
 développement back-end
Tutoriel Python
Cet article vous aidera à comprendre la lecture et l'écriture de fichiers Python
développement back-end
Tutoriel Python
Cet article vous aidera à comprendre la lecture et l'écriture de fichiers Python
Cet article vous aidera à comprendre la lecture et l'écriture de fichiers Python
1. Qu'est-ce qu'un fichier ?
Le fichier sert à stocker une certaine quantité de stockage, afin qu'il puisse être utilisé directement la prochaine fois que le programme est exécuté sans avoir à faire une nouvelle copie, ce qui permet d'économiser du temps et des efforts.
2. Comment ouvrir le dossier ?
Python a une méthode open() intégrée qui peut lire et écrire des fichiers.
Utiliser la méthode open() pour exploiter un fichier, c'est comme mettre un éléphant dans le réfrigérateur. Elle peut être divisée en trois étapes, l'une consiste à ouvrir le fichier, l'autre à exploiter le fichier et la troisième. pour fermer le fichier.
syntaxe ouverte
La valeur de retour de la méthode open() est un objet fichier, qui peut être affecté à une variable (descripteur de fichier).
Le format de syntaxe de base est :
f = open(filename, mode)
Remarque :
En Python, tous les objets dotés de méthodes de lecture et d'écriture peuvent être classés en tant que types de fichiers. Tous les objets de type fichier peuvent être ouverts à l’aide de la méthode open et terminés par la méthode close.
filename : Une valeur de chaîne contenant le nom du fichier auquel vous souhaitez accéder, généralement un chemin de fichier.
mode : Il existe de nombreux modes d'ouverture de fichiers, le mode par défaut est le mode lecture seule r.
Exemple :
# 打开一个文件
f = open("1.txt", "w")
f.write("Python 是一种非常好的语言。\nPython!!\n")
# 关闭打开的文件
f.close()Résultat d'exécution :
Écriture dans un fichier 1.txt Python est un très bon langage. Python.

3. Mode d'accès
Utilisez un tableau pour comprendre les modes de lecture et d'écriture couramment utilisés de Python
| Mode d'accès | Description |
|---|---|
| r | fichier en mode lecture seule. Le pointeur de fichier sera placé au début du fichier. (mode par défaut). |
| w | Ouvrez un fichier en écriture uniquement. Si le fichier existe déjà, il est écrasé. Si le fichier n'existe pas, créez un nouveau fichier. |
| a | Ouvrez un fichier à ajouter. Si le fichier existe déjà, le pointeur de fichier sera placé à la fin du fichier. En d’autres termes, le nouveau contenu sera écrit après le contenu existant. Si le fichier n'existe pas, créez un nouveau fichier en écriture. |
| rb | Ouvrez un fichier au format binaire en lecture seule. Le pointeur de fichier sera placé au début du fichier. C'est le mode par défaut. |
| wb | Ouvrez un fichier au format binaire en écriture uniquement. Si le fichier existe déjà, il est écrasé. Si le fichier n'existe pas, créez un nouveau fichier. |
| ab | Ouvrez un fichier au format binaire pour l'ajouter. Si le fichier existe déjà, le pointeur de fichier sera placé à la fin du fichier. En d’autres termes, le nouveau contenu sera écrit après le contenu existant. Si le fichier n'existe pas, créez un nouveau fichier en écriture. |
| r+ | Ouvrez un fichier en lecture et en écriture. Le pointeur de fichier sera placé au début du fichier. |
