
 Périphériques technologiques
IA
L'image de votre cerveau peut désormais être restaurée en haute définition
Périphériques technologiques
IA
L'image de votre cerveau peut désormais être restaurée en haute définition
L'image de votre cerveau peut désormais être restaurée en haute définition

Ces dernières années, de grands progrès ont été réalisés dans le domaine de la génération d'images, en particulier dans la génération de texte en image : tant que nous utilisons du texte pour décrire nos pensées, l'IA peut générer des images nouvelles et réalistes.
Mais en réalité, nous pouvons aller plus loin : l'étape de conversion des idées dans l'esprit en texte peut être omise et la création d'images peut être contrôlée directement par l'activité cérébrale (comme l'enregistrement EEG (électroencéphalogramme)).
Cette méthode de génération « penser à l'image » a de larges perspectives d'application. Par exemple, il peut grandement améliorer l'efficacité de la création artistique et aider les gens à capter une inspiration éphémère ; il peut également être possible de visualiser les rêves des gens la nuit ; il peut même être utilisé en psychothérapie pour aider les enfants autistes et les patients souffrant de troubles du langage.
Récemment, des chercheurs de l'école supérieure internationale de Shenzhen de l'université Tsinghua, du Tencent AI Lab et du laboratoire Pengcheng ont publié conjointement un document de recherche sur « Penser à l'image », en utilisant des modèles texte-image pré-entraînés (tels que la diffusion stable)' Les puissantes capacités de génération de l'appareil génèrent des images de haute qualité directement à partir des signaux EEG.
 Photos
Photos
Adresse papier : https://arxiv.org/pdf/2306.16934.pdf
Adresse du projet : https://github.com/bbaaii/DreamDiffusion
Metho d aperçu
Certaines recherches récentes (telles que MinD-Vis) tentent de reconstruire des informations visuelles basées sur l'IRMf (signaux d'imagerie par résonance magnétique fonctionnelle). Ils ont démontré la faisabilité d’utiliser l’activité cérébrale pour reconstruire des résultats de haute qualité. Cependant, ces méthodes sont encore loin de l'utilisation idéale des signaux cérébraux pour une création rapide et efficace. Cela est principalement dû à deux raisons :
Premièrement, l'équipement IRMf n'est pas portable et nécessite des professionnels pour fonctionner, donc la capture des signaux IRMf est très importante. difficile ;
Deuxièmement, le coût de la collecte de données IRMf est élevé, ce qui entravera grandement l'utilisation de cette méthode dans la création artistique réelle.
En revanche, l’EEG est une méthode non invasive et peu coûteuse d’enregistrement de l’activité électrique cérébrale, et il existe désormais sur le marché des produits commerciaux portables capables d’obtenir des signaux EEG.
Mais il reste encore deux défis principaux à relever pour parvenir à la génération de « pensée en image » :
1) Les signaux EEG sont capturés par des méthodes non invasives, ils sont donc intrinsèquement bruyants. De plus, les données EEG sont limitées et les différences individuelles ne peuvent être ignorées. Alors, comment obtenir des représentations sémantiques efficaces et robustes à partir de signaux EEG sous autant de contraintes ?
2) Les espaces de texte et d'image dans Stable Diffusion sont bien alignés grâce à l'utilisation de CLIP et à la formation sur un grand nombre de paires texte-image. Cependant, les signaux EEG ont leurs propres caractéristiques et leur espace est très différent du texte et des images. Comment aligner les espaces EEG, texte et image sur des paires EEG - image limitées et bruitées ?
Pour relever le premier défi, cette étude propose d'utiliser de grandes quantités de données EEG pour entraîner les représentations EEG au lieu de seulement de rares paires d'images EEG. Cette étude utilise une méthode de modélisation de signaux masqués pour prédire les jetons manquants sur la base d'indices contextuels.
Contrairement à MAE et MinD-Vis, qui traitent l'entrée comme une image bidimensionnelle et masquent les informations spatiales, cette étude considère les caractéristiques temporelles du signal EEG et approfondit la sémantique derrière les changements temporels dans le cerveau humain. . Cette étude a bloqué aléatoirement une partie des jetons puis a reconstruit ces jetons bloqués dans le domaine temporel. De cette manière, l’encodeur pré-entraîné est capable de développer une compréhension approfondie des données EEG de différents individus et de différentes activités cérébrales.
