

Gestion de la mémoire en mode protégé Linux

Nous savons que la mémoire peut être considérée comme un très grand tableau. Si nous voulons trouver un élément dans la mémoire, il sera spécifié par l'indice du tableau. Il en va de même pour la mémoire, mais il y a une prémisse selon laquelle. le tableau est composé d'un ensemble d'octets ordonnés. Dans ce tableau d'octets ordonnés, chaque octet a une adresse unique. Cette adresse est également appelée adresse mémoire.
Il existe de nombreux objets stockés dans la mémoire. Chaque objet est composé de différents octets, comme un objet char, un objet byte, un objet int, etc. Ils sont tous divisés en différents emplacements dans la mémoire. L'opération de localisation des adresses de ces objets est appelée adressage mémoire. La largeur du bus mémoire détermine le nombre de bits d'adresse mémoire pouvant être adressés, en commençant par l'adresse 0. Puisque 80X86 fait 32 bits, la largeur du bus est également de 32 bits, il y a donc 2 ^ 32 adresses mémoire au total, donc un total de 4 Go d'adresses mémoire peuvent être stockées. Plusieurs types de données d'octets, tels que int, long et double, peuvent être extraits via des adresses mémoire consécutives.
Bien que les objets puissent être adressés, l'ordre des octets dans lequel ces objets sont stockés est différent. Il existe deux méthodes de stockage, à savoir le big endian et le little endian.
Par exemple, il y a un objet de type int situé à l'adresse 0x100, et sa valeur hexadécimale est 0x01234567. Je vais vous faire un dessin et vous comprendrez la différence entre les deux ordres de stockage.
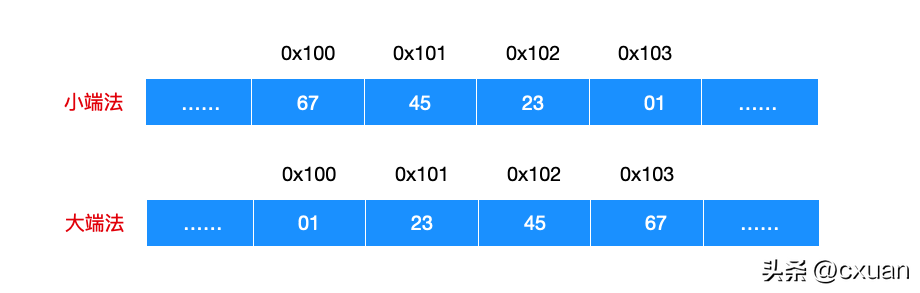
C'est en fait facile à comprendre. Le type de données int de 0x01234567 peut être divisé en 01 23 45 67 octets, et 01 est le bit haut et 67 est le bit bas, donc l'ordre de stockage du petit endian et Les méthodes big-endian peuvent être expliquées. : Autrement dit, la méthode small-endian utilise d'abord le bit de poids faible, tandis que la méthode big-endian utilise d'abord le bit de poids fort. La différence entre big-endian et small-endian réside uniquement dans l'ordre de stockage et n'a rien à voir avec le nombre de chiffres et les valeurs numériques de l'objet. La plupart des machines Intel utilisent le mode Little-Endian, donc 80X86 est également un stockage Little-Endian, tandis que la plupart des machines IBM et Oracle utilisent un stockage Big-Endian.
Comme l'ordinateur ne peut pas adresser directement toutes les données de la mémoire en même temps parce qu'elle est relativement trop volumineuse, la mémoire est généralement segmentée. Cela soulève une question : pourquoi la mémoire est-elle segmentée ? Je viens de donner une introduction générale ci-dessus.
