
 base de données
tutoriel mysql
Aujourd'hui, j'ai enfin compris la sous-base de données et les sous-tables MySQL, je peux donc m'en vanter dans l'interview !
base de données
tutoriel mysql
Aujourd'hui, j'ai enfin compris la sous-base de données et les sous-tables MySQL, je peux donc m'en vanter dans l'interview !
Aujourd'hui, j'ai enfin compris la sous-base de données et les sous-tables MySQL, je peux donc m'en vanter dans l'interview !
Avant-propos
La société a récemment travaillé sur la séparation des services et la segmentation des données, car la quantité de données dans une seule table de package est vraiment trop importante et elle augmente toujours de 60 W par jour.
J'ai déjà entendu parler de la sous-base de données et des sous-tableaux de la base de données et j'ai lu quelques articles de blog, mais je ne connais qu'un vague concept, et maintenant que j'y pense, tout est vague.
J'ai passé tout l'après-midi à lire les sous-tableaux de la base de données et à lire de nombreux articles. Je vais maintenant faire un résumé :
Partie 1 : Problèmes rencontrés dans le processus de développement du site Web.
Partie 2 : Quelles sont les différentes manières de segmentation, les différences et les aspects applicables entre vertical et horizontal.
Partie 3 : Quelques produits et technologies open source actuellement sur le marché, et quels sont leurs avantages et inconvénients.
Partie 4 : Peut-être la chose la plus importante, pourquoi n'est-il pas recommandé de diviser la base de données horizontalement ! ? Cela vous permet de le traiter avec soin dès les premières étapes de la planification et d'éviter les problèmes causés par la segmentation.
Explication des termes
Bibliothèque : base de données ; table : table ; sous-base de données et sous-table : sharding
Évolution de l'architecture de la base de données Au début, nous n'utilisions qu'une base de données mono-machine, puis nous avons été confrontés de plus en plus de demandes.Nous séparons les opérations d'écriture et de lecture de la base de données, utilisons plusieurs copies de la base de données esclave (Slaver Replication) pour être responsable de la lecture et utilisons la base de données maître (Master) pour être responsable de l'écriture des mises à jour de la base de données esclave. données de manière synchrone à partir de la base de données principale pour maintenir la cohérence des données. Sur le plan architectural, il s'agit d'une synchronisation maître-esclave de base de données. La bibliothèque esclave peut être mise à l'échelle horizontalement, donc davantage de demandes de lecture ne posent pas de problème.
Mais lorsque le nombre d'utilisateurs augmente et que les demandes d'écriture augmentent, que devons-nous faire ? L'ajout d'un maître ne peut pas résoudre le problème, car les données doivent être cohérentes et l'opération d'écriture nécessite une synchronisation entre les deux maîtres, ce qui équivaut à une duplication et est plus compliqué.
À ce stade, vous devez utiliser le partitionnement pour segmenter les opérations d'écriture.
Problèmes avant de partitionner des bases de données et des tables
Tout problème est trop grand ou trop petit. Le problème auquel nous sommes confrontés ici est que la quantité de données est trop importante.
Le volume des demandes des utilisateurs est trop important
Parce que les TPS, la mémoire et les IO d'un seul serveur sont limités.
Solution : Distribuez les requêtes sur plusieurs serveurs ; en fait, les requêtes des utilisateurs et l'exécution d'une requête SQL sont essentiellement les mêmes, toutes deux demandant une ressource, mais les requêtes des utilisateurs passeront également par des passerelles, du routage, des serveurs http, etc.
La base de données unique est trop volumineuse
La capacité de traitement d'une seule base de données est limitée
Espace disque insuffisant sur le serveur où se trouve la base de données unique
Le goulot d'étranglement des opérations sur une seule base de données ; Solution : diviser en bibliothèques plus petites
CRUD est un problème ; Extension d'index, délai d'expiration de la requêteSi une seule table est trop grande
Solution : diviser en plusieurs tables avec des ensembles de données plus petits.
