
 Périphériques technologiques
IA
Pratique industrielle du méta-apprentissage et de la recommandation interdomaine de Tencent TRS
Périphériques technologiques
IA
Pratique industrielle du méta-apprentissage et de la recommandation interdomaine de Tencent TRS
Pratique industrielle du méta-apprentissage et de la recommandation interdomaine de Tencent TRS


1. Méta-apprentissage
1. Points faibles de la modélisation personnalisée
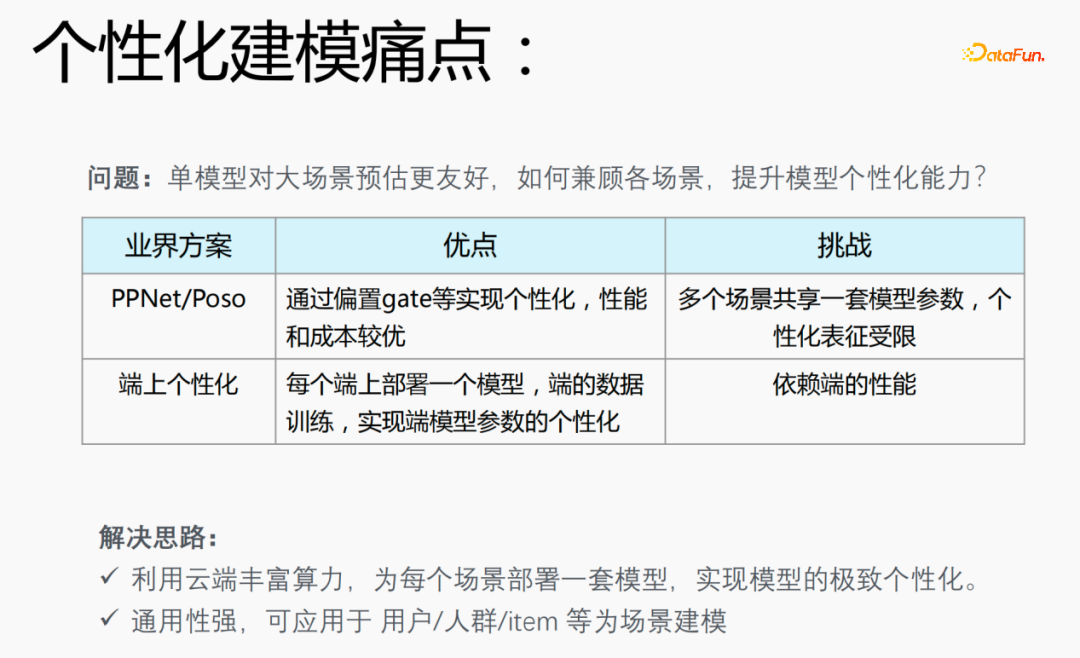
Dans les scénarios de recommandation, vous rencontrerez le problème de la distribution des données, 20% des scénarios appliquent 80% des les échantillons, ce qui pose un problème : un modèle unique est plus convivial pour l'estimation de grandes scènes. Comment prendre en compte divers scénarios et améliorer les capacités de personnalisation des modèles est un problème de la modélisation personnalisée.
Solution industrielle :
- PPNet/Poso : ce modèle permet une personnalisation via une porte décalée, etc., et a de meilleures performances et un meilleur coût. Cependant, plusieurs scénarios partagent un ensemble de paramètres de modèle et la représentation personnalisée est limitée.
- Personnalisation à la fin : déployez un modèle à chaque extrémité, utilisez les données en temps réel à la fin pour l'entraînement et personnalisez les paramètres du modèle final, mais cela dépendra des performances de la fin et de la le modèle ne peut pas être particulièrement grand, ce qui nécessite d'utiliser de petits modèles pour la formation.
En réponse aux problèmes existant dans les modèles de l'industrie, nous avons proposé les solutions suivantes :
- Utilisez la riche puissance de calcul du cloud pour déployer un ensemble de modèles pour chaque scénario afin d'atteindre la personnalisation ultime du modèle ;
- Le modèle est très polyvalent et peut être appliqué à des scénarios de modélisation personnalisés tels que des utilisateurs/foules/objets.
2. Le méta-apprentissage résout le problème de la personnalisation du modèle

- Exigences : Déployez un ensemble de modèles personnalisés pour chaque utilisateur et groupe de personnes, et le modèle n'entraîne aucune perte de coût. et les performances.
- Sélection de la solution : si un ensemble de modèles est déployé pour chaque utilisateur, la structure du modèle et les paramètres du modèle sont différents, ce qui entraînera un coût de formation et de service du modèle relativement élevé. Nous envisageons de fournir des paramètres de modèle personnalisés pour chaque scénario sous la même structure de modèle afin de résoudre le problème de la personnalisation du modèle.
- Lieu de déploiement : déployez le modèle sur le cloud et utilisez la puissance de calcul abondante sur le cloud pour le calcul en même temps, vous souhaitez contrôler de manière flexible le modèle sur le cloud ;
- Idée d'algorithme : le méta-apprentissage traditionnel résout le problème du petit nombre d'échantillons et du démarrage à froid. Grâce à une compréhension complète de l'algorithme, dans le domaine de la recommandation, l'innovation du méta-apprentissage est utilisée pour résoudre le problème de. personnalisation extrême du modèle.
L'idée générale est d'utiliser le méta-apprentissage pour déployer un ensemble de paramètres de modèle personnalisés pour chaque utilisateur dans le cloud, obtenant finalement l'effet d'aucune perte de coût et de performances.
3. Introduction au méta-apprentissage

Le méta-apprentissage fait référence à un algorithme qui apprend des connaissances générales pour guider de nouvelles tâches, donnant au réseau des capacités d'apprentissage rapide. Par exemple : la tâche de classification dans l'image ci-dessus : chats et oiseaux, fleurs et vélos, nous définissons cette tâche de classification comme une tâche de classification K-short N-class, dans l'espoir d'acquérir des connaissances en classification grâce au méta-apprentissage. Dans le processus d'estimation fine, nous espérons que pour les tâches de classification telles que les chiens et les loutres, l'affinage permettra d'obtenir l'effet d'estimation ultime avec très peu d'échantillons. Pour un autre exemple, lorsque nous apprenons les quatre opérations mixtes, nous apprenons d'abord l'addition et la soustraction, puis la multiplication et la division. Lorsque ces deux connaissances sont maîtrisées, nous pouvons apprendre à intégrer les deux connaissances pour calculer les opérations mixtes d'addition. , soustraction, multiplication et division, nous ne les calculons pas séparément, mais sur la base de l'addition, de la soustraction, de la multiplication et de la division, nous apprenons d'abord les règles de fonctionnement de la multiplication et de la division, puis de l'addition et de la soustraction, puis utilisons quelques échantillons pour nous entraîner. cette règle afin de comprendre rapidement cette règle, afin que dans la nouvelle estimation de meilleurs résultats soient obtenus sur les données. L'idée du méta-apprentissage est similaire à celle-ci.
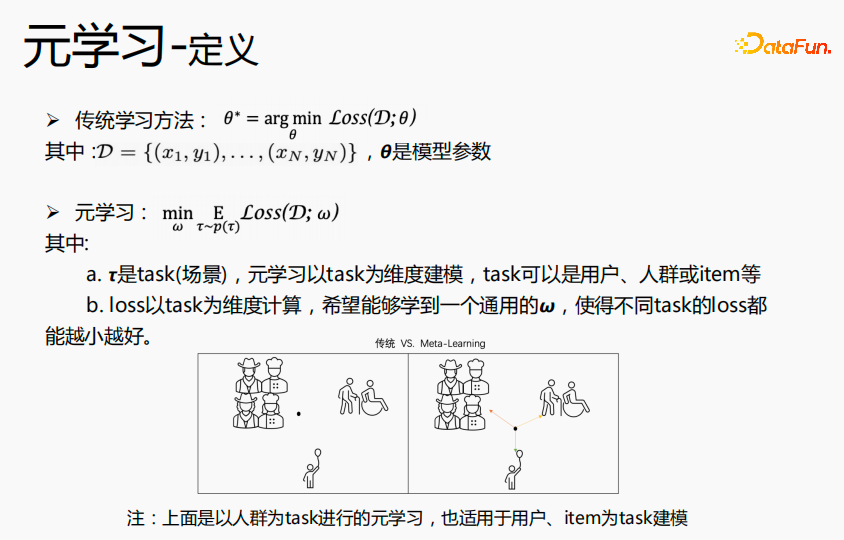
L'objectif des méthodes d'apprentissage traditionnelles est d'apprendre le θ optimal pour toutes les données, c'est-à-dire le θ globalement optimal. Le méta-apprentissage utilise la tâche comme dimension pour apprendre le général 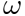 dans la scène, et la perte peut atteindre l'optimum dans toutes les scènes. Le θ appris par les méthodes d'apprentissage traditionnelles est plus proche de la foule dans les grandes scènes, a de meilleures prédictions pour les grandes scènes et a un effet moyen sur les prédictions à longue traîne consiste à apprendre un point similaire dans chaque scène et à l'utiliser ; chaque Les données de scène ou les nouvelles données de scène sont affinées à ce stade pour atteindre le point optimal pour chaque scène. Par conséquent, il est possible de construire des paramètres de modèle personnalisés dans chaque scénario pour atteindre l’objectif de personnalisation ultime. Dans l'exemple ci-dessus, la foule est utilisée comme tâche de méta-apprentissage, mais elle convient également aux utilisateurs ou aux éléments à utiliser comme tâches de modélisation.
dans la scène, et la perte peut atteindre l'optimum dans toutes les scènes. Le θ appris par les méthodes d'apprentissage traditionnelles est plus proche de la foule dans les grandes scènes, a de meilleures prédictions pour les grandes scènes et a un effet moyen sur les prédictions à longue traîne consiste à apprendre un point similaire dans chaque scène et à l'utiliser ; chaque Les données de scène ou les nouvelles données de scène sont affinées à ce stade pour atteindre le point optimal pour chaque scène. Par conséquent, il est possible de construire des paramètres de modèle personnalisés dans chaque scénario pour atteindre l’objectif de personnalisation ultime. Dans l'exemple ci-dessus, la foule est utilisée comme tâche de méta-apprentissage, mais elle convient également aux utilisateurs ou aux éléments à utiliser comme tâches de modélisation.