Pourquoi la mémoire doit-elle être segmentée ?
https://www.php.cn/link/d005ce7aeef46bd18515f783fb8e87fa
À l'aide du mécanisme de segmentation, l'espace mémoire est divisé en zones linéaires, et chaque zone linéaire peut être localisée par l'adresse de base du segment plus l'intra-segment compenser. La partie adresse de base du segment est spécifiée par un sélecteur de segment de 16 bits, dont 14 bits peuvent sélectionner la puissance 2 ^ 14, soit 16 384 segments. La partie adresse de décalage dans le segment est spécifiée à l'aide d'une valeur de 32 bits, de sorte que la partie adresse de base du segment est spécifiée par un sélecteur de segment de 16 bits, dont 14 bits peuvent sélectionner la puissance 2 ^ 14, soit 16 384 segments. L'adresse dans le segment peut être comprise entre 0 et 4G, la longueur maximale d'un segment est de 4 Go, ce qui correspond à l'adresse mémoire de 4 Go mentionnée ci-dessus. Une adresse de 48 bits ou un pointeur long composé d'un segment de 16 bits et d'un décalage dans un segment de 32 bits est appelée adresse logique, et l'adresse logique est l'adresse virtuelle.
Il existe six registres spéciaux dans l'architecture X86 pour stocker les adresses de base de segments, à savoir CS, DS, ES, SS, FS et GS. CS est utilisé pour adresser le segment de code, SS est utilisé pour adresser le segment de pile et d'autres registres sont utilisés pour adresser le segment de données. Le segment adressé par le CS à un instant donné est appelé segment de code courant. L'adresse de décalage de la prochaine instruction à exécuter dans le segment de code en cours existe déjà dans le registre EIP. À ce stade, l'adresse de base du segment : l'adresse de décalage peut être exprimée sous la forme CS : EIP.
Le segment adressé par le registre de segment SS est appelé le segment de pile actuel. Le haut de la pile est donné par le registre ESP. À tout moment, SS:ESP pointe vers le haut de la pile, et il n'y a pas d'exception. les quatre autres sont des registres de segments de données généraux. Quand Lorsqu'il n'y a pas de segment de données dans l'instruction par défaut, il est donné par DS.
Traduction d'adresses
Habituellement, un système complet de gestion de mémoire se compose de deux éléments : la protection d'accès et la traduction d'adresses. La protection d'accès consiste à empêcher une application d'accéder à une adresse mémoire utilisée par un autre programme. La traduction d'adresses consiste à fournir une méthode d'allocation d'adresse dynamique pour différentes applications. La protection d’accès et la traduction d’adresses se complètent.
La traduction d'adresses utilise généralement des blocs de mémoire comme unité de base. Voici une explication de ce qu'est un bloc. Comme nous le savons tous, sous Linux, tout est un fichier et les fichiers sont composés de blocs pour décrire les fichiers. L'unité constitutive du système est également l'unité de base du traitement des données. Les blocs communs ont différentes tailles, comme 512B, 1 Ko, 4 Ko, etc. Bien qu'un bloc soit l'unité de base, il est essentiellement composé de secteurs.
