
 Périphériques technologiques
IA
Comment utiliser Transformer BEV pour surmonter les situations extrêmes de conduite autonome ?
Périphériques technologiques
IA
Comment utiliser Transformer BEV pour surmonter les situations extrêmes de conduite autonome ?
Comment utiliser Transformer BEV pour surmonter les situations extrêmes de conduite autonome ?

Les systèmes de conduite autonome doivent faire face à divers scénarios complexes dans des applications pratiques, en particulier les Corner Cases (situations extrêmes) qui imposent des exigences plus élevées en matière de perception et de capacités de prise de décision de la conduite autonome. Corner Case fait référence à des situations extrêmes ou rares qui peuvent survenir lors de la conduite réelle, telles que des accidents de la route, des conditions météorologiques extrêmes ou des conditions routières complexes. La technologie BEV améliore les capacités de perception des systèmes de conduite autonome en offrant une perspective globale, qui devrait fournir un meilleur soutien dans la gestion de ces situations extrêmes. Cet article explorera comment la technologie BEV (Bird's Eye View) peut aider le système de conduite autonome à faire face à Corner Case et à améliorer la fiabilité et la sécurité du système.
 Picture
Picture
Transformer en tant qu'apprentissage profond basé sur un modèle de mécanisme d'auto-attention, qui a été utilisé pour la première fois dans les tâches de traitement du langage naturel. L'idée principale est de capturer les dépendances à longue distance dans la séquence d'entrée via un mécanisme d'auto-attention, améliorant ainsi la capacité du modèle à traiter les données de séquence.
La combinaison efficace des deux ci-dessus est également une technologie émergente très populaire dans les stratégies de conduite autonome.
01 L'analyse de l'avantage technique de BEV
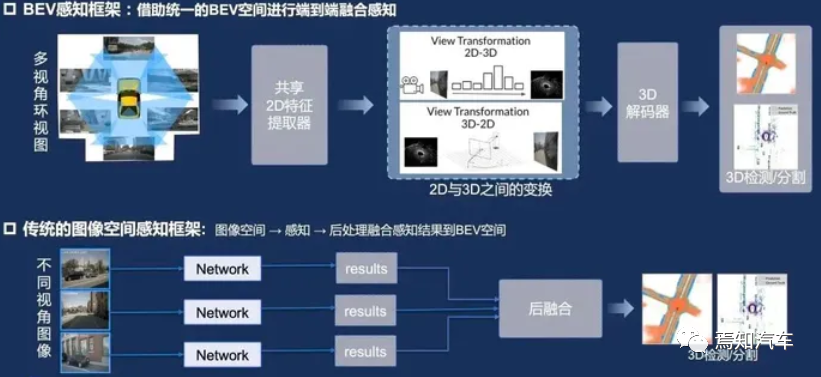
BEV est une méthode qui projette des informations environnementales tridimensionnelles en deux -dimensionnel Une approche planaire qui affiche les objets et le terrain dans l'environnement dans une perspective descendante. Dans le domaine de la conduite autonome, BEV peut aider le système à mieux comprendre l'environnement et à améliorer la précision de la perception et de la prise de décision. Au stade de la perception de l'environnement, BEV peut fusionner des données multimodales telles que le lidar, le radar et la caméra sur le même avion. Cette méthode peut éliminer les problèmes d’occlusion et de chevauchement entre les données et améliorer la précision de la détection et du suivi des objets. Dans le même temps, BEV peut fournir une représentation claire de l’environnement pour les étapes ultérieures de prévision et de prise de décision, ce qui contribue à améliorer les performances globales du système.
1 Comparaison des technologies Lidar et BEV :
Tout d'abord, la technologie BEV peut fournir un perspective globale La perception environnementale contribue à améliorer les performances des systèmes de conduite autonome dans des scénarios complexes. Cependant, le lidar offre une plus grande précision en termes de distance et d’informations spatiales.
Deuxièmement, la technologie BEV capture des images via des caméras et peut obtenir des informations sur la couleur et la texture, alors que les performances du lidar à cet égard sont faibles.
De plus, le coût de la technologie BEV est relativement faible et adapté à un déploiement commercial à grande échelle.