Pour le deuxième défi, les solutions précédentes affinent généralement directement le modèle de diffusion stable, en utilisant un petit nombre de paires de données bruitées pour l'entraînement. Cependant, il est difficile d’apprendre un alignement précis entre les signaux cérébraux (par exemple, EEG et IRMf) et l’espace de texte en ajustant uniquement la SD de bout en bout jusqu’à la perte finale de reconstruction de l’image. Par conséquent, l’équipe de recherche a proposé d’utiliser une supervision CLIP supplémentaire pour aider à obtenir l’alignement des espaces EEG, texte et image.
Plus précisément, SD lui-même utilise l'encodeur de texte de CLIP pour générer des intégrations de texte, ce qui est très différent des intégrations EEG pré-entraînées masquées de l'étape précédente. Tirez parti de l'encodeur d'image de CLIP pour extraire des intégrations d'images riches qui sont bien alignées avec les intégrations de texte de CLIP. Ces intégrations d'images CLIP ont ensuite été utilisées pour affiner davantage la représentation de l'intégration EEG. Par conséquent, les intégrations améliorées des fonctionnalités EEG peuvent être bien alignées avec les intégrations d'images et de texte de CLIP et sont plus adaptées à la génération d'images SD, améliorant ainsi la qualité des images générées.
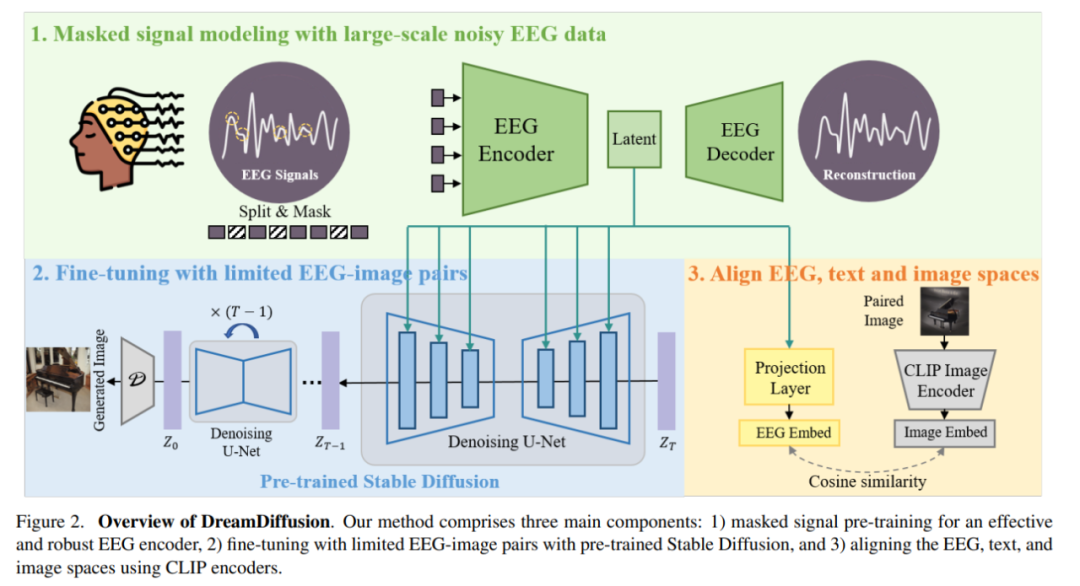
Basée sur les deux solutions soigneusement conçues ci-dessus, cette recherche propose une nouvelle méthode DreamDiffusion. DreamDiffusion génère des images réalistes et de haute qualité à partir de signaux d'électroencéphalogramme (EEG).
 Photos
Photos
Plus précisément, DreamDiffusion se compose principalement de trois parties :
1) Pré-entraînement au signal de masque pour obtenir un encodeur EEG efficace et robuste
2) Utiliser un pré-entraînement stable ; Diffusion et paires d'images EEG limitées pour un réglage fin ;
3) Utilisez l'encodeur CLIP pour aligner les espaces EEG, texte et image.
