
 Périphériques technologiques
IA
À quel point le modèle simple de conversion vocale qui prend en charge les échanges multilingues, de voix humaine et d'aboiements de chien est-il étonnant et n'utilise que les voisins les plus proches ?
Périphériques technologiques
IA
À quel point le modèle simple de conversion vocale qui prend en charge les échanges multilingues, de voix humaine et d'aboiements de chien est-il étonnant et n'utilise que les voisins les plus proches ?
À quel point le modèle simple de conversion vocale qui prend en charge les échanges multilingues, de voix humaine et d'aboiements de chien est-il étonnant et n'utilise que les voisins les plus proches ?

Le monde vocal auquel participe l'IA est vraiment magique. Il peut non seulement changer la voix d'une personne en celle de n'importe quelle autre personne, mais aussi échanger des voix avec des animaux.
Nous savons que le but de la conversion vocale est de convertir la voix source en voix cible tout en gardant le contenu inchangé. Les méthodes récentes de conversion de la parole de type "any-to-any" améliorent le naturel et la similarité des locuteurs, mais au prix d'une complexité considérablement accrue. Cela signifie que la formation et l’inférence deviennent plus coûteuses, ce qui rend les améliorations difficiles à évaluer et à établir.
La question est la suivante : une conversion vocale de haute qualité nécessite-t-elle de la complexité ? Dans un article récent de l'Université de Stellenbosch en Afrique du Sud, plusieurs chercheurs ont exploré cette question.

- Adresse papier : https://arxiv.org/pdf/2305.18975.pdf
- Adresse GitHub : https://bshall.github.io/knn-vc/
Les points forts de la recherche sont : Ils ont introduit la conversion vocale K-Nearest Neighbour (kNN-VC), une méthode de conversion vocale simple et puissante de n'importe quel à n'importe quel . Au lieu de former un modèle de transformation explicite, la régression du K-plus proche voisin est simplement utilisée.
Plus précisément, les chercheurs ont d'abord utilisé un modèle de représentation vocale auto-supervisé pour extraire la séquence de caractéristiques de l'énoncé source et de l'énoncé de référence, puis ont converti chaque image de la représentation source en locuteur cible en la remplaçant par la plus proche. voisin dans la référence, et enfin utiliser un vocodeur neuronal pour synthétiser les caractéristiques converties afin d'obtenir la parole convertie.
À en juger par les résultats, malgré sa simplicité, KNN-VC atteint une intelligibilité et une similarité de locuteur comparables, voire améliorées, dans les évaluations subjectives et objectives par rapport à plusieurs systèmes de conversion vocale de base.
Apprécions l'effet de la conversion vocale KNN-VC. En examinant d'abord la conversion de la voix humaine, KNN-VC est appliqué aux locuteurs sources et cibles invisibles dans l'ensemble de données LibriSpeech.
Voix source00:11
Voix synthétisée 100:11
Voix synthétisée 200:11
K NN-VC prend également en charge la conversion vocale multilingue, Par exemple, de l'espagnol vers l'allemand, de l'allemand vers le japonais, du chinois vers l'espagnol.
Source Chinois 00:08
Cible Espagnol 00:05
Discours synthétique 300:08
Encore plus étonnant ly, KNN-VC peut toujours échanger des voix humaines et les aboiements du chien.
Source chien qui aboie00:09
Source voix humaine00:05
Voix synthétique 400:08
S voix synthétique 5 00:05
Voyons comment KNN-VC fonctionne et se compare avec d'autres méthodes jixian.
