
Un morceau de code
Cette fois, je prendrai le langage Go comme exemple. Le langage Go est un langage de type C, et certaines des couches sous-jacentes sont très similaires !
Code
package main
import (
"fmt"
"unsafe"
)
func main() {
//定义一个 字符a
var a = 'a'
//定义一个 正 整数3
var b uint8 = 3
var c uint8 = 98
fmt.Printf("值:%c,十进制:%d,类型:%T,二进制:%b,大小%v字节\n", a, a, a, a, unsafe.Sizeof(a)) // 4个字节
fmt.Printf("值%d,十进制:%d,类型:%T,二进制%b,大小%v字节\n", b, b, b, b, unsafe.Sizeof(b)) //一个字节
fmt.Printf("值%c,十进制,%d,类型:%T,二进制%b,大小%v字节\n", c, c, c, c,unsafe.Sizeof(c)) //一个字节
}Résultats d'exécution

Il y a plusieurs questions
Quand je nomme une variable, j'utilise le caractère a, pourquoi la valeur décimale est-elle 97 ? Le binaire est 1100001 ?
Pourquoi la variable c s'appelle-t-elle 98 mais peut-elle afficher b ?
Pour comprendre les enjeux ci-dessus, il faut encore comprendre les enjeux essentiels.
Notre programme s'exécute en mémoire après tout.
Et notre module de mémoire est probablement comme ça.
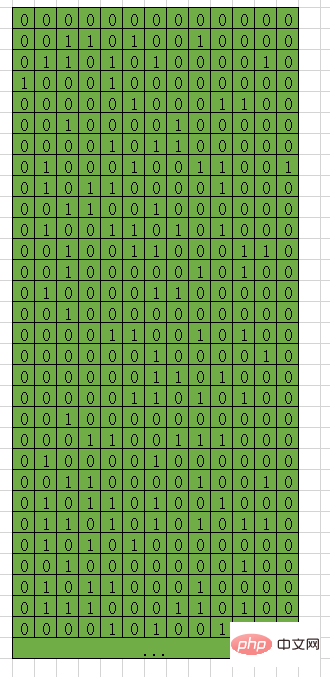
L'essence des clés USB est essentiellement composants électroniques Après tout, il n'y a que deux états, allumé (1), non allumé. (0).
un composant électronique, est un bit.
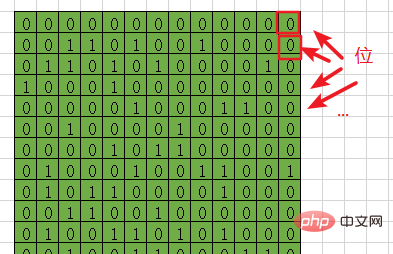
Et un octet , est égal à 8 bits , 1字节=8位 .
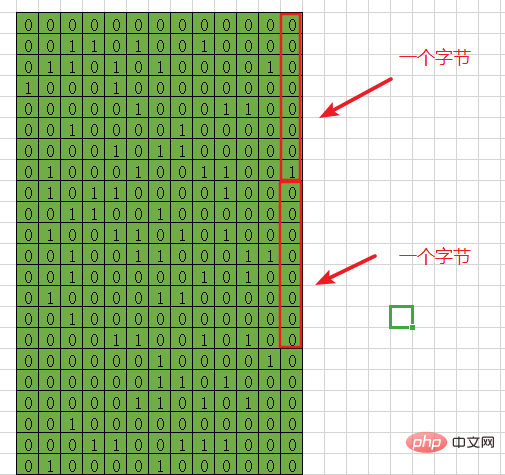
Un bit est un 0 ou 1, qui est binaire , non-0 est 1.
Un octet correspond à 8 0 ou 1 s, comme ceci, 00000000,Si vous voyez moins de 8 0 ou 1, remplissez les premiers avec des 0, Assez pour 8 les gens.
Normalement, le langage ne fonctionne généralement que sur des octets, et fonctionne rarement sur place.
Bien que nous sachions ce qui précède, un bit signifie une alimentation ou pas d'alimentation 's Composants électroniques .
Un octet représente une combinaison de 8 ou ou composants électroniques non alimentés. Mais cela ne résout pas le problème réel. Je veux enregistrer un 10, ajouter un 20 et effectuer des calculs d'addition. Que dois-je faire ? ? ?
Donc en ce moment, il doit y avoir une règle, selon que ce qui est allumé ou ce qui n'est pas allumé signifie ce que c'est.
Alors voilà
ASCIICette spécification, la plus petite unité de cette spécification est un octet, c'est-à-dire que ASCII这个规范,这个规范的最小单位是字节,也就是同时管理8个0或1。
比如说,第一个字节,就是前八位,如果说全部都是0,就表示的是十进制数字0。
8个二进制表示方式是00000000 gère 8 0 ou 1 en même temps
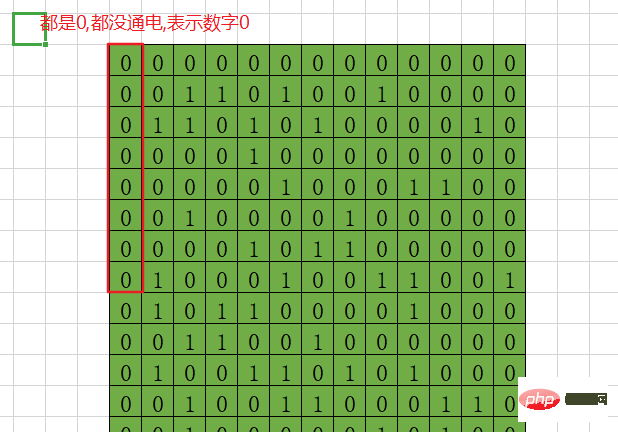
8 La représentation binaire est