Tout d'abord, les chercheurs ont utilisé des données EEG avec beaucoup de bruit et ont utilisé la modélisation du signal de masque pour entraîner l'encodeur EEG et extraire des connaissances contextuelles. L'encodeur EEG résultant est ensuite utilisé pour fournir des caractéristiques conditionnelles pour une diffusion stable via un mécanisme d'attention croisée.
 Photos
Photos
Pour améliorer la compatibilité des fonctionnalités EEG avec la diffusion stable, les chercheurs ont davantage aligné l'EEG, le texte et l'image en réduisant la distance entre l'intégration EEG et l'intégration de l'image CLIP pendant le réglage fin processus.
Expériences et analyses
Comparaison avec Brain2Image
Les chercheurs ont comparé la méthode présentée dans cet article avec Brain2Image. Brain2Image utilise des modèles génératifs traditionnels, à savoir des auto-encodeurs variationnels (VAE) et des réseaux contradictoires génératifs (GAN), pour la conversion de l'EEG en images. Cependant, Brain2Image ne fournit que des résultats pour quelques catégories et ne fournit pas d'implémentation de référence.
Dans cet esprit, cette étude a effectué une comparaison qualitative de plusieurs catégories présentées dans l'article Brain2Image (c'est-à-dire les avions, les citrouilles-lanternes et les pandas). Pour garantir une comparaison équitable, les chercheurs ont utilisé la même stratégie d'évaluation que celle décrite dans l'article Brain2Image et montrent les résultats générés par les différentes méthodes dans la figure 5 ci-dessous.
La première ligne de la figure ci-dessous montre les résultats générés par Brain2Image, et la dernière ligne est générée par DreamDiffusion, la méthode proposée par les chercheurs. On constate que la qualité de l'image générée par DreamDiffusion est nettement supérieure à celle générée par Brain2Image, ce qui vérifie également l'efficacité de cette méthode.
 Photos
Photos
Expérience d'ablation
Le rôle de la pré-entraînement : Pour démontrer l'efficacité de la pré-entraînement des données EEG à grande échelle, cette étude a utilisé des encodeurs non entraînés pour entraîner Validez plusieurs modèles. L'un des modèles était identique au modèle complet, tandis que l'autre modèle ne comportait que deux couches de codage EEG pour éviter un surajustement des données. Au cours du processus de formation, les deux modèles ont été formés avec/sans supervision CLIP, et les résultats sont présentés dans les colonnes 1 à 4 du modèle dans le tableau 1. On peut constater que la précision du modèle sans pré-entraînement est réduite.
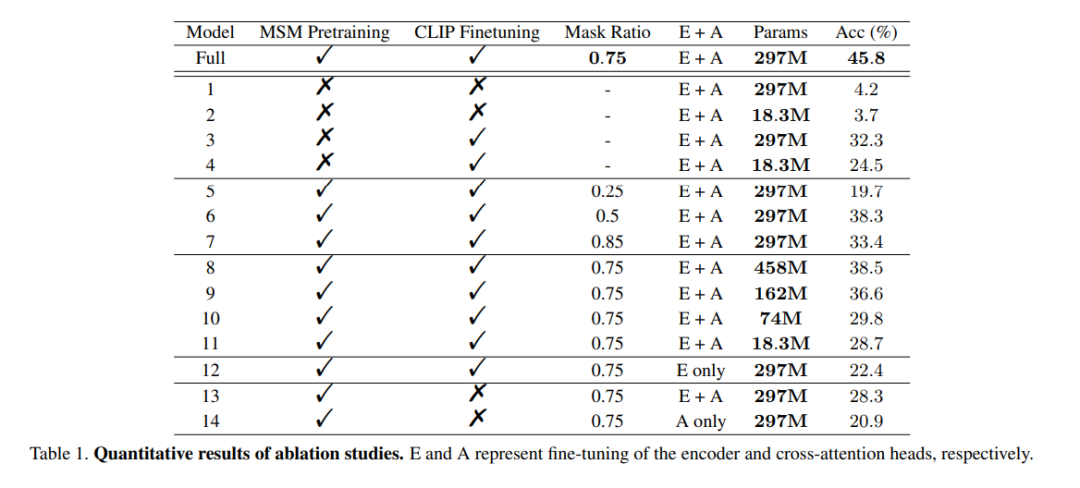
rapport de masque : Cet article étudie également l'utilisation des données EEG pour déterminer le rapport de masque optimal pour la pré-entraînement des HSH. Comme le montrent les colonnes 5 à 7 du modèle du tableau 1, un rapport de masque trop élevé ou trop faible peut nuire aux performances du modèle. La précision globale la plus élevée est obtenue lorsque le rapport de masque est de 0,75. Cette découverte est cruciale car elle suggère que, contrairement au traitement du langage naturel, qui utilise généralement de faibles ratios de masque, des ratios de masque élevés constituent un meilleur choix lors de la réalisation de MSM sur EEG.
