

Mardi, heure locale, MLCommons, une alliance industrielle ouverte dans le domaine de l'apprentissage automatique et de l'intelligence artificielle, a divulgué les dernières données de deux benchmarks MLPerf. Parmi eux, le chipset NVIDIA H100 a établi de nouveaux records dans toutes les catégories du test. des performances de puissance de calcul de l'intelligence artificielle, et est également la seule plate-forme matérielle capable d'exécuter tous les tests.
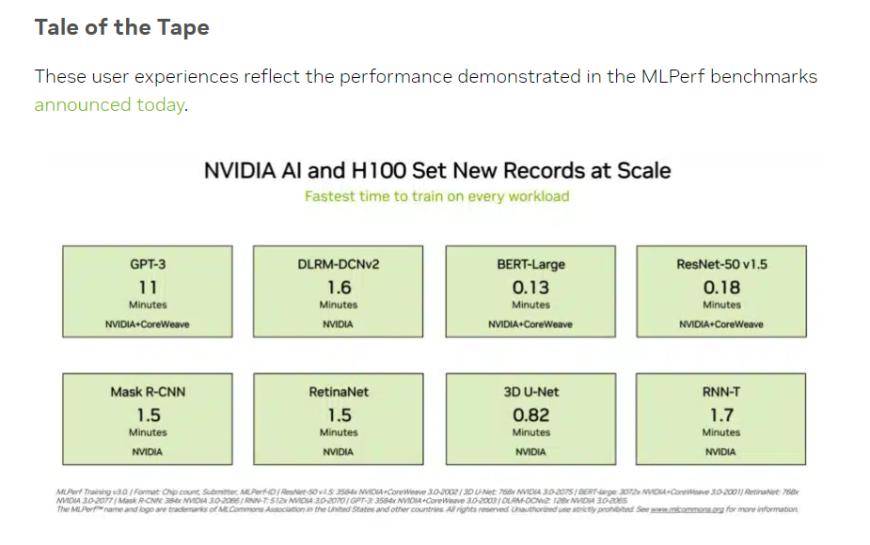
(Source : NVIDIA, MLCommons)
MLPerf est une alliance de leadership en intelligence artificielle composée d'universités, de laboratoires et d'industries. Il s'agit actuellement d'une référence internationalement reconnue et faisant autorité en matière d'évaluation des performances de l'IA. Training v3.0 contient 8 charges différentes, dont la vision (classification d'images, segmentation d'images biomédicales, détection d'objets pour deux charges), le langage (reconnaissance vocale, grand modèle de langage, traitement du langage naturel) et le système de recommandation. En d’autres termes, différents fournisseurs d’équipement mettent des délais différents pour réaliser la tâche de référence.
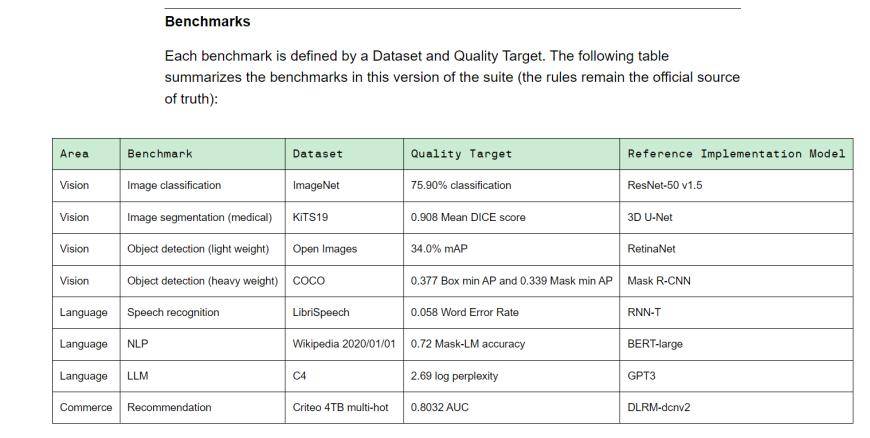
(benchmark de formation Training v3.0, source : MLCommons)
Dans le test de formation du « grand modèle de langage » qui préoccupe davantage les investisseurs, les données soumises par NVIDIA et la plate-forme de cloud computing GPU CoreWeave ont établi une norme industrielle cruelle pour ce test. Grâce aux efforts concertés de 896 processeurs Intel Xeon 8462Y+ et de 3 584 puces NVIDIA H100, il n'a fallu que 10,94 minutes pour terminer la grande tâche de formation du modèle de langage basé sur GPT-3.
Hormis Nvidia, seul le portefeuille de produits d'Intel a reçu des données d'évaluation sur ce projet. Dans un système construit avec 96 processeurs Xeon 8380 et 96 puces Habana Gaudi2 AI, le temps nécessaire pour effectuer le même test était de 311,94 minutes. Un test de comparaison horizontale utilisant une plate-forme équipée de 768 puces H100 ne prend que 45,6 minutes.
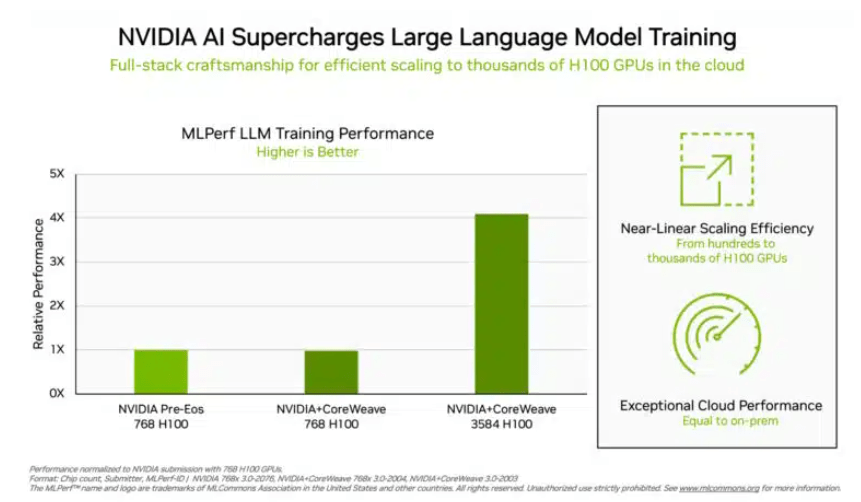
(Plus il y a de puces, meilleures sont les données, source : NVIDIA)
Concernant ce résultat, Intel a également déclaré qu'il y avait encore place à l'amélioration. Théoriquement, tant que davantage de jetons sont empilés, les résultats des calculs seront naturellement plus rapides. Jordan Plawner, directeur principal des produits d'IA d'Intel, a déclaré aux médias que les résultats informatiques de Habana seraient améliorés de 1,5 à 2 fois. Plawner a refusé de divulguer le prix spécifique de Habana Gaudi2, affirmant seulement que l'industrie avait besoin d'un deuxième fabricant pour fournir des puces de formation à l'IA, et les données MLPerf montrent qu'Intel a la capacité de répondre à cette demande.
Dans la formation du modèle BERT-Large, plus familière aux investisseurs chinois, NVIDIA et CoreWeave ont poussé les données à un niveau extrême de 0,13 minute. Dans le cas de 64 cartes, les données de test ont également atteint 0,89 minute. L'infrastructure actuelle des grands modèles traditionnels est la structure Transformer dans le modèle BERT.
Source : Financial Associated Press
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



