toujours 5 points de moins que ChatGPT, Orca est nettement meilleur que ChatGPT sur les tâches liées aux mathématiques (en SAT, GRE, GMAT).
Par rapport à Vicuna, Orca affiche des performances plus fortes, surpassant Vicuna dans toutes les catégories, avec une amélioration relative moyenne de 42%.
GPT-4 surpasse de loin tous les autres modèles, mais il reste encore beaucoup de place à l'amélioration dans cette référence, tous les modèles ayant actuellement des performances nettement inférieures aux scores humains.
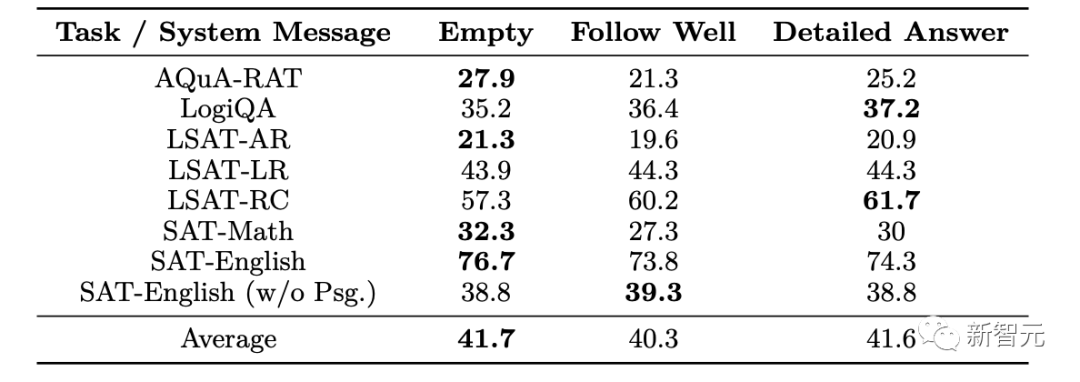
Les performances d'Orca varient considérablement en fonction du type de message système, et les messages système vides ont tendance à bien fonctionner pour les modèles entraînés.
Orca surpasse ChatGPT (exemple Orca-beats-ChatGPT) dans 325 échantillons de tâches différentes, dont la plupart proviennent de LogiQA (29%), tandis que les autres tâches LSAT et SAT-anglais sont réparties également à 10 %
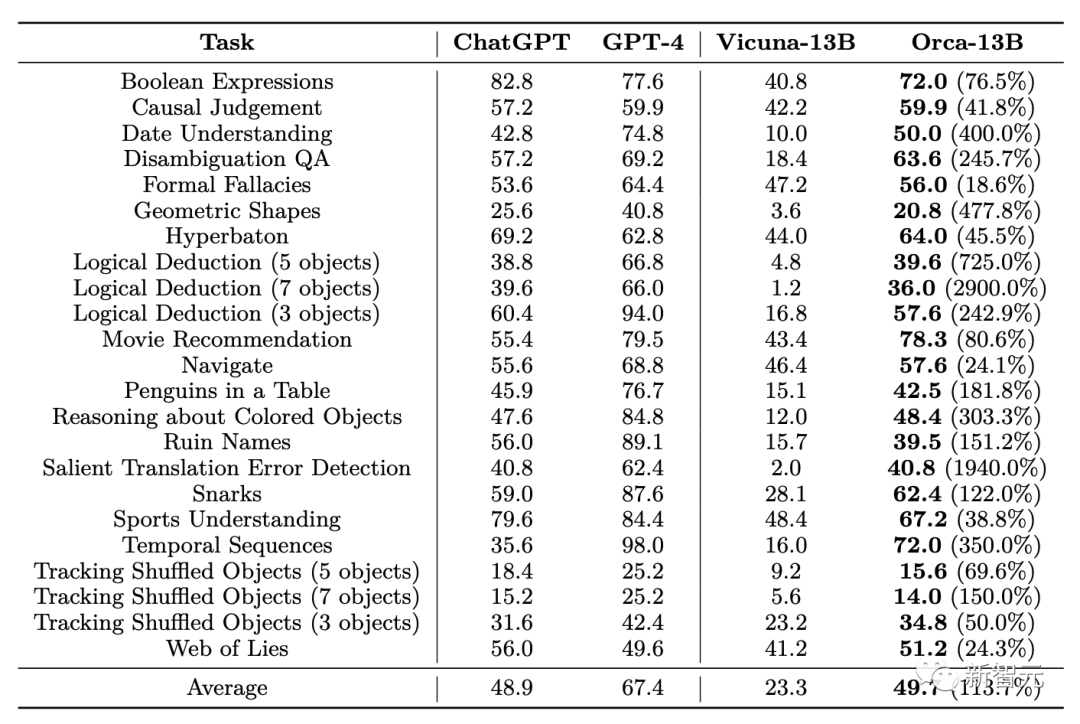
Les résultats de l'évaluation d'inférence sur l'ensemble de données Big-Bench Hard Results montrent que les performances globales d'Orca dans toutes les tâches sont légèrement meilleures que celles de ChatGPT, mais nettement derrière GPT-4 %
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ajouter une nouvelle colonne dans SQL
Apr 09, 2025 pm 02:09 PM
Comment ajouter une nouvelle colonne dans SQL
Apr 09, 2025 pm 02:09 PM
Ajoutez de nouvelles colonnes à une table existante dans SQL en utilisant l'instruction ALTER TABLE. Les étapes spécifiques comprennent: la détermination des informations du nom de la table et de la colonne, rédaction des instructions de la table ALTER et exécution des instructions. Par exemple, ajoutez une colonne de messagerie à la table des clients (VARCHAR (50)): Alter Table Clients Ajouter un e-mail VARCHAR (50);
 Quelle est la syntaxe pour ajouter des colonnes dans SQL
Apr 09, 2025 pm 02:51 PM
Quelle est la syntaxe pour ajouter des colonnes dans SQL
Apr 09, 2025 pm 02:51 PM
La syntaxe pour ajouter des colonnes dans SQL est alter table table_name Ajouter Column_name data_type [pas null] [default default_value]; Lorsque Table_Name est le nom de la table, Column_name est le nouveau nom de colonne, DATA_TYPE est le type de données, et non Null Spécifie si les valeurs NULL sont autorisées, et default default_value spécifie la valeur par défaut.