2. Comparaison entre la technologie BEV et la caméra traditionnelle à vue unique
La caméra traditionnelle à vue unique est un dispositif de détection de véhicule couramment utilisé qui peut capturer des informations environnementales autour du véhicule. Cependant, les caméras à vue unique présentent certaines limites en termes de champ de vision et d'acquisition d'informations. La technologie BEV intègre les images de plusieurs caméras pour offrir une perspective globale et une compréhension plus complète de l'environnement autour du véhicule. La technologie BEV est relativement efficace dans des scénarios complexes et des conditions météorologiques extrêmes. Les caméras à vue unique ont de meilleures capacités de perception de l'environnement, car BEV est capable de fusionner les informations d'image sous différents angles, améliorant ainsi la perception de l'environnement par le système.
 La technologie BEV peut aider le système de conduite autonome à mieux gérer les situations difficiles, telles que les conditions routières complexes, les routes étroites ou obstruées, etc., et les caméras à vue unique peuvent aider dans ces situations, les performances peuvent être médiocres.
La technologie BEV peut aider le système de conduite autonome à mieux gérer les situations difficiles, telles que les conditions routières complexes, les routes étroites ou obstruées, etc., et les caméras à vue unique peuvent aider dans ces situations, les performances peuvent être médiocres.
Bien sûr, en termes de coût et d'occupation des ressources, puisque BEV doit effectuer la perception, la reconstruction et l'épissage d'images sous différentes perspectives, il consomme plus de puissance de calcul et de ressources de stockage . Bien que la technologie BEV nécessite le déploiement de plusieurs caméras, le coût global reste inférieur à celui du lidar et ses performances sont considérablement améliorées par rapport aux caméras à vue unique.
En résumé, la technologie BEV présente certains avantages par rapport aux autres technologies de perception dans le domaine de la conduite autonome. En particulier lorsqu'il s'agit de traiter les Corner Cases, la technologie BEV peut fournir une perspective globale de la perception de l'environnement, contribuant ainsi à améliorer les performances des systèmes de conduite autonome dans des scénarios complexes. Cependant, afin de tirer pleinement parti des avantages de la technologie BEV, des recherches et développements supplémentaires sont encore nécessaires pour améliorer les performances des capacités de traitement d’images, de la technologie de fusion de capteurs et de la prédiction des comportements anormaux. Dans le même temps, en combinaison avec d'autres technologies de perception (telles que le lidar) et des algorithmes d'apprentissage profond et d'apprentissage automatique, la stabilité et la sécurité du système de conduite autonome dans divers scénarios peuvent être encore améliorées.
02 Système de conduite autonome basé sur Transformer et BEV
En même temps, Bird's Eye View ( BEV), en tant que méthode efficace de perception de l'environnement, joue un rôle important dans les systèmes de conduite autonome. En combinant les avantages de Transformer et BEV, nous pouvons construire un système de conduite autonome de bout en bout pour obtenir une perception, une prédiction et une prise de décision de haute précision. Cet article explorera également comment Transformer et BEV peuvent être efficacement combinés et appliqués dans le domaine de la conduite autonome pour améliorer les performances du système.
Les étapes spécifiques sont les suivantes :
1. 🎜#
Fusion de données multimodales telles que lidar, radar et caméra au format BEV, et effectuer les opérations de prétraitement nécessaires, telles que l'amélioration des données, la normalisation, etc.Tout d'abord, nous devons convertir les données multimodales telles que le lidar, le radar et la caméra au format BEV. Pour les données de nuage de points lidar, nous pouvons projeter le nuage de points tridimensionnel sur un plan bidimensionnel, puis pixelliser le plan pour générer une carte de hauteur ; pour les données radar, nous pouvons convertir les informations de distance et d'angle en une carte de hauteur. Les coordonnées Karl sont ensuite rastérisées sur le plan BEV ; pour les données de la caméra, nous pouvons projeter les données d'image sur le plan BEV pour générer une carte de couleur ou d'intensité.