| w+ | Ouvrez un fichier en lecture et en écriture. Si le fichier existe déjà, il est écrasé.Si le fichier n'existe pas, créez un nouveau fichier. |
| a+ | Ouvre un fichier en lecture et en écriture. Si le fichier existe déjà, le pointeur de fichier sera placé à la fin du fichier. Le fichier sera ouvert en mode ajout. Si le fichier n'existe pas, un nouveau fichier est créé pour la lecture et l'écriture. |
| rb+ | Ouvre un fichier au format binaire en lecture et en écriture. Le pointeur de fichier sera placé au début du fichier. |
| wb+ | Ouvrez un fichier au format binaire en lecture et en écriture. Si le fichier existe déjà, il est écrasé. Si le fichier n'existe pas, créez un nouveau fichier. |
| ab+ | Ouvrez un fichier au format binaire pour l'ajouter. Si le fichier existe déjà, le pointeur de fichier sera placé à la fin du fichier. Si le fichier n'existe pas, un nouveau fichier est créé pour la lecture et l'écriture. |
如果要读取非UTF-8编码的文件,需要给open()函数传入encoding参数。
例如,读取GBK编码的文件:
>>> f = open('gbk.txt', 'r', encoding='gbk') >>> f.read() 'GBK' #编码
遇到有些编码不规范的文件,可能会抛出UnicodeDecodeError异常,这表示在文件中可能夹杂了一些非法编码的字符。遇到这种情况,可以提供errors参数,表示如果遇到编码错误后如何处理。
f = open('gbk.txt', 'r', encoding='gbk', errors='ignore')
四、 文件对象操作
用open方法打开一个文件,将返回一个文件对象。这个对象内置了很多操作方法。
下面打开了一个f文件对象(1.txt)。对文件对象进行相关的操作。
1. f.read(size)
读取一定大小的数据, 然后作为字符串或字节对象返回。size是一个可选的数字类型的参数,用于指定读取的数据量。当size被忽略了或者为负值,那么该文件的所有内容都将被读取并且返回。
f = open("1.txt", "r")
str = f.read()
print(str)
f.close()如果文件体积较大,请不要使用read()方法一次性读入内存,而是read(312)这种一点一点的读。
2. f.readline()
从文件中读取一行n内容。换行符为'\n'。如果返回一个空字符串,说明已经已经读取到最后一行。这种方法,通常是读一行,处理一行的情况下使用。
f = open("1.txt", "r")
str = f.readline()
print(str)
f.close()3. f.readlines()
将文件中所有的行,一行一行全部读入一个列表内,按顺序一个一个作为列表的元素,并返回这个列表。readlines方法会一次性将文件全部读入内存,所以也存在一定的弊端。但是它有个好处,每行都保存在列表里,可随意存取。
f = open("1.txt", "r")
a = f.readlines()
print(a)
f.close()4. 遍历文件
实际情况中,我们会将文件对象作为一个迭代器来使用。
# 打开一个文件
f = open("1.txt", "r")
for line in f:
print(line, end='')
# 关闭打开的文件
f.close()这个方法很简单, 不需要将文件一次性读出,但是同样没有提供一个很好的控制,与readline方法一样只能前进,不能回退。
几种不同的读取和遍历文件的方法比较:
如果文件很小,read()一次性读取最方便;
如果不能确定文件大小,反复调用read(size)比较保险;
如果是配置文件,调用readlines()最方便。普通情况,使用for循环更好,速度更快。
5. f.write()
使用write()可以完成向文件写入数据。
# 打开一个文件
f = open("/tmp/foo.txt", "w")
f.write("Python 是一种非常好的语言。\n我喜欢Python!!\n")
# 关闭打开的文件
f.close()6. f.tell()
返回文件读写指针当前所处的位置,它是从文件开头开始算起的字节数。一定要注意了,是字节数,不是字符数。
7. f.seek()
如果要改变位置指针的位置, 可以使用f.seek(offset, from_what)方法。seek()经常和tell()方法配合使用。
from_what的值,如果是0表示从文件开头计算,如果是1表示从文件读写指针的当前位置开始计算,2表示从文件的结尾开始计算,默认为0,例如:
offset:表示偏移量。
seek(x,0) :从起始位置即文件首行首字符开始移动 x 个字符。
seek(x,1) :表示从当前位置往后移动x个字符。
seek(-x,2):表示从文件的结尾往前移动x个字符。
例:
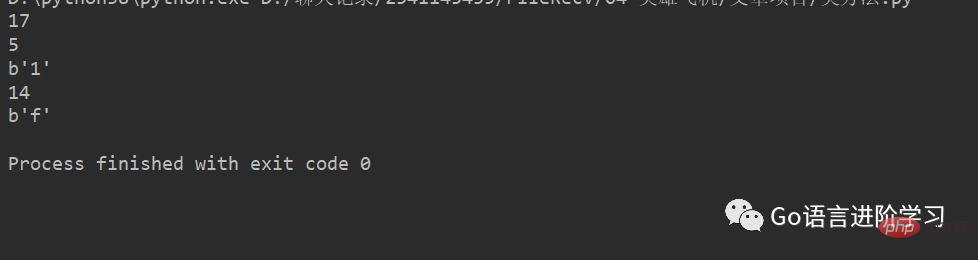
f = open("1.txt", "rb+")
f.write(b"1232312adsfalafds")
print(f.tell())
print(f.seek(5))
print(f.read(1))
print(f.seek(-3, 2))print(f.read(1))
运行结果:
8. f.close()
关闭文件对象。当处理完一个文件后,调用f.close()来关闭文件并释放系统的资源。文件关闭后,如果尝试再次调用该文件对象,则会抛出异常。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了,或者更糟糕的结果。
五、 with关键字
with关键字用于Python的上下文管理器机制。为了防止open这一类文件打开方法,在操作过程出现异常或错误,或者最后忘了执行close方法,文件非正常关闭等可能导致文件泄露、破坏的问题。
Python提供了with这个上下文管理器机制,保证文件会被正常关闭。不需要再写close语句。注意缩进。
with open('test.txt', 'w') as f: f.write('Hello, world!')