Alignement CLIP : L'une des clés de cette méthode est d'aligner la représentation EEG sur l'image via un encodeur CLIP. Cette étude a mené des expériences pour vérifier l'efficacité de cette méthode, et les résultats sont présentés dans le tableau 1. On peut observer que les performances du modèle chutent considérablement lorsque la supervision CLIP n'est pas utilisée. En fait, comme le montre le coin inférieur droit de la figure 6, l'utilisation de CLIP pour aligner les caractéristiques EEG peut toujours donner des résultats raisonnables même sans pré-entraînement, ce qui souligne l'importance de la supervision CLIP dans cette méthode.
 photos
photos
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 phpmyadmin crée un tableau de données
Apr 10, 2025 pm 11:00 PM
phpmyadmin crée un tableau de données
Apr 10, 2025 pm 11:00 PM
Pour créer un tableau de données à l'aide de PhpMyAdmin, les étapes suivantes sont essentielles: connectez-vous à la base de données et cliquez sur le nouvel onglet. Nommez le tableau et sélectionnez le moteur de stockage (InnODB recommandé). Ajouter les détails de la colonne en cliquant sur le bouton Ajouter une colonne, y compris le nom de la colonne, le type de données, s'il faut autoriser les valeurs nuls et d'autres propriétés. Sélectionnez une ou plusieurs colonnes comme clés principales. Cliquez sur le bouton Enregistrer pour créer des tables et des colonnes.
 Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:33 PM
Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:33 PM
La création d'une base de données Oracle n'est pas facile, vous devez comprendre le mécanisme sous-jacent. 1. Vous devez comprendre les concepts de la base de données et des SGBD Oracle; 2. Master les concepts de base tels que SID, CDB (base de données de conteneurs), PDB (base de données enfichable); 3. Utilisez SQL * Plus pour créer CDB, puis créer PDB, vous devez spécifier des paramètres tels que la taille, le nombre de fichiers de données et les chemins; 4. Les applications avancées doivent ajuster le jeu de caractères, la mémoire et d'autres paramètres et effectuer un réglage des performances; 5. Faites attention à l'espace disque, aux autorisations et aux paramètres des paramètres, et surveillez et optimisez en continu les performances de la base de données. Ce n'est qu'en le maîtrisant habilement une pratique continue que vous pouvez vraiment comprendre la création et la gestion des bases de données Oracle.
 Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:36 PM
Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:36 PM
Pour créer une base de données Oracle, la méthode commune consiste à utiliser l'outil graphique DBCA. Les étapes sont les suivantes: 1. Utilisez l'outil DBCA pour définir le nom DBN pour spécifier le nom de la base de données; 2. Définissez Syspassword et SystemPassword sur des mots de passe forts; 3. Définir les caractères et NationalCharacterset à Al32Utf8; 4. Définissez la taille de mémoire et les espaces de table pour s'ajuster en fonction des besoins réels; 5. Spécifiez le chemin du fichier log. Les méthodes avancées sont créées manuellement à l'aide de commandes SQL, mais sont plus complexes et sujets aux erreurs. Faites attention à la force du mot de passe, à la sélection du jeu de caractères, à la taille et à la mémoire de l'espace de table
 Comment rédiger des instructions de base de données Oracle
Apr 11, 2025 pm 02:42 PM
Comment rédiger des instructions de base de données Oracle
Apr 11, 2025 pm 02:42 PM
Le cœur des instructions Oracle SQL est sélectionné, insérer, mettre à jour et supprimer, ainsi que l'application flexible de diverses clauses. Il est crucial de comprendre le mécanisme d'exécution derrière l'instruction, tel que l'optimisation de l'indice. Les usages avancés comprennent des sous-requêtes, des requêtes de connexion, des fonctions d'analyse et PL / SQL. Les erreurs courantes incluent les erreurs de syntaxe, les problèmes de performances et les problèmes de cohérence des données. Les meilleures pratiques d'optimisation des performances impliquent d'utiliser des index appropriés, d'éviter la sélection *, d'optimiser les clauses et d'utiliser des variables liées. La maîtrise d'Oracle SQL nécessite de la pratique, y compris l'écriture de code, le débogage, la réflexion et la compréhension des mécanismes sous-jacents.