Photo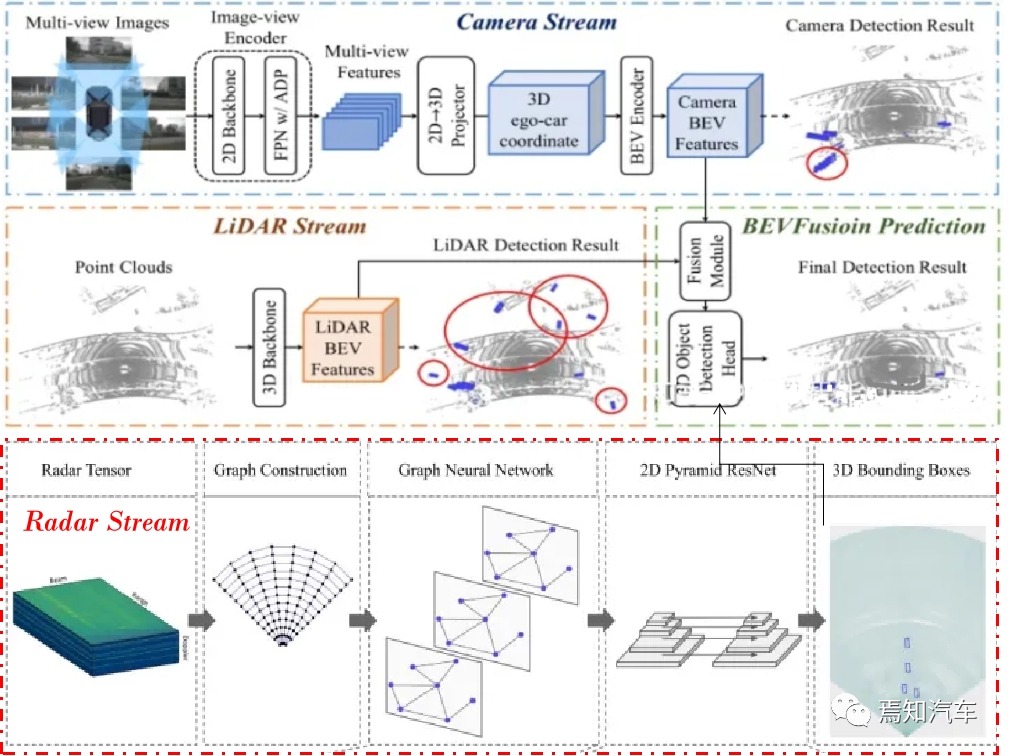
Dans la phase de perception de la conduite autonome, le modèle Transformer peut être utilisé pour extraire des caractéristiques dans des données multimodales, telles que des nuages de points lidar, des images, des données radar, etc. En effectuant une formation de bout en bout sur ces données, Transformer peut automatiquement apprendre la structure intrinsèque et les interrelations de ces données, identifiant et localisant ainsi efficacement les obstacles dans l'environnement.
Utilisez le modèle Transformer pour extraire des fonctionnalités des données BEV afin de détecter et de localiser les obstacles.
Superposez ces données au format BEV ensemble pour former une image BEV multicanal. Supposons que la carte de hauteur BEV du lidar est H(x, y), la carte de portée BEV du radar est R(x, y) et la carte d'intensité BEV de la caméra est I(x, y), alors le L'image multicanal BEV peut être exprimée comme suit: :
B(x, y) = [H(x, y), R(x, y), I( x, y)]
Où B(x, y) représente la valeur en pixels de l'image BEV multicanal aux coordonnées (x, y), [] représente superposition des canaux.
3. Module de prédiction :
En fonction de la sortie du module de perception, utilisez le modèle Transformer. pour prédire aux autres usagers de la route le comportement et la trajectoire futurs de la personne. En apprenant les données de trajectoire historiques, Transformer est capable de capturer les schémas de mouvement et les interactions des usagers de la route, fournissant ainsi des prédictions plus précises pour les systèmes de conduite autonome.
Plus précisément, nous utilisons d'abord Transformer pour extraire des fonctionnalités d'images BEV multicanaux. En supposant que l'image BEV d'entrée est B(x, y), nous pouvons extraire la caractéristique F(x, y) via un mécanisme d'auto-attention multicouche et un codage de position :
#🎜 🎜# F(x, y) = Transformer(B(x, y))
où F(x, y) représente la carte des caractéristiques, aux coordonnées (x , y) valeurs propres à.
