
 développement back-end
Tutoriel Python
Apprenez étape par étape à utiliser le robot d'exploration Web Python pour obtenir les instructions sur l'équipement du héros King of Glory et générer automatiquement des fichiers de démarques.
développement back-end
Tutoriel Python
Apprenez étape par étape à utiliser le robot d'exploration Web Python pour obtenir les instructions sur l'équipement du héros King of Glory et générer automatiquement des fichiers de démarques.
Apprenez étape par étape à utiliser le robot d'exploration Web Python pour obtenir les instructions sur l'équipement du héros King of Glory et générer automatiquement des fichiers de démarques.
1. Introduction
Les amis qui ont joué au jeu Honor of Kings savent tous qu'un équipement de héros est très important, associé à des inscriptions, peut vous rendre imparable et. imparable sur le champ de bataille des rois !
Il y a quelques jours, j'ai vu dans le groupe [Minglao] qu'il partageait un robot d'exploration Python pour obtenir les instructions d'équipement du héros Honor of Kings, et utilisait le pool de threads pour télécharger les images d'équipement, puis générait automatiquement une démarque fichiers. Il y a beaucoup de contenu utile, et je vais le partager avec vous ici. Tout le monde est invité à l'essayer.
2. Acquisition de données
Notre site Web cible ici est le site officiel de King of Glory, comme le montre l'image ci-dessous. 
Cliquez ensuite sur le bouton [Plus] de [Héros/Skins] sur le côté droit de la page d'accueil pour accéder à la page de détails, comme indiqué dans l'image ci-dessous. Cliquez sur [Objets du jeu] pour voir les informations sur l'équipement, qui. comprend l'obtention des informations cibles que nous souhaitons. 
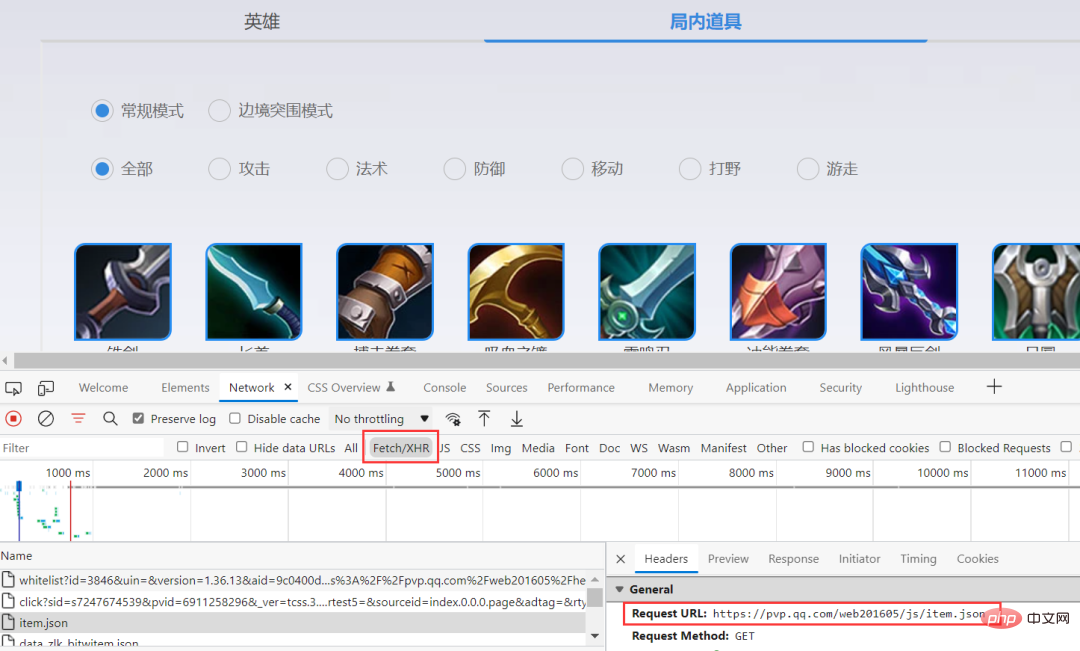
En capturant des paquets via le navigateur, vous pouvez obtenir des informations spécifiques et les voir stockées au format json.
