
 Périphériques technologiques
IA
Le rapport académique ACL de Chen Danqi est ici ! Explication détaillée des 7 grandes orientations et 3 enjeux majeurs de la base de données 'plug-in' grand modèle, 3 heures pleines d'informations utiles
Périphériques technologiques
IA
Le rapport académique ACL de Chen Danqi est ici ! Explication détaillée des 7 grandes orientations et 3 enjeux majeurs de la base de données 'plug-in' grand modèle, 3 heures pleines d'informations utiles
Le rapport académique ACL de Chen Danqi est ici ! Explication détaillée des 7 grandes orientations et 3 enjeux majeurs de la base de données 'plug-in' grand modèle, 3 heures pleines d'informations utiles

Chen Danqi, ancien élève de la classe Tsinghua Yao, a prononcé un dernier discours à l'ACL 2023 !
Le sujet est encore un domaine de recherche très brûlant récemment - comme GPT-3, PaLM et d'autres(grands)modèles linguistiques, ont-ils besoin de s'appuyer sur la récupération pour compenser leurs propres lacunes, afin de mieux mettre en œuvre leurs applications ?
Dans ce discours, elle et trois autres intervenants ont présenté conjointement plusieurs axes de recherche majeurs sur ce sujet, notamment les méthodes de formation, leurs applications et leurs enjeux. Photos
Photos
 Photos
Photos
 Photos
Photos
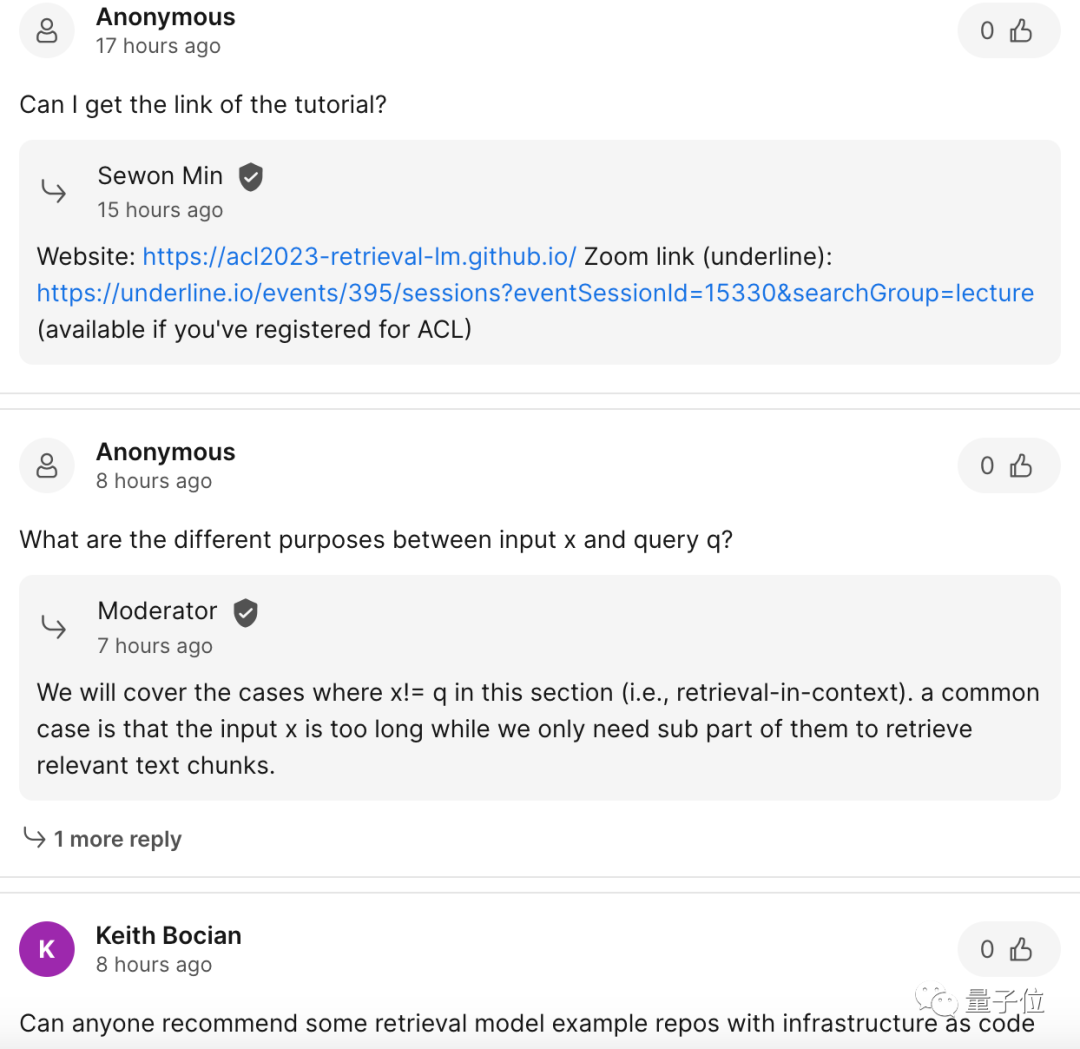
Récupération et Modèle linguistique.
