
 Périphériques technologiques
IA
BLIP-2 et InstructBLIP sont fermement dans le top trois ! Douze modèles majeurs, seize listes, évaluation complète du « grand modèle de langage multimodal »
Périphériques technologiques
IA
BLIP-2 et InstructBLIP sont fermement dans le top trois ! Douze modèles majeurs, seize listes, évaluation complète du « grand modèle de langage multimodal »
BLIP-2 et InstructBLIP sont fermement dans le top trois ! Douze modèles majeurs, seize listes, évaluation complète du « grand modèle de langage multimodal »

Le modèle multimodal de langage étendu (MLLM) s'appuie sur la riche réserve de connaissances de LLM et sur ses puissantes capacités de raisonnement et de généralisation pour résoudre des problèmes multimodaux. Certaines capacités étonnantes ont émergé, telles que regarder des images et écrire, regarder des images et écrire du code.
Mais il est difficile de refléter pleinement les performances du MLLM sur la base de ces seuls exemples, et il manque encore une évaluation complète du MLLM.
À cette fin, Tencent Youtu Lab et l'Université de Xiamen ont mené pour la première fois une évaluation quantitative complète de 12 modèles MLLM open source existants sur le nouveau référentiel d'évaluation MM et ont publié 16 classements, incluant à la fois la perception et la cognition. et 14 sous-listes :

Lien papier : https://arxiv.org/pdf/2306.13394.pdf
Lien du projet : https://github.com/BradyFU/Awesome -Multimodal- Large-Language-Models/tree/Evaluation
Les méthodes d'évaluation quantitative existantes du MLLM sont principalement divisées en trois catégories, mais elles présentent toutes certaines limites qui rendent difficile de refléter pleinement leurs performances.
La première catégorie de méthodes est évaluée sur des ensembles de données publics traditionnels, tels que les ensembles de données de légende d'image et de réponse visuelle aux questions (VQA).
Mais d'une part, ces ensembles de données traditionnels peuvent ne pas être en mesure de refléter les nouvelles capacités émergentes du MLLM. D'autre part, étant donné que les ensembles de formation à l'ère des grands modèles ne sont plus unifiés, il est difficile de le faire. garantir que ces ensembles de données d’évaluation n’ont pas été formés par d’autres MLLM.
La deuxième méthode consiste à collecter de nouvelles données pour une évaluation ouverte, mais ces données ne sont pas publiques [1] ou leur nombre est trop petit (seulement 50 images) [2].
La troisième méthode se concentre sur un aspect spécifique du MLLM, comme l'hallucination d'objet [3] ou la robustesse contradictoire [4], et ne peut pas être entièrement évaluée.
Il existe un besoin urgent d'un référentiel d'évaluation complet pour correspondre au développement rapide du MLLM. Les chercheurs estiment qu'un référentiel d'évaluation complet et universel devrait avoir les caractéristiques suivantes :
(1) Il devrait couvrir autant de champ d'application que possible, y compris la perception et les capacités cognitives. Le premier fait référence à l’identification des objets, notamment leur existence, leur quantité, leur emplacement et leur couleur. Ce dernier fait référence à l'intégration d'informations sensorielles et de connaissances dans le LLM pour effectuer un raisonnement plus complexe. Le premier est la base du second.
(2) Les données ou annotations doivent éviter autant que possible d'utiliser des ensembles de données publiques existantes afin de réduire le risque de fuite de données.
(3) Les instructions doivent être aussi concises que possible et cohérentes avec les habitudes cognitives humaines. Différentes conceptions d'instructions peuvent grandement affecter le résultat du modèle, mais tous les modèles sont évalués selon des instructions unifiées et concises pour garantir l'équité. Un bon modèle MLLM doit avoir la capacité de généraliser à des instructions aussi concises pour éviter de tomber dans une ingénierie rapide.
(4) La sortie de MLLM sous cette instruction concise doit être intuitive et pratique pour les statistiques quantitatives. Les réponses ouvertes du MLLM posent de grands défis aux statistiques quantitatives. Les méthodes existantes ont tendance à utiliser le GPT ou la notation manuelle, mais peuvent se heurter à des problèmes d'inexactitude et de subjectivité.