Il existe deux manières de mettre en œuvre la traduction d'adresses : le mécanisme de segmentation et le mécanisme de pagination. L'implémentation de la gestion de la mémoire dans x86 combine des mécanismes de segmentation et de pagination. Ce qui suit est un diagramme de mappage d'adresses virtuelles converties en adresses physiques après segmentation et pagination
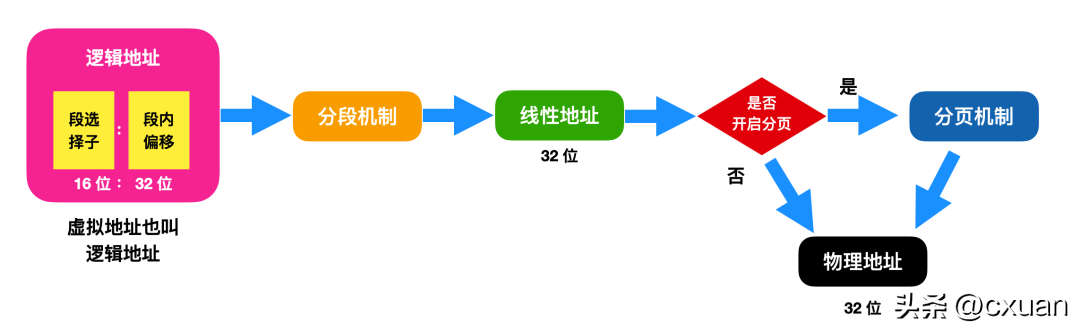
Pour cette image, il est nécessaire d'expliquer :
Tout d'abord, cette image contient trois adresses et le processus de conversion de ces trois adresses. De manière générale, l'adresse logique deviendra une adresse linéaire après conversion de l'adresse de base segmentée. L'adresse linéaire est l'adresse de base du segment en mode protection + Intra-. décalage de segment, cette image est donc un diagramme de traduction d'adresses en mode protégé. L'adresse linéaire sera convertie en adresse physique après le mécanisme de pagination, à condition que le mécanisme de pagination doive être activé ; si le mécanisme de pagination n'est pas activé, l'adresse linéaire = adresse physique ;
Je dois reparler de l'adresse logique. L'adresse logique contient le sélecteur de segment et le décalage intra-segment. La notion de sélecteur de segment est relativement vague lorsque je suis entré en contact avec elle pour la première fois. être compris comme la base du segment en mode protégé, nous savons tous que l'adresse de base du segment est de 16 bits et que le décalage à l'intérieur du segment est de 32 bits.
De nombreux livres ou articles ont mentionné les sélecteurs de segments. En fait, les sélecteurs de segments sont des sélecteurs de segments. En anglais, ce sont tous des sélecteurs.
Le descripteur de segment sera mentionné plus tard. Le descripteur de segment et le sélecteur de segment ne sont pas la même chose, mais le sélecteur de segment est un descripteur de segment de 16 bits.
Laissez-moi vous dire quelque chose qui n'est pas écrit dans cette image. Maintenant, tout le monde sait que les adresses logiques peuvent être converties en adresses linéaires et que les adresses linéaires peuvent être converties en adresses physiques. Alors, comment la cause première est-elle convertie ? En fait, la méthode utilisée ici est la MMU (memory management unit) pour la conversion et la conversion des adresses linéaires en adresses physiques utilise le circuit matériel de l'unité de radiomessagerie ; L'objectif de cet article n'est pas de discuter du processus de conversion spécifique, mais de se concentrer sur les deux mécanismes de segmentation et de pagination.
Parlons en détail des deux mécanismes de segmentation et de pagination.
Mécanisme de segmentation
Je vous recommande de lire d'abord la description que j'ai écrite sur "Pourquoi la mémoire doit être segmentée".
https://www.php.cn/link/d005ce7aeef46bd18515f783fb8e87fa
Plusieurs programmes s'exécutent dans le même espace mémoire et n'interfèrent pas les uns avec les autres. En effet, la segmentation permet d'isoler le code, les données et les zones de pile. . Si plusieurs programmes ou tâches sont exécutés dans le processeur, chaque programme peut se voir attribuer son propre ensemble de segments (y compris le code du programme, les données et la pile). Le processeur empêche les applications d'interférer les unes avec les autres en renforçant les limites entre les segments.
Tous les segments utilisés dans un système sont contenus dans l'espace d'adressage linéaire du CPU. Afin de localiser un octet dans un segment spécifié, le programme doit fournir une adresse logique pour que la traduction ait lieu. L'adresse logique contient le sélecteur de segment et le décalage au sein du segment. Chaque segment a un descripteur de segment. Le descripteur de segment est utilisé pour indiquer la taille du segment, les droits d'accès et le niveau de privilège du segment, le type de segment et le premier octet. du segment est en ligne, emplacement dans l'espace d'adressage sexuel (adresse de base du segment). La partie décalage de l'adresse logique est ajoutée à l'adresse de base du segment pour localiser la position d'un certain octet dans le segment, de sorte que l'adresse de base du segment + le décalage forme l'adresse dans l'espace d'adressage linéaire du processeur.
