
 Périphériques technologiques
IA
L'équipe Byte a proposé le modèle Lynx : compréhension des LLM multimodaux et liste de génération cognitive SoTA
Périphériques technologiques
IA
L'équipe Byte a proposé le modèle Lynx : compréhension des LLM multimodaux et liste de génération cognitive SoTA
L'équipe Byte a proposé le modèle Lynx : compréhension des LLM multimodaux et liste de génération cognitive SoTA

Les grands modèles linguistiques (LLM) actuels tels que GPT4 ont montré d'excellentes capacités multimodales en suivant des instructions ouvertes à partir d'une image. Cependant, les performances de ces modèles dépendent fortement des choix de structure du réseau, des données de formation et des stratégies de formation, mais ces choix n'ont pas été largement discutés dans la littérature précédente. De plus, il existe actuellement un manque de références appropriées pour évaluer et comparer ces modèles, ce qui limite le développement de LLM multimodaux.
 Photos
Photos
- Papier : https://arxiv.org/abs/2307.02469
- Site Web : https://lynx-llm.github.io/
- Code : https : //github.com/bytedance/lynx-llm
Dans cet article, l'auteur mène une étude systématique et complète sur la formation de tels modèles sous des aspects à la fois quantitatifs et qualitatifs. Plus de 20 variantes ont été mises en place. Pour la structure du réseau, différents squelettes de LLM et conceptions de modèles ont été comparés ; pour les données de formation, l'impact des données et des stratégies d'échantillonnage a été étudié en termes d'instructions, l'effet de diverses invites sur le modèle ; l’instruction suivant la capacité a été explorée. Pour les benchmarks, l'article propose pour la première fois Open-VQA, un ensemble d'évaluation de questions-réponses visuelles ouvertes comprenant des tâches d'image et de vidéo.
Sur la base des conclusions expérimentales, l'auteur a proposé Lynx, qui montre la compréhension multimodale la plus précise tout en conservant la meilleure multimodalité par rapport au modèle open source existant de style GPT4 Capacité générative.
Schéma d'évaluation
Différent des tâches typiques de langage visuel, le principal défi de l'évaluation des modèles de style GPT4 est d'équilibrer les performances des capacités de génération de texte et de la précision de la compréhension multimodale. Pour résoudre ce problème, les auteurs proposent un nouveau benchmark Open-VQA incluant des données vidéo et image, et mènent une évaluation complète des modèles open source actuels.
Plus précisément, deux schémas d'évaluation quantitative sont adoptés :
- Collecter un ensemble de tests Open Visual Question Answering (Open-VQA), qui contient des informations sur les objets, l'OCR, le comptage, le raisonnement, la reconnaissance des actions et l'ordre temporel. .et d'autres catégories de questions. Contrairement à l'ensemble de données VQA, qui comporte des réponses standard, les réponses de l'Open-VQA sont ouvertes. Pour évaluer les performances sur Open-VQA, GPT4 est utilisé comme discriminateur et les résultats sont cohérents à 95 % avec une évaluation humaine.
- De plus, l'auteur a utilisé l'ensemble de données OwlEval fourni par mPLUG-owl [1] pour évaluer la capacité de génération de texte du modèle. Bien qu'il ne contienne que 50 images et 82 questions, il couvre la génération d'histoires, la génération de publicités, génération de code, etc. Diverses questions et recrutement d'annotateurs humains pour noter les performances des différents modèles.
Conclusion
Afin d'étudier en profondeur la stratégie de formation des LLM multimodaux, l'auteur part principalement de la structure du réseau (réglage fin des préfixes/attention croisée), des données de formation (sélection des données et rapport de combinaison), instructions (instruction unique/plus de vingt variantes ont été définies dans divers aspects tels qu'une indication diversifiée), modèle LLM (LLaMA [5]/Vicuna [6]), pixels d'image (420/224), etc., et les principales conclusions suivantes ont été tirées à travers des expériences :
- La capacité de suivi d'instruction des LLM multimodaux n'est pas aussi bonne que celle des LLM. Par exemple, InstructBLIP [2] a tendance à générer des réponses courtes quelles que soient les instructions de saisie, tandis que d'autres modèles ont tendance à générer des phrases longues quelles que soient les instructions, ce qui, selon les auteurs, est dû au manque de réponses multiples diversifiées et de haute qualité. modalité causée par les données de commande.
