
 Java
javaDidacticiel
Il s'agit peut-être du meilleur article détaillé sur l'architecture des microservices que vous ayez jamais lu.
Java
javaDidacticiel
Il s'agit peut-être du meilleur article détaillé sur l'architecture des microservices que vous ayez jamais lu.
Il s'agit peut-être du meilleur article détaillé sur l'architecture des microservices que vous ayez jamais lu.
Cet article présentera l'architecture des microservices et les composants associés, présentera ce qu'ils sont et pourquoi utiliser l'architecture des microservices et ces composants. Cet article se concentre sur l’expression concise de l’image globale de l’architecture des microservices, il n’entrera donc pas dans les détails tels que la façon d’utiliser les composants.
Pour comprendre les microservices, vous devez d'abord comprendre ceux qui ne sont pas des microservices. Habituellement, le contraire des microservices est une application monolithique, c'est-à-dire une application qui regroupe toutes les fonctions dans une unité indépendante. Passer d’une application monolithique aux microservices ne se fait pas du jour au lendemain. Il s’agit d’un processus évolutif progressif. Cet article prendra comme exemple une application de supermarché en ligne pour illustrer ce processus.
Demande initiale
Il y a quelques années, Xiao Ming et Xiao Pi ont lancé ensemble un supermarché en ligne. Xiao Ming est responsable du développement du programme et Xiao Pi est responsable d'autres questions. À cette époque, Internet n’était pas encore développé et les supermarchés en ligne représentaient encore un océan bleu. Tant que la fonction est mise en œuvre, vous pouvez gagner de l'argent à volonté. Leurs besoins sont donc très simples : ils ont uniquement besoin d'un site Web sur le réseau public sur lequel les utilisateurs peuvent parcourir et acheter des produits. Ils ont également besoin d'un backend de gestion capable de gérer les produits, les utilisateurs et les données de commande.
Trions la liste des fonctions :
Site Web Fonctions d'enregistrement et de connexion des utilisateurs Affichage du produit Passer une commande -
Homme fond d'agence -
Gestion des utilisateurs Gestion des produits Gestion des commandes
En raison de besoins simples, Xiao Ming a simplement déplacé ses mains gauche et droite au ralenti et le site Web était prêt. Pour des raisons de sécurité, le backend de gestion n'est pas colocalisé avec le site Web. La main droite et la main gauche de Xiao Ming sont relues au ralenti et le site Web de gestion est prêt. Le schéma global de l'architecture est le suivant :
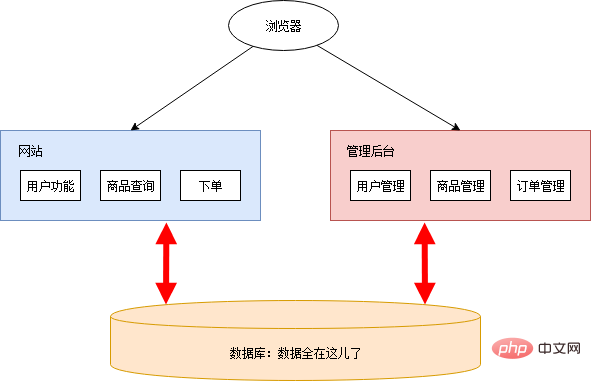
Xiao Ming a agité la main, a trouvé un service cloud à déployer et le site Web était en ligne. Après avoir été lancé en ligne, il a reçu des critiques élogieuses et a été apprécié par toutes sortes de grosses maisons. Xiao Ming et Xiao Pi commencèrent joyeusement à s'allonger et à récupérer l'argent.
Avec le développement des affaires...
Les bons moments n'ont pas duré longtemps. En quelques jours, divers supermarchés en ligne ont vu le jour, ce qui a eu un fort impact sur Xiao Ming Xiaopi.
Sous la pression de la concurrence, Xiaoming Xiaopi a décidé de mettre en œuvre quelques méthodes de marketing :
Réaliser des activités promotionnelles. Par exemple, les réductions du Nouvel An sur le site, la Fête du Printemps, achetez-en deux, obtenez-en un gratuitement, les coupons de nourriture pour chiens de la Saint-Valentin, etc. Développez les canaux et ajoutez le marketing mobile. En plus du site Web, il est également nécessaire de développer une application mobile, une applet WeChat, etc. Marketing de précision. Utilisez les données historiques pour analyser les utilisateurs et fournir des services personnalisés. ……
Ces activités nécessitent le soutien du développement du programme. Xiao Ming a enrôlé son camarade de classe Xiao Hong pour rejoindre l'équipe. Xiaohong est responsable de l'analyse des données et du développement lié aux terminaux mobiles. Xiao Ming est responsable du développement des fonctions liées aux activités promotionnelles.
