
 base de données
tutoriel mysql
MySQL vs PostgreSQL : avantages et inconvénients des bases de données Open Source
base de données
tutoriel mysql
MySQL vs PostgreSQL : avantages et inconvénients des bases de données Open Source
MySQL vs PostgreSQL : avantages et inconvénients des bases de données Open Source

MySQL et PostgreSQL : avantages et inconvénients des bases de données Open Source
Introduction :
À l'ère d'Internet d'aujourd'hui, le traitement et la gestion des données sont devenus un élément incontournable. En tant qu’outil de stockage et de gestion de données, le choix de la base de données est crucial pour les développeurs et les entreprises. Parmi les bases de données open source, MySQL et PostgreSQL sont deux choix de premier plan. Cet article explorera les avantages et les inconvénients de MySQL et PostgreSQL sous de nombreux aspects, et joindra quelques exemples de code.
1. Avantages de MySQL :
- Excellentes performances : MySQL est réputé pour ses hautes performances et est une base de données adaptée à de nombreux scénarios d'applications à haute concurrence. Il a d’excellentes vitesses de lecture et d’écriture et des temps de réponse.
Exemple de code :
SELECT * FROM users WHERE age > 18;
- Simple et facile à utiliser : MySQL a une courbe d'apprentissage douce, ce qui permet aux débutants de démarrer plus facilement. Sa syntaxe est concise et facile à comprendre et à utiliser.
Exemple de code :
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
age INT
);- Grande communauté de support : MySQL dispose d'une grande communauté d'utilisateurs et de développeurs qui peuvent fournir des ressources abondantes et un support technique. Cela signifie que vous pouvez facilement trouver des solutions et des réponses aux problèmes que vous rencontrez.
Exemple de code :
SELECT COUNT(*) FROM users;
2. Inconvénients de MySQL :
- Support relativement faible pour les requêtes complexes : Par rapport à PostgreSQL, MySQL est légèrement insuffisant pour prendre en charge les requêtes complexes. Il lui manque certaines fonctionnalités avancées par rapport à d’autres bases de données.
Exemple de code :
SELECT * FROM users JOIN orders ON users.id = orders.user_id WHERE users.age > 18 AND orders.status = 'completed';
- Problème de cohérence des données : MySQL utilise un moteur "sans verrouillage" par défaut, ce qui signifie qu'une incohérence des données peut se produire dans certains scénarios à forte concurrence et que les développeurs doivent les gérer eux-mêmes.
Échantillon de code :
START TRANSACTION; UPDATE users SET age = 20 WHERE id = 1; UPDATE users SET age = 30 WHERE id = 1; COMMIT;
3. Avantages de PostgreSQL :
- Prise en charge puissante des types de données : PostgreSQL dispose d'une variété de types de données puissants, tels que les tableaux, JSON, UUID, etc., rendant le stockage et les requêtes non structurés et semi-structurés. -structured Les données structurées deviennent plus flexibles et plus pratiques.
Exemple de code :
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(50),
emails TEXT[]
);- Prise en charge des transactions ACID : PostgreSQL est une base de données qui prend en charge les transactions ACID, qui peuvent garantir la cohérence, l'atomicité, l'isolement et la durabilité des données, et convient aux applications ayant des exigences élevées en matière d'intégrité des données. Scénarios d'application.
Exemple de code :
BEGIN;
INSERT INTO users (name) VALUES ('Alice');
INSERT INTO orders (user_id, amount) VALUES (1, 100);
COMMIT;- Prise en charge des requêtes complexes et des fonctions avancées : PostgreSQL fournit une prise en charge puissante des requêtes complexes, telles que les jointures multi-tables, les sous-requêtes, les fonctions de fenêtre, etc. Il dispose également de fonctionnalités plus avancées telles que la recherche en texte intégral, le système d’information géographique, etc.
Exemple de code :
SELECT * FROM users JOIN orders ON users.id = orders.user_id WHERE users.age > 18 AND orders.status = 'completed';
4. Inconvénients de PostgreSQL :
- Faibles performances : par rapport à MySQL, PostgreSQL a des performances inférieures dans le traitement de données à grande échelle et de scénarios de concurrence élevée. Ses vitesses de lecture et d'écriture et ses temps de réponse sont généralement plus lents que MySQL.
Exemple de code :
SELECT * FROM users WHERE age > 18;
- Courbe d'apprentissage raide : par rapport à MySQL, PostgreSQL a une courbe d'apprentissage plus raide et nécessite plus d'apprentissage et de compréhension. Sa syntaxe complexe et ses fonctionnalités avancées peuvent être difficiles pour les débutants.