Ensuite, nous utilisons les caractéristiques extraites F(x, y) pour prédire les comportements et les trajectoires des autres usagers de la route. Le décodeur de Transformer peut être utilisé pour générer des résultats de prédiction, comme indiqué ci-dessous :
P(t) = Decoder(F(x, y), t)#🎜🎜 #
où P(t) représente le résultat de la prédiction au temps t, et Decoder représente le décodeur Transformer.
Grâce aux étapes ci-dessus, nous pouvons réaliser la fusion de données et la prédiction basées sur Transformer et BEV. La structure spécifique du Transformer et les réglages des paramètres peuvent être ajustés en fonction des scénarios d'application réels pour obtenir des performances optimales.
4. Module de prise de décision :
Basé sur les résultats du module de prédiction, combiné avec modèle de règles de circulation et de dynamique des véhicules, utilisant le modèle Transformer pour générer des stratégies de conduite appropriées.
Photo
En intégrant des informations environnementales, des règles de circulation et des modèles de dynamique des véhicules dans le modèle, Transformer est capable d'apprendre des stratégies de conduite efficaces et sûres. Tels que la planification de chemin, la planification de vitesse, etc. De plus, grâce au mécanisme d'auto-attention multi-têtes de Transformer, les pondérations entre les différentes sources d'informations peuvent être efficacement équilibrées pour prendre des décisions plus raisonnables dans des environnements complexes.
Voici les étapes spécifiques pour adopter cette méthode :
1. # 🎜🎜#
Tout d'abord, une grande quantité de données de conduite doivent être collectées, notamment des informations sur l'état du véhicule (telles que la vitesse, l'accélération, l'angle du volant, etc.), informations sur l'état de la route (telles que le type de route, les panneaux de signalisation, les voies, etc.), les lignes, etc.), les informations sur l'environnement environnant (telles que les autres véhicules, les piétons, les vélos, etc.) et les actions entreprises par le conducteur. Ces données sont prétraitées, y compris le nettoyage des données, la normalisation et l'extraction de fonctionnalités.
2. Encodage et sérialisation des données :
Encodez les données collectées dans un formulaire de saisie de modèle Transformer approprié. . Cela implique généralement la discrétisation de données numériques continues et la conversion des données discrétisées sous forme vectorielle. Dans le même temps, les données doivent être sérialisées afin que le modèle Transformer puisse gérer les informations de synchronisation.
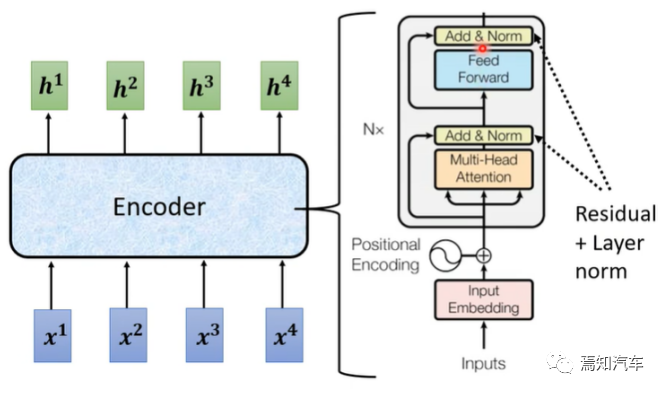
2.1, Encodeur de transformateur
Encodeur de transformateur par Il se compose de sous-couches avec la même couche, et chaque sous-couche contient deux parties : l'attention multi-têtes et le réseau neuronal à action directe.
Auto-attention multi-têtes : divisez d'abord la séquence d'entrée en h têtes différentes, calculez l'auto-attention de chaque tête séparément, puis divisez la sortie de celles-ci se dirige vers Ensemble. Cela capture les dépendances à différentes échelles dans la séquence d'entrée.
 Photo
Photo
La formule de calcul de l'auto-attention du taureau est : #🎜🎜 #
MHA(X) = Concat(head_1, head_2, ..., head_h) * W_Owhere MHA ( X) représente le résultat de l'auto-attention multi-têtes, head_i représente le résultat de la i-ème tête et W_O est la matrice de poids de sortie.