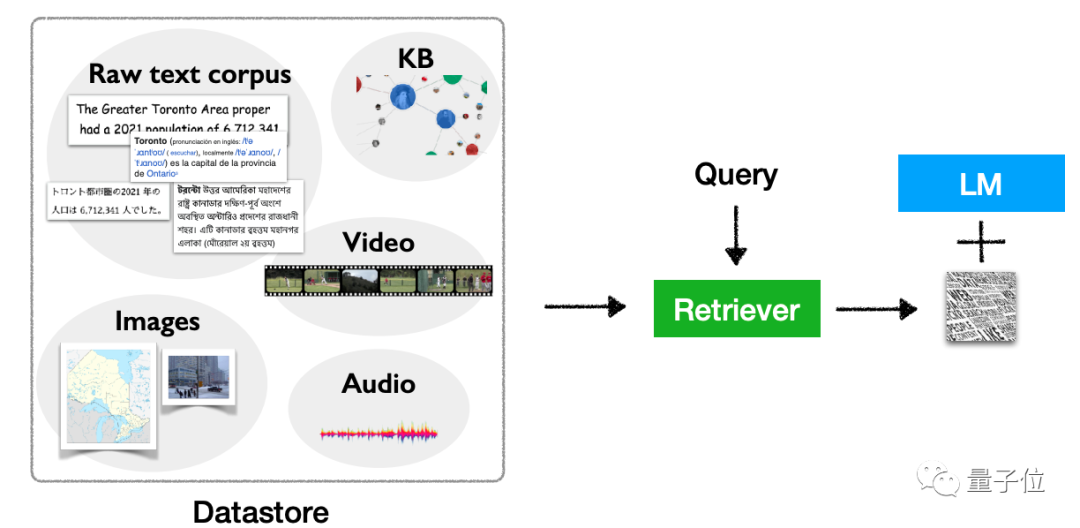
D'après ladéfinition, cela fait référence au "branchement" d'une base de données de récupération de données au modèle de langage, à la récupération de cette base de données lors de l'exécution de l'inférence (et d'autres opérations) , et enfin à la sortie basée sur les résultats de la récupération.
Ce type de référentiel de données de plug-ins est également appelé modèle semi-paramétrique ou modèle non paramétrique.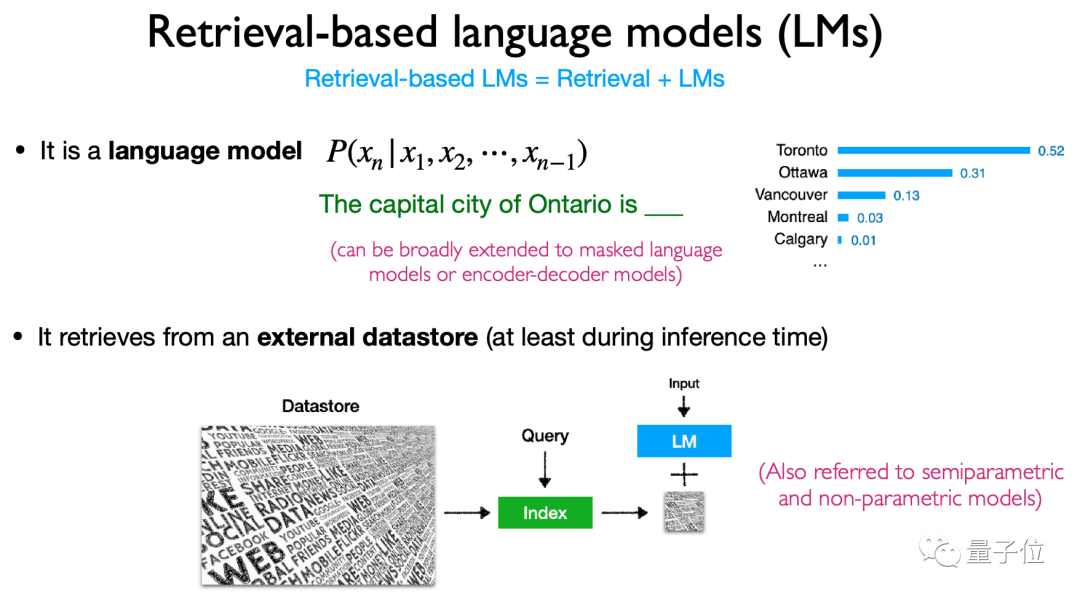 Photos
Photos
(grands)les modèles de langage tels que GPT-3 et PaLM ont montré de bons résultats, mais il y a aussi eu quelques maux de tête." bug", il y a trois problèmes principaux :
1, Le nombre de paramètres est trop grand, et si le réentraînement est basé sur de nouvelles données, le coût de calcul est trop élevé
2, La mémoire n'est pas bonne (Face à une longue période ; textes, j'oublie de me souvenir de ce qui suit ci-dessus) , cela provoquera des hallucinations avec le temps, et il est facile de divulguer des données
3 Avec le nombre actuel de paramètres, il est impossible de se souvenir de toutes les connaissances ;
architecture, de la formation, de la multimodalité, des applications et des défis spécifiques de cette direction de recherche.
Dans l'architecture, il introduit principalement le contenu, la méthode de récupération et le « timing » de récupération basé sur la récupération du modèle de langage.