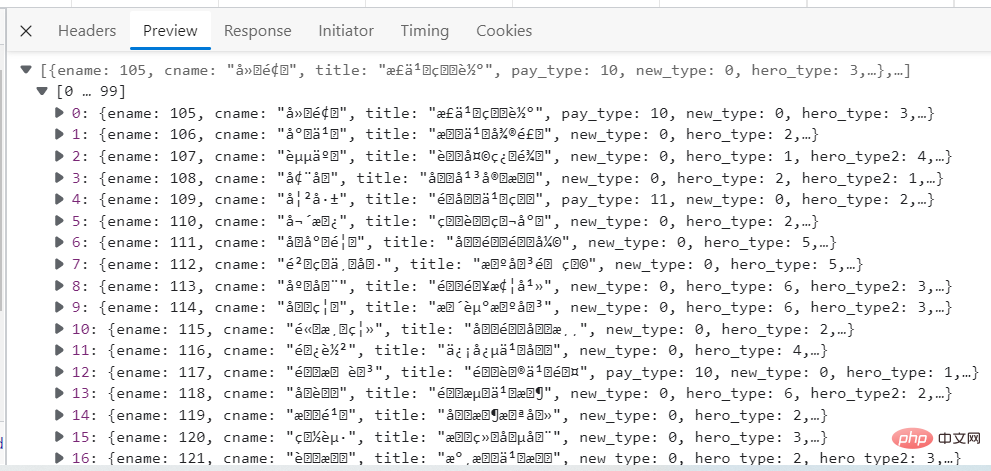
 L'image ci-dessous est une capture d'écran des détails des données. Vous pouvez voir qu'il y a des caractères chinois tronqués. Cela ne l'affecte pas. Au moins, les données peuvent être obtenues.
L'image ci-dessous est une capture d'écran des détails des données. Vous pouvez voir qu'il y a des caractères chinois tronqués. Cela ne l'affecte pas. Au moins, les données peuvent être obtenues.
Processus d'implémentation du code
Après avoir trouvé la source de données, l'étape suivante consiste à implémenter le code. Jetons un coup d'œil. Le code [Minglao] est directement appliqué ici et est exécuté dans jupyter notebook.
Obtenir les données de l'équipement
import requests
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/88.0.4324.104 Safari/537.36 '
}
target = 'https://pvp.qq.com/web201605/js/item.json'
item_list = requests.get(target, headers=headers).json()
item_df = pd.DataFrame(item_list)
item_df.sort_values(["item_type", "price", "item_id"], inplace=True)
item_df.fillna("", inplace=True)
item_df.des1 = item_df.des1.str.replace("</?p>", "", regex=True)
item_df.des2 = item_df.des2.str.replace("</?p>", "", regex=True)