- La qualité des données d'entraînement est cruciale pour les performances du modèle. Sur la base des résultats d'expériences sur différentes données, il a été constaté que l'utilisation d'une petite quantité de données de haute qualité est plus efficace que l'utilisation de données bruitées à grande échelle. L'auteur estime que c'est la différence entre la formation générative et la formation contrastive, car la formation générative apprend directement la distribution conditionnelle des mots plutôt que la similitude entre le texte et les images. Par conséquent, pour de meilleures performances du modèle, deux choses doivent être remplies en termes de données : 1) contenir un texte fluide de haute qualité 2) le contenu du texte et de l'image est bien aligné ;
- Les quêtes et les invites sont essentielles aux capacités de tir zéro. L'utilisation de diverses tâches et instructions peut améliorer la capacité de génération de tir nul du modèle sur des tâches inconnues, ce qui est cohérent avec les observations dans les modèles en texte brut.
- Il est important d’équilibrer l’exactitude et les capacités de génération de langage. Si le modèle est sous-entraîné sur les tâches en aval (telles que VQA), il est plus susceptible de générer du contenu fabriqué qui ne correspond pas à l'entrée visuelle et si le modèle est surentraîné sur les tâches en aval, il aura tendance à générer des réponses courtes ; et ne pourra pas suivre les instructions de l'utilisateur, générer des réponses plus longues.
- Prefix-finetuning (PT) est actuellement la meilleure solution pour l'adaptation multimodale des LLM. Dans les expériences, le modèle avec structure de réglage fin des préfixes peut améliorer la capacité à suivre diverses instructions plus rapidement et est plus facile à entraîner que la structure du modèle avec attention croisée (CA). (Le réglage des préfixes et l'attention croisée sont deux structures modèles, voir la section d'introduction du modèle Lynx pour plus de détails)
Modèle Lynx
L'auteur a proposé Lynx (猞猁)——formation en deux étapes GPT4 -modèle de style avec réglage fin du préfixe. Dans la première étape, environ 120 M paires image-texte sont utilisées pour aligner les intégrations visuelles et linguistiques ; dans la deuxième étape, 20 images ou vidéos sont utilisées pour des tâches multimodales et des données de traitement du langage naturel (NLP) pour ajuster le modèle. capacités de suivi de commandes.
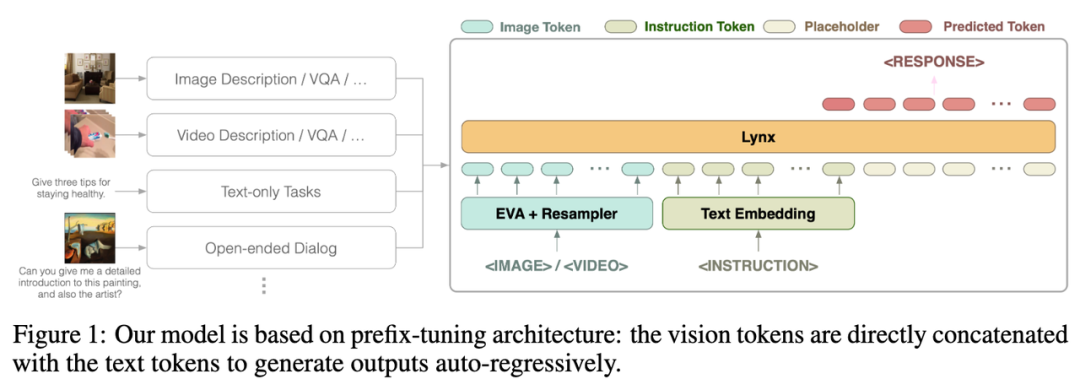 Photos
Photos
La structure globale du modèle Lynx est présentée dans la figure 1 ci-dessus.
