
Il y a quelques jours, un fan est venu me voir pour obtenir des informations sur le fonds. Je le partagerai ici. Les amis intéressés peuvent également l'essayer activement.
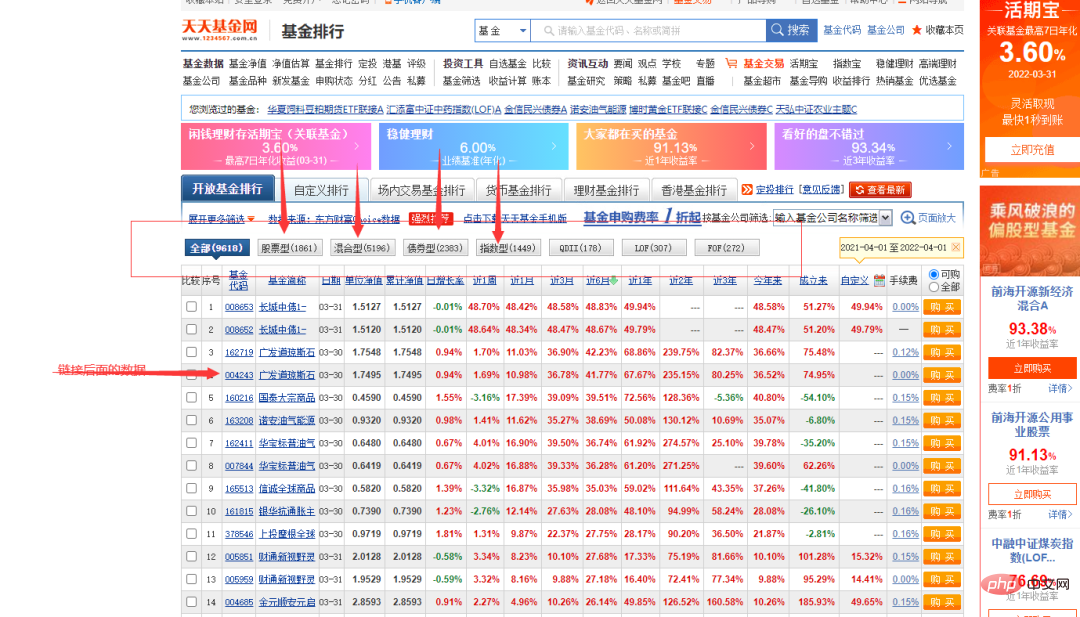
Ici, notre site Web cible est le site officiel d'un fonds, et les données qui doivent être capturées sont comme indiqué dans la figure ci-dessous.
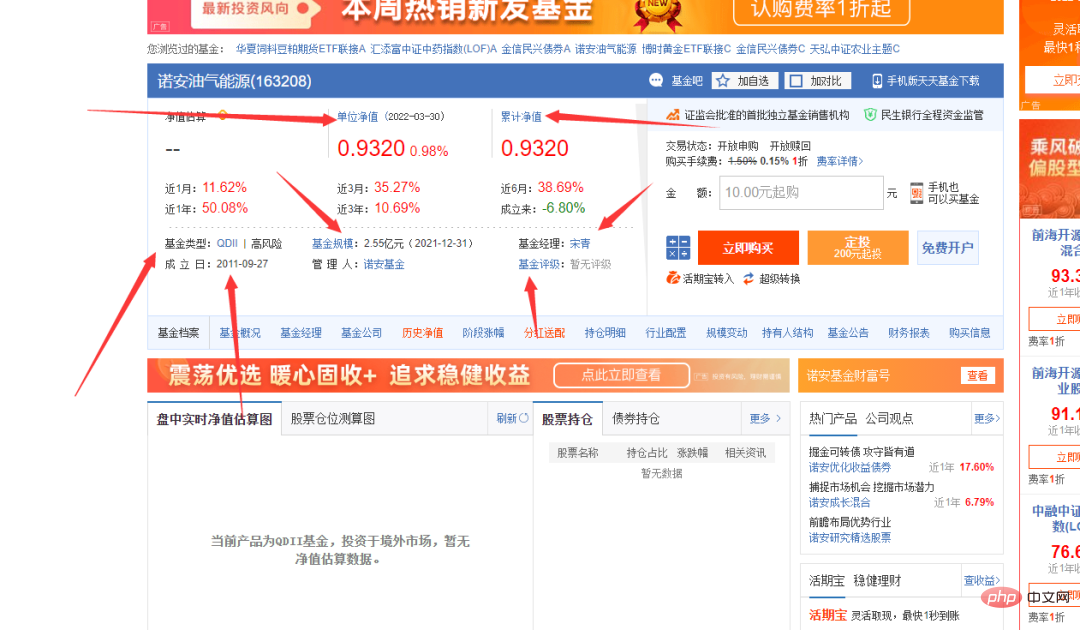 Vous pouvez voir que la colonne du code du fonds dans l'image ci-dessus comporte des numéros différents. Cliquez sur un au hasard pour accéder à la page de détails du fonds. Les liens sont également très réguliers, avec le code du fonds comme symbole.