Parce que la tâche de développement était relativement urgente, Xiao Ming et Xiao Hong n'ont pas planifié soigneusement l'architecture de l'ensemble du système. Il s'est simplement tapoté la tête et a décidé de mettre la gestion des promotions et l'analyse des données en arrière-plan de la gestion, ainsi que WeChat et l'application mobile. ont été construits séparément. Après avoir travaillé toute la nuit pendant quelques jours, les nouvelles fonctions et les nouvelles applications sont pratiquement terminées. Le schéma d'architecture à ce moment est le suivant :
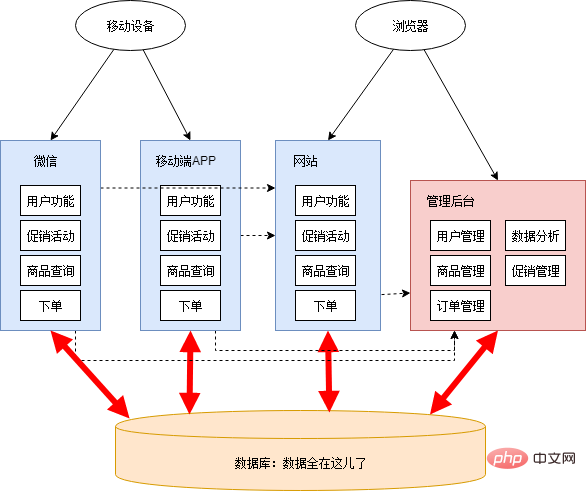
Il y a beaucoup de choses déraisonnables à ce stade :
Les sites Web et les applications mobiles contiennent de nombreux codes en double avec la même logique métier. Les données sont parfois partagées via la base de données, et parfois transmises via des appels d'interface. La relation d'appel de l'interface est compliquée. Afin de fournir des interfaces pour d'autres applications, une seule application change progressivement de plus en plus, incluant beaucoup de logiques qui ne lui appartiennent pas en premier lieu. Les frontières des applications sont floues et l’attribution des fonctions prête à confusion. Le backend de gestion a été initialement conçu avec un faible niveau de sécurité. Après l'ajout de fonctions liées à l'analyse des données et à la gestion des promotions, des goulots d'étranglement en termes de performances sont apparus, affectant d'autres applications. La structure des tables de la base de données dépend de plusieurs applications et ne peut pas être reconstruite et optimisée. Toutes les applications fonctionnent sur une base de données et il existe un goulot d'étranglement en termes de performances dans la base de données. En particulier lorsque l'analyse des données est en cours, les performances de la base de données chutent fortement. Le développement, les tests, le déploiement et la maintenance deviennent de plus en plus difficiles. Même si seule une petite fonctionnalité est modifiée, l’ensemble de l’application doit être publié ensemble. Parfois, du code non testé est accidentellement inclus dans la conférence de presse, ou après la modification d'une fonction, une autre erreur inattendue se produit. Afin de réduire l'impact des éventuels problèmes causés par la publication et l'impact de la suspension des activités en ligne, toutes les candidatures doivent être publiées à trois ou quatre heures du matin. Après la sortie, afin de vérifier que l'application fonctionne normalement, il faut garder un œil sur la période de pointe d'utilisation dans la journée du lendemain... Il y a un phénomène de push and pull au sein de l'équipe . Il y a souvent un long débat sur l'application sur laquelle certaines fonctions publiques devraient être construites, et en fin de compte, soit ils font simplement ce qu'ils veulent, soit ils les placent simplement à un endroit aléatoire sans les maintenir.
Même si les problèmes sont nombreux, on ne peut nier les résultats de cette étape : le système s'est construit rapidement en fonction des évolutions du business. Cependant, les tâches urgentes et lourdes peuvent facilement amener les gens à adopter une réflexion partielle et à court terme et à prendre des décisions de compromis. Dans ce type de structure, chacun se concentre uniquement sur son propre tiers d’acre, sans conception globale et à long terme. Si les choses continuent ainsi, la construction du système deviendra de plus en plus difficile et pourrait même tomber dans un cycle de renversement et de reconstruction constants.
Il est temps de faire un changement
Heureusement, Xiao Ming et Xiao Hong sont de bons jeunes avec des activités et des idéaux. Après avoir pris conscience du problème, Xiao Ming et Xiao Hong ont libéré un peu d'énergie des besoins commerciaux insignifiants, ont commencé à trier la structure globale et se sont préparés à transformer le problème.
Pour opérer une transformation, il faut d'abord avoir suffisamment d'énergie et de ressources. Si votre côté demande (personnel commercial, chef de projet, patron, etc.) est si fort dans la poursuite de la progression de la demande que vous ne pouvez pas allouer d'énergie et de ressources supplémentaires, alors vous ne pourrez peut-être rien faire...