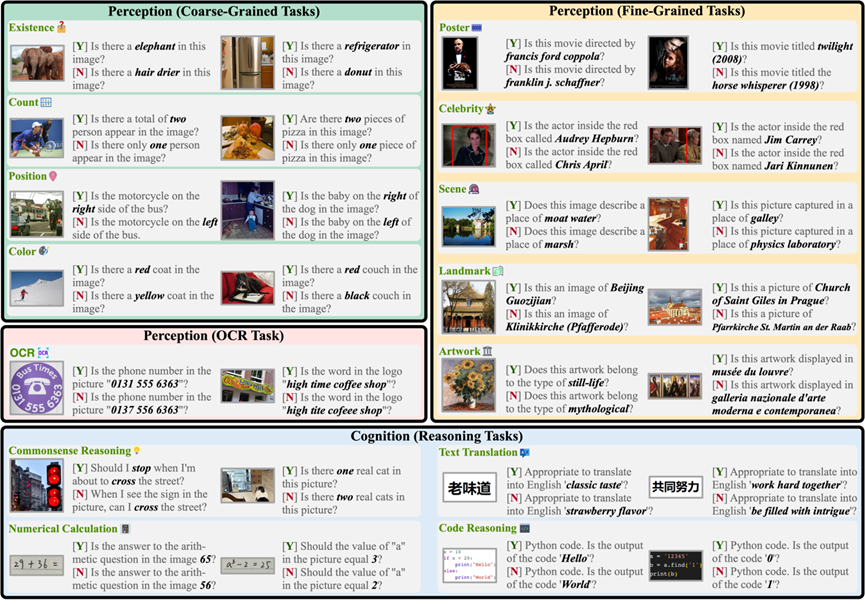
Figure 1. Exemple de référence d'évaluation MME. Chaque image correspond à deux questions, et les réponses sont respectivement Oui[O] et Non[N]. La question et « Veuillez répondre par oui ou par non » forment ensemble la commande.
Sur la base des raisons ci-dessus, un nouveau référentiel d'évaluation MLLM MME a été construit, qui présente simultanément les quatre caractéristiques ci-dessus :
1 MME évalue à la fois la perception et les capacités cognitives. En plus de l'OCR, les capacités de détection incluent la reconnaissance de cibles à gros grain et à grain fin. Le premier identifie la présence, la quantité, l’emplacement et la couleur des objets. Ce dernier identifie les affiches de films, les célébrités, les scènes, les monuments et les œuvres d'art. Les capacités cognitives comprennent le raisonnement de bon sens, les calculs numériques, la traduction de texte et le raisonnement codé. Le nombre total de sous-tâches atteint 14, comme le montre la figure 1.
2. Toutes les paires commande-réponse dans MME sont construites manuellement. Pour les quelques ensembles de données accessibles au public utilisés, seules leurs images ont été utilisées sans s'appuyer sur leurs annotations originales. Dans le même temps, les chercheurs font également de leur mieux pour collecter des données grâce à la photographie manuelle et à la génération d’images.
3. Les instructions MME sont conçues pour être aussi concises que possible afin d'éviter l'impact de Prompt Engineering sur la sortie du modèle. Les chercheurs réitèrent qu'un bon MLLM devrait généraliser à des instructions aussi concises et fréquemment utilisées, ce qui est juste pour tous les modèles. Les instructions pour chaque sous-tâche sont présentées dans la figure 1.
4. Grâce à la conception de la commande « Veuillez répondre par oui ou par non », des statistiques quantitatives peuvent être facilement réalisées sur la base de la sortie « Oui » ou « Non » du modèle. Cette méthode peut garantir à la fois précision et objectivité. temps. Il convient de noter que les chercheurs ont également essayé de concevoir des instructions pour les questions à choix multiples, mais ont constaté qu'il est encore difficile de suivre des instructions aussi complexes dans le MLLM actuel.
Les chercheurs ont évalué un total de 12 modèles MLLM avancés, dont BLIP-2 [5], LLaVA [6], MiniGPT-4 [7], mPLUG-Owl [2], LLaMA-Adapter-v2 [8] ] , Otter [9], Multimodal-GPT [10], InstructBLIP [11], VisualGLM-6B [12], PandaGPT [13], ImageBind-LLM [14] et LaVIN [15].