Vous pouvez voir que la colonne du code du fonds dans l'image ci-dessus comporte des numéros différents. Cliquez sur un au hasard pour accéder à la page de détails du fonds. Les liens sont également très réguliers, avec le code du fonds comme symbole.
En fait, ce site Web n'est pas difficile. Les données ne sont pas cryptées. Les informations sur la page Web sont visibles directement dans le code source. 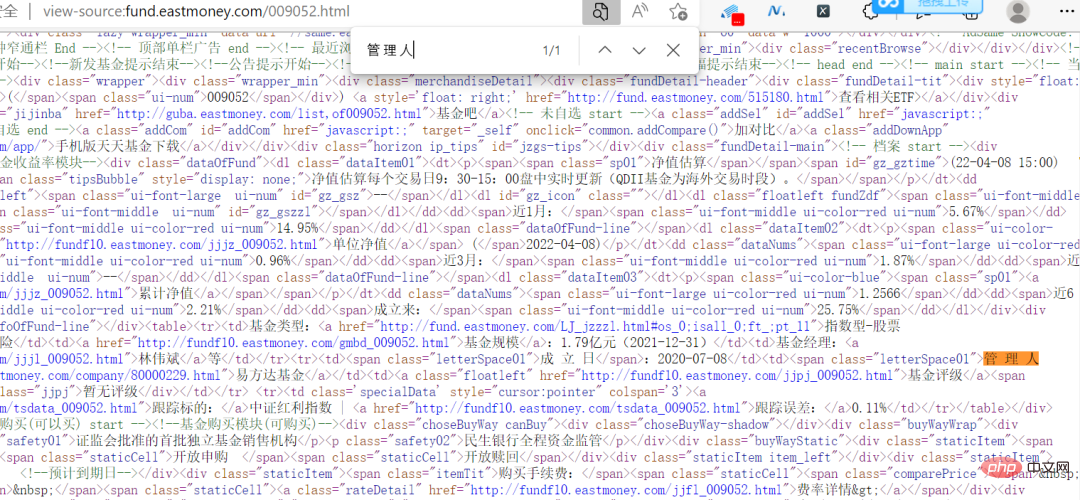
Cela réduit la difficulté de ramper. Grâce à la méthode de capture de paquets du navigateur, vous pouvez voir les paramètres de requête spécifiques, et vous pouvez voir que seul pi change dans les paramètres de requête, et cette valeur correspond à la page, vous pouvez donc directement construire les paramètres de requête. 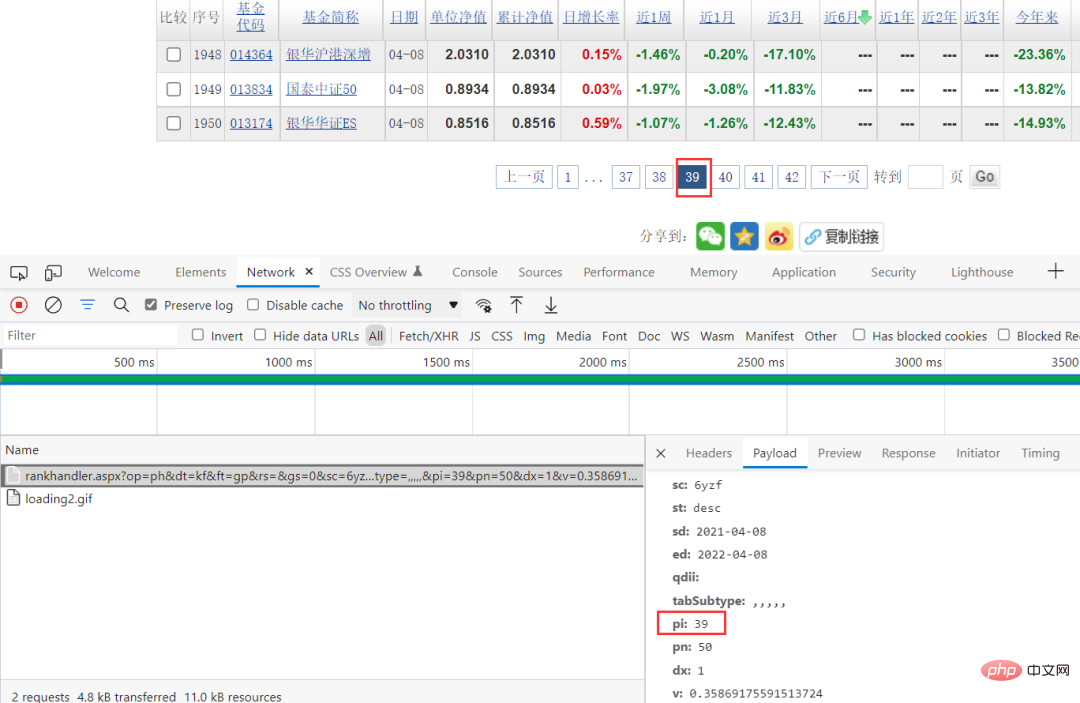
Après avoir trouvé la source de données, l'étape suivante consiste à implémenter le code. Voici quelques codes clés.
response = requests.get(url, headers=headers, params=params, verify=False)
pattern = re.compile(r'.*?"(?P<items>.*?)".*?', re.S)