Plus précisément, ce type de modèle récupère principalement des jetons, des blocs de texte et des mots d'entité(mentions d'entité) Les méthodes et le calendrier d'utilisation de la récupération sont également très divers, ce qui en fait une architecture de modèle très flexible.
 images
images
formation, il se concentre sur la formation indépendante (la formation indépendante, le modèle de langage et le modèle de récupération sont formés séparément), l'apprentissage continu (formation séquentielle) et le multitâche apprentissage(formation conjointe) et autres méthodes.
 Photos
Photos
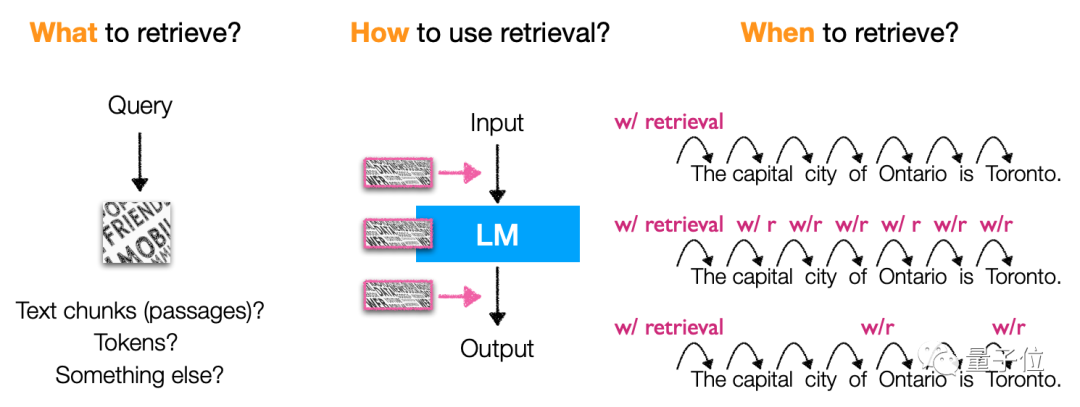
application, ce type de modèle implique beaucoup de choses. Il peut non seulement être utilisé dans la génération de code, la classification, la PNL à forte intensité de connaissances et d'autres tâches, mais également pour le réglage fin, le renforcement. l'apprentissage, basé sur les mots d'invite de recherche et d'autres méthodes, peut être utilisé.
Les scénarios d'application sont également très flexibles, y compris des scénarios à longue traîne, des scénarios nécessitant une mise à jour des connaissances et des scénarios impliquant la confidentialité et la sécurité, etc. Ce type de modèle a sa place à utiliser.Bien sûr, il ne s’agit pas seulement de texte. Ce type de modèle présente également un potentiel d'expansion multimodale, lui permettant d'être utilisé pour des tâches autres que le texte.