L'entrée visuelle est traitée par l'encodeur visuel pour obtenir des jetons visuels (jetons) $$W_v$$ Après le mappage, elle est épissée avec les jetons d'instruction $$W_l$$ comme entrée des LLM. structure est appelée dans cet article. Il s'agit de "prefix-finetuning" pour la distinguer de la structure cross-attention utilisée par Flamingo [3].
De plus, les auteurs ont découvert que les coûts de formation peuvent être encore réduits en ajoutant Adaptateur après certaines couches de LLM gelés.
Effet de modèle
L'auteur a évalué les performances des modèles LLM multimodaux open source existants sur Évaluation manuelle Open-VQA, Mme [4] et OwlEval (voir le tableau ci-dessous pour les résultats, et voir le document détaillé de l’évaluation). On peut voir que le modèle Lynx a obtenu les meilleures performances dans les tâches de compréhension d'images et de vidéos Open-VQA, d'évaluation manuelle OwlEval et de tâches Mme Perception. Parmi eux, InstructBLIP atteint également des performances élevées dans la plupart des tâches, mais sa réponse est trop courte. En comparaison, dans la plupart des cas, le modèle Lynx fournit des raisons concises pour soutenir la réponse basée sur la bonne réponse. convivial (voir la section Affichage des cas ci-dessous pour certains cas).
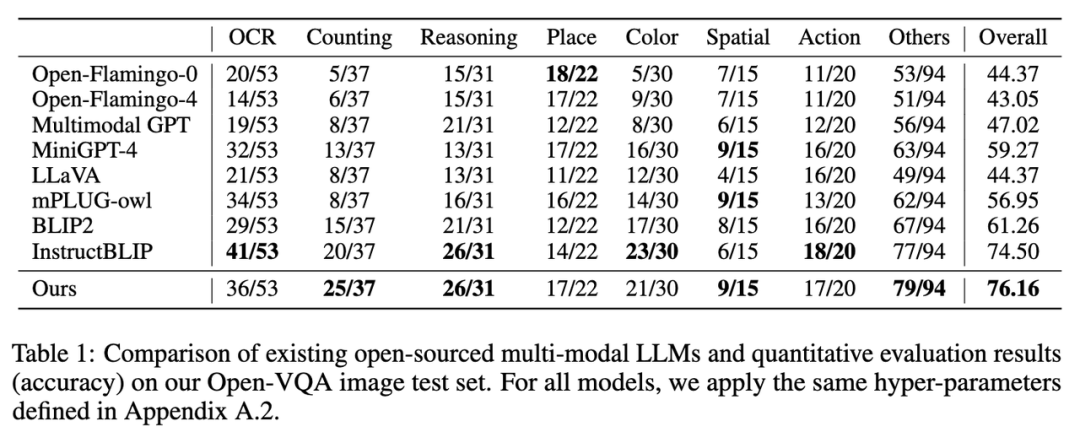
1. Les résultats des indicateurs sur l'ensemble de tests d'images Open-VQA sont présentés dans le tableau 1 ci-dessous :
 Photos
Photos
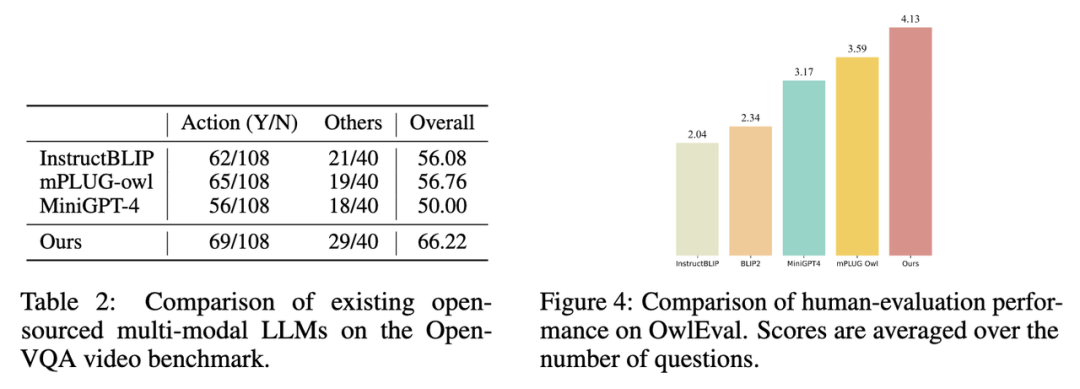
2 Les résultats des indicateurs sur l'ensemble de tests vidéo Open-VQA sont tels qu'indiqués. dans le tableau 1 ci-dessous 2 indiqué.