L'espace d'adressage linéaire a la même structure que l'espace d'adressage physique, mais les segments qu'ils peuvent accueillir sont très différents. L'adresse virtuelle, c'est-à-dire l'espace d'adressage logique, peut contenir jusqu'à 16 000 segments, et chaque segment peut accueillir une taille de. 4 Go, de sorte que l'adresse virtuelle peut trouver un total de segments de 64 To (2 ^ 46), et l'adresse linéaire et l'espace d'adressage physique sont de 4 Go (2 ^ 32). Ainsi, si la pagination est désactivée, l'espace d'adressage linéaire est l'espace d'adressage physique.
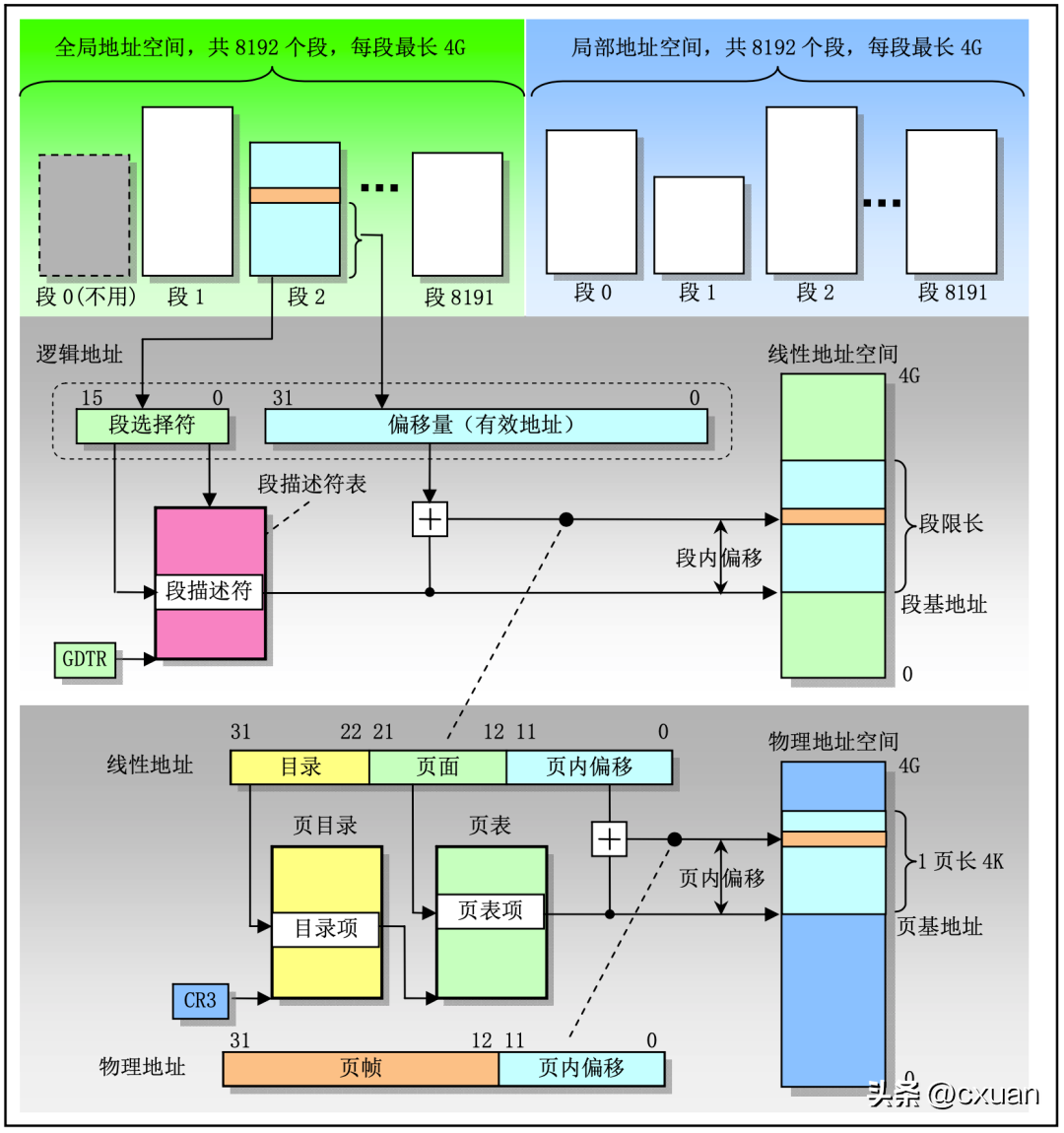
Cette image est le diagramme de mappage de l'adresse logique-> adresse linéaire-> La table GDT et la table LDT occupent chacune la moitié de l'espace d'adressage, chacune avec 8192 segments, et chaque segment est actif. à 4G, qu'il s'agisse d'interroger à partir de la table GDT ou de la table LDT, la table à interroger dépend de l'attribut TI du sélecteur de segment. La structure du sélecteur de segment est la suivante

Le sélecteur de segment est divisé en. trois parties au total :
- RPL (Request Privilege Level) : niveau de privilège de demande, indiquant les autorisations que le processus doit avoir pour accéder au segment. Plus la valeur est grande, plus les autorisations sont petites.
- TI (Indicateur de table) : Indique quelle table doit être interrogée, TI = 0 pour interroger la table GDT ; TI = 1 pour interroger la table LDT.
- Index : le CPU ajoutera automatiquement l'index * 8, plus l'adresse de base du segment dans GDT et LDT, qui est le descripteur de segment à charger.
Il n'y a pas d'explication détaillée des descripteurs de segments ici, car cet article privilégie toujours la gestion de la mémoire et n'est pas trop obsédé par certains détails.
Dans GDTR, l'adresse logique composée du sélecteur de segment et du décalage peut être synthétisée dans un descripteur de segment et enregistrée directement. Les sélecteurs de segments et les décalages intra-segments peuvent être convertis en adresses linéaires après passage par la MMU.