Dans le monde de la programmation, la chose la plus importante est la capacité d'abstraction. Le processus de transformation des microservices est en réalité un processus abstrait. Xiao Ming et Xiao Hong ont organisé la logique commerciale du supermarché en ligne, résumé les capacités commerciales communes et créé plusieurs services publics :
Service utilisateur Service marchandise Service de promotion -
Service de commande Service d'analyse de données
Chaque backend d'application n'a besoin que d'obtenir les données requises de ces services, supprimant ainsi une grande quantité de code redondant, ne laissant qu'une fine couche de contrôle et un front-end. L'architecture de cette étape est la suivante :
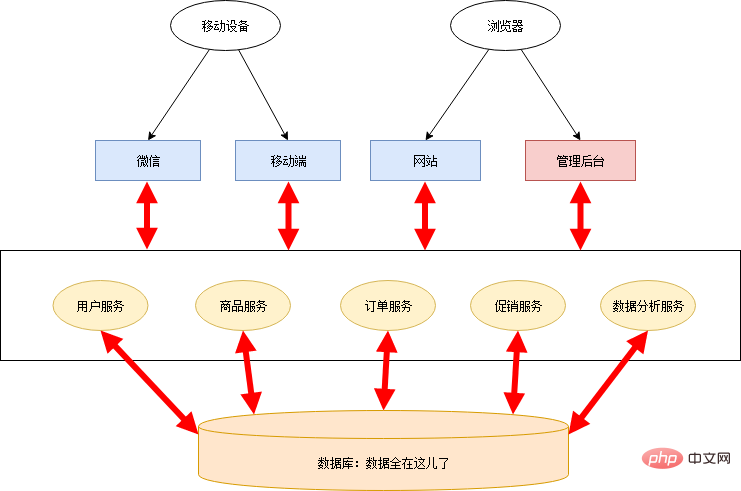
Cette étape ne sépare que les services, et la base de données est toujours partagée, donc certains défauts du système de cheminée existent toujours :
La base de données devient un goulot d'étranglement de performances, et il n'y a qu'un seul point : risque d'échec. La gestion des données a tendance à être chaotique. Même s'il existe une bonne conception modulaire au début, au fil du temps, il y aura toujours un phénomène où un service récupère les données d'un autre service directement de la base de données. La structure des tables de la base de données peut dépendre de plusieurs services, ce qui affecte l'ensemble du système et est difficile à ajuster.
Si vous conservez le modèle de base de données partagée, l'ensemble de l'architecture deviendra de plus en plus rigide et perdra le sens de l'architecture des microservices. Par conséquent, Xiao Ming et Xiao Hong ont travaillé ensemble pour diviser la base de données. Toutes les couches de persistance sont isolées les unes des autres et relèvent de la responsabilité de chaque service. De plus, afin d'améliorer les performances en temps réel du système, un mécanisme de file d'attente de messages est ajouté. L'architecture est la suivante :
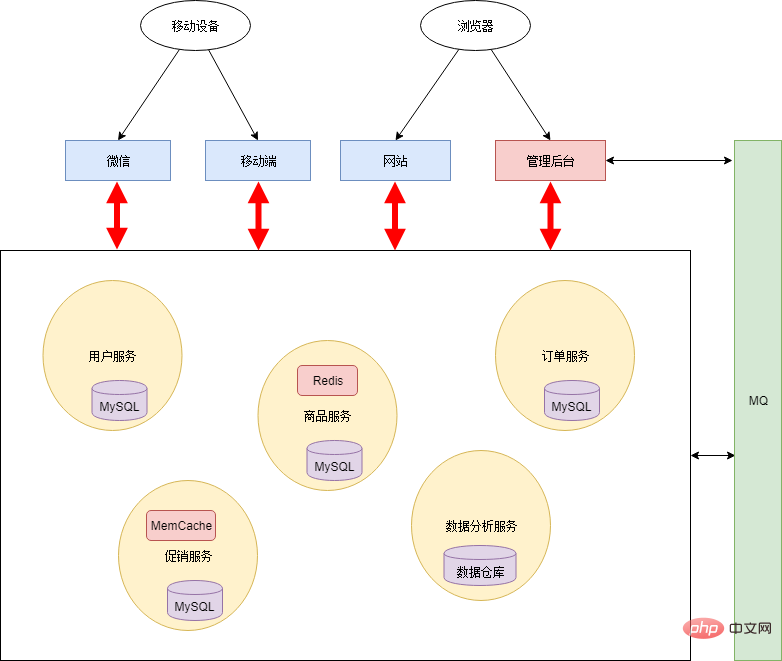
Après un découpage complet, chaque service peut utiliser des technologies hétérogènes. Par exemple, les services d'analyse de données peuvent utiliser des entrepôts de données comme couche de persistance pour effectuer efficacement certains calculs statistiques ; les services de base et les services promotionnels sont consultés plus fréquemment, un mécanisme de mise en cache est donc ajouté.