Réseau neuronal feedforward : Ensuite, la sortie de l'auto-attention multi-têtes est transmise au réseau neuronal feedforward. Les réseaux de neurones Feedforward contiennent généralement deux couches entièrement connectées et une fonction d'activation (telle que ReLU). La formule de calcul du réseau de neurones feedforward est :
FFN(x) = max(0, xW_1 + b_1) * W_2 + b_2
#🎜🎜 # où FFN(x) représente la sortie du réseau neuronal feedforward, W_1 et W_2 sont des matrices de poids, b_1 et b_2 sont des vecteurs de biais et max(0, x) représente la fonction d'activation ReLU.
De plus, chaque sous-couche de l'encodeur contient des connexions résiduelles et une normalisation de couche (normalisation de couche), ce qui contribue à améliorer la stabilité d'entraînement du modèle et la vitesse de convergence .
2.2, le décodeur de transformateur
est similaire à l'encodeur, Le décodeur Transformer est également composé de plusieurs sous-couches identiques, chaque sous-couche contient trois parties : l'auto-attention multi-têtes, l'attention codeur-décodeur (Encoder-Decoder Attention) et le réseau neuronal à action directe.
Auto-attention multi-têtes : identique à l'auto-attention multi-têtes dans l'encodeur, utilisée pour calculer le degré de corrélation entre chaque élément dans le décodeur séquence d’entrée.
Attention codeur-décodeur : permet de calculer le degré de corrélation entre la séquence d'entrée du décodeur et la séquence de sortie du codeur. La méthode de calcul est similaire à l'auto-attention, sauf que le vecteur de requête provient de la séquence d'entrée du décodeur et que le vecteur clé et le vecteur de valeur proviennent de la séquence de sortie du codeur.
Réseau neuronal Feedforward : identique au réseau neuronal feedforward dans l'encodeur. Chaque sous-couche du décodeur contient également des connexions résiduelles et une normalisation de couche. En empilant plusieurs couches d'encodeurs et de décodeurs, Transformer est capable de gérer des données de séquence avec des dépendances complexes.
3. Construisez un modèle Transformer :
Construisez un modèle Transformer adapté aux scénarios de conduite autonome, y compris Définissez le nombre approprié de calques, le nombre d’en-têtes et la taille des calques masqués. En outre, le modèle doit également être affiné en fonction des exigences de la tâche, par exemple en utilisant une stratégie de conduite pour générer une fonction de perte pour la tâche.
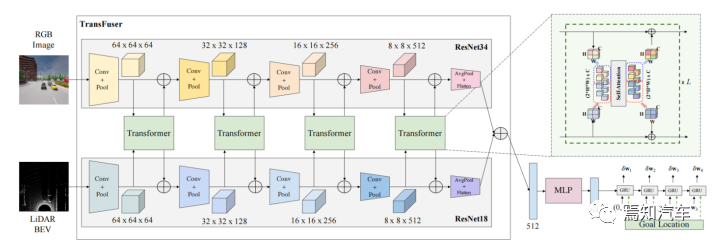
Tout d'abord, le vecteur de caractéristiques est obtenu par MLP pour obtenir un vecteur de faible dimension, qui est transmis au réseau de points de chemin de régression automatique implémenté par GRU et utilisé pour initialiser l'état caché de GRU. De plus, la position actuelle et la position cible sont également saisies, ce qui permet au réseau de se concentrer sur le contexte pertinent de l'état caché.
 image
image
Utilisez un GRU monocouche et utilisez une couche linéaire pour prédire le décalage du point de chemin 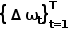 par rapport à l'état caché pour obtenir le point de chemin prédit
par rapport à l'état caché pour obtenir le point de chemin prédit 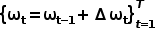 . L'entrée du GRU est l'origine.
. L'entrée du GRU est l'origine.
Le contrôleur utilise deux contrôleurs PID pour effectuer un contrôle horizontal et longitudinal respectivement en fonction des points de trajectoire prédits afin d'obtenir les valeurs de direction, de freinage et d'accélérateur. Effectuez une moyenne pondérée des vecteurs de points de trajet de trame continue, puis l'entrée du contrôleur longitudinal est la longueur de son module et l'entrée du contrôleur transversal est son orientation.