La méthode de partitionnement des bases de données et des tables
est généralement une segmentation verticale et une segmentation horizontale. Il s'agit d'une méthode de segmentation décrite dans l'ensemble de résultats, qui est une segmentation de l'espace physique.
Nous partons des problèmes auxquels nous sommes confrontés et les résolvons.Explication :
Premièrement, le nombre de requêtes des utilisateurs est trop important, donc nous empilons les machines pour le gérer (ce n'est pas l'objet de cet article)Ensuite, la bibliothèque unique est trop grande à ce moment-là, nous en avons besoin. pour voir s'il y a trop de données à cause d'un trop grand nombre de tables, ou si c'est à cause d'une seule base de données. Il y a beaucoup de données dans la table.S'il y a beaucoup de tableaux et beaucoup de données, utilisez la segmentation verticale et divisez-la en différentes bibliothèques selon l'activité.
. Parce que la division verticale est plus simple et plus cohérente avec la façon dont nous traitons les problèmes du monde réel.
Si la quantité de données dans une seule table est trop importante, une segmentation horizontale doit être utilisée, c'est-à-dire que les données de la table sont divisées en plusieurs tables selon certaines règles, ou même en plusieurs tables sur plusieurs bases de données.
Partage vertical
Le partage vertical d'une table
consiste également à "diviser une grande table en une petite table", basée sur des champs de colonnes. Généralement, il y a de nombreux champs dans le tableau, et ceux qui ne sont pas couramment utilisés, contiennent des données volumineuses et sont longs (comme les champs de type texte) sont divisés en « tableaux étendus ». Il s'adresse généralement aux grandes tables comportant des centaines de colonnes, et évite également le problème de « page croisée » provoqué par trop de données lors de l'interrogation.
Sous-bibliothèque verticale
La sous-bibliothèque verticale vise à diviser différentes entreprises dans un système, comme une base de données pour les utilisateurs, une base de données pour les produits et une base de données pour les commandes. Après le fractionnement, il doit être placé sur plusieurs serveurs au lieu d'un seul serveur. Pourquoi? Imaginons qu'un site Web commercial fournisse des services au monde extérieur et dispose de CRUD pour les utilisateurs, les produits, les commandes, etc. Avant le fractionnement, tout tombait dans une seule bibliothèque, ce qui rendrait la base de données La capacité de traitement d'une seule base de données est devenue un goulot d'étranglement. Après avoir divisé verticalement la base de données, si elle est toujours placée sur un serveur de base de données, à mesure que le nombre d'utilisateurs augmente, la capacité de traitement d'une seule base de données deviendra un goulot d'étranglement et L'espace disque, la mémoire, le tps, etc. d'un seul serveur sont très restreints. Par conséquent, nous devons le diviser en plusieurs serveurs, afin que les problèmes ci-dessus soient résolus et que nous ne soyons pas confrontés à des problèmes de ressources sur une seule machine à l'avenir. 单库处理能力成为瓶颈。按垂直分库后,如果还是放在一个数据库服务器上, 随着用户量增大,这会让单个数据库的处理能力成为瓶颈,还有单个服务器的磁盘空间,内存,tps等非常吃紧。所以我们要拆分到多个服务器上,这样上面的问题都解决了,以后也不会面对单机资源问题。
数据库业务层面的拆分,和服务的治理,降级机制类似,也能对不同业务的数据分别的进行管理,维护,监控,扩展等。数据库往往最容易成为应用系统的瓶颈,而数据库本身属于有状态的,相对于Web和应用服务器来讲,是比较难实现横向扩展
Rétrogradation est similaire. Il peut également gérer, maintenir, surveiller, développer, etc. les données de différentes entreprises séparément. La base de données est souvent la plus susceptible de devenir le goulot d'étranglement du système d'application, et la base de données elle-même appartient à la couleur : rgba(27, 31, 35, 0.05) ;font-family : "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(239, 112, 96);" >Stateful est plus difficile à mettre en œuvre que les serveurs Web et d'applicationsExpansion horizontale. Les ressources de connexion aux bases de données sont précieuses et les capacités de traitement sur une seule machine sont limitées. Dans les scénarios à forte concurrence, les sous-bases de données verticales peuvent dans une certaine mesure surmonter les goulots d'étranglement des E/S, du nombre de connexions et des ressources matérielles d'une seule machine. 🎜Séparation horizontale
Sous-table horizontale
Pour une seule table avec une énorme quantité de données (comme une table de commande), selon certaines règles (RANGE,HASH取模等),切分到多张表里面去。但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈. Ce n'est pas recommandé.