 photos
photos
3. Sélectionnez le modèle avec le meilleur score dans Open-VQA pour effectuer une évaluation manuelle des effets sur l'ensemble d'évaluation OwlEval. Les résultats sont présentés dans la figure 4 ci-dessus. Il ressort des résultats de l'évaluation manuelle que le modèle Lynx présente les meilleures performances de génération de langage.
 Images
Images
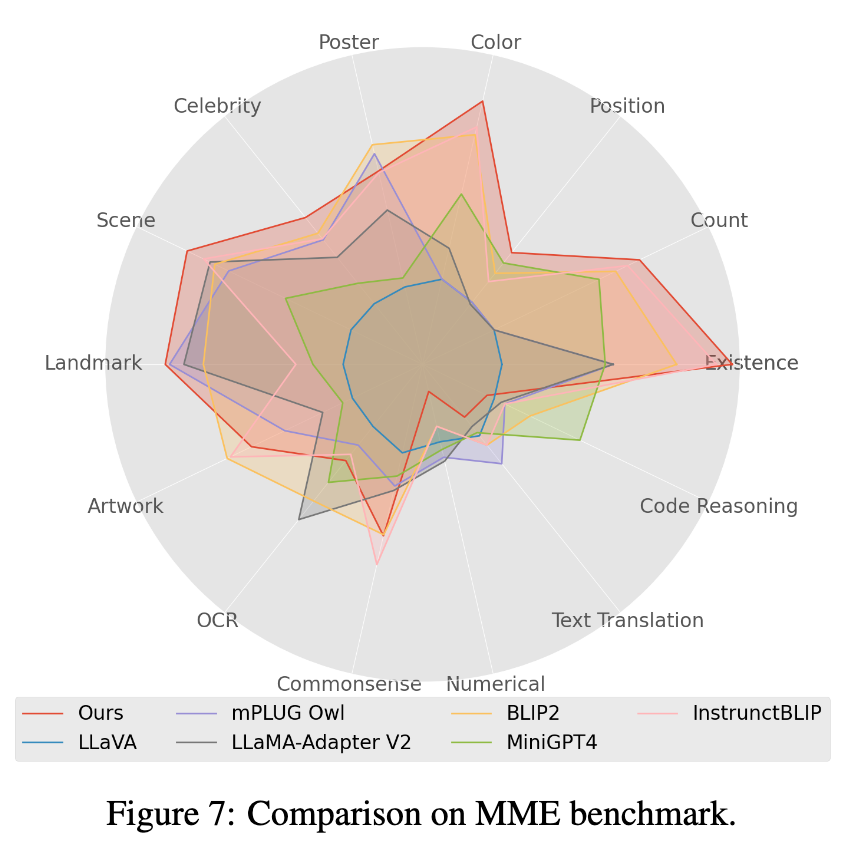
4 Dans le test de référence Mme, les tâches de la classe Perception ont obtenu les meilleures performances, parmi lesquelles 7 des 14 sous-tâches de la classe ont obtenu les meilleures performances. (Voir l'annexe de l'article pour les résultats détaillés) -Boîtier vidéo VQA
Résumé
Dans cet article, à travers des expériences sur plus de vingt variantes de LLM multimodaux, l'auteur détermine le modèle Lynx avec le réglage fin des préfixes comme structure principale et donne un plan d'évaluation Open-VQA avec réponses ouvertes. Les résultats expérimentaux montrent que le modèle Lynx offre la compréhension multimodale la plus précise tout en conservant les meilleures capacités de génération multimodale. 