Mécanisme de pagination
Comme nous l'avons mentionné ci-dessus, l'adresse linéaire est convertie à partir de l'adresse logique. Si le mécanisme de pagination est désactivé, l'adresse linéaire est l'adresse physique. Si le mécanisme de pagination est activé, le nombre d'adresses linéaires et logiques. les espaces d’adressage sont toujours différents. Généralement, les programmes sont multitâches et l'espace d'adressage linéaire généralement défini par le multitâche est beaucoup plus grand que la capacité de la mémoire physique. Pourquoi ? La carte de traduction d'adresse montre que l'adresse linéaire et l'adresse physique ont une taille 4G. En effet, les adresses linéaires sont virtualisées par la technologie de stockage virtuel.
Le stockage virtuel est une technologie de gestion de la mémoire. L'utilisation de cette technologie peut nous donner l'illusion que l'espace mémoire est beaucoup plus grand que la capacité réelle de la mémoire physique. Son essence est de virtualiser la mémoire, ce qui signifie que la mémoire ne peut être que de 4G. Mais vous pensez que la mémoire a 64 Go, alors pourquoi puis-je ouvrir autant d'applications ?
Le mécanisme de pagination est en fait une implémentation de la virtualisation. Dans un environnement virtualisé, une grande quantité d'espace d'adressage linéaire est mappée sur un petit morceau de mémoire physique (RAM ou ROM). Lors de la pagination, chaque segment est divisé en pages (généralement 4K) et ces pages sont stockées dans la mémoire physique ou sur disque. Le système d'exploitation gère ces pages à l'aide d'un répertoire de pages et de tables de pages. Lorsqu'un programme tente d'accéder à un emplacement d'adresse dans l'espace d'adressage linéaire, le processeur utilise le répertoire de pages et la table de pages pour convertir l'adresse linéaire en adresse physique, puis la stocke dans la mémoire physique.