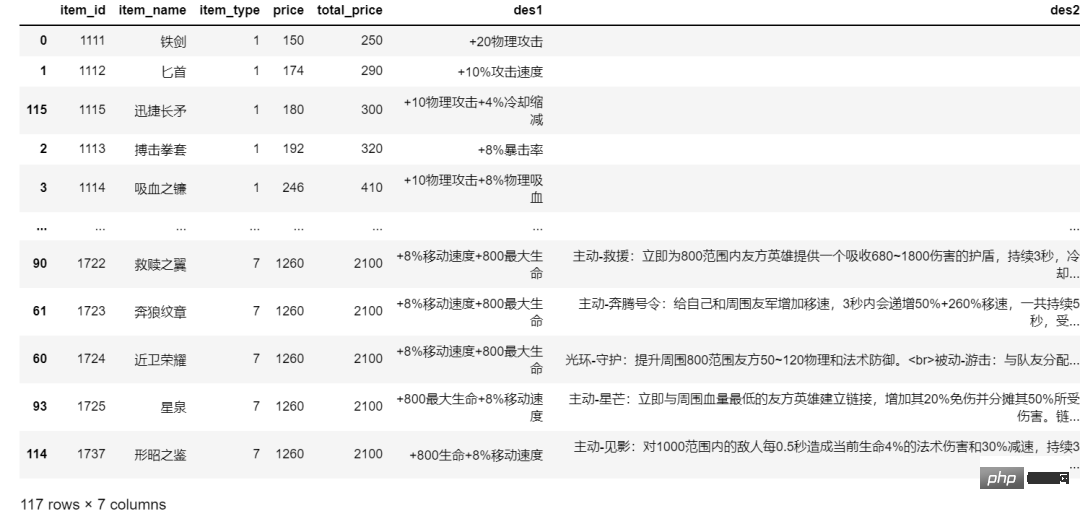
item_dfLe résultat est comme indiqué dans la figure ci-dessous :
Téléchargement d'images multithread
Ensuite, utilisez la méthode du pool de threads pour télécharger des images. La méthode d'épissage des images est également très simple, cela sera clair en un coup d'œil en regardant l'image ci-dessous.
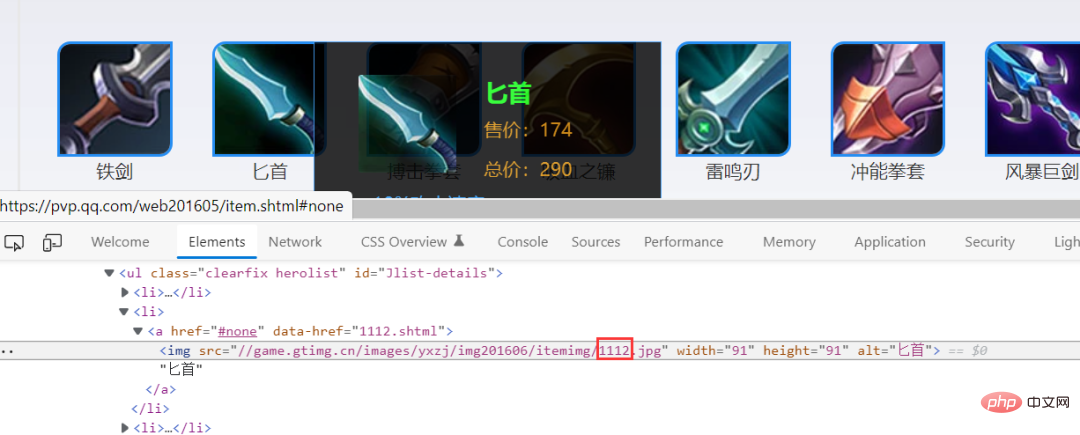 Voici l'implémentation du code :
Voici l'implémentation du code :
import os
from concurrent.futures import ThreadPoolExecutor
def download_img(item_id):
if os.path.exists(f"imgs/{item_id}.jpg"):
return
imgurl = f"http://game.gtimg.cn/images/yxzj/img201606/itemimg/{item_id}.jpg"
res = requests.get(imgurl)
with open(f"imgs/{item_id}.jpg", "wb") as f:
f.write(res.content)
os.makedirs("imgs", exist_ok=True)
with ThreadPoolExecutor(max_workers=8) as executor:
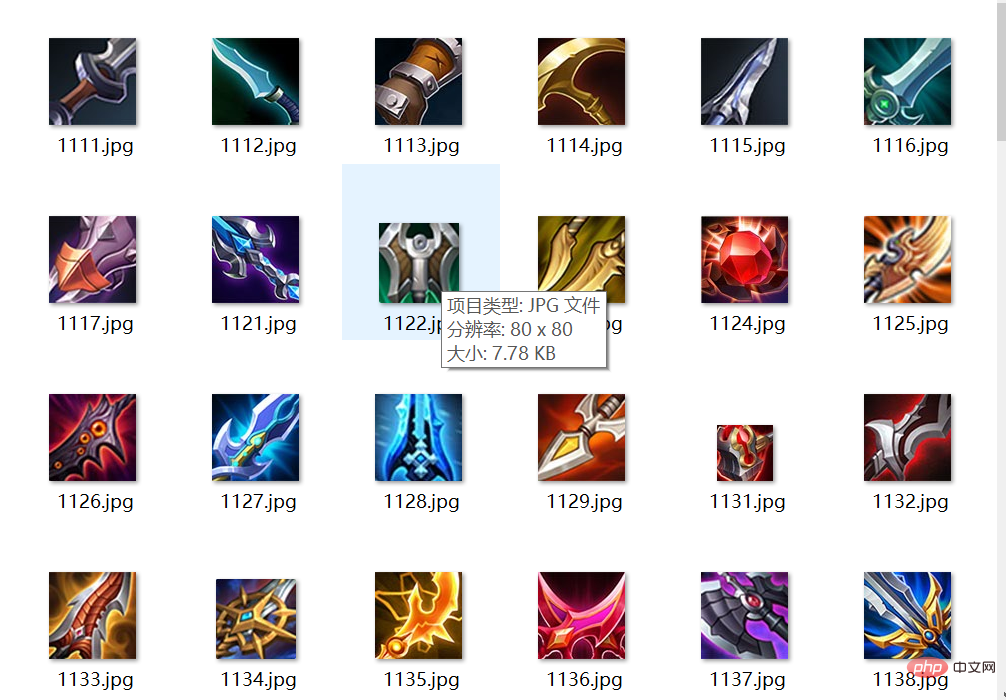
nums = executor.map(download_img, item_df.item_id)La vitesse de téléchargement est très rapide, quelques secondes seulement, et le résultat est comme le montre la figure ci-dessous :
Ensuite, nous générerons automatiquement le document Markdown à partir des données, jetons un coup d'œil.
Générer le document Markdown