result = re.finditer(pattern, response.text)
ids = []
for item in result:
# print(item.group('items'))
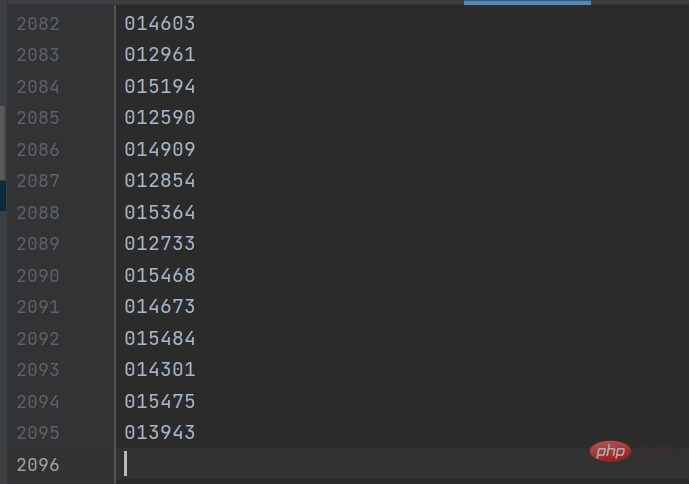
gp_id = item.group('items').split(',')[0]Le résultat est comme indiqué dans la figure ci-dessous :
Construisez ensuite le lien de la page de détails pour obtenir les informations sur le fonds sur la page de détails. Le code clé est le suivant. :
response = requests.get(url, headers=headers) response.encoding = response.apparent_encoding selectors = etree.HTML(response.text) danweijingzhi1 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[1]/text()')[0] danweijingzhi2 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[2]/text()')[0] leijijingzhi = selectors.xpath('//dl[@class="dataItem03"]/dd[1]/span/text()')[0] lst = selectors.xpath('//div[@class="infoOfFund"]/table//text()')
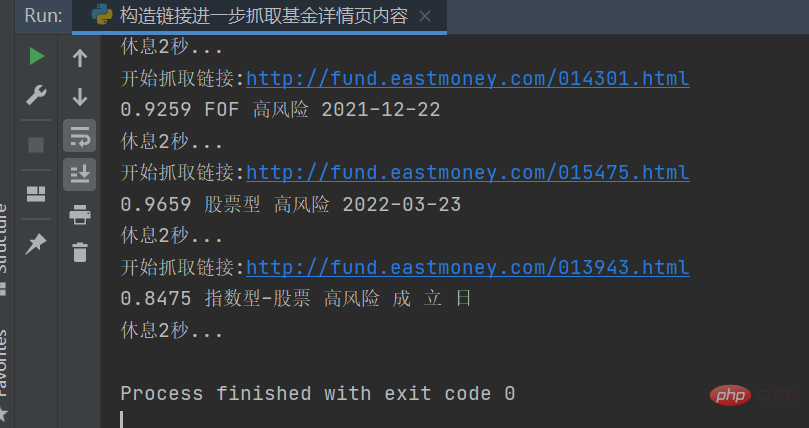
Le résultat est comme indiqué dans la figure ci-dessous :
 Traitez les informations spécifiques dans les chaînes correspondantes, puis enregistrez-les dans le