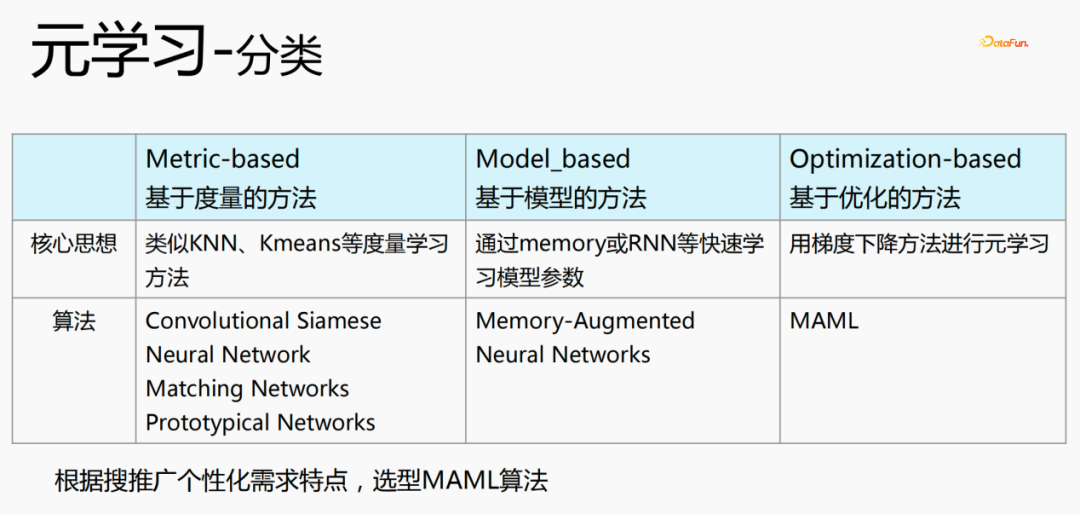
Il existe trois catégories de méta-apprentissage :
- Basé sur la métrique : utilisez des méthodes d'apprentissage métriques telles que KNN et K-means pour apprendre de nouveaux scénarios et ceux existants. La distance de la scène et à quelle catégorie il est estimé appartenir. Les algorithmes représentatifs sont le siamois convolutif, le réseau neuronal, les réseaux correspondants et les réseaux prototypiques.
- Model_based : apprenez rapidement les paramètres du modèle via la mémoire ou RNN, etc. Les algorithmes représentatifs sont : Réseaux de neurones augmentés par mémoire
- Méthode basée sur l'optimisation (basée sur l'optimisation) : Il s'agit d'une méthode populaire ces dernières années. Elle utilise la méthode de descente de gradient pour calculer la perte pour chaque scène afin d'obtenir l'optimal. Le paramètre représente l'algorithme MAML, qui est actuellement utilisé pour la modélisation personnalisée.
4. Algorithme de méta-apprentissage

Le méta-apprentissage indépendant du modèle (MAML) est un algorithme qui n'a rien à voir avec la structure du modèle et qui se prête à la généralisation. deux parties : méta-entraînement et réglage fin.
meta-train a une initialisation θ et effectue deux échantillonnages, un échantillonnage de scène et un échantillonnage d'échantillons intra-champ. La première étape est l'échantillonnage de scènes. Dans ce cycle de processus d'échantillonnage, l'échantillon total comporte des centaines de milliers, voire des millions de tâches, et n tâches seront échantillonnées parmi les millions de tâches. La deuxième étape, sur chaque scène, consiste à échantillonner des échantillons par lots ; pour cette scène et divisez les échantillons de taille de lot en deux parties, une partie est Support Set et l'autre partie est Query Set ; utilisez Support Set pour mettre à jour le thêta de chaque scène en utilisant la troisième étape de descente de gradient stochastique, utilisez Query Set Set pour calculer la perte ; pour chaque scène ; dans la quatrième étape, ajouter toutes les pertes et renvoyer le gradient à θ ; plusieurs séries de calculs sont effectuées dans leur ensemble jusqu'à ce que la condition de terminaison soit remplie.
Parmi eux, Support Set peut être compris comme un ensemble de formation et Query Set peut être compris comme un ensemble de validation.

Le processus Finetune est très proche du processus méta-train. θ est placé dans une scène spécifique, l'ensemble de supports de la scène est obtenu et la méthode de descente de gradient (SGD) est utilisée pour obtenir le paramètres optimaux de la scène 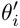 ; utilisez
; utilisez 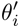 Générer des résultats estimés pour les échantillons (ensemble de requêtes) à évaluer dans le scénario de tâche.
Générer des résultats estimés pour les échantillons (ensemble de requêtes) à évaluer dans le scénario de tâche.
5. Les défis de l'industrialisation du méta-apprentissage
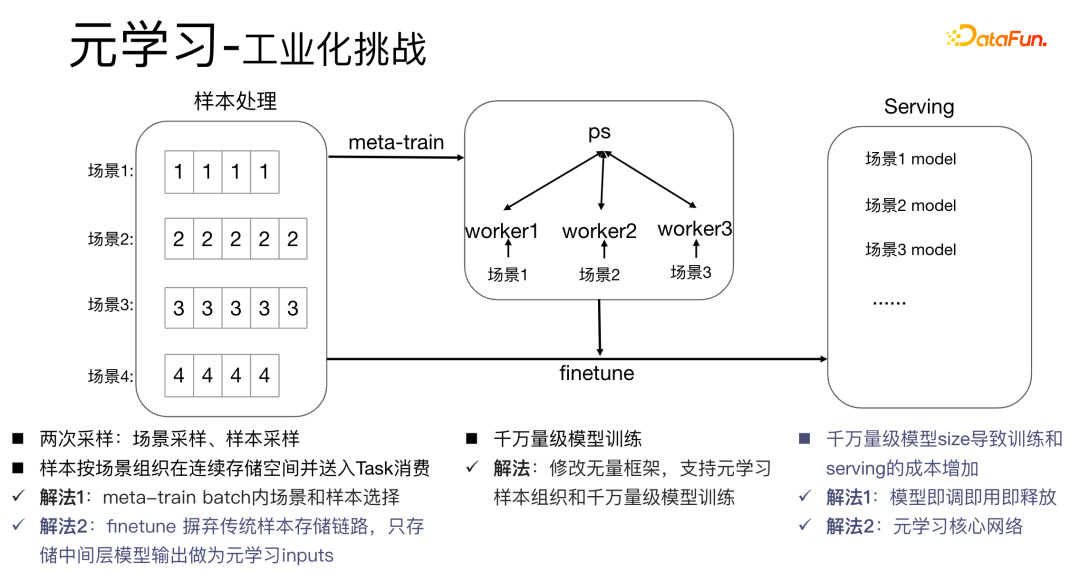
L'application d'algorithmes de méta-apprentissage dans des scénarios industriels posera des défis relativement importants : le processus de méta-apprentissage des algorithmes de méta-apprentissage implique deux échantillonnages, l'échantillonnage de scène et l'échantillonnage. échantillonnage. Pour les échantillons, il est nécessaire de bien organiser les échantillons et de les stocker et traiter dans l'ordre des scènes. En même temps, une table de dictionnaire est nécessaire pour stocker la relation correspondante entre les échantillons et les scènes. Ce processus consomme beaucoup. d'espace de stockage et de performances informatiques. Dans le même temps, les échantillons doivent être mis à la disposition des travailleurs pour être consommés, ce qui pose un très grand défi aux scénarios industriels.
Nous avons les solutions suivantes :
- Solution 1 : effectuez une sélection d'échantillons dans le lot de méta-train. Dans le même temps, pour des dizaines de millions de formations de modèles, nous modifions le cadre infini pour prendre en charge l'organisation des échantillons de méta-apprentissage et des dizaines de millions de formations de modèles. La méthode traditionnelle de déploiement de modèles consiste à déployer un ensemble de modèles dans chaque scénario, ce qui entraînera des modèles de très grande taille, se chiffrant en dizaines de millions, et augmentant les coûts de formation et de service. Nous utilisons une méthode de réglage, d'utilisation et de publication pour stocker un seul ensemble de paramètres du modèle, ce qui peut éviter d'augmenter la taille du modèle. Parallèlement, afin de gagner en performances, nous étudions uniquement la partie cœur de réseau.