Aperçu de la méthode et résultats expérimentaux
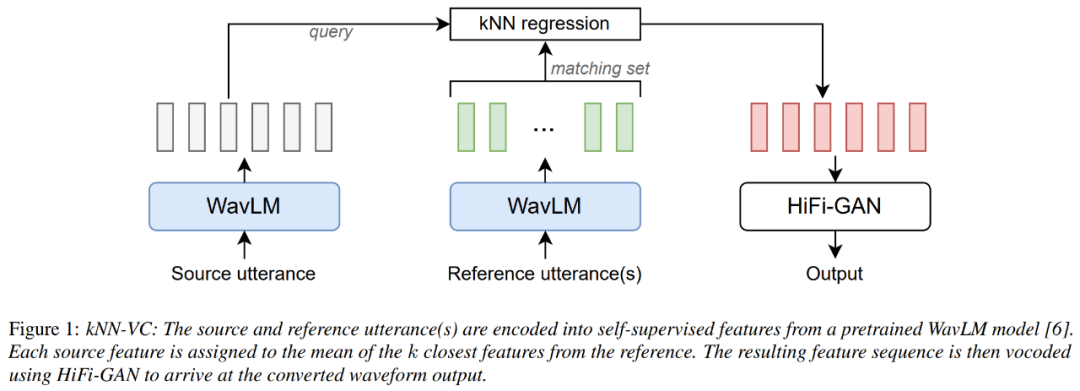
Le schéma d'architecture de kNN-VC est présenté ci-dessous, suivant la structure encodeur-convertisseur-vocodeur. Tout d'abord, l'encodeur extrait les représentations auto-supervisées de la parole source et de référence, puis le convertisseur mappe chaque image source à son voisin le plus proche dans la référence, et enfin le vocodeur génère des formes d'onde audio basées sur les caractéristiques converties.
L'encodeur utilise WavLM, le convertisseur utilise la régression du voisin le plus proche et le vocodeur utilise HiFiGAN. Le seul composant qui nécessite une formation est le vocodeur.
Pour l'encodeur WavLM, le chercheur a uniquement utilisé le modèle WavLM-Large pré-entraîné et n'a effectué aucune formation sur celui-ci dans l'article. Pour le modèle de transformation kNN, kNN est non paramétrique et ne nécessite aucune formation. Pour le vocodeur HiFiGAN, le dépôt original de l'auteur HiFiGAN a été utilisé pour vocoder les fonctionnalités WavLM, devenant ainsi la seule partie nécessitant une formation.
 Photos
Photos
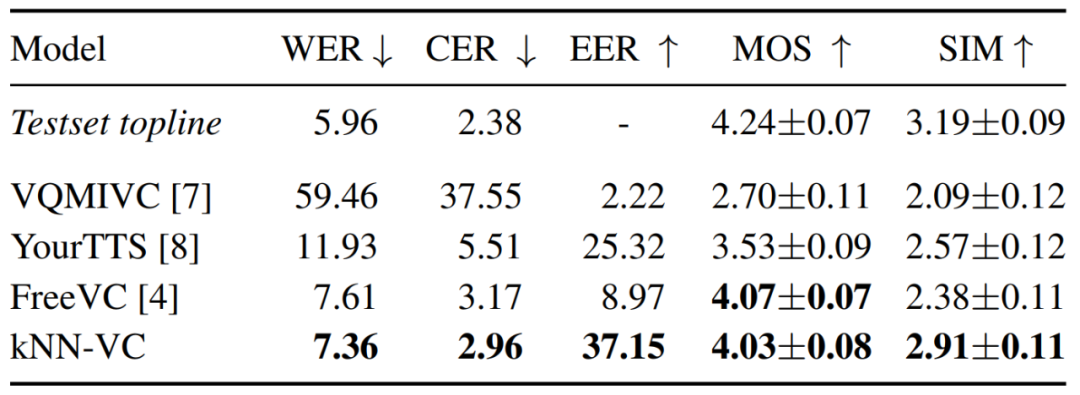
Dans l'expérience, les chercheurs ont d'abord comparé KNN-VC avec d'autres méthodes de base, en utilisant les plus grandes données cibles disponibles (environ 8 minutes d'audio par locuteur) pour tester le système de conversion vocale.
Pour KNN-VC, le chercheur utilise toutes les données cibles comme ensemble de correspondance. Pour la méthode de base, ils font la moyenne des intégrations de locuteurs pour chaque énoncé cible.
Le tableau 1 ci-dessous présente les résultats de chaque modèle en termes d'intelligibilité, de naturel et de similarité des locuteurs. Comme on peut le voir, kNN-VC atteint un naturel et une clarté similaires à ceux du meilleur FreeVC de base, mais avec une similarité de haut-parleur considérablement améliorée. Cela confirme également l'affirmation de cet article : une conversion vocale de haute qualité ne nécessite pas de complexité accrue.