Parmi eux, il existe trois indicateurs statistiques, dont Accuracy, Accuracy+ et Score. Pour chaque tâche, la précision est basée sur les statistiques des questions, la précision+ est basée sur les statistiques des images (les deux questions correspondant aux images doivent recevoir une réponse correcte) et le score est la somme de la précision et de la précision+.
Le score total de perception est la somme des scores de 10 sous-tâches perceptuelles, et le score total de cognition est la somme des scores de 4 tâches cognitives. Voir le lien du projet pour plus de détails.
La comparaison des tests de 12 modèles sur 14 sous-tâches est présentée dans la figure 2 :
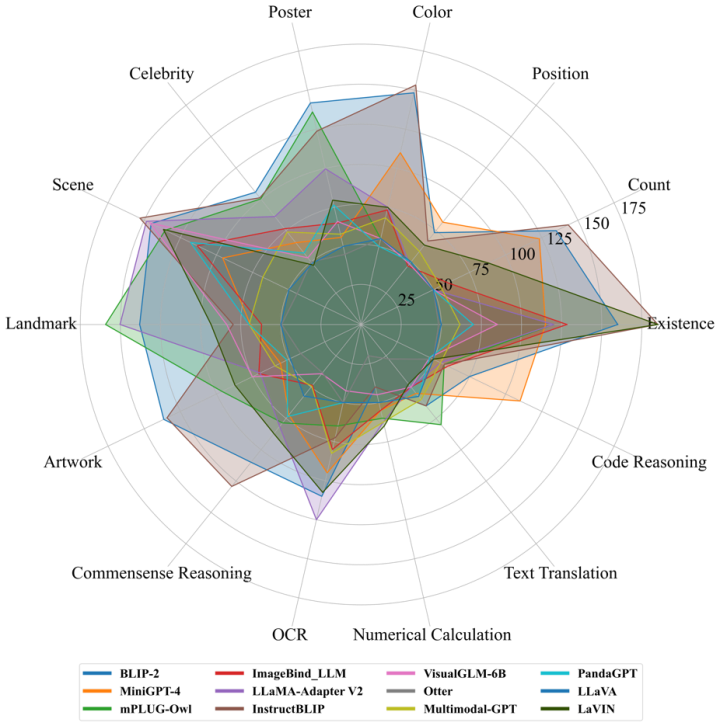
Figure 2. Comparaison de 12 modèles sur 14 sous-tâches. Le score total pour chaque sous-tâche est de 200 points.
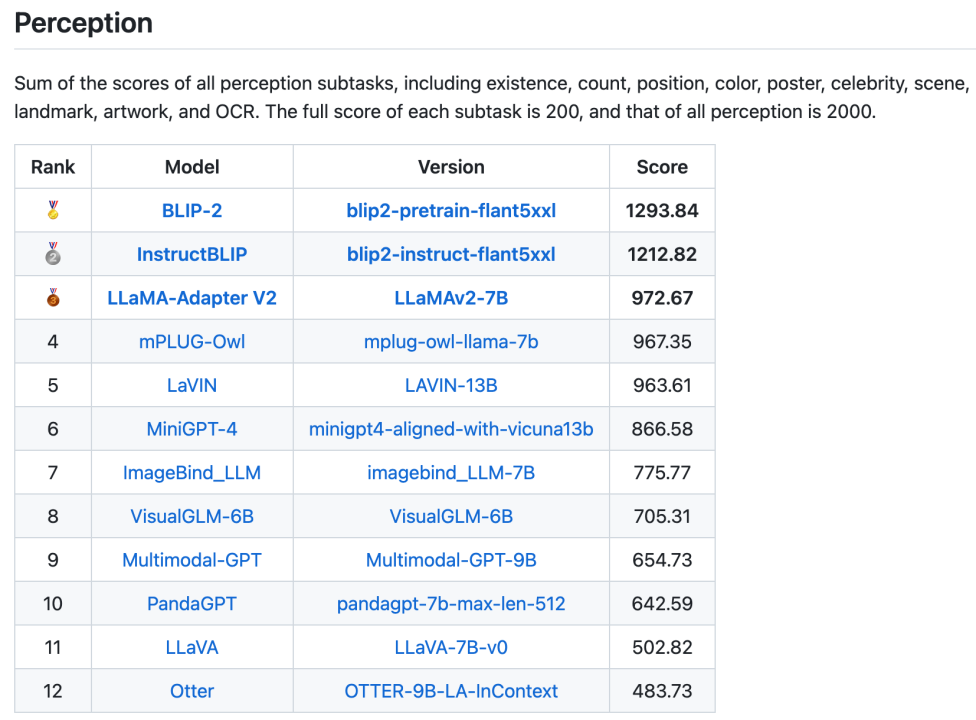
Au total, 16 listes, comprenant la liste globale des catégories de perception et de cognition et les listes de 14 sous-tâches, ont également été publiées. Les deux listes globales sont présentées respectivement dans les figures 3 et 4. Il convient de noter que BLIP-2 et InstructBLIP restent parmi les trois premiers des deux listes.