- Solution 2 : effectuez un réglage fin pendant le processus de diffusion. Le lien de stockage d'échantillons traditionnel augmente le coût de maintenance des échantillons. Par conséquent, nous abandonnons la méthode traditionnelle et stockons uniquement les données de la couche intermédiaire comme entrée de méta. -apprentissage.
6. Solution de méta-apprentissage
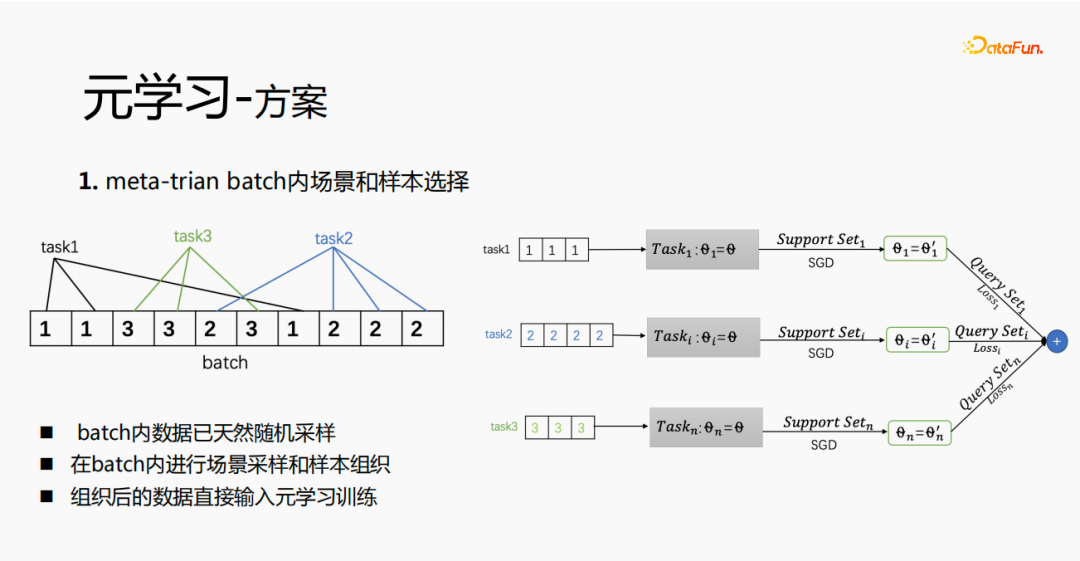
Premièrement, la sélection des scènes et des échantillons au sein du lot est implémentée dans le méta-train. Il y aura plusieurs éléments de données dans chaque lot, et chacun. les données appartiennent à une tâche. Au sein d'un lot, ces données sont extraites en fonction des tâches, et les échantillons extraits sont placés dans le processus de formation méta-train. Cela résout le problème de la nécessité de maintenir indépendamment un ensemble de liens de traitement pour la sélection de scènes et la sélection d'échantillons.

Grâce à des recherches expérimentales et à la lecture d'articles, nous avons constaté que dans le processus de réglage fin et de méta-apprentissage, plus la couche de prédiction est proche, plus l'impact sur l'effet de prédiction du modèle est grand. Dans le même temps, la couche emb a un plus grand impact sur l'effet de prédiction du modèle, et la couche intermédiaire n'a pas un grand impact sur l'effet de prédiction. Notre idée est donc que le méta-apprentissage sélectionne uniquement les paramètres les plus proches de la couche de prédiction. D'un point de vue coût, la couche emb augmentera le coût de l'apprentissage et la couche emb ne sera pas entraînée pour le méta-apprentissage.
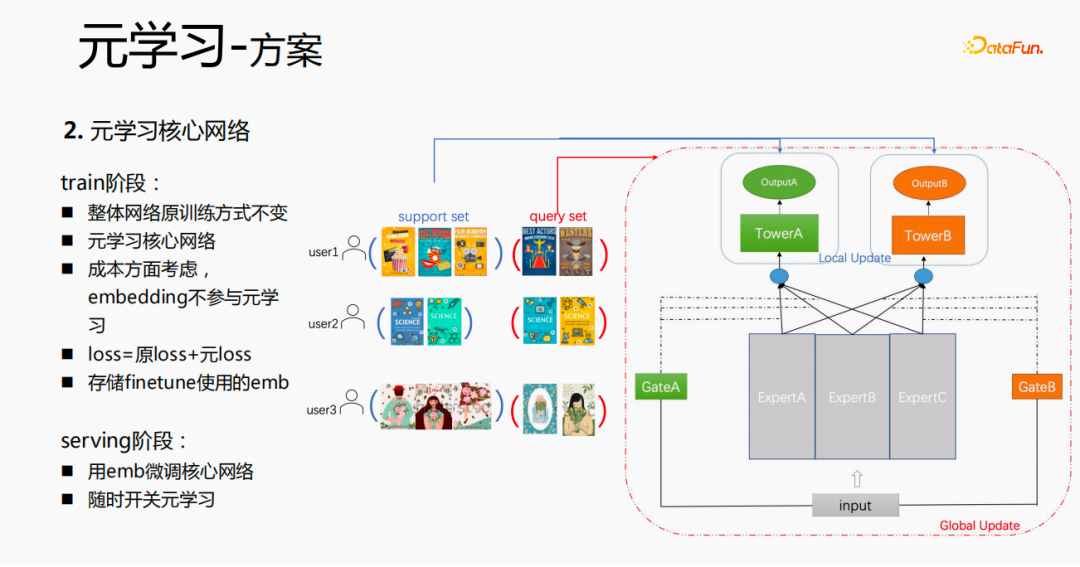
Le processus de formation global, tel que le réseau de formation mmoe dans l'image ci-dessus, nous apprenons les paramètres de la couche tour, et les paramètres des autres scènes sont toujours appris selon la méthode de formation originale. Les échantillons sont organisés avec l'utilisateur comme dimension. Chaque utilisateur a ses propres données de formation. Les données de formation sont divisées en deux parties, une partie est l'ensemble de support et l'autre partie est l'ensemble de requêtes. Dans l'ensemble de support, seul le contenu du côté local est appris pour la mise à jour de la tour et la formation des paramètres ; ensuite, les données de l'ensemble de requêtes sont utilisées pour calculer la perte de l'ensemble du réseau, puis le gradient est renvoyé pour mettre à jour les paramètres de l'ensemble du réseau ; .
Par conséquent, l'ensemble du processus de formation est le suivant : la méthode de formation initiale du réseau global reste inchangée ; le méta-apprentissage n'apprend que le réseau principal, l'intégration ne participe pas à la perte du méta-apprentissage ; méta-perte ; lors du fintune, le stockage est effectué. Dans le processus de service, emb est utilisé pour affiner le réseau principal et le commutateur peut être utilisé pour contrôler l'activation et la désactivation du méta-apprentissage.