 Photos
Photos
Il semble que ce type de modèle présente de nombreux avantages, mais il existe également des défis basés sur des modèles de langage basés sur la récupération.
Dans son discours final de « clôture », Chen Danqi a souligné plusieurs problèmes majeurs qui doivent être résolus dans cette direction de recherche.
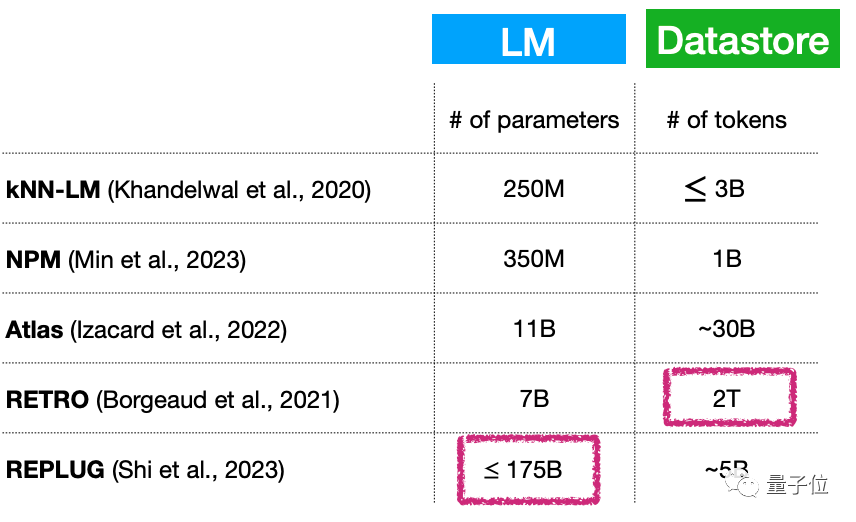
Premièrement, petit modèle de langage + (en expansion continue) grande base de données, cela signifie-t-il essentiellement que le nombre de paramètres du modèle de langage est encore très grand ? Comment résoudre ce problème ?
Par exemple, bien que le nombre de paramètres de ce type de modèle puisse être très faible, seulement 7 milliards de paramètres, la base de données du plug-in peut atteindre 2T...
 Images
Images
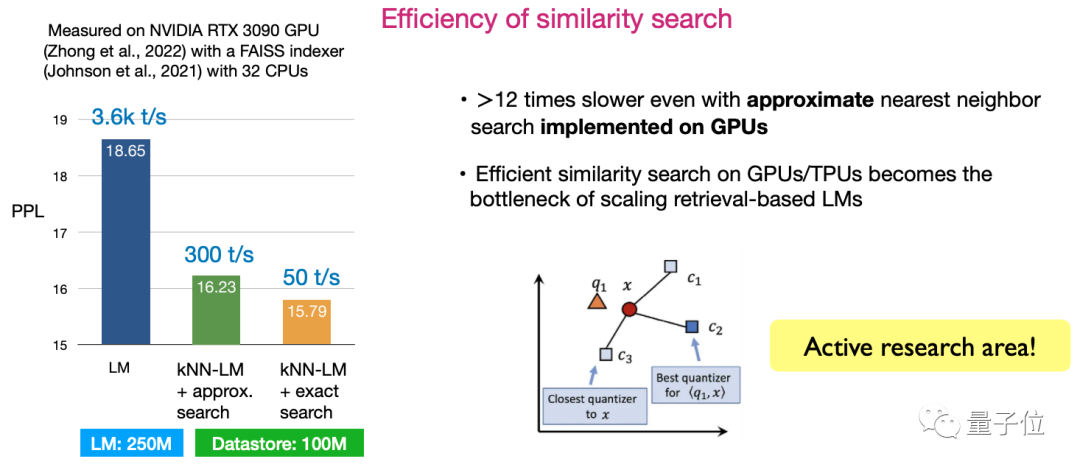
Deuxièmement, l'efficacité de la similarité recherche. Comment concevoir des algorithmes pour maximiser l’efficacité de la recherche est actuellement une direction de recherche très active.
 Images
Images
Troisièmement, effectuez des tâches linguistiques complexes. Y compris les tâches de génération de texte ouvertes et les tâches de raisonnement de texte complexes, la manière d'utiliser des modèles de langage basés sur la récupération pour accomplir ces tâches est également une direction qui nécessite une exploration continue.