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Recommandé : Excellent projet de détection et de reconnaissance des visages open source JS
Apr 03, 2024 am 11:55 AM
Recommandé : Excellent projet de détection et de reconnaissance des visages open source JS
Apr 03, 2024 am 11:55 AM
La technologie de détection et de reconnaissance des visages est déjà une technologie relativement mature et largement utilisée. Actuellement, le langage d'application Internet le plus utilisé est JS. La mise en œuvre de la détection et de la reconnaissance faciale sur le front-end Web présente des avantages et des inconvénients par rapport à la reconnaissance faciale back-end. Les avantages incluent la réduction de l'interaction réseau et de la reconnaissance en temps réel, ce qui réduit considérablement le temps d'attente des utilisateurs et améliore l'expérience utilisateur. Les inconvénients sont les suivants : il est limité par la taille du modèle et la précision est également limitée ; Comment utiliser js pour implémenter la détection de visage sur le web ? Afin de mettre en œuvre la reconnaissance faciale sur le Web, vous devez être familier avec les langages et technologies de programmation associés, tels que JavaScript, HTML, CSS, WebRTC, etc. Dans le même temps, vous devez également maîtriser les technologies pertinentes de vision par ordinateur et d’intelligence artificielle. Il convient de noter qu'en raison de la conception du côté Web
 Fraichement publié! Un modèle open source pour générer des images de style anime en un seul clic
Apr 08, 2024 pm 06:01 PM
Fraichement publié! Un modèle open source pour générer des images de style anime en un seul clic
Apr 08, 2024 pm 06:01 PM
Permettez-moi de vous présenter le dernier projet open source AIGC-AnimagineXL3.1. Ce projet est la dernière itération du modèle texte-image sur le thème de l'anime, visant à offrir aux utilisateurs une expérience de génération d'images d'anime plus optimisée et plus puissante. Dans AnimagineXL3.1, l'équipe de développement s'est concentrée sur l'optimisation de plusieurs aspects clés pour garantir que le modèle atteigne de nouveaux sommets en termes de performances et de fonctionnalités. Premièrement, ils ont élargi les données d’entraînement pour inclure non seulement les données des personnages du jeu des versions précédentes, mais également les données de nombreuses autres séries animées bien connues dans l’ensemble d’entraînement. Cette décision enrichit la base de connaissances du modèle, lui permettant de mieux comprendre les différents styles et personnages d'anime. AnimagineXL3.1 introduit un nouvel ensemble de balises et d'esthétiques spéciales
 Le document multimodal Alibaba 7B comprenant le grand modèle remporte le nouveau SOTA
Apr 02, 2024 am 11:31 AM
Le document multimodal Alibaba 7B comprenant le grand modèle remporte le nouveau SOTA
Apr 02, 2024 am 11:31 AM
Nouveau SOTA pour des capacités de compréhension de documents multimodaux ! L'équipe Alibaba mPLUG a publié le dernier travail open source mPLUG-DocOwl1.5, qui propose une série de solutions pour relever les quatre défis majeurs que sont la reconnaissance de texte d'image haute résolution, la compréhension générale de la structure des documents, le suivi des instructions et l'introduction de connaissances externes. Sans plus tarder, examinons d’abord les effets. Reconnaissance et conversion en un clic de graphiques aux structures complexes au format Markdown : Des graphiques de différents styles sont disponibles : Une reconnaissance et un positionnement de texte plus détaillés peuvent également être facilement traités : Des explications détaillées sur la compréhension du document peuvent également être données : Vous savez, « Compréhension du document " est actuellement un scénario important pour la mise en œuvre de grands modèles linguistiques. Il existe de nombreux produits sur le marché pour aider à la lecture de documents. Certains d'entre eux utilisent principalement des systèmes OCR pour la reconnaissance de texte et coopèrent avec LLM pour le traitement de texte.