Une autre façon d'abstraire la logique publique est de transformer cette logique publique en une bibliothèque de cadre public. Cette méthode peut réduire la perte de performances des appels de service. Cependant, le coût de gestion de cette méthode est très élevé, et il est difficile d’assurer la cohérence de toutes les versions de l’application.
Le fractionnement des bases de données présente également certains problèmes et défis : tels que la nécessité d'une mise en cascade entre les bases de données, la granularité des requêtes de données via les services, etc. Mais ces problèmes peuvent être résolus grâce à une conception raisonnable. Dans l’ensemble, le fractionnement d’une base de données présente plus d’avantages que d’inconvénients.
L'architecture des microservices présente également un avantage non technique. Elle rend la division du travail dans l'ensemble du système plus claire et les responsabilités plus claires. Chacun se consacre à fournir de meilleurs services aux autres. À l’ère des applications monolithiques, les fonctions des entreprises publiques n’ont souvent pas de propriété clairement définie. En fin de compte, soit chacun fait ce qu'il veut et chacun le met en œuvre à nouveau ; soit une personne aléatoire (généralement une personne plus compétente ou plus enthousiaste) met en œuvre l'application dont elle est responsable. Dans ce dernier cas, en plus d'être responsable de sa propre application, cette personne est également responsable de fournir ces fonctions publiques à d'autres - et cette fonction n'est à l'origine responsable de personne, simplement parce qu'elle est plus capable/enthousiaste de prendre le relais. blâmer (cette situation est aussi appelée par euphémisme « les capables font le travail dur »). En fin de compte, personne n’était disposé à assurer des fonctions publiques. Au fil du temps, les membres de l’équipe sont progressivement devenus indépendants et ne se souciaient plus de la conception globale de l’architecture. Suivez le compte officiel Java Journey pour recevoir des e-books.
De ce point de vue, l'utilisation de l'architecture des microservices nécessite également des ajustements correspondants de la structure organisationnelle. Par conséquent, la transformation des microservices nécessite le soutien des managers.
Une fois la transformation terminée, Xiao Ming et Xiao Hong ont clairement divisé leurs rôles respectifs. Ils étaient tous les deux très satisfaits, tout était aussi beau et parfait que les équations de Maxwell.
Cependant...
Il n'y a pas de solution miracle
Le printemps est là, tout reprend vie et c'est à nouveau le carnaval annuel du shopping. Voyant le nombre de commandes quotidiennes augmenter régulièrement, Xiaopi, Xiaoming et Xiaohong ont souri joyeusement. Malheureusement, les bons moments n’ont pas duré longtemps. Soudain, le système s’est effondré.
Dans le passé, pour des applications uniques, le dépannage impliquait généralement la consultation des journaux, l'étude des messages d'erreur et des piles d'appels. Dans l'architecture microservice, l'ensemble de l'application est dispersée en plusieurs services, ce qui rend très difficile la localisation du point de défaillance. Xiao Ming a vérifié les journaux un par un et a appelé manuellement chaque service un par un. Après plus de dix minutes de recherche, Xiao Ming a finalement localisé le point faible : le service de promotion ne répondait plus en raison du grand nombre de demandes qu'il recevait. D'autres services appellent directement ou indirectement le service de promotion, ils tombent donc également en panne. Dans une architecture de microservices, une panne de service peut avoir un effet d'avalanche, provoquant la panne de l'ensemble du système. En fait, avant les vacances, Xiao Ming et Xiao Hong ont procédé à une évaluation du volume des demandes. Comme prévu, les ressources du serveur sont suffisantes pour prendre en charge le volume de demandes du jour férié, il doit donc y avoir un problème. Cependant, la situation était urgente. Chaque minute et chaque seconde écoulée était de l'argent gaspillé, donc Xiao Ming n'a pas eu le temps de résoudre le problème. Il a immédiatement pris la décision de créer plusieurs nouvelles machines virtuelles sur le cloud, puis a déployé de nouveaux services promotionnels. par un nœud. Après quelques minutes de fonctionnement, le système est finalement revenu à la normale. On estime que des centaines de milliers de ventes ont été perdues pendant toute la panne, et le cœur de tous les trois saignait...