 Photos
Photos
Bien sûr, Chen Danqi a également mentionné que ces sujets ne sont pas seulement des défis, mais aussi des opportunités de recherche. Amis qui recherchent encore des sujets de thèse, vous pouvez envisager de les ajouter à la liste de recherche ~
Il convient de mentionner que ce discours n'est pas un sujet « sorti de nulle part ». Les quatre intervenants l'ont pensivement mentionné sur le fonctionnaire. site Web Des liens vers les articles référencés dans le discours ont été publiés.
De l'architecture des modèles, aux méthodes de formation, aux applications, à la multimodalité jusqu'aux challenges, si l'un de ces sujets vous intéresse, vous pouvez vous rendre sur le site officiel pour retrouver les articles classiques correspondants :
 Photos
Photos
Sur place Répondre à la confusion du public
Pour un discours aussi instructif, les quatre conférenciers principaux ne sont pas sans expérience. Au cours du discours, ils ont également patiemment répondu aux questions soulevées par le public.
Parlons d’abord de qui sont les locuteurs de Kangkang.
Le premier est Chen Danqi, professeur adjoint d'informatique à l'Université de Princeton qui a dirigé ce discours.
 Photos
Photos
Elle est récemment l'une des jeunes universitaires chinoises les plus populaires dans le domaine de l'informatique et est également une ancienne élève de la classe Tsinghua Yao en 2008.
Dans le cercle des compétitions informatiques, elle est assez légendaire - l'algorithme CDQ diviser pour mieux régner porte son nom. En 2008, elle a remporté une médaille d'or de l'IOI au nom de l'équipe chinoise.
Et sa thèse de doctorat de 156 pages « Neural Reading Comprehension and Beyond » est devenue très populaire. Non seulement elle a remporté le prix de la meilleure thèse de doctorat de Stanford cette année-là, mais elle est également devenue le sujet le plus populaire à l'Université de Stanford au cours des dix dernières années. . Un des mémoires de fin d'études.
Maintenant, en plus d'être professeur adjoint d'informatique à l'Université de Princeton, Chen Danqi est également co-responsable de l'équipe PNL de l'école et membre de l'équipe AIML.
Son axe de recherche porte principalement sur le traitement du langage naturel et l'apprentissage automatique, et elle s'intéresse aux méthodes simples et fiables, réalisables, évolutives et généralisables à des problèmes pratiques.
Également de l'Université de Princeton, il y a l'apprenti de Chen Danqi Zexuan Zhong(Zexuan Zhong).
 Photos
Photos
Zhong Zexuan est étudiant en quatrième année de doctorat à l'Université de Princeton. J'ai obtenu une maîtrise de l'Université de l'Illinois à Urbana-Champaign et mon mentor était Xie Tao ; j'ai obtenu une licence du département d'informatique de l'Université de Pékin et j'ai travaillé comme stagiaire chez Microsoft Research Asia, et mon Le mentor était Nie Zaiqing.
Ses dernières recherches se concentrent sur l'extraction d'informations structurées à partir de textes non structurés, l'extraction d'informations factuelles à partir de modèles linguistiques pré-entraînés, l'analyse des capacités de généralisation des modèles de récupération denses et le développement d'une formation à la technologie des modèles linguistiques basés sur la récupération.
De plus, les conférenciers principaux incluent Akari Asai et Sewon Min de Université de Washington.
 Photos
Photos
Akari Asai est un doctorant de quatrième année à l'Université de Washington avec spécialisation en traitement du langage naturel. Il est diplômé de l'Université de Tokyo au Japon avec son diplôme de premier cycle.
Elle s'intéresse principalement au développement de systèmes de traitement du langage naturel fiables et adaptables pour améliorer les capacités d'acquisition d'informations.
Récemment, ses recherches se concentrent principalement sur les systèmes de récupération de connaissances générales, les modèles PNL adaptatifs efficaces et d'autres domaines.
 Pictures
Pictures
Sewon Min est doctorant au sein du groupe de traitement du langage naturel de l'Université de Washington. Au cours de ses études de doctorat, il a travaillé à temps partiel comme chercheur chez Meta AI pendant quatre ans. de l'Université nationale de Séoul avec un baccalauréat.
Récemment, elle se concentre principalement sur la modélisation du langage, la récupération et l'intersection des deux.