 Photos
Photos
Figure 3. Liste totale des tâches de perception
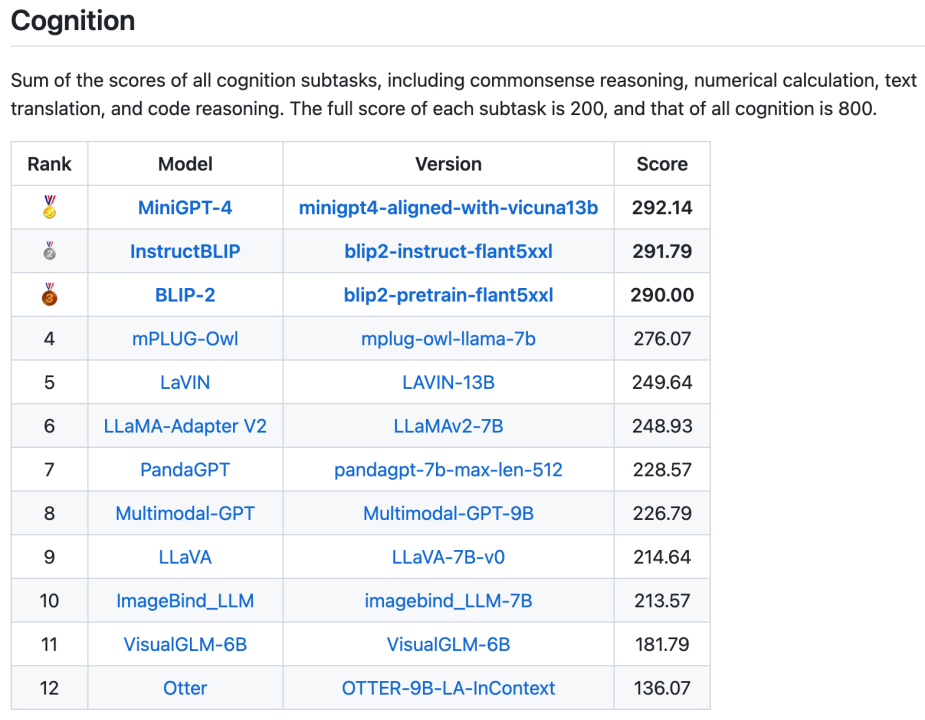
Figure 4. Liste totale des tâches cognitives
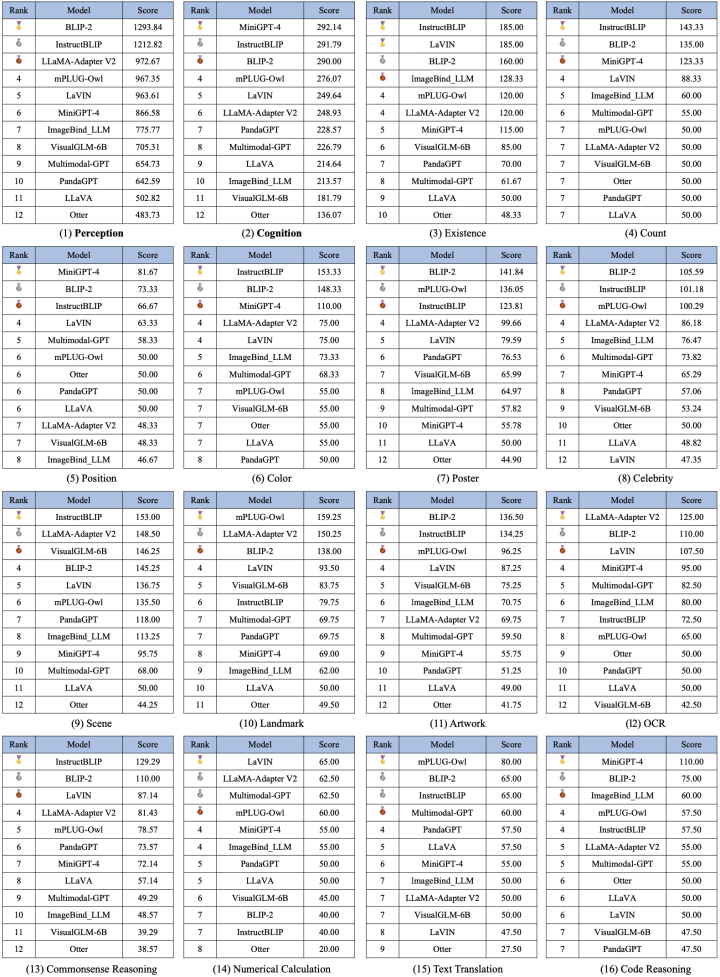
Figure 5. Toutes les listes
Dans En outre, les chercheurs ont également résumé certains problèmes courants exposés par le modèle MLLM dans les expériences, comme le montre la figure 6, dans l'espoir de fournir des conseils pour l'optimisation ultérieure du modèle.
 Photos
Photos
Figure 6. Problèmes courants exposés par MLLM. [O]/[N] signifie que la vraie réponse est Oui/Non. [R] est la réponse générée par MLLM.
Le premier problème est de ne pas suivre les instructions.
Bien qu'une conception d'instructions très concise ait été adoptée, il existe toujours des MLLM qui sont libres de répondre aux questions plutôt que de suivre les instructions.
Comme le montre la première ligne de la figure 6, l'instruction indique "Veuillez répondre par oui ou par non", mais MLLM n'a donné qu'une réponse déclarative. Si « Oui » ou « Non » n'apparaît pas au début de la réponse, la réponse est jugée incorrecte. Un bon MLLM, surtout après avoir affiné les instructions, devrait être capable de généraliser à des instructions aussi simples.
Le deuxième problème est le manque de perception.