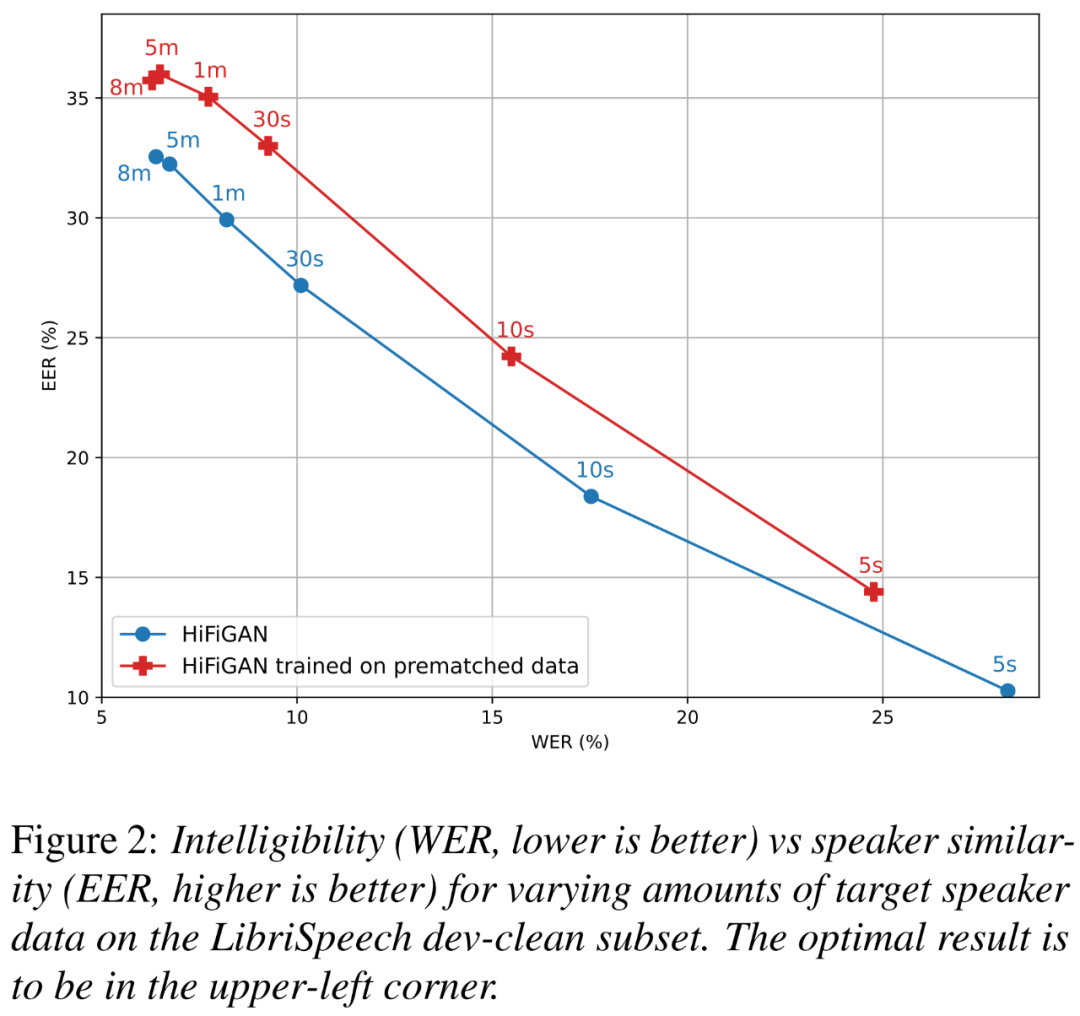
De plus, les chercheurs voulaient comprendre dans quelle mesure l'amélioration était due à la formation HiFi-GAN sur des données pré-appariées, et dans quelle mesure la taille des données du locuteur cible affectait l'intelligibilité et la similarité des locuteurs.
La figure 2 ci-dessous montre la relation entre WER (plus petit est mieux) et EER (plus haut est mieux) pour deux variantes HiFi-GAN à différentes tailles d'enceintes cibles.
 Photos
Photos
Commentaires chauds des internautes
Pour cette nouvelle méthode de conversion vocale kNN-VC qui "utilise uniquement les voisins les plus proches", certaines personnes pensent qu'un modèle vocal pré-entraîné est utilisé dans l'article , donc "seulement" est utilisé. Pas tout à fait précis. Mais il est indéniable que le kNN-VC reste plus simple que les autres modèles.
Les résultats prouvent également que kNN-VC est tout aussi efficace, sinon le meilleur, par rapport aux méthodes très complexes de conversion vocale any-to-any.
 Photos
Photos
Certaines personnes ont également dit que l'exemple de l'échange de voix humaine et d'aboiements de chien est très intéressant.
 photos
photos
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