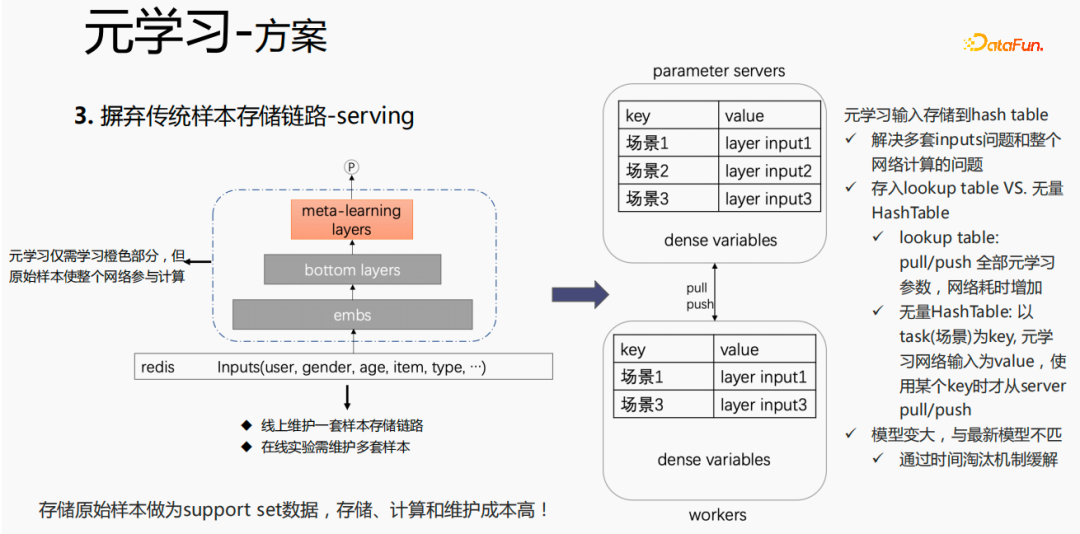
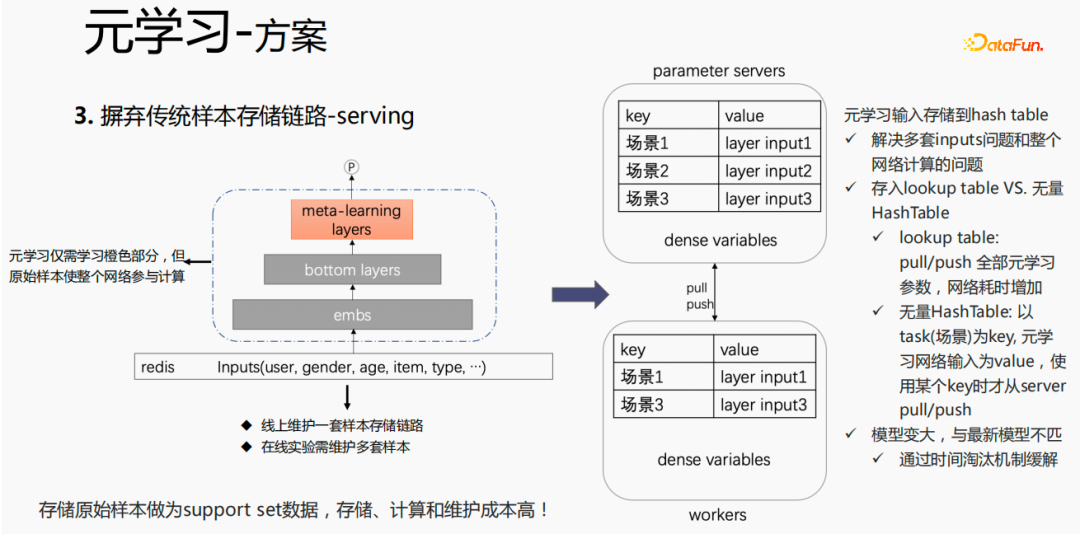
Pour la méthode traditionnelle de stockage des échantillons, si le réglage fin est effectué directement pendant le processus de présentation, de sérieux problèmes surviendront : un ensemble de liens de stockage d'échantillons doit être maintenu en ligne, plusieurs ensembles d'expériences en ligne ; doivent être conservés. Plusieurs ensembles d’échantillons. Dans le même temps, dans le processus de réglage fin, l'échantillon original est utilisé pour le réglage fin. L'échantillon doit passer par la couche emb, les couches inférieures et la couche de méta-apprentissage. Cependant, le méta-apprentissage n'a besoin que d'apprendre les couches de méta-apprentissage. processus de service et ne se soucie pas des autres parties. Nous envisageons de sauvegarder uniquement l'entrée de méta-apprentissage dans le modèle pendant le processus de diffusion, ce qui peut économiser la maintenance du lien d'échantillon et obtenir un certain effet. Si seule la partie emb est enregistrée, le coût de calcul et le coût de maintenance de cette partie peuvent. être sauvé.
Nous utilisons les méthodes suivantes :
Mettez le stockage dans la table de recherche du modèle. La table de recherche sera considérée comme une variable dense et stockée dans ps. Tous les paramètres seront transférés vers le travailleur lors de la mise à jour, toutes les variables seront également poussées. temps de réseau. Une autre façon consiste à utiliser une HashTable infinie. La HashTable est stockée sous forme de clé et de valeur. La clé est la scène et la valeur est l'entrée de la couche méta. L'avantage est qu'il vous suffit d'importer l'entrée. La couche de la scène requise à partir de ps. Push ou pull permettra de gagner du temps sur le réseau dans son ensemble, nous échantillonnons donc cette méthode pour stocker l'entrée de la couche méta. Dans le même temps, si des couches de méta-apprentissage sont stockées dans le modèle, le modèle deviendra plus grand et rencontrera des problèmes d'expiration, ce qui entraînera une inadéquation avec le modèle actuel. Nous utilisons l'élimination du temps pour résoudre ce problème, c'est-à-dire pour l'éliminer. intégrations expirées. Cela rend non seulement le modèle plus petit, mais résout également le problème du temps réel.
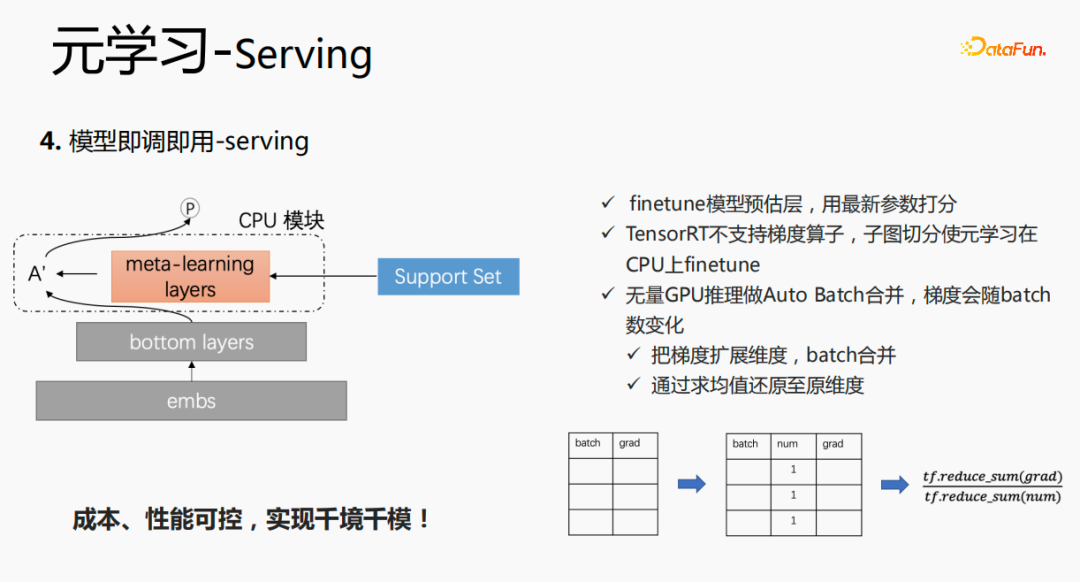
Dans la phase de service, ce modèle utilisera l'intégration. L'intégration est entrée dans les couches inférieures, ce n'est pas la même chose que la méthode d'origine. Au lieu de cela, les données de l'ensemble de support sont obtenues. via des couches de méta-apprentissage, et l'intégration est entrée dans les couches inférieures. Les paramètres de cette couche sont mis à jour et les paramètres mis à jour sont utilisés pour la notation. Ce processus ne peut pas être calculé sur le GPU, nous exécutons donc le processus sur le CPU. Dans le même temps, l'inférence GPU Wuliang effectue une fusion automatique par lots pour fusionner plusieurs requêtes. Les requêtes fusionnées sont calculées sur le GPU. De cette manière, le dégradé changera à mesure que le lot augmente. Pour résoudre ce problème, nous utilisons batch et grad On. sur la base de , ajoutez une dimension numérique Lors du calcul du dégradé, ajoutez le grade et traitez-le en fonction du nombre pour maintenir la stabilité du dégradé. En fin de compte, le coût et les performances sont contrôlables et divers scénarios et modèles sont réalisés.
7. Pratique industrialisée du méta-apprentissage
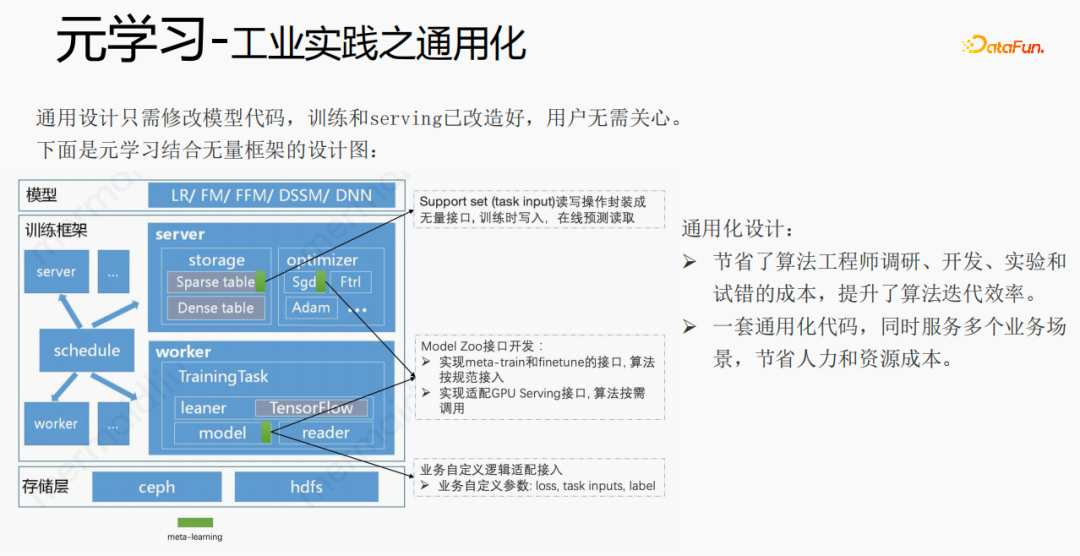
En utilisant des frameworks et des composants pour généraliser le méta-apprentissage, lorsque les utilisateurs y accèdent, il leur suffit de modifier le code du modèle. Les utilisateurs n'ont pas besoin de se soucier de la formation. et servir, il leur suffit d'appeler ce que nous avons déjà. Implémenter de bonnes interfaces, telles que des interfaces de lecture et d'écriture d'ensembles de support, des interfaces d'implémentation de méta-entraînement et de réglage fin et des interfaces d'adaptation de service GPU. Les utilisateurs doivent uniquement transmettre les paramètres liés à l'entreprise tels que la perte, les entrées de tâches, l'étiquette, etc. Cette conception permet aux ingénieurs en algorithmes d'économiser les coûts de recherche, de développement, d'expérimentation et d'essais et erreurs, et améliore l'efficacité des itérations de l'algorithme. Dans le même temps, le code généralisé peut servir plusieurs scénarios commerciaux, économisant ainsi des coûts de main-d'œuvre et de ressources.