Ensuite, Xiao Ming a simplement écrit un outil d'analyse des journaux (le volume était si volumineux qu'il était presque impossible de l'ouvrir avec un éditeur de texte et n'était pas visible à l'œil nu), a compté les journaux d'accès aux services promotionnels et a trouvé que lors de la panne, les services du produit étaient Il y a un problème de code Dans certains scénarios, un grand nombre de demandes seront adressées au service promotionnel. Ce problème n'est pas compliqué. Xiao Ming a corrigé ce bug valant des centaines de milliers d'un simple mouvement du doigt.
Le problème a été résolu, mais personne ne peut garantir que d'autres problèmes similaires ne se reproduiront pas. Bien que l'architecture des microservices semble parfaite dans sa conception logique, elle ressemble à un magnifique palais construit à partir de blocs de construction et ne peut pas résister au vent et aux vagues. Bien que l'architecture des microservices résolve d'anciens problèmes, elle en introduit également de nouveaux :
L'ensemble de l'application de l'architecture des microservices est dispersée en plusieurs services, et il est très difficile de localiser le point de défaillance. La stabilité a diminué. À mesure que le nombre de services augmente, la probabilité d'une panne d'un service augmente et une panne de service peut entraîner le blocage de l'ensemble du système. En fait, dans les scénarios de production avec de gros volumes d’accès, des pannes se produiront toujours. Le nombre de services est très important et la charge de travail de déploiement et de gestion est énorme. Développement : Comment garantir que les différents services maintiennent toujours une synergie dans un développement continu. Test : une fois le service divisé, presque toutes les fonctions impliqueront plusieurs services. Le test original d'un seul programme devient un test d'appels entre services. Les tests deviennent plus complexes.
Xiao Ming et Xiao Hong ont tiré les leçons de cette expérience et sont déterminés à résoudre ces problèmes. Le dépannage implique généralement deux aspects : d’une part, on essaie de réduire la probabilité d’une panne, et d’autre part, on réduit l’impact de la panne.
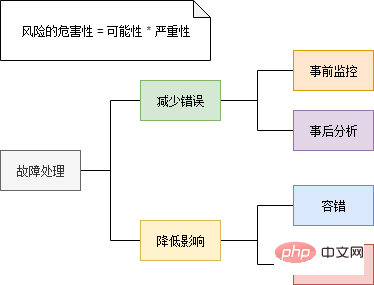
Surveillance - Découvrez les signes d'échecs
Dans les scénarios distribués à haute concurrence, les échecs se produisent souvent soudainement comme une avalanche. Par conséquent, un système de surveillance complet doit être mis en place pour détecter autant que possible les signes de défaillance.
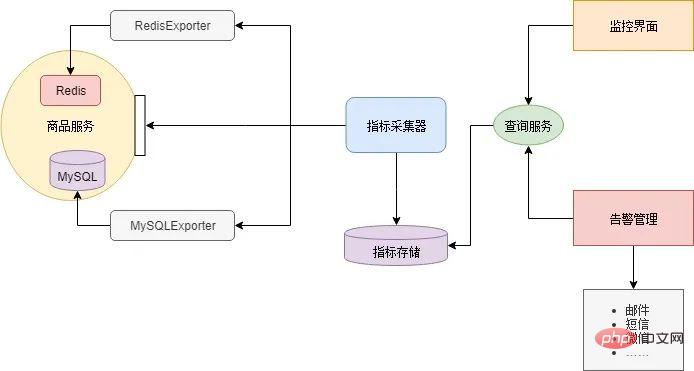
Il existe de nombreux composants dans l'architecture des microservices, et chaque composant doit surveiller différents indicateurs. Par exemple, le cache Redis surveille généralement la valeur de mémoire occupée et le trafic réseau, la base de données surveille le nombre de connexions et l'espace disque, et le service métier surveille le nombre de simultanéités, les délais de réponse, les taux d'erreur, etc. Par conséquent, il n’est pas réaliste de construire un système de surveillance vaste et complet pour surveiller chaque composant, et l’évolutivité sera très faible. L'approche générale consiste à laisser chaque composant fournir une interface (interface de métriques) pour signaler son état actuel. Le format de données généré par cette interface doit être cohérent. Déployez ensuite un composant collecteur d'indicateurs pour obtenir et maintenir régulièrement l'état des composants à partir de ces interfaces, tout en fournissant des services de requête. Enfin, une interface utilisateur est nécessaire pour interroger divers indicateurs du collecteur d'indicateurs, dessiner une interface de surveillance ou émettre des alarmes basées sur des seuils.