Pendant le discours, le public a également soulevé avec enthousiasme de nombreuses questions, comme par exemple pourquoi la perplexité(perplexité) est utilisée comme principal indicateur du discours.
 Photos
Photos
L'orateur a donné une réponse prudente :
Lors de la comparaison de modèles de langage paramétrés, la perplexité (PPL) est souvent utilisée. Mais la question de savoir si les améliorations apportées à la perplexité peuvent se traduire par des applications en aval reste une question de recherche.
La recherche a maintenant montré que la perplexité est bien corrélée aux tâches en aval (en particulier les tâches de génération) et que la perplexité fournit souvent des résultats très stables, et qu'elle peut être évaluée sur des données d'évaluation à grande échelle (les données d'évaluation ne sont pas étiquetées par rapport aux tâches en aval , qui peut être affecté par la sensibilité des signaux et le manque de données étiquetées à grande échelle, conduisant à des résultats instables) .
 Photos
Photos
Certains internautes ont soulevé cette question :
Concernant l'affirmation selon laquelle "le coût de formation des modèles de langage est élevé et l'introduction de la récupération peut résoudre ce problème", vous remplacez simplement la complexité temporelle par l'espace. complexité (stockage des données) ?

La réponse donnée par l'oratrice est celle de tante Jiang :
L'objectif de notre discussion est de savoir comment réduire le modèle de langage à une taille plus petite, réduisant ainsi les besoins en temps et en espace. Cependant, le stockage des données ajoute également des frais supplémentaires, qui doivent être soigneusement pesés et étudiés, et nous pensons qu'il s'agit d'un défi actuel.
Par rapport à la formation d'un modèle de langage avec plus de 10 milliards de paramètres, je pense que le plus important en ce moment est de réduire le coût de la formation.
 Photos
Photos
Si vous souhaitez retrouver le PPT de ce discours, ou regarder la lecture spécifique, vous pouvez vous rendre sur le site officiel~
Site officiel : https://acl2023-retrieval- lm.github.io /
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
À la pointe de la technologie logicielle, le groupe de l'UIUC Zhang Lingming, en collaboration avec des chercheurs de l'organisation BigCode, a récemment annoncé le modèle de grand code StarCoder2-15B-Instruct. Cette réalisation innovante a permis une percée significative dans les tâches de génération de code, dépassant avec succès CodeLlama-70B-Instruct et atteignant le sommet de la liste des performances de génération de code. Le caractère unique de StarCoder2-15B-Instruct réside dans sa stratégie d'auto-alignement pur. L'ensemble du processus de formation est ouvert, transparent et complètement autonome et contrôlable. Le modèle génère des milliers d'instructions via StarCoder2-15B en réponse au réglage fin du modèle de base StarCoder-15B sans recourir à des annotations manuelles coûteuses.
 Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Afin d'aligner les grands modèles de langage (LLM) sur les valeurs et les intentions humaines, il est essentiel d'apprendre les commentaires humains pour garantir qu'ils sont utiles, honnêtes et inoffensifs. En termes d'alignement du LLM, une méthode efficace est l'apprentissage par renforcement basé sur le retour humain (RLHF). Bien que les résultats de la méthode RLHF soient excellents, certains défis d’optimisation sont impliqués. Cela implique de former un modèle de récompense, puis d'optimiser un modèle politique pour maximiser cette récompense. Récemment, certains chercheurs ont exploré des algorithmes hors ligne plus simples, dont l’optimisation directe des préférences (DPO). DPO apprend le modèle politique directement sur la base des données de préférence en paramétrant la fonction de récompense dans RLHF, éliminant ainsi le besoin d'un modèle de récompense explicite. Cette méthode est simple et stable
 Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Jun 07, 2024 pm 12:05 PM
Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Jun 07, 2024 pm 12:05 PM