Le code est le suivant La première partie est le prétraitement des données, suivi de l'écriture du fichier :
item_type_dict = {1: '攻击', 2: '法术', 3: '防御', 4: '移动', 5: '打野', 7: '游走'}
item_ids = item_df.item_id.values
item_df.item_id = item_df.item_id.apply(
lambda item_id: f"")
item_df.item_type = item_df.item_type.map(item_type_dict)
item_df.columns = ["图片", "装备名称", "类型", "售价", "总价", "基础描述", "扩展描述"]
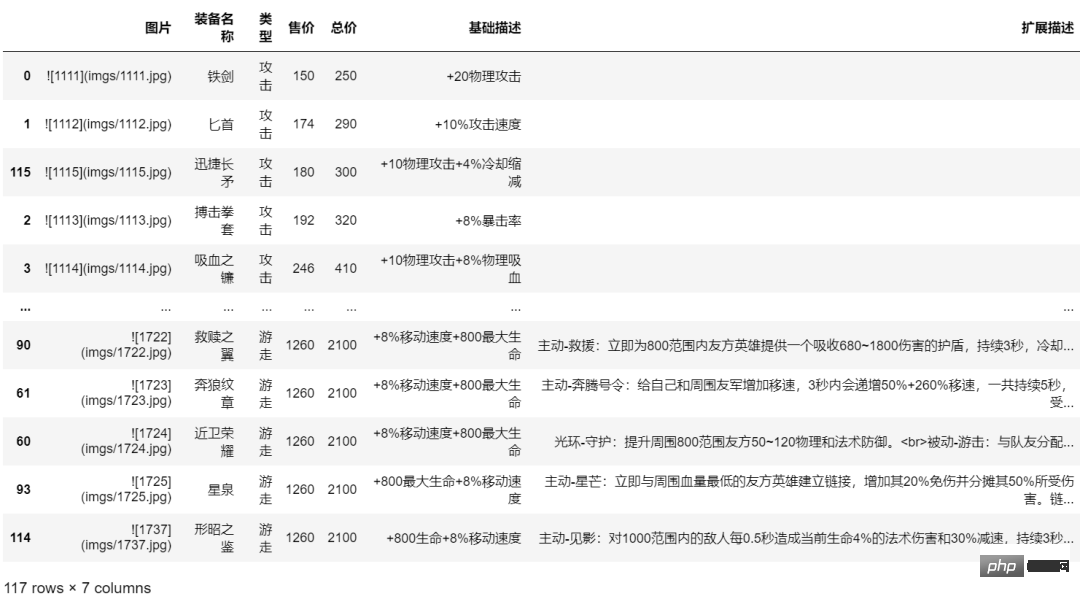
item_dfLe code pour écrire le fichier et générer le document Markdown :
with open("王者装备说明.md", "w") as f:
for item_type, item_split in item_df.groupby("类型", sort=False):
f.write(f"# {item_type}\n")
item_split.drop(columns="类型", inplace=True)
f.write(item_split.to_markdown(index=False))
f.write("\n\n"). Le résultat est le suivant :
Ensuite, un document Markdown nommé [King Equipment Description.md] sera généré localement. Double-cliquez sur le fichier pour l'ouvrir. Le contenu est tel qu'indiqué ci-dessous :
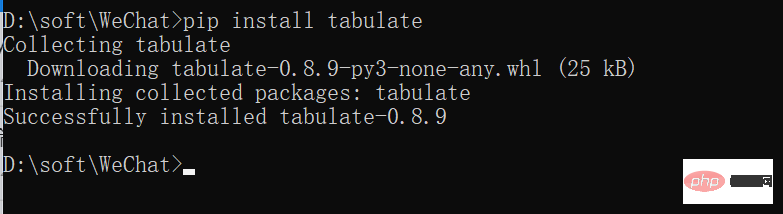
 Quoi. un gars génial ! Lorsque j'ai implémenté cette étape, j'ai rencontré une erreur, comme indiqué ci-dessous :
Quoi. un gars génial ! Lorsque j'ai implémenté cette étape, j'ai rencontré une erreur, comme indiqué ci-dessous :