La plupart des composants n'ont pas besoin d'être développés par vous-même, il existe des composants open source sur Internet. Xiao Ming a téléchargé RedisExporter et MySQLExporter. Ces deux composants fournissent respectivement des interfaces d'indicateur pour le cache Redis et la base de données MySQL. Les microservices implémentent des interfaces d'indicateurs personnalisées basées sur la logique métier de chaque service. Ensuite, Xiao Ming utilise Prometheus comme collecteur d'indicateurs et Grafana configure l'interface de surveillance et les alertes par e-mail. Un tel système de surveillance des microservices est construit :
Problème de localisation - suivi des liens
Dans l'architecture du microservice, la demande d'un utilisateur implique souvent plusieurs appels de service internes. Afin de faciliter la localisation des problèmes, il est nécessaire de pouvoir enregistrer le nombre d'appels de service générés au sein du microservice lorsque chaque utilisateur le demande, ainsi que leurs relations d'appel. C’est ce qu’on appelle le suivi des liens.
Utilisons un exemple de suivi de lien dans le document Istio pour voir l'effet :
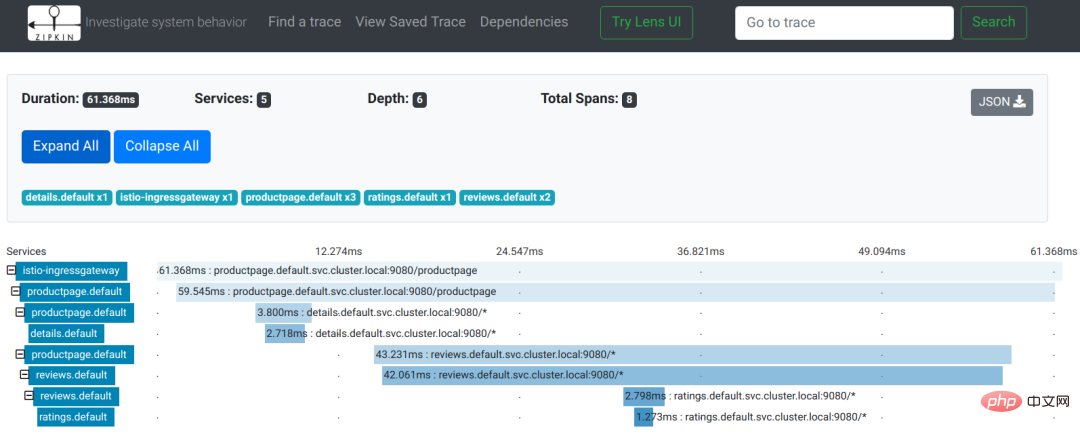
L'image provient du document Istio
Comme vous pouvez le voir sur l'image, il s'agit d'une demande d'utilisateur pour accéder au page de la page produit. Au cours du processus de demande, le service productpage appelle séquentiellement les interfaces des services de détails et d'avis. Le service d'avis appelle l'interface d'évaluation pendant le processus de réponse. L'enregistrement de l'ensemble du suivi des liens est un arbre :
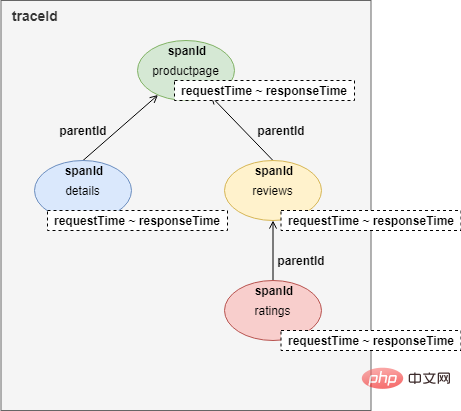
Pour mettre en œuvre le suivi des liens, chaque appel de service enregistrera au moins quatre éléments de données dans des HEADERS HTTP :
traceId : traceId identifie un utilisateur. L'appel demandé lien. Les appels avec le même traceId appartiennent au même lien. spanId : L'ID qui identifie un appel de service, c'est-à-dire l'ID du nœud du suivi du lien. parentId : spanId du nœud parent. requestTime & ResponseTime : temps de demande et temps de réponse.
De plus, vous devez également appeler des composants pour la collecte et le stockage des journaux, ainsi que des composants d'interface utilisateur pour afficher les appels de lien.