Calculez la perte L1 du point de trajectoire expert et du point de trajectoire de trajectoire prédit dans le système de coordonnées de l'auto-véhicule du cadre actuel, c'est-à-dire
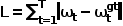
4. Formation et vérification :
. Utilisez l’ensemble de données collectées Former le modèle Transformer. Au cours du processus de formation, le modèle doit être validé pour vérifier sa capacité de généralisation. L'ensemble de données peut être divisé en ensembles de formation, de validation et de test pour évaluer le modèle.
5. Génération de stratégie de conduite :
Dans les applications réelles, le modèle Transformer pré-entraîné est saisi en fonction de l'état actuel du véhicule, des informations sur l'état de la route et des informations sur l'environnement environnant. Le modèle générera des stratégies de conduite telles que l'accélération, la décélération, la direction, etc. sur la base de ces entrées.
6. Exécution et optimisation de la stratégie de conduite :
Transmettez la stratégie de conduite générée au système de conduite autonome pour contrôler le véhicule. Dans le même temps, les données du processus d'exécution réel sont collectées pour une optimisation et une itération ultérieures du modèle.
Grâce aux étapes ci-dessus, une méthode basée sur le modèle Transformer peut être utilisée pour générer une stratégie de conduite appropriée dans la phase de prise de décision en matière de conduite autonome. Il convient de noter qu'en raison des exigences de sécurité élevées dans le domaine de la conduite autonome, il est nécessaire de garantir les performances et la sécurité du modèle dans différents scénarios lors du déploiement réel.
03 Exemples de technologie Transformer+BEV résolvant un cas de coin
Dans cette section, nous présenterons en détail trois exemples de technologie BEV résolvant un cas de coin, impliquant respectivement des conditions routières complexes, des conditions météorologiques extrêmes et la prévision d'un comportement anormal. . La figure suivante montre quelques scénarios de cas extrêmes en matière de conduite autonome. L'utilisation de la technologie Transformer+BEV permet d'identifier et de traiter efficacement la plupart des scènes périphériques actuellement identifiables.
 Photos
Photos
1. Gestion de conditions routières complexes
Dans des conditions routières complexes, telles que des embouteillages, des intersections complexes ou des surfaces routières irrégulières, la technologie Transformer+BEV peut fournir une perception environnementale plus complète. En intégrant des images de plusieurs caméras autour du véhicule, les BEV génèrent une perspective aérienne continue, permettant au système de conduite autonome d'identifier clairement les lignes de voie, les obstacles, les piétons et les autres usagers de la route. Par exemple, à une intersection complexe, la technologie BEV peut aider le système de conduite autonome à identifier avec précision l'emplacement et la direction de chaque participant à la circulation, fournissant ainsi une base fiable pour la planification des itinéraires et la prise de décision.
2. Faire face à des conditions météorologiques extrêmes
Dans des conditions météorologiques extrêmes, telles que la pluie, la neige, le brouillard, etc., les caméras et lidar traditionnels peuvent être affectés, réduisant les capacités de perception du système de conduite autonome. La technologie Transformer+BEV présente encore certains avantages dans ces situations car elle peut fusionner les informations d'image sous différents angles pour améliorer la perception de l'environnement par le système. Afin d'améliorer encore les performances de la technologie Transformer+BEV dans des conditions météorologiques extrêmes, vous pouvez envisager d'utiliser des équipements auxiliaires tels que des caméras infrarouges ou des caméras thermiques pour compléter les carences des caméras à lumière visible dans ces situations.
3. Prédire un comportement anormal
Dans les environnements routiers réels, les piétons, les cyclistes et les autres usagers de la route peuvent présenter un comportement anormal, comme traverser soudainement la route, enfreignant le code de la route, etc. La technologie BEV peut aider les systèmes de conduite autonome à mieux prédire ces comportements anormaux. Dans une perspective mondiale, BEV peut fournir des informations environnementales complètes, permettant au système de conduite autonome de suivre et de prédire avec plus de précision la dynamique des piétons et des autres usagers de la route. De plus, en combinant des algorithmes d'apprentissage automatique et d'apprentissage profond, la technologie Transformer+BEV peut encore améliorer la précision de la prédiction des comportements anormaux, permettant au système de conduite autonome de prendre des décisions plus raisonnables dans des scénarios complexes.