Sous-table horizontale base de données et sous-table
Les données d'une seule table sont divisées en plusieurs serveurs. Chaque serveur a une base de données et une table correspondantes, mais la collecte de données dans la table est différente. Le partitionnement horizontal peut efficacement atténuer les goulots d'étranglement et la pression des performances. une seule machine et une seule base de données, et éliminer les goulots d'étranglement dans les E/S, le nombre de connexions, les ressources matérielles, etc. 20000 ;
Modèle d'extraction HASHUn système de centre commercial utilise généralement les utilisateurs et les commandes comme table principale, puis utilise leurs tables associées comme tables supplémentaires. Cela ne posera pas de problèmes tels que des transactions entre bases de données. L'ID utilisateur est pris, puis le hachage est pris et distribué vers différentes bases de données Régions géographiquesPar exemple, Qiniu Cloud devrait diviser l'entreprise en fonction du temps. il y a même un an et les placer dans un autre tableau. Au fil du temps, la probabilité que les données de ces tableaux soient interrogées diminue, il n'est donc pas nécessaire de les regrouper avec les "données chaudes", c'est aussi ". séparation des données chaudes et froides" .
Problèmes rencontrés après la sous-base de données et la table
Support des transactions
Après la sous-base de données et la table, cela devient Transaction distribuée. 分布式事务了。
如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
多库结果集合并(group by,order by)
类似于group by,order by
Fusion de plusieurs ensembles de résultats de bases de données (regrouper par, trier par)
🎜Similaire àLes instructions de groupe et de tri telles que group by, order by ne peuvent pas être utilisées🎜🎜Jointure entre bases de données🎜🎜Une fois la base de données divisée en tables, les opérations d'association entre les tables seront restreintes, et nous ne pouvons pas joindre les tables dans des emplacements différents. Les tables des sous-bases de données ne peuvent pas être jointes à des tables avec des granularités de sous-tables différentes. Par conséquent, l'activité qui peut être réalisée avec une seule requête peut nécessiter plusieurs requêtes. Solution approximative : table globale : données de base, toutes les bibliothèques en ont une copie. Redondance des champs : De cette manière, certains champs n'ont pas besoin d'être interrogés par jointure. Assemblage de la couche système : interrogez tout séparément, puis assemblez-le, ce qui est plus compliqué. 🎜Produits de solutions de sous-bases de données et de sous-tables
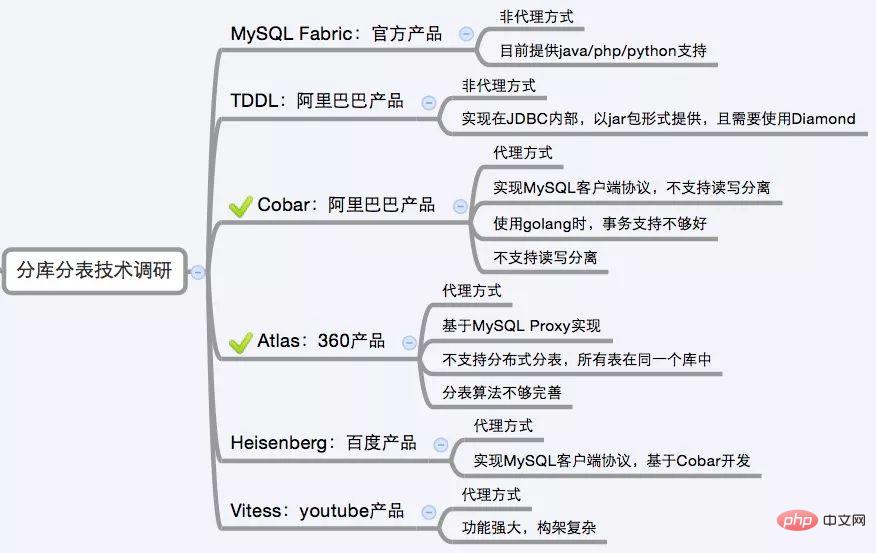