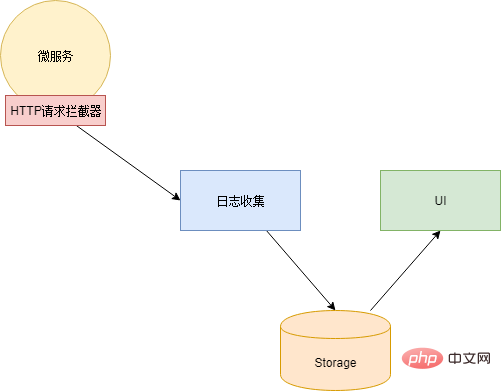
Ce qui précède n'est qu'une explication minimaliste. La base théorique du suivi des liens peut être trouvée dans Dapper de Google
Après avoir compris la base théorique, Xiao Ming a choisi Zipkin, une implémentation open source de Dapper. Puis, d'un simple mouvement du doigt, j'ai écrit un intercepteur de requêtes HTTP, généré ces données et les ai injectées dans HEADERS lors de chaque requête HTTP, et en même temps envoyé le journal des appels de manière asynchrone au collecteur de journaux de Zipkin. Une mention supplémentaire ici est que l'intercepteur de requêtes HTTP peut être implémenté dans le code du microservice, ou il peut être implémenté à l'aide d'un composant proxy réseau (mais dans ce cas, chaque microservice doit ajouter une couche de proxy).
Le suivi des liens peut uniquement localiser le service qui présente un problème et ne peut pas fournir d'informations d'erreur spécifiques. La capacité de trouver des informations d'erreur spécifiques doit être fournie par le composant d'analyse des journaux.
Problèmes d'analyse - Analyse des journaux
Le composant d'analyse des journaux aurait dû être largement utilisé avant l'essor des microservices. Même avec une architecture d'application unique, lorsque le nombre d'accès augmente ou que la taille du serveur augmente, la taille des fichiers journaux augmente au point qu'il devient difficile d'y accéder avec un éditeur de texte. Le pire, c'est qu'ils sont dispersés. sur plusieurs serveurs. Pour résoudre un problème, vous devez vous connecter à chaque serveur pour obtenir les fichiers journaux et rechercher les informations de journal souhaitées une par une (et l'ouverture et la recherche sont très lentes).
Par conséquent, lorsque l'échelle de l'application devient plus grande, nous avons besoin d'un journal "Search Engine". Pour que vous puissiez trouver avec précision le journal que vous souhaitez. De plus, le côté source de données a également besoin de composants pour collecter les journaux et de composants d'interface utilisateur pour afficher les résultats :
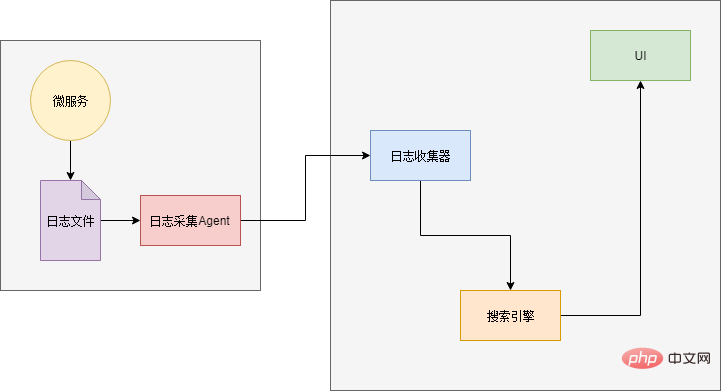
Xiao Ming a étudié et utilisé le célèbre composant d'analyse des journaux ELK. ELK est l'abréviation de trois composants : Elasticsearch, Logstash et Kibana.
Elasticsearch : moteur de recherche et stockage de journaux. Logstash : le collecteur de journaux, qui reçoit les entrées du journal, effectue un prétraitement sur le journal, puis le transmet à Elasticsearch. Kibana : composant d'interface utilisateur, recherche des données via l'API Elasticsearch et les affiche aux utilisateurs.
La dernière petite question est de savoir comment envoyer les logs à Logstash. Une solution consiste à appeler directement l'interface Logstash pour envoyer le journal lors de la sortie du journal. De cette façon, le code doit être modifié à nouveau (Hé, pourquoi utiliser "et")... Alors Xiao Ming a choisi une autre solution : les journaux sont toujours générés dans des fichiers, et un agent est déployé dans chaque service pour analyser le journal. fichiers, puis les exporter vers Logstash.
Pause publicitaire : Suivez le compte public : Java Learning Guide pour obtenir plus d'articles techniques.
Gateway - contrôle des autorisations, gouvernance des services
Après la scission en microservices, un grand nombre de services et d'interfaces sont apparus, rendant toute la relation d'appel désordonnée. Souvent, pendant le processus de développement, lors de l'écriture et de l'écriture, je ne me souviens plus quel service doit être appelé pour certaines données. Ou bien c'était écrit de manière tordue, appelant un service qui ne devait pas être appelé, et une fonction en lecture seule a fini par modifier les données...