Exemple de code :
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(50),
age INT
);Conclusion :
MySQL et PostgreSQL sont deux bases de données open source, chacune avec ses propres avantages et inconvénients. MySQL convient à la plupart des scénarios d'application simples, et ses performances exceptionnelles et sa facilité d'utilisation en font le premier choix des développeurs. PostgreSQL convient aux scénarios nécessitant une prise en charge solide des types de données et des requêtes complexes, et fournit des transactions ACID pour garantir la cohérence des données. Par conséquent, un jugement doit être fait en fonction des besoins spécifiques de l’entreprise et des exigences de performance avant la sélection.
Exemples de code :
SELECT COUNT(*) FROM users;
Résumé :
En menant une discussion approfondie sur les avantages et les inconvénients de MySQL et PostgreSQL, et en joignant quelques exemples de code, j'espère que cela vous aidera à choisir une base de données open source et à comprendre les différences entre bases de données aider. Quelle que soit la base de données que vous choisissez, vous devez faire un choix approprié en fonction de vos besoins spécifiques et de vos scénarios réels.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Fraichement publié! Un modèle open source pour générer des images de style anime en un seul clic
Apr 08, 2024 pm 06:01 PM
Fraichement publié! Un modèle open source pour générer des images de style anime en un seul clic
Apr 08, 2024 pm 06:01 PM
Permettez-moi de vous présenter le dernier projet open source AIGC-AnimagineXL3.1. Ce projet est la dernière itération du modèle texte-image sur le thème de l'anime, visant à offrir aux utilisateurs une expérience de génération d'images d'anime plus optimisée et plus puissante. Dans AnimagineXL3.1, l'équipe de développement s'est concentrée sur l'optimisation de plusieurs aspects clés pour garantir que le modèle atteigne de nouveaux sommets en termes de performances et de fonctionnalités. Premièrement, ils ont élargi les données d’entraînement pour inclure non seulement les données des personnages du jeu des versions précédentes, mais également les données de nombreuses autres séries animées bien connues dans l’ensemble d’entraînement. Cette décision enrichit la base de connaissances du modèle, lui permettant de mieux comprendre les différents styles et personnages d'anime. AnimagineXL3.1 introduit un nouvel ensemble de balises et d'esthétiques spéciales
 Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Le FP8 et la précision de quantification inférieure en virgule flottante ne sont plus le « brevet » du H100 ! Lao Huang voulait que tout le monde utilise INT8/INT4, et l'équipe Microsoft DeepSpeed a commencé à exécuter FP6 sur A100 sans le soutien officiel de NVIDIA. Les résultats des tests montrent que la quantification FP6 de la nouvelle méthode TC-FPx sur A100 est proche ou parfois plus rapide que celle de INT4, et a une précision supérieure à celle de cette dernière. En plus de cela, il existe également une prise en charge de bout en bout des grands modèles, qui ont été open source et intégrés dans des cadres d'inférence d'apprentissage profond tels que DeepSpeed. Ce résultat a également un effet immédiat sur l'accélération des grands modèles : dans ce cadre, en utilisant une seule carte pour exécuter Llama, le débit est 2,65 fois supérieur à celui des cartes doubles. un
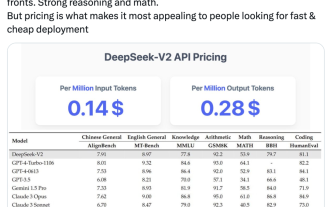 Les indicateurs du MoE open source national explosent : capacités de niveau GPT-4, le prix de l'API n'est que de 1 %
May 07, 2024 pm 05:34 PM
Les indicateurs du MoE open source national explosent : capacités de niveau GPT-4, le prix de l'API n'est que de 1 %
May 07, 2024 pm 05:34 PM
Le dernier modèle open source national à grande échelle du MoE est devenu populaire juste après ses débuts. Les performances de DeepSeek-V2 atteignent le niveau GPT-4, mais il est open source, gratuit pour un usage commercial et le prix de l'API ne représente que 1 % de celui de GPT-4-Turbo. Par conséquent, dès sa sortie, il a immédiatement déclenché de nombreuses discussions. À en juger par les indicateurs de performance publiés, les capacités chinoises complètes de DeepSeekV2 dépassent celles de nombreux modèles open source. Dans le même temps, les modèles fermés tels que GPT-4Turbo et Wenkuai 4.0 sont également au premier échelon. La maîtrise complète de l'anglais se situe également au même premier échelon que LLaMA3-70B et surpasse Mixtral8x22B, qui est également un MoE. Il montre également de bonnes performances en connaissances, mathématiques, raisonnement, programmation, etc. Et prend en charge le contexte 128K. Imaginez ceci
 Partagez plusieurs frameworks de projets open source .NET liés à l'IA et au LLM
May 06, 2024 pm 04:43 PM
Partagez plusieurs frameworks de projets open source .NET liés à l'IA et au LLM
May 06, 2024 pm 04:43 PM
Le développement des technologies d’intelligence artificielle (IA) bat son plein aujourd’hui et elles ont montré un grand potentiel et une grande influence dans divers domaines. Aujourd'hui, Dayao partagera avec vous 4 cadres de projets liés au modèle d'IA open source .NET LLM, dans l'espoir de vous fournir une référence. https://github.com/YSGStudyHards/DotNetGuide/blob/main/docs/DotNet/DotNetProjectPicks.mdSemanticKernelSemanticKernel est un kit de développement logiciel (SDK) open source conçu pour intégrer de grands modèles de langage (LLM) tels qu'OpenAI, Azure
 Comment Hibernate implémente-t-il le mappage polymorphe ?