 Comment ajouter, modifier et supprimer le guide de fonctionnement du champ de table de données MySQL
Apr 11, 2025 pm 05:42 PM
Comment ajouter, modifier et supprimer le guide de fonctionnement du champ de table de données MySQL
Apr 11, 2025 pm 05:42 PM
Guide de fonctionnement du champ dans MySQL: Ajouter, modifier et supprimer les champs. Ajouter un champ: alter table table_name Ajouter Column_name data_type [pas null] [Default default_value] [Clé primaire] [Auto_increment] Modifier le champ: alter table table_name modifie Column_name data_type [pas null] [default default_value] [clé primaire]
 Quelles sont les contraintes d'intégrité des tables de base de données Oracle?
Apr 11, 2025 pm 03:42 PM
Quelles sont les contraintes d'intégrité des tables de base de données Oracle?
Apr 11, 2025 pm 03:42 PM
Les contraintes d'intégrité des bases de données Oracle peuvent garantir la précision des données, notamment: Not Null: les valeurs nulles sont interdites; Unique: garantie l'unicité, permettant une seule valeur nulle; Clé primaire: contrainte de clé primaire, renforcer unique et interdire les valeurs nulles; Clé étrangère: maintenir les relations entre les tableaux, les clés étrangères se réfèrent aux clés primaires primaires; Vérifiez: limitez les valeurs de colonne en fonction des conditions.
 Explication détaillée des instances de requête imbriquées dans la base de données MySQL
Apr 11, 2025 pm 05:48 PM
Explication détaillée des instances de requête imbriquées dans la base de données MySQL
Apr 11, 2025 pm 05:48 PM
Les requêtes imbriquées sont un moyen d'inclure une autre requête dans une requête. Ils sont principalement utilisés pour récupérer des données qui remplissent des conditions complexes, associer plusieurs tables et calculer des valeurs de résumé ou des informations statistiques. Les exemples incluent la recherche de salaires supérieurs aux employés, la recherche de commandes pour une catégorie spécifique et le calcul du volume des commandes totales pour chaque produit. Lorsque vous écrivez des requêtes imbriquées, vous devez suivre: écrire des sous-requêtes, écrire leurs résultats sur les requêtes extérieures (référencées avec des alias ou en tant que clauses) et optimiser les performances de la requête (en utilisant des index).
 Comment les journaux Tomcat aident à dépanner les fuites de mémoire
Apr 12, 2025 pm 11:42 PM
Comment les journaux Tomcat aident à dépanner les fuites de mémoire
Apr 12, 2025 pm 11:42 PM
Les journaux TomCat sont la clé pour diagnostiquer les problèmes de fuite de mémoire. En analysant les journaux TomCat, vous pouvez avoir un aperçu de l'utilisation de la mémoire et du comportement de collecte des ordures (GC), localiser et résoudre efficacement les fuites de mémoire. Voici comment dépanner les fuites de mémoire à l'aide des journaux Tomcat: 1. Analyse des journaux GC d'abord, activez d'abord la journalisation GC détaillée. Ajoutez les options JVM suivantes aux paramètres de démarrage TomCat: -xx: printgcdetails-xx: printgcdatestamps-xloggc: gc.log Ces paramètres généreront un journal GC détaillé (GC.Log), y compris des informations telles que le type GC, la taille et le temps des objets de recyclage. Analyse GC.Log
