
 développement back-end
Tutoriel Python
Faire le point sur les différences entre la bibliothèque urllib et la bibliothèque de requêtes en Python
développement back-end
Tutoriel Python
Faire le point sur les différences entre la bibliothèque urllib et la bibliothèque de requêtes en Python
Faire le point sur les différences entre la bibliothèque urllib et la bibliothèque de requêtes en Python
1. Introduction
Lorsque vous utilisez un robot d'exploration Python, vous devez simuler le lancement de requêtes réseau. Les principales bibliothèques utilisées sont la bibliothèque de requêtes et la bibliothèque urllib intégrée à Python. use request, qui est une extension de urllib encapsulée à nouveau.
Quelle est la différence entre eux ?
Ce qui suit est une explication détaillée à travers des cas pour comprendre les principales différences dans leur utilisation.
2. Bibliothèque urllib
Introduction : L'objet de réponse de la bibliothèque urllib crée d'abord des objets http et de requête, puis les charge dans reques.urlopen pour terminer la requête http.
Ce qui est renvoyé est http, un objet de réponse, qui est en fait un attribut HTML. Utilisez .read().decode() pour le décoder et le convertir en type chaîne str. Après le décodage, les caractères chinois peuvent être affichés.
Exemple :
from urllib import request
#请求头
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'
}
wd = {"wd": "中国"}
url = "http://www.baidu.com/s?"
req = request.Request(url, headers=headers)
response = request.urlopen(req)
print(type(response))
print(response)
res = response.read().decode()
print(type(res))
print(res)Résultat de course :
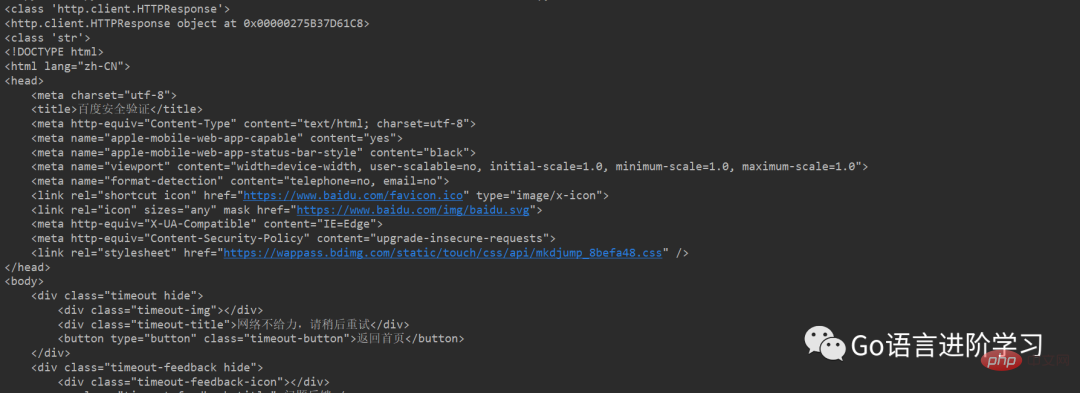
Remarque :
Habituellement, en explorant les pages Web, lors de la construction de requêtes http, vous devez en ajouter des informations supplémentaires, telles que Useragent, cookies, etc., ou ajouter un serveur proxy. Il s’agit souvent de mécanismes anti-exploration nécessaires.
三、requests库
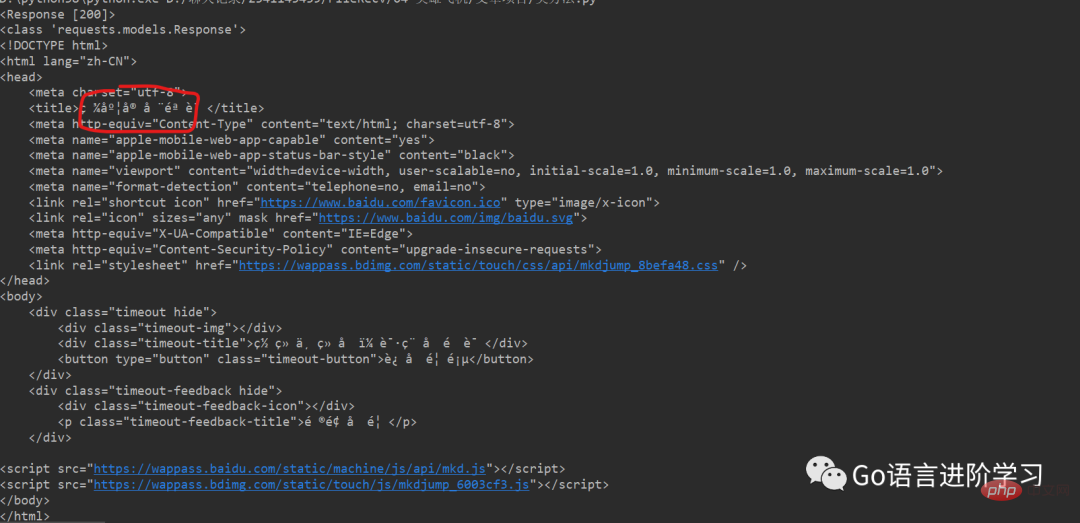
简介:requests库调用是requests.get方法传入url和参数,返回的对象是Response对象,打印出来是显示响应状态码。
通过.text 方法可以返回是unicode 型的数据,一般是在网页的header中定义的编码形式,而content返回的是bytes,二级制型的数据,还有 .json方法也可以返回json字符串。
如果想要提取文本就用text,但是如果你想要提取图片、文件等二进制文件,就要用content,当然decode之后,中文字符也会正常显示。
requests的优势:Python爬虫时,更建议用requests库。因为requests比urllib更为便捷,requests可以直接构造get,post请求并发起,而urllib.request只能先构造get,post请求,再发起。
例:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Linux; U; Android 8.1.0; zh-cn; BLA-AL00 Build/HUAWEIBLA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/8.9 Mobile Safari/537.36"
}
wd = {"wd": "中国"}
url = "http://www.baidu.com/s?"