Si la page actuellement consultée n'est pas dans la mémoire physique, le processeur exécutera une interruption. L'erreur générale est une exception de page. Ensuite, le système d'exploitation lira la page du disque dur dans la mémoire physique, puis continuera à exécuter l'erreur. programme à partir du point d’interruption. Le système d'exploitation échange souvent des pages, ce qui devient également un goulot d'étranglement en termes de performances.
En segmentation, la longueur de chaque segment n'est pas fixe, et la longueur maximale est de 4G tandis qu'en pagination, la taille de chaque page est fixe ; Que ce soit en mémoire physique ou sur disque, l'utilisation de pages de taille fixe est plus adaptée à la gestion de la mémoire physique tandis que le mécanisme de segmentation par blocs de taille variable est plus adapté au traitement de partitions logiques de systèmes complexes.
Bien que la segmentation et la pagination soient deux mécanismes de traduction d'adresses différents, ils sont gérés indépendamment pendant tout le processus de traduction d'adresses, et chaque processus est indépendant. Les deux mécanismes utilisent une table intermédiaire pour stocker les mappages d’entrées, mais la structure de cette table intermédiaire est différente. La table de segments existe dans l'espace d'adressage linéaire et la table de pages est stockée dans l'espace d'adressage physique.
Mécanisme de protection
80x86 dispose de deux mécanismes de protection, dont l'un permet une isolation complète entre les tâches en attribuant différents espaces d'adressage virtuels à chaque tâche. Ceci est réalisé en donnant à chaque tâche une transformation différente d'une adresse logique à une adresse physique. Chaque application ne peut accéder aux données et aux instructions que dans son propre espace virtuel, et ne peut obtenir l'adresse physique que via son propre mappage. protéger les segments de mémoire du système d'exploitation et certains registres spéciaux contre l'accès des applications. Discutons de ces deux tâches en détail ci-dessous.
Protection entre les tâches
Chaque tâche sera placée séparément dans son propre espace d'adressage virtuel, puis mappée en une adresse physique via le matériel. Différentes adresses virtuelles seront converties en différentes adresses physiques, et il n'y aura pas d'adresse virtuelle de A. . L'adresse sera mappée sur la plage de l'adresse physique où se trouve B, de sorte que toutes les tâches soient isolées et que les différentes tâches n'interfèrent pas les unes avec les autres.
Chaque tâche a sa propre table de mappage, table de segments et table de pages Lorsque le processeur bascule entre différentes applications ou tâches, ces tables basculent également.
L'adresse virtuelle est une abstraction du système d'exploitation, ce qui signifie que l'adresse virtuelle est complètement abstraite par le système d'exploitation en tant que support capable de mieux gérer les applications et les tâches. Chaque tâche peut mapper une adresse logique en une adresse virtuelle, qui également. montre que chaque tâche a accès au système d'exploitation, qui est partagé par toutes les tâches. Cette partie de l'espace d'adressage virtuel où toutes les tâches ont le même espace d'adressage virtuel est appelée espace d'adressage global, et Linux utilise l'espace d'adressage global.
Chaque tâche dans l'espace d'adressage global possède son propre espace d'adressage virtuel unique. Cet espace d'adressage virtuel est appelé espace d'adressage local.
Protection spéciale des segments de mémoire et des registres
Si la protection du système d'exploitation entre différentes tâches est assimilée à une protection horizontale, alors la protection des segments de mémoire et des registres peut être considérée comme une protection verticale. Afin de restreindre l'accès à différents segments d'une tâche, le système d'exploitation définit quatre niveaux de privilèges pour protéger chaque tâche.
La priorité est divisée en 4 niveaux, 0 est le plus élevé et 3 est le plus bas. Généralement, les données les plus sensibles recevront la priorité la plus élevée, et elles ne seront accessibles que par la partie la plus fiable de la tâche. Les données les moins sensibles auront une priorité inférieure ; l'accès au système d'exploitation du noyau est généralement de niveau 0, et les données d'application l'est. généralement niveau 3. Chaque segment de mémoire est associé à un niveau de privilège.