Missing optional dependency 'tabulate'. Use pip or conda to install tabulate.
提示却少依赖库,只需要在cmd下进行安装即可pip install tabulate,之后就可以正常运行了。
生成Excel表格
不过Markdown的表格无法任意调整,图片需要点击后才会放大,下面我们考虑生成Excel表格:首先需要整理数据,代码如下:
item_df.图片 = ""
item_df.基础描述 = item_df.基础描述.str.replace("<br>", "\n")
item_df.扩展描述 = item_df.扩展描述.str.replace("<br>", "\n")
item_df生成结果如下图所示:
 之后将结果写入到
之后将结果写入到Excel中去,代码如下所示:
# 写入Excel表格
from openpyxl.drawing.image import Image
from openpyxl.styles import Alignment
with pd.ExcelWriter("王者装备说明.xlsx", engine='openpyxl') as writer:
item_df.to_excel(writer, sheet_name='装备说明', index=False)
worksheet = writer.sheets['装备说明']
worksheet.column_dimensions["A"].width = 11
for item_id, (cell,) in zip(item_ids, worksheet.iter_rows(2, None, 1, 1)):
worksheet.row_dimensions[cell.row].height = 67
worksheet.add_image(Image(f"imgs/{item_id}.jpg"), f'A{cell.row}')
worksheet.column_dimensions["F"].width = 15
worksheet.column_dimensions["G"].width = 35
writer.save()打开文件,效果图如下图所示:

当然了,大家也可以根据自己想要的效果生成HTML和Word等等。
三、总结
大家好,我是Python进阶者。这篇文章主要分享了一个使用Python网络爬虫获取王者荣耀英雄出装说明,并使用线程池的方式下载了出装图片,之后还自动化生成了markdown文件,干货内容很多,欢迎大家积极尝试,如果有遇到问题,请添加我好友,我帮助解决。
最后感谢粉丝【明佬】分享的代码喝王者荣耀出装攻略,真是太强了,上王者指日可待!