response = requests.get(url, params=wd, headers=headers)
data = response.text
data2 = response.content
print(response)
print(type(response))
print(data)
print(type(data))
print(data2)
print(type(data2))
print(data2.decode())
print(type(data2.decode()))运行结果 (可以直接获取整网页的信息,打印控制台):
四、总结
1. 本文基于Python基础,主要介绍了urllib库和requests库的区别。
2. 在使用urllib内的request模块时,返回体获取有效信息和请求体的拼接需要decode和encode后再进行装载。进行http请求时需先构造get或者post请求再进行调用,header等头文件也需先进行构造。
3. requests是对urllib的进一步封装,因此在使用上显得更加的便捷,建议在实际应用当中尽量使用requests。
4. 希望能给一些对爬虫感兴趣,有一个具体的概念。方法只是一种工具,试着去爬一爬会更容易上手,网络也会有很多的坑,做爬虫更需要大量的经验来应付复杂的网络情况。
5. 希望大家一起探讨学习, 一起进步。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
PHP convient au développement Web et au prototypage rapide, et Python convient à la science des données et à l'apprentissage automatique. 1.Php est utilisé pour le développement Web dynamique, avec une syntaxe simple et adapté pour un développement rapide. 2. Python a une syntaxe concise, convient à plusieurs champs et a un écosystème de bibliothèque solide.
 PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP est principalement la programmation procédurale, mais prend également en charge la programmation orientée objet (POO); Python prend en charge une variété de paradigmes, y compris la POO, la programmation fonctionnelle et procédurale. PHP convient au développement Web, et Python convient à une variété d'applications telles que l'analyse des données et l'apprentissage automatique.
 Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code peut fonctionner sur Windows 8, mais l'expérience peut ne pas être excellente. Assurez-vous d'abord que le système a été mis à jour sur le dernier correctif, puis téléchargez le package d'installation VS Code qui correspond à l'architecture du système et l'installez comme invité. Après l'installation, sachez que certaines extensions peuvent être incompatibles avec Windows 8 et doivent rechercher des extensions alternatives ou utiliser de nouveaux systèmes Windows dans une machine virtuelle. Installez les extensions nécessaires pour vérifier si elles fonctionnent correctement. Bien que le code VS soit possible sur Windows 8, il est recommandé de passer à un système Windows plus récent pour une meilleure expérience de développement et une meilleure sécurité.
 L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
Les extensions de code vs posent des risques malveillants, tels que la cachette de code malveillant, l'exploitation des vulnérabilités et la masturbation comme des extensions légitimes. Les méthodes pour identifier les extensions malveillantes comprennent: la vérification des éditeurs, la lecture des commentaires, la vérification du code et l'installation avec prudence. Les mesures de sécurité comprennent également: la sensibilisation à la sécurité, les bonnes habitudes, les mises à jour régulières et les logiciels antivirus.
 Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Dans VS Code, vous pouvez exécuter le programme dans le terminal via les étapes suivantes: Préparez le code et ouvrez le terminal intégré pour vous assurer que le répertoire de code est cohérent avec le répertoire de travail du terminal. Sélectionnez la commande Run en fonction du langage de programmation (tel que Python de Python your_file_name.py) pour vérifier s'il s'exécute avec succès et résoudre les erreurs. Utilisez le débogueur pour améliorer l'efficacité du débogage.
 Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
VS Code peut être utilisé pour écrire Python et fournit de nombreuses fonctionnalités qui en font un outil idéal pour développer des applications Python. Il permet aux utilisateurs de: installer des extensions Python pour obtenir des fonctions telles que la réalisation du code, la mise en évidence de la syntaxe et le débogage. Utilisez le débogueur pour suivre le code étape par étape, trouver et corriger les erreurs. Intégrez Git pour le contrôle de version. Utilisez des outils de mise en forme de code pour maintenir la cohérence du code. Utilisez l'outil de liaison pour repérer les problèmes potentiels à l'avance.
 Peut-on utiliser pour mac
Apr 15, 2025 pm 07:36 PM
Peut-on utiliser pour mac
Apr 15, 2025 pm 07:36 PM
VS Code est disponible sur Mac. Il a des extensions puissantes, l'intégration GIT, le terminal et le débogueur, et offre également une multitude d'options de configuration. Cependant, pour des projets particulièrement importants ou un développement hautement professionnel, le code vs peut avoir des performances ou des limitations fonctionnelles.
 Peut-on rescode exécuter ipynb
Apr 15, 2025 pm 07:30 PM
Peut-on rescode exécuter ipynb
Apr 15, 2025 pm 07:30 PM
La clé de l'exécution du cahier Jupyter dans VS Code est de s'assurer que l'environnement Python est correctement configuré, de comprendre que l'ordre d'exécution du code est cohérent avec l'ordre cellulaire et d'être conscient des fichiers volumineux ou des bibliothèques externes qui peuvent affecter les performances. Les fonctions d'achèvement et de débogage du code fournies par VS Code peuvent considérablement améliorer l'efficacité du codage et réduire les erreurs.