 Comment définir des valeurs par défaut lors de l'ajout de colonnes dans SQL
Apr 09, 2025 pm 02:45 PM
Comment définir des valeurs par défaut lors de l'ajout de colonnes dans SQL
Apr 09, 2025 pm 02:45 PM
Définissez la valeur par défaut des colonnes nouvellement ajoutées, utilisez l'instruction ALTER TABLE: Spécifiez des colonnes Ajouter et définissez la valeur par défaut: alter table table_name Ajouter Column_name data_type default_value; Utilisez la clause CONSTRAINT pour spécifier la valeur par défaut: ALTER TABLE TABLE_NAME ADD COLUMN COLUMN_NAME DATA_TYPE CONSTRAINT DEFAULT_CONSTRAINT DEFAULT_VALUE;
 Tableau Clear SQL: Conseils d'optimisation des performances
Apr 09, 2025 pm 02:54 PM
Tableau Clear SQL: Conseils d'optimisation des performances
Apr 09, 2025 pm 02:54 PM
Conseils pour améliorer les performances de compensation de la table SQL: utilisez une table tronquée au lieu de supprimer, libre d'espace et réinitialiser la colonne d'identité. Désactivez les contraintes de clés étrangères pour éviter la suppression en cascade. Utilisez les opérations d'encapsulation des transactions pour assurer la cohérence des données. Supprimer les mégadonnées et limiter le nombre de lignes via Limit. Reconstruisez l'indice après la compensation pour améliorer l'efficacité de la requête.
 Utilisez la déclaration de suppression pour effacer les tables SQL
Apr 09, 2025 pm 03:00 PM
Utilisez la déclaration de suppression pour effacer les tables SQL
Apr 09, 2025 pm 03:00 PM
Oui, l'instruction Delete peut être utilisée pour effacer une table SQL, les étapes sont les suivantes: Utilisez l'instruction Delete: Delete de Table_Name; Remplacez Table_Name par le nom de la table à effacer.
 Comment ajouter une colonne à une table SQL
Apr 09, 2025 pm 02:06 PM
Comment ajouter une colonne à une table SQL
Apr 09, 2025 pm 02:06 PM
L'ajout d'une colonne dans une table SQL nécessite les étapes suivantes: Ouvrez l'environnement SQL et sélectionnez la base de données. Sélectionnez le tableau que vous souhaitez modifier et utiliser la clause "Ajouter la colonne" pour ajouter une colonne qui inclut le nom de la colonne, le type de données et l'opportunité d'autoriser les valeurs nulles. Exécutez l'instruction "ALTER TABLE" pour terminer l'ajout.
 Comment gérer la fragmentation de la mémoire redis?
Apr 10, 2025 pm 02:24 PM
Comment gérer la fragmentation de la mémoire redis?
Apr 10, 2025 pm 02:24 PM
La fragmentation de la mémoire redis fait référence à l'existence de petites zones libres dans la mémoire allouée qui ne peut pas être réaffectée. Les stratégies d'adaptation comprennent: Redémarrer Redis: effacer complètement la mémoire, mais le service d'interruption. Optimiser les structures de données: utilisez une structure plus adaptée à Redis pour réduire le nombre d'allocations et de versions de mémoire. Ajustez les paramètres de configuration: utilisez la stratégie pour éliminer les paires de valeurs clés les moins récemment utilisées. Utilisez le mécanisme de persistance: sauvegardez régulièrement les données et redémarrez Redis pour nettoyer les fragments. Surveillez l'utilisation de la mémoire: découvrez les problèmes en temps opportun et prenez des mesures.
 phpmyadmin crée un tableau de données
Apr 10, 2025 pm 11:00 PM
phpmyadmin crée un tableau de données
Apr 10, 2025 pm 11:00 PM
Pour créer un tableau de données à l'aide de PhpMyAdmin, les étapes suivantes sont essentielles: connectez-vous à la base de données et cliquez sur le nouvel onglet. Nommez le tableau et sélectionnez le moteur de stockage (InnODB recommandé). Ajouter les détails de la colonne en cliquant sur le bouton Ajouter une colonne, y compris le nom de la colonne, le type de données, s'il faut autoriser les valeurs nuls et d'autres propriétés. Sélectionnez une ou plusieurs colonnes comme clés principales. Cliquez sur le bouton Enregistrer pour créer des tables et des colonnes.