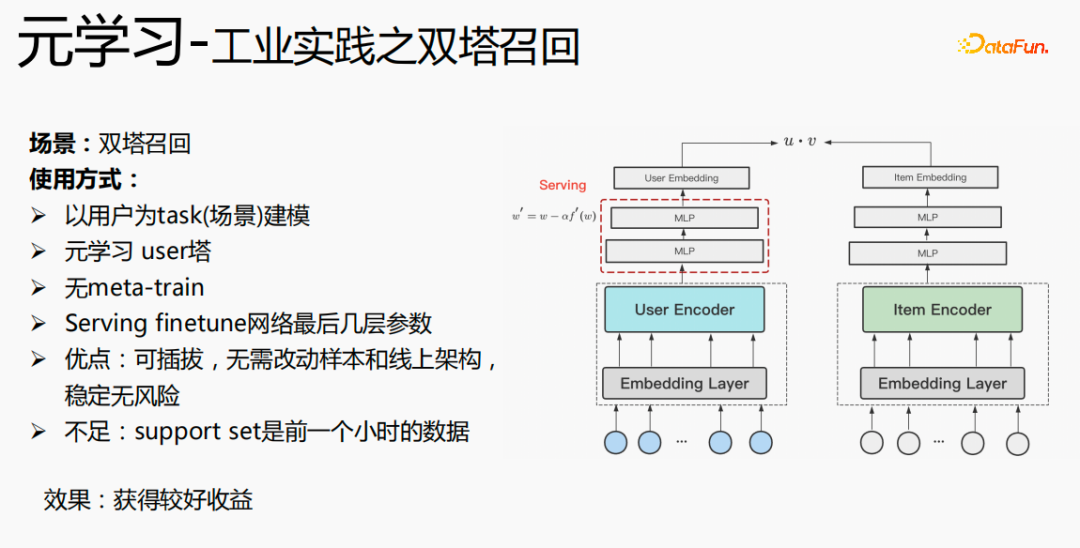
L'utilisation du méta-apprentissage dans le scénario de rappel à deux tours est modélisée avec l'utilisateur comme dimension, y compris la tour utilisateur et la tour objet. Les avantages du modèle sont : enfichable, pas besoin de modifier les échantillons et l'architecture en ligne, stable et sans risque ; l'inconvénient est que l'ensemble de support est constitué des données de l'heure précédente, ce qui présente des problèmes en temps réel ;

Un autre scénario d'application du méta-apprentissage est le scénario de rappel de séquence. Ce scénario est modélisé avec l'utilisateur comme scénario et la séquence de comportement de l'utilisateur comme ensemble de support. , que nous maintiendrons Une file d'attente d'échantillons négative, les échantillons de la file d'attente d'échantillonnage sont utilisés comme échantillons négatifs et les échantillons positifs sont épissés dans l'ensemble de support. Les avantages sont les suivants : des performances en temps réel plus élevées et un coût inférieur.
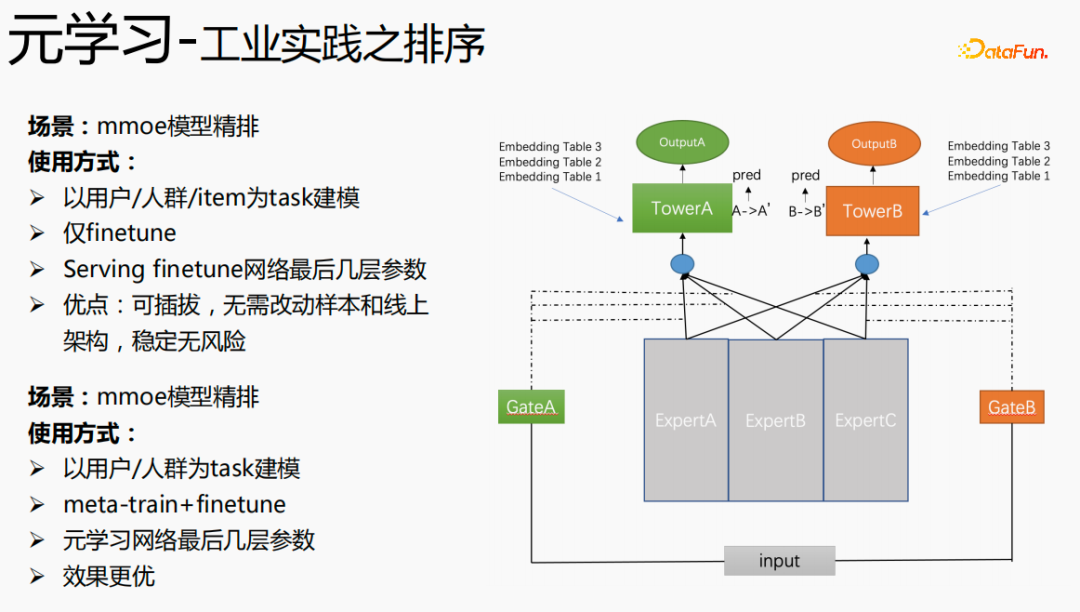
Enfin, le méta-apprentissage est également appliqué dans des scénarios de tri, tels que le modèle de tri fin mmoe dans l'image ci-dessus. Il existe deux méthodes de mise en œuvre : en utilisant uniquement le réglage fin et en utilisant à la fois le méta-entraînement et le réglage fin. La deuxième méthode de mise en œuvre est plus efficace.
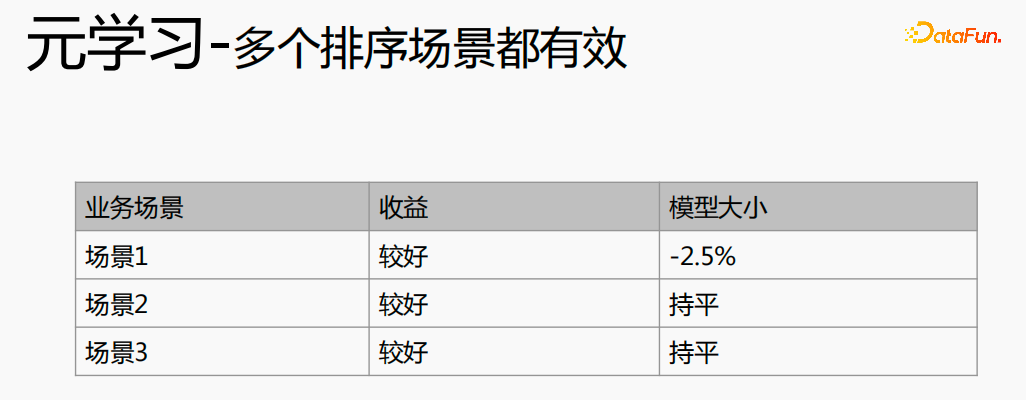
Le méta-apprentissage a obtenu de bons résultats dans différents scénarios.
2. Recommandation inter-domaines
1. Points faibles de la recommandation inter-domaines
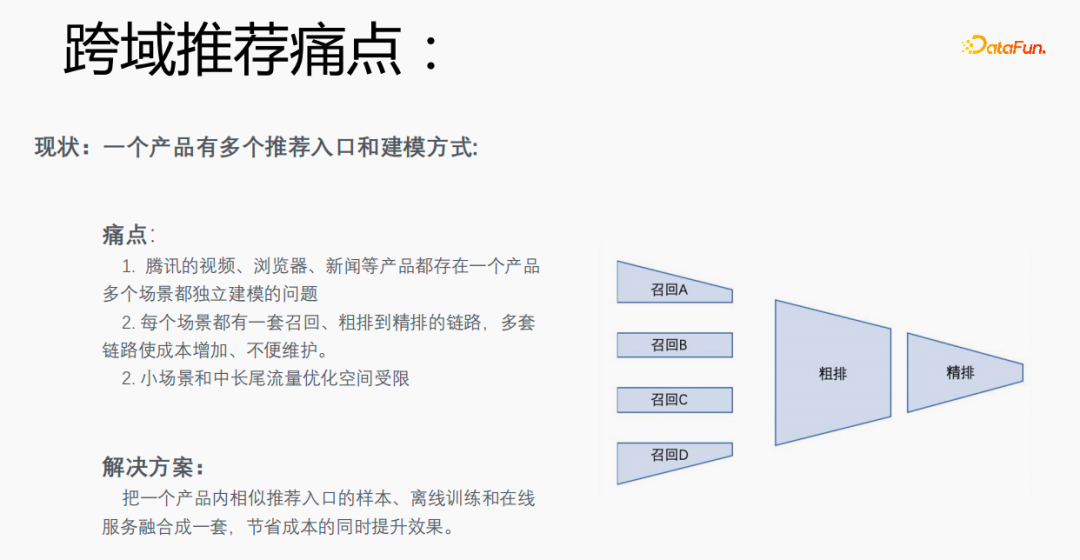
Chaque scène a plusieurs entrées recommandées. Il est nécessaire d'établir un ensemble de liens allant du rappel au classement approximatif en passant par le classement fin pour chaque scène, ce qui est coûteux. En particulier, les petites scènes et les données de trafic à moyenne et longue traîne sont rares et l'espace d'optimisation est limité. Pouvons-nous intégrer des échantillons de portails de recommandation, de formations hors ligne et de services en ligne similaires dans un seul produit dans un ensemble pour réduire les coûts et améliorer les résultats ?