Il existe relativement de nombreux middlewares de sous-bases de données et de sous-tables sur le marché, parmi lesquels ceux basés sur un proxy incluent MySQL Proxy et Amoeba, basé sur le framework Hibernate est Hibernate Shards, basé sur jdbc Dangdangsharding-jdbc, un plug-in Maven basé sur mybatis similaire à Mogujie TSharding, en réécrivant le Client Cobar. MySQL Proxy和Amoeba, 基于Hibernate框架的是Hibernate Shards,基于jdbc的有当当sharding-jdbc, 基于mybatis的类似maven插件式的有蘑菇街的蘑菇街TSharding, 通过重写spring的ibatis template类的Cobar Client。
还有一些大公司的开源产品:
我是程序员青戈,一个爱生活、爱分享的90后程序员。
本期关于Mysql分库分表的介绍和解决方案介绍到这里,希望能帮助到大家,后续更多Java面试类的文章请持续关注公众号Java学习指南Il existe également des produits open source de certaines grandes entreprises :
🎜🎜Je suisProgrammeur Qingge, un programmeur post-90 qui aime la vie et le partage. 🎜
Ce numéro présente la sous-base de données et les sous-tables Mysql La solution est présentée ici, j'espère qu'elle pourra aider tout le monde. Veuillez continuer à prêter attention au compte officiel pour plus d'articles d'interview Java à l'avenirGuide d'étude Java🎜. 🎜🎜
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Créez une base de données à l'aide de NAVICAT Premium: Connectez-vous au serveur de base de données et entrez les paramètres de connexion. Cliquez avec le bouton droit sur le serveur et sélectionnez Créer une base de données. Entrez le nom de la nouvelle base de données et le jeu de caractères spécifié et la collation. Connectez-vous à la nouvelle base de données et créez le tableau dans le navigateur d'objet. Cliquez avec le bouton droit sur le tableau et sélectionnez Insérer des données pour insérer les données.
 Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Vous pouvez créer une nouvelle connexion MySQL dans NAVICAT en suivant les étapes: ouvrez l'application et sélectionnez une nouvelle connexion (CTRL N). Sélectionnez "MySQL" comme type de connexion. Entrez l'adresse Hostname / IP, le port, le nom d'utilisateur et le mot de passe. (Facultatif) Configurer les options avancées. Enregistrez la connexion et entrez le nom de la connexion.
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
La récupération des lignes supprimées directement de la base de données est généralement impossible à moins qu'il n'y ait un mécanisme de sauvegarde ou de retour en arrière. Point clé: Rollback de la transaction: Exécutez Rollback avant que la transaction ne s'engage à récupérer les données. Sauvegarde: la sauvegarde régulière de la base de données peut être utilisée pour restaurer rapidement les données. Instantané de la base de données: vous pouvez créer une copie en lecture seule de la base de données et restaurer les données après la suppression des données accidentellement. Utilisez la déclaration de suppression avec prudence: vérifiez soigneusement les conditions pour éviter la suppression accidentelle de données. Utilisez la clause WHERE: Spécifiez explicitement les données à supprimer. Utilisez l'environnement de test: testez avant d'effectuer une opération de suppression.