最后放上【明佬】的csdn链接:https://xxmdmst.blog.csdn.net/article/details/124035041,点击阅读原文可以直达噢!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Miniopen Centos Compatibilité
Apr 14, 2025 pm 05:45 PM
Miniopen Centos Compatibilité
Apr 14, 2025 pm 05:45 PM
Minio Object Storage: Déploiement haute performance dans le système Centos System Minio est un système de stockage d'objets distribué haute performance développé sur la base du langage Go, compatible avec Amazons3. Il prend en charge une variété de langages clients, notamment Java, Python, JavaScript et GO. Cet article introduira brièvement l'installation et la compatibilité de Minio sur les systèmes CentOS. Compatibilité de la version CentOS Minio a été vérifiée sur plusieurs versions CentOS, y compris, mais sans s'y limiter: CentOS7.9: fournit un guide d'installation complet couvrant la configuration du cluster, la préparation de l'environnement, les paramètres de fichiers de configuration, le partitionnement du disque et la mini
 Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
La formation distribuée par Pytorch sur le système CentOS nécessite les étapes suivantes: Installation de Pytorch: La prémisse est que Python et PIP sont installés dans le système CentOS. Selon votre version CUDA, obtenez la commande d'installation appropriée sur le site officiel de Pytorch. Pour la formation du processeur uniquement, vous pouvez utiliser la commande suivante: pipinstalltorchtorchVisionTorChaudio Si vous avez besoin d'une prise en charge du GPU, assurez-vous que la version correspondante de CUDA et CUDNN est installée et utilise la version Pytorch correspondante pour l'installation. Configuration de l'environnement distribué: la formation distribuée nécessite généralement plusieurs machines ou des GPU multiples uniques. Lieu
 Comment choisir la version Pytorch sur Centos
Apr 14, 2025 pm 06:51 PM
Comment choisir la version Pytorch sur Centos
Apr 14, 2025 pm 06:51 PM
Lors de l'installation de Pytorch sur le système CentOS, vous devez sélectionner soigneusement la version appropriée et considérer les facteurs clés suivants: 1. Compatibilité de l'environnement du système: Système d'exploitation: Il est recommandé d'utiliser CentOS7 ou plus. CUDA et CUDNN: La version Pytorch et la version CUDA sont étroitement liées. Par exemple, Pytorch1.9.0 nécessite CUDA11.1, tandis que Pytorch2.0.1 nécessite CUDA11.3. La version CUDNN doit également correspondre à la version CUDA. Avant de sélectionner la version Pytorch, assurez-vous de confirmer que des versions compatibles CUDA et CUDNN ont été installées. Version Python: branche officielle de Pytorch
 Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
CENTOS L'installation de Nginx nécessite de suivre les étapes suivantes: Installation de dépendances telles que les outils de développement, le devet PCRE et l'OpenSSL. Téléchargez le package de code source Nginx, dézippez-le et compilez-le et installez-le, et spécifiez le chemin d'installation AS / USR / LOCAL / NGINX. Créez des utilisateurs et des groupes d'utilisateurs de Nginx et définissez les autorisations. Modifiez le fichier de configuration nginx.conf et configurez le port d'écoute et le nom de domaine / adresse IP. Démarrez le service Nginx. Les erreurs communes doivent être prêtées à prêter attention, telles que les problèmes de dépendance, les conflits de port et les erreurs de fichiers de configuration. L'optimisation des performances doit être ajustée en fonction de la situation spécifique, comme l'activation du cache et l'ajustement du nombre de processus de travail.