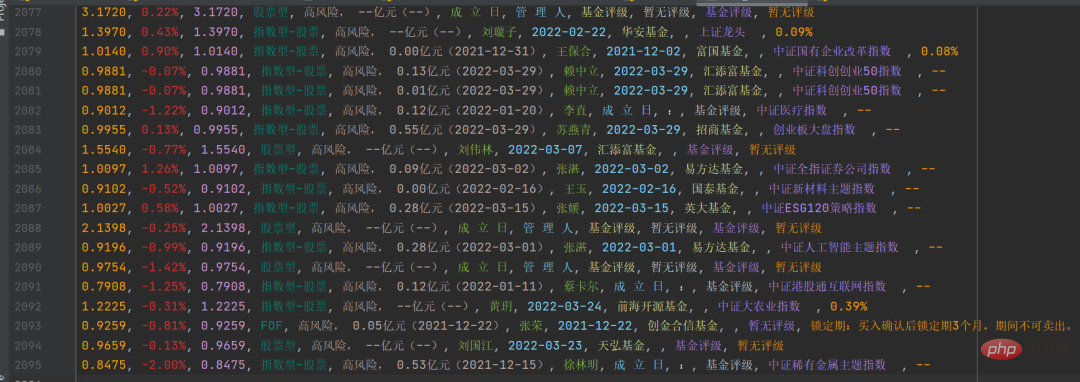
Traitez les informations spécifiques dans les chaînes correspondantes, puis enregistrez-les dans le csv fichier Le résultat est comme indiqué ci-dessous :
 Avec cela, vous pouvez le faire. d'autres statistiques et analyses de données.
Avec cela, vous pouvez le faire. d'autres statistiques et analyses de données.
Bonjour à tous, je suis une personne avancée en Python. Cet article partage principalement l'utilisation du robot d'exploration Web Python pour obtenir des informations sur les données des fonds. Ce projet n'est pas trop difficile, mais il y a quelques pièges. Tout le monde est invité à l'essayer. Si vous rencontrez des problèmes, veuillez m'ajouter en tant qu'ami. Je vais aider à le résoudre.
Cet article capture principalement la classification [Type de stock]. Je ne l'ai pas fait pour d'autres types. Vous pouvez l'essayer. En fait, la logique est la même, il suffit de modifier les paramètres. 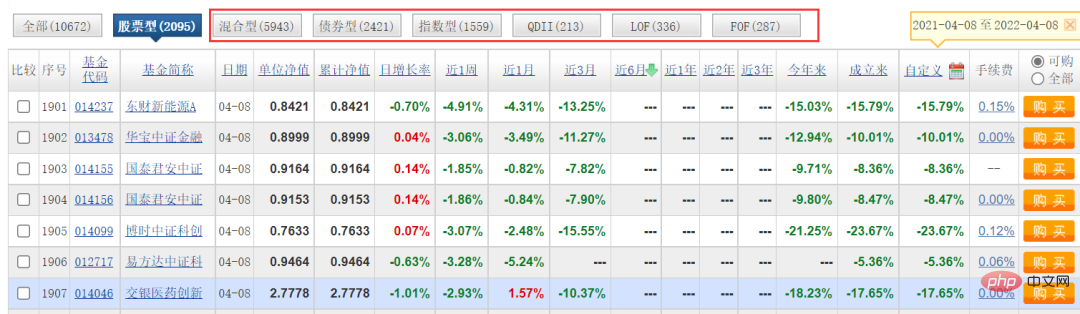
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