等等等等,通过字节组织位,通过每8位不同的组合,表示不同的符号或者数字或者字母等。
具体二进制对应的符号或者数字:https://baike.baidu.com/item/ASCII/309296?fromtitle=ASCII%E7%BC%96%E7%A0%81&fromid=3712529&fr=aladdin
通过查询ASCII可知。
字母a的二进制是0110 0001,十进制是97,表示的符号是a
et ainsi de suite, organisés bits par octets, toutes les 8 combinaisons différentes de bits représentent différents symboles, chiffres, lettres, etc.
Symboles ou nombres binaires correspondants spécifiques :🎜https:/ / baike.baidu.com/item/ASCII/309296?fromtitle=ASCII%E7%BC%96%E7%A0%81&fromid=3712529&fr=aladdin🎜🎜🎜Par requête🎜🎜ASCII🎜🎜peut être connu. 🎜🎜
🎜lettres Le binaire de a est 🎜🎜0110 0001🎜🎜, la décimale est 🎜🎜97🎜🎜, le symbole représenté est 🎜🎜a🎜🎜. 🎜🎜🎜🎜🎜
Alors avouons-le au début !
Pourquoi 98 peut afficher b ? C'est parce que ASCIIASCII,因为98代表的就是字母b,就是二进制0110 0010。
只不过是输出方式不一样。
目前的编码方向
其实一个字节,8位,如果全部亮灯,就是11111111,他的十进制是255, car 98 représente la lettre b, qui est binaire0110 0010
.
uniquement Mais la méthode de sortie est différente. 🎜🎜 🎜
🎜
🎜Direction actuelle de l'encodage🎜🎜
🎜 Dans en fait, un octet, 8 bits, si tous les voyants sont allumés, équivaut à 🎜🎜11111111🎜🎜, sa décimale est 🎜🎜255🎜🎜, théoriquement, il peut prendre en charge 255 symboles. 🎜🎜🎜🎜Cela devrait suffire pour les pays anglophones. Une lettre fait 8 bits et un octet pour stocker un bonjour fait 5 octets. 🎜🎜
Mais de nos jours, les ordinateurs sont devenus un arbre imposant. La Chine les utilise, le Japon les utilise et les bâtons sont utilisés. Le nombre total de caractères dans chaque pays n'est plus aussi simple que 255.
Il est donc dérivé comme celui de la Chine GBKGBK等一些编码,各种编码都是基于ASCII扩充的。
ASCII占一个字节,8位,那我GBK不够啊,几万个汉字呢,那我占俩字节,16位,16个0或者1,应该凑合吧,再不行三个字节,24个0或1,三个字节十进制就已经到16777215了,上千万了,足够保存各国的符号和文字了。
但是GBK和其他编码又不通用,所以现在又衍生出utf-8 et quelques autres codes, divers codes sont basés sur ASCII
🎜 étendu. 🎜🎜🎜GBK
16777215🎜🎜, des dizaines de millions, de quoi préserver les symboles et caractères de divers pays. 🎜🎜🎜Mais 🎜🎜目前 utf-8 dimensionnement : border-box;break-after: éviter-page;break-inside: éviter;police-size: 1.75em;marge-top: 1rem;marge-inférieure: 1rem;font-weight: bold;line-height: 1.225; curseur : texte ; remplissage en bas : 0,3 em ; bordure en bas : 1 px solide RVB (238, 238, 238 ); espace blanc : pré-enveloppement ; famille de polices : 'Open Sans', 'Clear Sans', 'Helvetica Neue', Helvetica, Arial, sans-serif;text-align: start;">utf-8是一个最好的编码,基本已经支持所以计算机。
总结
本篇主要是理解计算机内存的本质,1字节=8位,1位=一个通电or没通电的电子元件,通过不同的00101010总结
1字节=8位,
Étiquettes associées:
 Utilisation du mot-clé Type dans Go
Utilisation du mot-clé Type dans Go
 Comment implémenter une liste chaînée en go
Comment implémenter une liste chaînée en go
 Que sont les logiciels de programmation en langage Go ?
Que sont les logiciels de programmation en langage Go ?
 Comment apprendre le langage go à partir de 0 bases
Comment apprendre le langage go à partir de 0 bases
 Quelles sont les méthodes pour implémenter la surcharge d'opérateurs en langage Go ?
Quelles sont les méthodes pour implémenter la surcharge d'opérateurs en langage Go ?
 Quels sont les opérateurs en langage Go ?
Quels sont les opérateurs en langage Go ?
 l'espacement des lettres
l'espacement des lettres
 css
css
 La différence entre rom et bélier
La différence entre rom et bélier


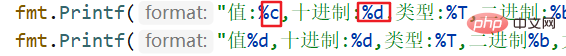










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