4. Routes étroites ou bloquées
Dans les environnements routiers étroits ou bloqués, les caméras et lidar traditionnels peuvent ont du mal à obtenir suffisamment d’informations pour une sensibilisation efficace à l’environnement. Cependant, la technologie Transformer+BEV peut entrer en jeu dans ces situations car elle peut intégrer des images capturées par plusieurs caméras pour générer une vue plus complète. Cela permet au système de conduite autonome de mieux comprendre l’environnement autour du véhicule, d’identifier les obstacles dans les passages étroits et de naviguer en toute sécurité dans ces scénarios.
5. Fusion des véhicules et fusion du trafic
Dans des scénarios tels que les autoroutes, les systèmes de conduite autonome doivent faire face avec des tâches complexes telles que la fusion des véhicules et la fusion du trafic. Ces tâches imposent des exigences élevées aux capacités de perception du système de conduite autonome, car le système doit évaluer la position et la vitesse des véhicules environnants en temps réel pour garantir une fusion et une fusion du trafic en toute sécurité. Grâce à la technologie Transformer+BEV, le système de conduite autonome peut obtenir une perspective globale et comprendre clairement les conditions de circulation autour du véhicule. Cela aidera le système de conduite autonome à développer une stratégie de fusion appropriée pour garantir que le véhicule se fond en toute sécurité dans le flux de circulation.
6. Intervention d'urgence
Dans les situations d'urgence, telles que les accidents de la route, les fermetures de routes ou les urgences En cas d'incident, le système de conduite autonome doit prendre des décisions rapides pour garantir la sécurité de conduite. Dans ces cas, la technologie Transformer+BEV peut fournir une perception environnementale complète et en temps réel pour le système de conduite autonome, aidant ainsi le système à évaluer rapidement les conditions routières actuelles. En combinant des données en temps réel et des algorithmes avancés de planification de trajectoire, les systèmes de conduite autonome peuvent développer des stratégies d'urgence appropriées pour éviter les risques potentiels.
A travers ces exemples, nous pouvons voir que la technologie Transformer+BEV a un grand potentiel pour traiter les Corner Case. Cependant, afin de tirer pleinement parti des avantages de la technologie Transformer+BEV, des recherches et développements supplémentaires sont encore nécessaires pour améliorer les performances en matière de capacités de traitement d'images, de technologie de fusion de capteurs et de prédiction de comportements anormaux.
04 Conclusion
Cet article résume les principes et les applications de la technologie Transformer et BEV dans la conduite autonome. Surtout comment résoudre le problème du Corner Case. En offrant une perspective globale et une perception environnementale précise, la technologie Transformer+BEV devrait améliorer la fiabilité et la sécurité des systèmes de conduite autonome face à des situations extrêmes. Cependant, la technologie actuelle présente encore certaines limites, comme la dégradation des performances en cas de conditions météorologiques défavorables. Les recherches futures devraient continuer à se concentrer sur l’amélioration de la technologie BEV et son intégration avec d’autres technologies de détection pour atteindre un niveau plus élevé de sécurité de conduite autonome.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Mar 06, 2024 pm 05:34 PM
Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Mar 06, 2024 pm 05:34 PM
L'article de StableDiffusion3 est enfin là ! Ce modèle est sorti il y a deux semaines et utilise la même architecture DiT (DiffusionTransformer) que Sora. Il a fait beaucoup de bruit dès sa sortie. Par rapport à la version précédente, la qualité des images générées par StableDiffusion3 a été considérablement améliorée. Il prend désormais en charge les invites multithèmes, et l'effet d'écriture de texte a également été amélioré et les caractères tronqués n'apparaissent plus. StabilityAI a souligné que StableDiffusion3 est une série de modèles avec des tailles de paramètres allant de 800M à 8B. Cette plage de paramètres signifie que le modèle peut être exécuté directement sur de nombreux appareils portables, réduisant ainsi considérablement l'utilisation de l'IA.
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