with支持同时打开多个文件(文件都是随机创建的):
with open('1') as obj1, open('2','w') as obj2: s=obj1.read() obj2.write(s)
六、总结
本文基于Python基础,使用Python语言。介绍了有关Python文件操作的知识点,从文件的基本概念入手 ,通过一个个小项目的演示,对常用的读写模式,文件对象操作方法,以及在实际应用中需要注意的问题,都做了详细的讲解。希望帮助你更好的学习Python。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Miniopen Centos Compatibilité
Apr 14, 2025 pm 05:45 PM
Miniopen Centos Compatibilité
Apr 14, 2025 pm 05:45 PM
Minio Object Storage: Déploiement haute performance dans le système Centos System Minio est un système de stockage d'objets distribué haute performance développé sur la base du langage Go, compatible avec Amazons3. Il prend en charge une variété de langages clients, notamment Java, Python, JavaScript et GO. Cet article introduira brièvement l'installation et la compatibilité de Minio sur les systèmes CentOS. Compatibilité de la version CentOS Minio a été vérifiée sur plusieurs versions CentOS, y compris, mais sans s'y limiter: CentOS7.9: fournit un guide d'installation complet couvrant la configuration du cluster, la préparation de l'environnement, les paramètres de fichiers de configuration, le partitionnement du disque et la mini
 Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
La formation distribuée par Pytorch sur le système CentOS nécessite les étapes suivantes: Installation de Pytorch: La prémisse est que Python et PIP sont installés dans le système CentOS. Selon votre version CUDA, obtenez la commande d'installation appropriée sur le site officiel de Pytorch. Pour la formation du processeur uniquement, vous pouvez utiliser la commande suivante: pipinstalltorchtorchVisionTorChaudio Si vous avez besoin d'une prise en charge du GPU, assurez-vous que la version correspondante de CUDA et CUDNN est installée et utilise la version Pytorch correspondante pour l'installation. Configuration de l'environnement distribué: la formation distribuée nécessite généralement plusieurs machines ou des GPU multiples uniques. Lieu
 Comment choisir la version Pytorch sur Centos
Apr 14, 2025 pm 06:51 PM
Comment choisir la version Pytorch sur Centos
Apr 14, 2025 pm 06:51 PM
Lors de l'installation de Pytorch sur le système CentOS, vous devez sélectionner soigneusement la version appropriée et considérer les facteurs clés suivants: 1. Compatibilité de l'environnement du système: Système d'exploitation: Il est recommandé d'utiliser CentOS7 ou plus. CUDA et CUDNN: La version Pytorch et la version CUDA sont étroitement liées. Par exemple, Pytorch1.9.0 nécessite CUDA11.1, tandis que Pytorch2.0.1 nécessite CUDA11.3. La version CUDNN doit également correspondre à la version CUDA. Avant de sélectionner la version Pytorch, assurez-vous de confirmer que des versions compatibles CUDA et CUDNN ont été installées. Version Python: branche officielle de Pytorch
 Python: automatisation, script et gestion des tâches
Apr 16, 2025 am 12:14 AM
Python: automatisation, script et gestion des tâches
Apr 16, 2025 am 12:14 AM
Python excelle dans l'automatisation, les scripts et la gestion des tâches. 1) Automatisation: La sauvegarde du fichier est réalisée via des bibliothèques standard telles que le système d'exploitation et la fermeture. 2) Écriture de script: utilisez la bibliothèque PSUTIL pour surveiller les ressources système. 3) Gestion des tâches: utilisez la bibliothèque de planification pour planifier les tâches. La facilité d'utilisation de Python et la prise en charge de la bibliothèque riche en font l'outil préféré dans ces domaines.