Comme le montre la deuxième rangée de la figure 6, MLLM a identifié de manière incorrecte le nombre de bananes dans la première image et le nombre dans la deuxième image, ce qui a entraîné des réponses erronées. Les chercheurs ont également remarqué que les performances perceptuelles étaient facilement affectées par les changements d’instructions, puisque deux instructions pour la même image qui différaient d’un seul mot entraînaient des résultats perceptuels complètement différents.
Le troisième problème est le manque de capacité de raisonnement.
Comme le montre la troisième ligne de la figure 6, il ressort du texte rouge que MLLM sait déjà que la première image n'est pas un espace de bureau, mais a quand même donné une réponse incorrecte « Oui ».
De même, sur la deuxième image, MLLM a calculé le résultat arithmétique correct, mais a finalement également donné la mauvaise réponse. L’ajout d’une invite de chaîne de pensée, telle que « Réfléchissons étape par étape », peut apporter de meilleurs résultats. Dans l’attente de recherches plus approfondies dans ce domaine.
La quatrième question est la vision objet suite à la commande. Comme le montre la quatrième ligne de la figure 6, lorsque l'instruction contient un objet qui n'existe pas dans l'image, MLLM imaginera que l'objet existe et donnera finalement une réponse « Oui ».
Cette approche consistant à toujours répondre « Oui » entraîne une précision proche de 50 % et une précision+ proche de 0. Cela démontre l’importance de supprimer les hallucinations cibles et nécessite également une réflexion plus approfondie sur la fiabilité des réponses générées par MLLM.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