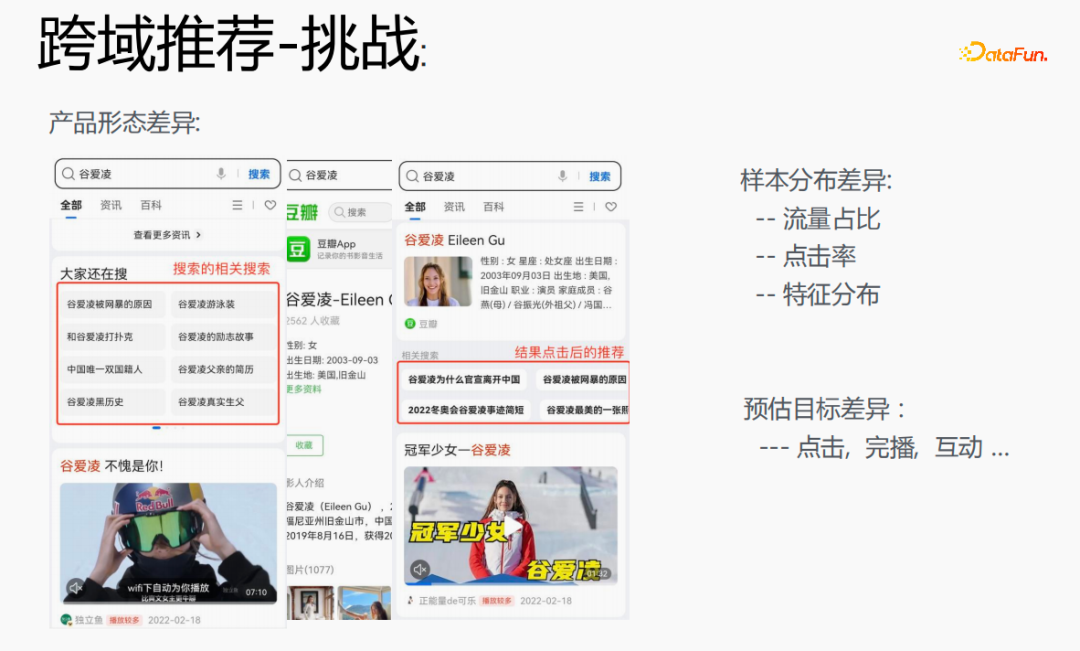
Cependant, cela présente certains défis. Recherchez Gu Ailing sur le navigateur et les termes de recherche pertinents apparaîtront. Après avoir cliqué sur le contenu spécifique et revenu, des recommandations après avoir cliqué sur les résultats apparaîtront. Les proportions de trafic, les taux de clics et la répartition des fonctionnalités des deux sont assez différentes. Dans le même temps, il existe également des différences dans les objectifs estimés.
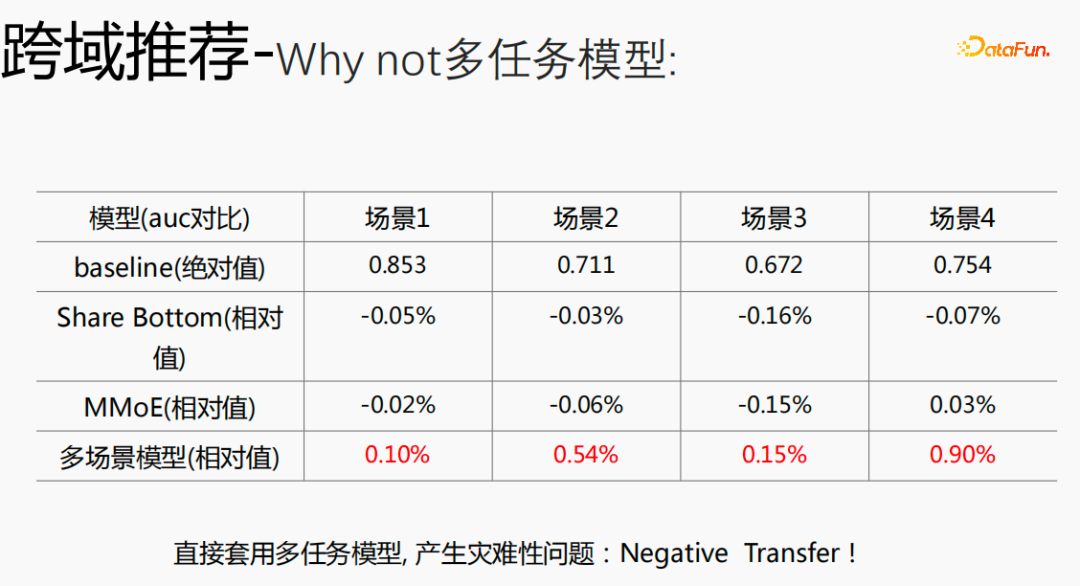
Si vous utilisez un modèle multitâche pour un modèle inter-domaines, de graves problèmes surviendront et vous ne pourrez pas obtenir de meilleurs avantages.
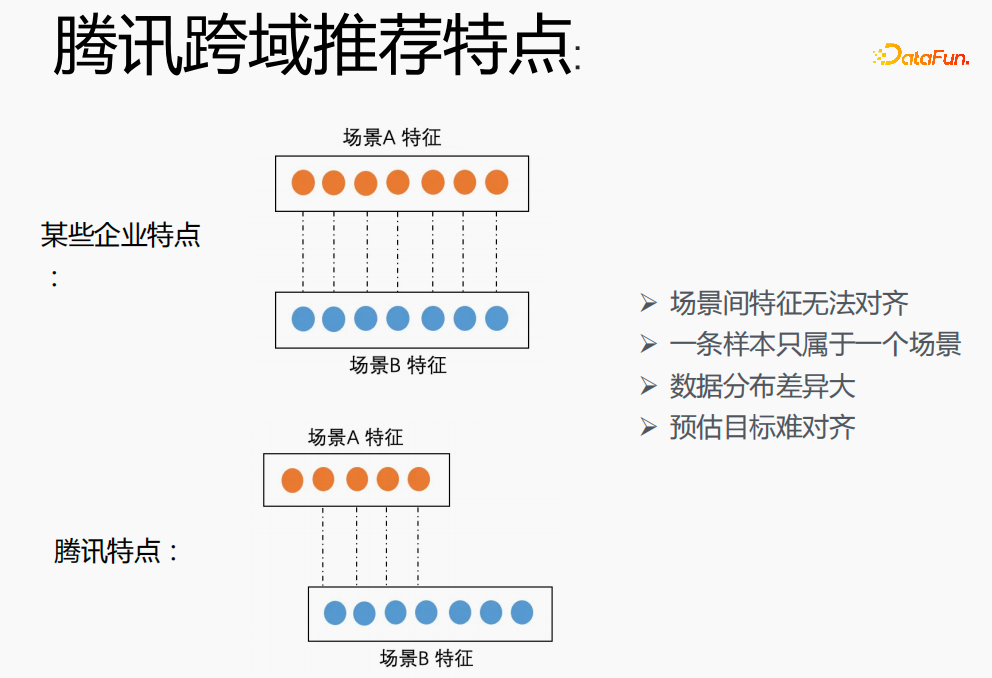
La mise en œuvre de la modélisation multi-scénarios dans Tencent est un grand défi. Premièrement, dans d'autres entreprises, les caractéristiques des deux scénarios peuvent correspondre une à une, mais dans le domaine de recommandation inter-domaines de Tencent, les caractéristiques des deux scénarios ne peuvent pas être alignées. Un échantillon ne peut appartenir qu'à un seul scénario. la répartition est très différente et il est difficile d’aligner les objectifs estimés.