Nous savons que le CPU obtient les instructions et les données du segment via CS pour l'exécution. Les instructions et les données obtenues du segment ont un niveau de privilège. Elles sont généralement accessibles avec le niveau de privilège actuel (Current Privilege Level est le privilège). niveau du code actif actuel. Lorsqu'une application tente d'accéder à un segment, elle est comparée à ce niveau de privilège et seuls les niveaux de privilège inférieurs à ce segment sont accessibles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Les principales différences entre Centos et Ubuntu sont: l'origine (Centos provient de Red Hat, pour les entreprises; Ubuntu provient de Debian, pour les particuliers), la gestion des packages (Centos utilise Yum, se concentrant sur la stabilité; Ubuntu utilise APT, pour une fréquence de mise à jour élevée), le cycle de support (CentOS fournit 10 ans de soutien, Ubuntu fournit un large soutien de LT tutoriels et documents), utilisations (Centos est biaisé vers les serveurs, Ubuntu convient aux serveurs et aux ordinateurs de bureau), d'autres différences incluent la simplicité de l'installation (Centos est mince)
 Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Étapes d'installation de CentOS: Téléchargez l'image ISO et Burn Bootable Media; démarrer et sélectionner la source d'installation; sélectionnez la langue et la disposition du clavier; configurer le réseau; partitionner le disque dur; définir l'horloge système; créer l'utilisateur racine; sélectionnez le progiciel; démarrer l'installation; Redémarrez et démarrez à partir du disque dur une fois l'installation terminée.
 Centos arrête la maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos arrête la maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos sera fermé en 2024 parce que sa distribution en amont, Rhel 8, a été fermée. Cette fermeture affectera le système CentOS 8, l'empêchant de continuer à recevoir des mises à jour. Les utilisateurs doivent planifier la migration et les options recommandées incluent CentOS Stream, Almalinux et Rocky Linux pour garder le système en sécurité et stable.
 Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
CentOS a été interrompu, les alternatives comprennent: 1. Rocky Linux (meilleure compatibilité); 2. Almalinux (compatible avec CentOS); 3. Serveur Ubuntu (configuration requise); 4. Red Hat Enterprise Linux (version commerciale, licence payante); 5. Oracle Linux (compatible avec Centos et Rhel). Lors de la migration, les considérations sont: la compatibilité, la disponibilité, le soutien, le coût et le soutien communautaire.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop? Docker Desktop est un outil pour exécuter des conteneurs Docker sur les machines locales. Les étapes à utiliser incluent: 1. Installer Docker Desktop; 2. Démarrer Docker Desktop; 3. Créer une image Docker (à l'aide de DockerFile); 4. Build Docker Image (en utilisant Docker Build); 5. Exécuter Docker Container (à l'aide de Docker Run).
 Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Une fois CentOS arrêté, les utilisateurs peuvent prendre les mesures suivantes pour y faire face: sélectionnez une distribution compatible: comme Almalinux, Rocky Linux et CentOS Stream. Migrez vers les distributions commerciales: telles que Red Hat Enterprise Linux, Oracle Linux. Passez à Centos 9 Stream: Rolling Distribution, fournissant les dernières technologies. Sélectionnez d'autres distributions Linux: comme Ubuntu, Debian. Évaluez d'autres options telles que les conteneurs, les machines virtuelles ou les plates-formes cloud.
 Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Vs Code Système Exigences: Système d'exploitation: Windows 10 et supérieur, MacOS 10.12 et supérieur, processeur de distribution Linux: minimum 1,6 GHz, recommandé 2,0 GHz et au-dessus de la mémoire: minimum 512 Mo, recommandée 4 Go et plus d'espace de stockage: Minimum 250 Mo, recommandée 1 Go et plus d'autres exigences: connexion du réseau stable, xorg / wayland (Linux) recommandé et recommandée et plus