Apr 17, 2024 pm 12:09 PM
Comment Hibernate implémente-t-il le mappage polymorphe ?
Apr 17, 2024 pm 12:09 PM
Le mappage polymorphe Hibernate peut mapper les classes héritées à la base de données et fournit les types de mappage suivants : join-subclass : crée une table séparée pour la sous-classe, incluant toutes les colonnes de la classe parent. table par classe : créez une table distincte pour les sous-classes, contenant uniquement des colonnes spécifiques aux sous-classes. union-subclass : similaire à join-subclass, mais la table de classe parent réunit toutes les colonnes de la sous-classe.
 iOS 18 ajoute une nouvelle fonction d'album 'Récupéré' pour récupérer les photos perdues ou endommagées
Jul 18, 2024 am 05:48 AM
iOS 18 ajoute une nouvelle fonction d'album 'Récupéré' pour récupérer les photos perdues ou endommagées
Jul 18, 2024 am 05:48 AM
Les dernières versions d'Apple des systèmes iOS18, iPadOS18 et macOS Sequoia ont ajouté une fonctionnalité importante à l'application Photos, conçue pour aider les utilisateurs à récupérer facilement des photos et des vidéos perdues ou endommagées pour diverses raisons. La nouvelle fonctionnalité introduit un album appelé "Récupéré" dans la section Outils de l'application Photos qui apparaîtra automatiquement lorsqu'un utilisateur a des photos ou des vidéos sur son appareil qui ne font pas partie de sa photothèque. L'émergence de l'album « Récupéré » offre une solution aux photos et vidéos perdues en raison d'une corruption de la base de données, d'une application d'appareil photo qui n'enregistre pas correctement dans la photothèque ou d'une application tierce gérant la photothèque. Les utilisateurs n'ont besoin que de quelques étapes simples
 Une analyse approfondie de la façon dont HTML lit la base de données
Apr 09, 2024 pm 12:36 PM
Une analyse approfondie de la façon dont HTML lit la base de données
Apr 09, 2024 pm 12:36 PM
HTML ne peut pas lire directement la base de données, mais cela peut être réalisé via JavaScript et AJAX. Les étapes comprennent l'établissement d'une connexion à la base de données, l'envoi d'une requête, le traitement de la réponse et la mise à jour de la page. Cet article fournit un exemple pratique d'utilisation de JavaScript, AJAX et PHP pour lire les données d'une base de données MySQL, montrant comment afficher dynamiquement les résultats d'une requête dans une page HTML. Cet exemple utilise XMLHttpRequest pour établir une connexion à la base de données, envoyer une requête et traiter la réponse, remplissant ainsi les données dans les éléments de la page et réalisant la fonction de lecture HTML de la base de données.
 Le modèle de code open source aiXcoder-7B le plus puissant de l'Université de Pékin ! Concentrez-vous sur des scénarios de développement réels et conçus spécifiquement pour le déploiement privé en entreprise
Apr 09, 2024 pm 06:10 PM
Le modèle de code open source aiXcoder-7B le plus puissant de l'Université de Pékin ! Concentrez-vous sur des scénarios de développement réels et conçus spécifiquement pour le déploiement privé en entreprise
Apr 09, 2024 pm 06:10 PM
À en juger par les derniers développements dans le cercle technologique, le concept de génération de code IA est devenu populaire récemment. Cependant, mes amis, pensez-vous que les questions de programmation de l'IA sont plus accrocheuses, mais lorsqu'il s'agit de scénarios réels de développement d'entreprise, vous avez toujours l'impression que cela ne suffit pas ? À ce moment-là, un acteur senior discret, aiXcoder, a pris des mesures et a lancé un grand pas en avant : il s'agit d'un nouveau modèle de code open source-aiXcoder-7BBase, un modèle de code spécifiquement adapté au déploiement dans des scénarios de développement de logiciels d'entreprise. Attendez, quel type de niveau de programmation de l'IA un grand modèle de code avec « seulement » 7 milliards de paramètres peut-il montrer ? Jetons d'abord un coup d'œil à ses performances sur les trois ensembles d'évaluation principaux de HumanEval, MBPP et MultiPL-E. Son score moyen dépasse en fait celui de Co, qui compte 34 milliards de paramètres.