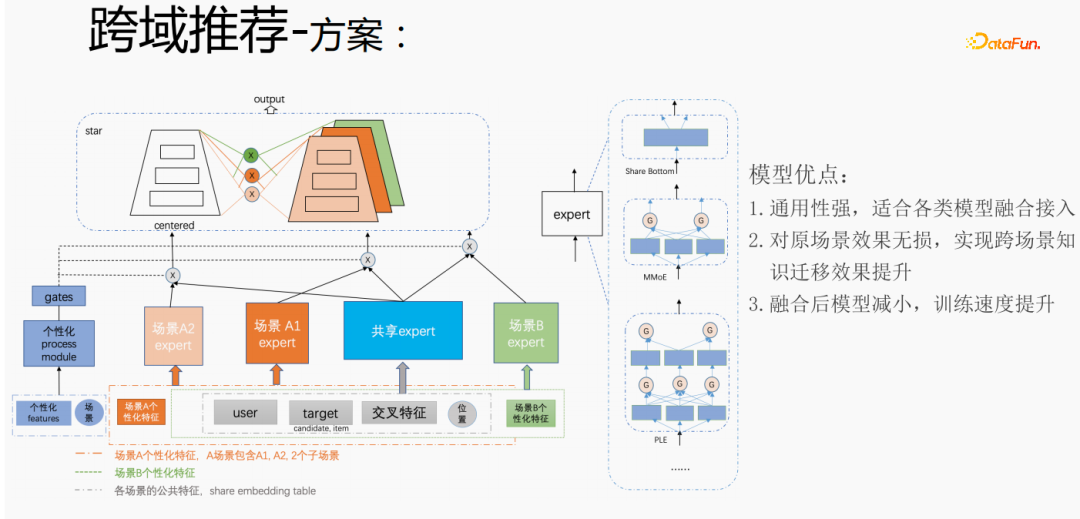
Selon les besoins personnalisés des scénarios de recommandation inter-domaines de Tencent, la méthode ci-dessus est utilisée pour le gérer. Pour les fonctionnalités communes, une intégration partagée est effectuée. Les fonctionnalités personnalisées de la scène ont leur propre espace d'intégration indépendant, il y a des experts partagés et des experts personnalisés. Toutes les données circuleront dans les experts partagés, et les échantillons de chaque scène. aura ses propres données de personnalité. Personnalisez l'expert, intègrez l'expert partagé et l'expert personnalisé via la porte personnalisée, saisissez-les dans la tour et utilisez la méthode des étoiles pour résoudre le problème de la rareté de la cible dans différents scénarios. Pour la partie experte, n'importe quelle structure de modèle peut être utilisée, comme Share bottom, MMoE, PLE, ou une structure de modèle complète sur le scénario métier. Les avantages de cette méthode sont les suivants : le modèle est très polyvalent et adapté à l'accès à la fusion de divers modèles puisque l'expert de scène peut être directement migré, l'effet de scène d'origine n'est pas endommagé et l'effet du transfert de connaissances entre scénarios est amélioré ; après la fusion, le modèle est réduit et la vitesse d'entraînement est améliorée. Améliorez tout en économisant des coûts.
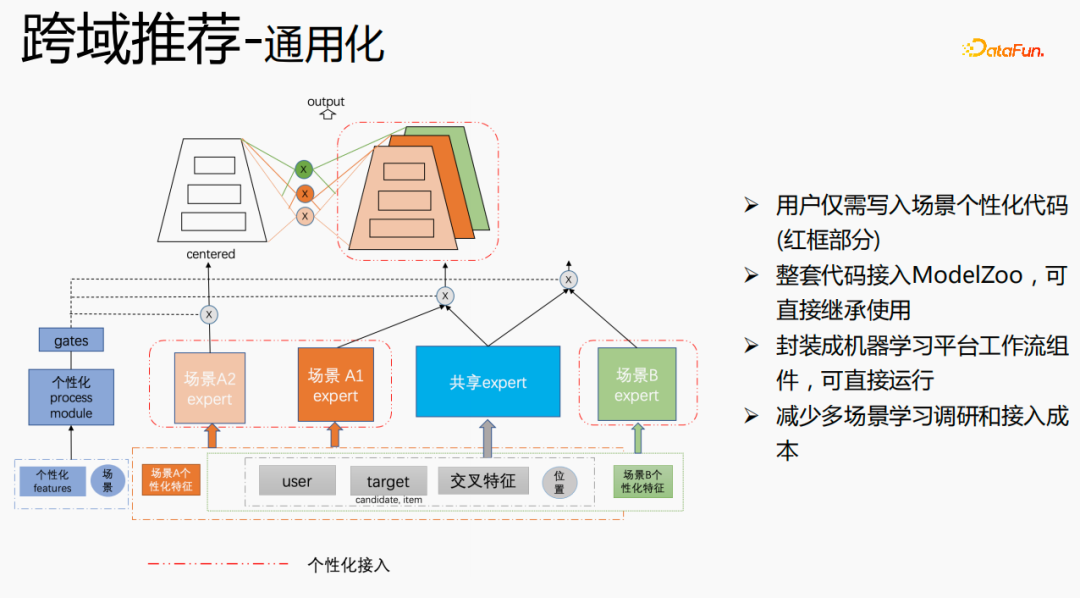
Nous avons réalisé une construction universelle. La partie rouge est le contenu qui nécessite un accès personnalisé, tel que : des fonctionnalités personnalisées, une structure de modèle personnalisée, etc. Les utilisateurs n'ont qu'à écrire du code personnalisé. Pour d'autres parties, nous avons connecté l'ensemble des codes à ModelZoo, qui peuvent être directement hérités et utilisés, et encapsulés dans des composants de flux de travail de la plateforme d'apprentissage automatique, qui peuvent être exécutés directement. Cette méthode réduit le coût de la recherche et de l'apprentissage multi-scénarios. accéder.
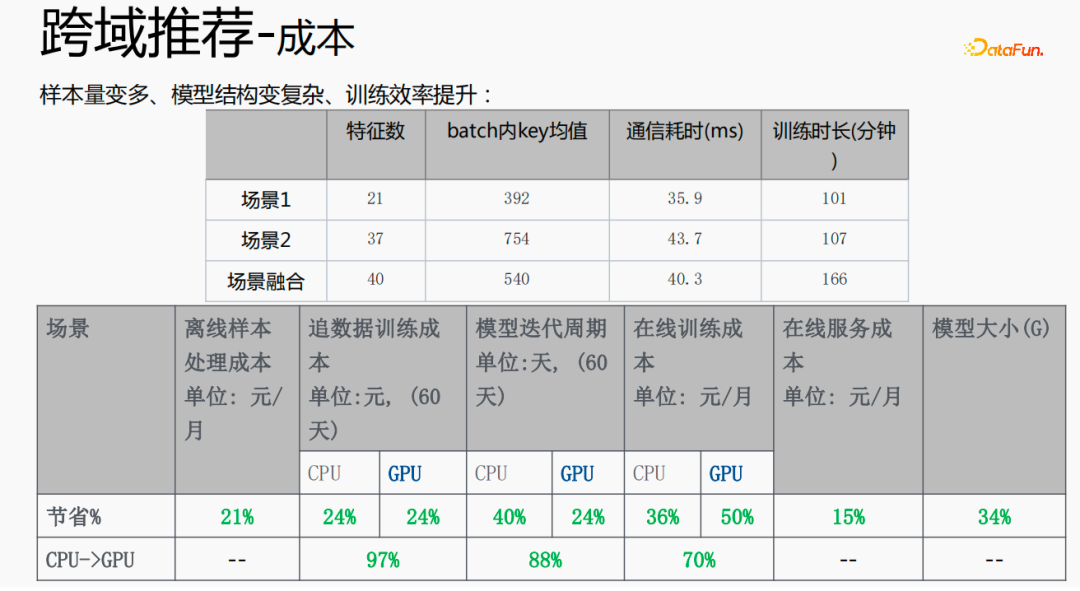
Cette méthode augmente la taille de l'échantillon et complique la structure du modèle, mais l'efficacité est améliorée. Les raisons sont les suivantes : étant donné que certaines fonctionnalités sont partagées, le nombre de fonctionnalités après la fusion est inférieur à la somme des fonctionnalités des deux scènes en raison de la fonction d'intégration partagée, la valeur clé moyenne dans le lot est inférieure à la valeur clé moyenne dans le lot. somme des deux scènes ; diminution Cela permet d'économiser le temps de traction ou de poussée du côté serveur, économisant ainsi le temps de communication et réduisant le temps global de formation.
La fusion de plusieurs scénarios peut réduire le coût global : le traitement des échantillons hors ligne peut réduire les coûts de 21 % ; l'utilisation du processeur pour rechercher les données permettra d'économiser 24 % des coûts, tandis que le temps d'itération du modèle sera également réduit de 40 % %, et formation en ligne Le coût, le coût du service en ligne et la taille du modèle seront tous réduits, de sorte que le coût de l'ensemble du lien est réduit. Dans le même temps, la fusion des données de plusieurs scènes est plus adaptée au calcul GPU. La fusion du CPU de deux scènes uniques avec le GPU permettra d'économiser une proportion plus élevée.