1. Introduction Au cours des dernières années, les YOLO sont devenus le paradigme dominant dans le domaine de la détection d'objets en temps réel en raison de leur équilibre efficace entre le coût de calcul et les performances de détection. Les chercheurs ont exploré la conception architecturale de YOLO, les objectifs d'optimisation, les stratégies d'expansion des données, etc., et ont réalisé des progrès significatifs. Dans le même temps, le recours à la suppression non maximale (NMS) pour le post-traitement entrave le déploiement de bout en bout de YOLO et affecte négativement la latence d'inférence. Dans les YOLO, la conception de divers composants manque d’une inspection complète et approfondie, ce qui entraîne une redondance informatique importante et limite les capacités du modèle. Il offre une efficacité sous-optimale et un potentiel d’amélioration des performances relativement important. Dans ce travail, l'objectif est d'améliorer encore les limites d'efficacité des performances de YOLO à la fois en post-traitement et en architecture de modèle. à cette fin
 Le LLM est terminé ! OmniDrive : Intégration de la perception 3D et de la planification du raisonnement (la dernière version de NVIDIA)
May 09, 2024 pm 04:55 PM
Le LLM est terminé ! OmniDrive : Intégration de la perception 3D et de la planification du raisonnement (la dernière version de NVIDIA)
May 09, 2024 pm 04:55 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : cet article est dédié à la résolution des principaux défis des grands modèles de langage multimodaux (MLLM) actuels dans les applications de conduite autonome, c'est-à-dire le problème de l'extension des MLLM de la compréhension 2D à l'espace 3D. Cette expansion est particulièrement importante car les véhicules autonomes (VA) doivent prendre des décisions précises concernant les environnements 3D. La compréhension spatiale 3D est essentielle pour les véhicules utilitaires car elle a un impact direct sur la capacité du véhicule à prendre des décisions éclairées, à prédire les états futurs et à interagir en toute sécurité avec l’environnement. Les modèles de langage multimodaux actuels (tels que LLaVA-1.5) ne peuvent souvent gérer que des entrées d'images de résolution inférieure (par exemple) en raison des limitations de résolution de l'encodeur visuel et des limitations de la longueur de la séquence LLM. Cependant, les applications de conduite autonome nécessitent
 Li Feifei révèle l'orientation entrepreneuriale de « l'intelligence spatiale » : la visualisation se transforme en aperçu, la vue devient compréhension et la compréhension mène à l'action
Jun 01, 2024 pm 02:55 PM
Li Feifei révèle l'orientation entrepreneuriale de « l'intelligence spatiale » : la visualisation se transforme en aperçu, la vue devient compréhension et la compréhension mène à l'action
Jun 01, 2024 pm 02:55 PM
Stanford Li Feifei a dévoilé pour la première fois le nouveau concept « d'intelligence spatiale » après avoir lancé sa propre entreprise. Ce n'est pas seulement son orientation entrepreneuriale, mais aussi « l'étoile du Nord » qui la guide, elle la considère comme « la pièce clé du puzzle pour résoudre le problème de l'intelligence artificielle ». La visualisation mène à la perspicacité ; la vue mène à la compréhension ; la compréhension mène à l’action. Basé sur la conférence TED de 15 minutes de Li Feifei, il est entièrement révélé, depuis l'origine de l'évolution de la vie il y a des centaines de millions d'années, jusqu'à la façon dont les humains ne sont pas satisfaits de ce que la nature leur a donné et développent l'intelligence artificielle, jusqu'à la façon de construire l'intelligence spatiale dans la prochaine étape. Il y a neuf ans, Li Feifei a présenté au monde le nouveau ImageNet sur la même scène - l'un des points de départ de cette explosion d'apprentissage profond. Elle a elle-même encouragé les internautes : si vous regardez les deux vidéos, vous pourrez comprendre la vision par ordinateur des 10 dernières années.
 L'Université Tsinghua a pris le relais et YOLOv10 est sorti : les performances ont été grandement améliorées et il figurait sur la hot list de GitHub
Jun 06, 2024 pm 12:20 PM
L'Université Tsinghua a pris le relais et YOLOv10 est sorti : les performances ont été grandement améliorées et il figurait sur la hot list de GitHub
Jun 06, 2024 pm 12:20 PM
La série de référence YOLO de systèmes de détection de cibles a une fois de plus reçu une mise à niveau majeure. Depuis la sortie de YOLOv9 en février de cette année, le relais de la série YOLO (YouOnlyLookOnce) a été passé entre les mains de chercheurs de l'Université Tsinghua. Le week-end dernier, la nouvelle du lancement de YOLOv10 a attiré l'attention de la communauté IA. Il est considéré comme un cadre révolutionnaire dans le domaine de la vision par ordinateur et est connu pour ses capacités de détection d'objets de bout en bout en temps réel, poursuivant l'héritage de la série YOLO en fournissant une solution puissante alliant efficacité et précision. Adresse de l'article : https://arxiv.org/pdf/2405.14458 Adresse du projet : https://github.com/THU-MIG/yo