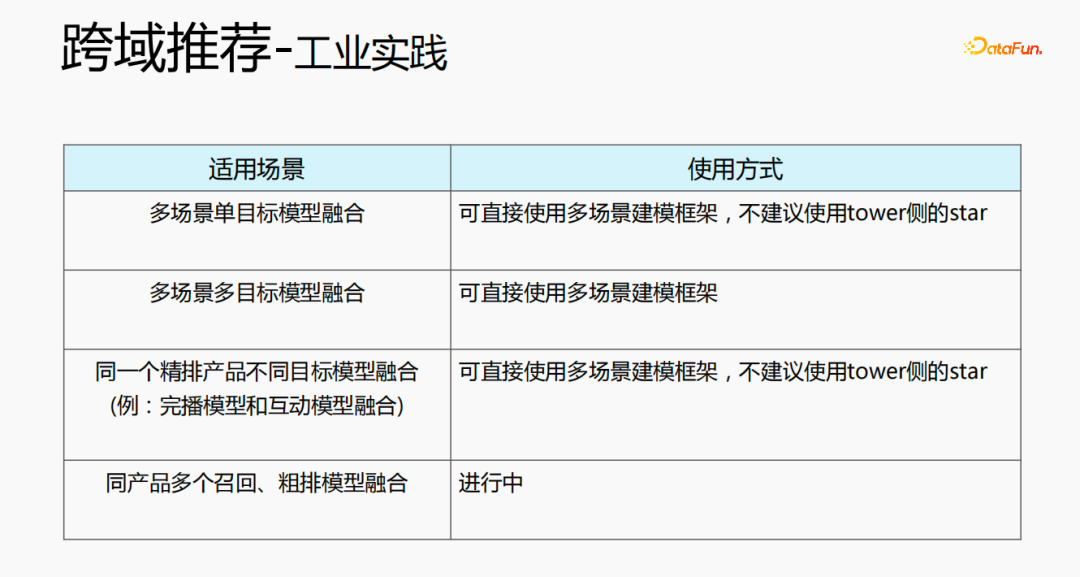
Les recommandations multidomaines peuvent être utilisées de plusieurs manières. La première est une structure de modèle multi-scènes à objectif unique, qui peut utiliser directement le cadre de modélisation multi-scènes. Il n'est pas recommandé d'utiliser l'étoile côté tour ; -objectif, et peut utiliser directement le cadre de modélisation multi-scènes ; Le troisième type est la fusion de différents modèles cibles pour le même produit raffiné. Il n'est pas recommandé d'utiliser l'étoile. du côté de la tour ; le dernier est la fusion de plusieurs modèles de rappel et de classement approximatif pour un même produit.
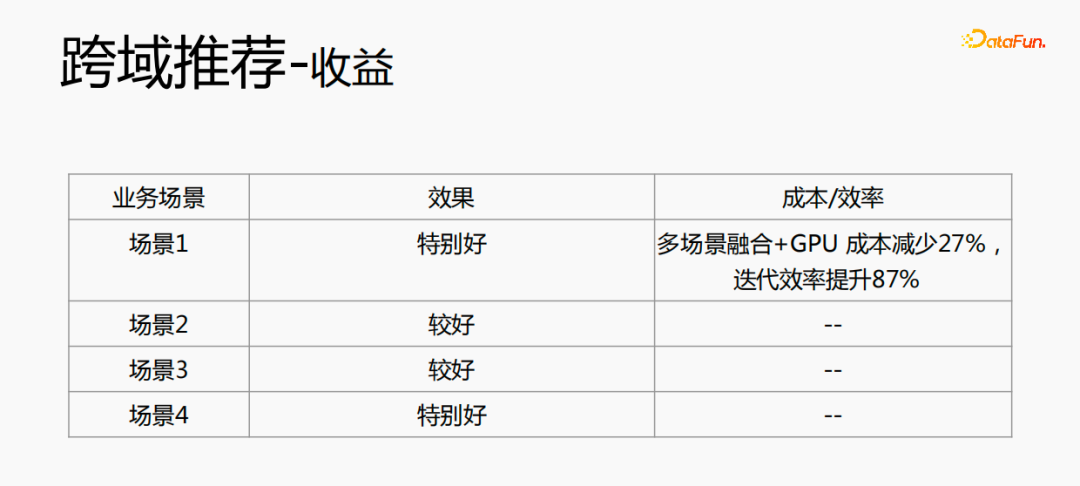
La recommandation inter-domaines améliore non seulement l'effet, mais permet également d'économiser beaucoup de coûts.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
La couche inférieure de la fonction de tri C++ utilise le tri par fusion, sa complexité est O(nlogn) et propose différents choix d'algorithmes de tri, notamment le tri rapide, le tri par tas et le tri stable.
 L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
La convergence de l’intelligence artificielle (IA) et des forces de l’ordre ouvre de nouvelles possibilités en matière de prévention et de détection de la criminalité. Les capacités prédictives de l’intelligence artificielle sont largement utilisées dans des systèmes tels que CrimeGPT (Crime Prediction Technology) pour prédire les activités criminelles. Cet article explore le potentiel de l’intelligence artificielle dans la prédiction de la criminalité, ses applications actuelles, les défis auxquels elle est confrontée et les éventuelles implications éthiques de cette technologie. Intelligence artificielle et prédiction de la criminalité : les bases CrimeGPT utilise des algorithmes d'apprentissage automatique pour analyser de grands ensembles de données, identifiant des modèles qui peuvent prédire où et quand les crimes sont susceptibles de se produire. Ces ensembles de données comprennent des statistiques historiques sur la criminalité, des informations démographiques, des indicateurs économiques, des tendances météorologiques, etc. En identifiant les tendances qui pourraient échapper aux analystes humains, l'intelligence artificielle peut donner du pouvoir aux forces de l'ordre.
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
 Pratique et réflexion sur la plateforme multimodale de grands modèles Jiuzhang Yunji DataCanvas
Oct 20, 2023 am 08:45 AM
Pratique et réflexion sur la plateforme multimodale de grands modèles Jiuzhang Yunji DataCanvas
Oct 20, 2023 am 08:45 AM
1. Le développement historique des grands modèles multimodaux. La photo ci-dessus est le premier atelier sur l'intelligence artificielle organisé au Dartmouth College aux États-Unis en 1956. Cette conférence est également considérée comme le coup d'envoi du développement de l'intelligence artificielle. pionniers de la logique symbolique (à l'exception du neurobiologiste Peter Milner au milieu du premier rang). Cependant, cette théorie de la logique symbolique n’a pas pu être réalisée avant longtemps et a même marqué le début du premier hiver de l’IA dans les années 1980 et 1990. Il a fallu attendre la récente mise en œuvre de grands modèles de langage pour découvrir que les réseaux de neurones portent réellement cette pensée logique. Les travaux du neurobiologiste Peter Milner ont inspiré le développement ultérieur des réseaux de neurones artificiels, et c'est pour cette raison qu'il a été invité à y participer. dans ce projet.
 Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
1. Contexte de la construction de la plateforme 58 Portraits Tout d'abord, je voudrais partager avec vous le contexte de la construction de la plateforme 58 Portraits. 1. La pensée traditionnelle de la plate-forme de profilage traditionnelle ne suffit plus. La création d'une plate-forme de profilage des utilisateurs s'appuie sur des capacités de modélisation d'entrepôt de données pour intégrer les données de plusieurs secteurs d'activité afin de créer des portraits d'utilisateurs précis. Elle nécessite également l'exploration de données pour comprendre le comportement et les intérêts des utilisateurs. et besoins, et fournir des capacités côté algorithmes ; enfin, il doit également disposer de capacités de plate-forme de données pour stocker, interroger et partager efficacement les données de profil utilisateur et fournir des services de profil. La principale différence entre une plate-forme de profilage d'entreprise auto-construite et une plate-forme de profilage de middle-office est que la plate-forme de profilage auto-construite dessert un seul secteur d'activité et peut être personnalisée à la demande. La plate-forme de mid-office dessert plusieurs secteurs d'activité et est complexe ; modélisation et offre des fonctionnalités plus générales. 2.58 Portraits d'utilisateurs de l'arrière-plan de la construction du portrait sur la plate-forme médiane 58
 Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !
Mar 14, 2024 pm 11:50 PM
Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !
Mar 14, 2024 pm 11:50 PM
Écrit ci-dessus & La compréhension personnelle de l'auteur est que dans le système de conduite autonome, la tâche de perception est un élément crucial de l'ensemble du système de conduite autonome. L'objectif principal de la tâche de perception est de permettre aux véhicules autonomes de comprendre et de percevoir les éléments environnementaux environnants, tels que les véhicules circulant sur la route, les piétons au bord de la route, les obstacles rencontrés lors de la conduite, les panneaux de signalisation sur la route, etc., aidant ainsi en aval modules Prendre des décisions et des actions correctes et raisonnables. Un véhicule doté de capacités de conduite autonome est généralement équipé de différents types de capteurs de collecte d'informations, tels que des capteurs de caméra à vision panoramique, des capteurs lidar, des capteurs radar à ondes millimétriques, etc., pour garantir que le véhicule autonome peut percevoir et comprendre avec précision l'environnement environnant. éléments , permettant aux véhicules autonomes de prendre les bonnes décisions pendant la conduite autonome. Tête