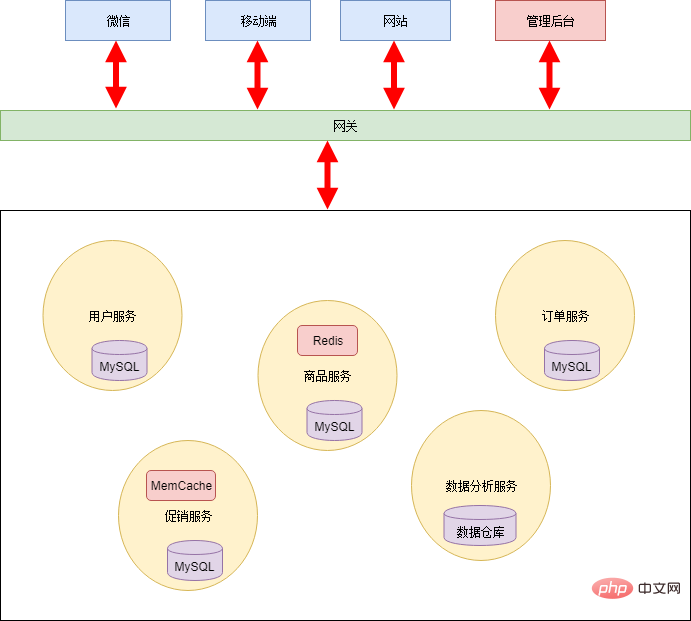
Pour faire face à ces situations, l'appel des microservices a besoin d'un vérificateur, c'est-à-dire , une passerelle. Ajoutez une couche de passerelle entre l'appelant et l'appelé et effectuez une vérification des autorisations à chaque appel. En outre, la passerelle peut également être utilisée comme plate-forme pour fournir des documents d'interface de service.
L'un des problèmes liés à l'utilisation d'une passerelle est de décider du degré de granularité de son utilisation : la solution la plus grossière est une passerelle pour l'ensemble du microservice. L'extérieur du microservice accède au microservice via la passerelle, et l'intérieur du microservice appelle. directement ; la granularité la plus fine est que tous les appels, qu'ils soient internes au microservice ou provenant de l'extérieur, doivent passer par la passerelle. Une solution de compromis consiste à diviser les microservices en plusieurs zones selon les domaines d'activité, à les appeler directement au sein de la zone et à les appeler via la passerelle.
Étant donné que le nombre de services dans l'ensemble du supermarché en ligne n'est pas particulièrement important, Xiao Ming a adopté la solution la plus grossière :
Enregistrement et découverte de services - Expansion dynamique
Les composants précédents sont tous conçus pour réduire la possibilité d'échec. Cependant, des échecs se produiront toujours. Un autre aspect à étudier est donc la manière de réduire l’impact des échecs.
La stratégie de gestion des pannes la plus grossière (et la plus couramment utilisée) est la redondance. De manière générale, un service déploiera plusieurs instances, afin de pouvoir partager la pression et améliorer les performances, et deuxièmement, même si une instance échoue, d'autres instances peuvent toujours répondre.
Un problème avec la redondance est de savoir combien de redondances sont utilisées ? Il n’y a pas de réponse définitive à cette question sur la chronologie. En fonction de la fonction de service et de la période, différents nombres d'instances sont requis. Par exemple, en semaine, 4 instances peuvent suffire ; lors des promotions, lorsque le trafic augmente de manière significative, 40 instances peuvent être nécessaires. Par conséquent, le montant de la redondance n’est pas une valeur fixe, mais peut être ajusté en temps réel selon les besoins. De manière générale, l'opération d'ajout d'une nouvelle instance est la suivante :
- Déployer une nouvelle instance
- Enregistrer la nouvelle instance sur l'équilibrage de charge ou le DNS
- L'opération ne comporte que deux étapes, mais si vous inscrivez-vous au Load Balancing ou au DNS. Si l'opération est manuelle, alors les choses ne seront pas simples. Pensez à la sensation de devoir saisir manuellement 40 adresses IP après avoir ajouté 40 instances...
La solution à ce problème est l'enregistrement et la découverte automatiques du service. Tout d’abord, vous devez déployer un service de découverte de services qui fournit des informations d’adresse pour tous les services enregistrés. Le DNS peut également être considéré comme un service de découverte de services. Ensuite, chaque service d'application s'enregistre automatiquement auprès du service de découverte de services lors de son démarrage. Et une fois le service d'application démarré, la liste d'adresses de chaque service d'application sera synchronisée du service de découverte de services vers le local en temps réel (régulièrement). Le service de découverte de services vérifiera également régulièrement l'état de santé des services d'application et supprimera les adresses d'instances défectueuses. De cette façon, lors de l'ajout d'une instance, il vous suffit de déployer la nouvelle instance. Lorsque l'instance est hors ligne, vous pouvez directement arrêter le service. La découverte de services vérifiera automatiquement l'augmentation ou la diminution des instances de service.
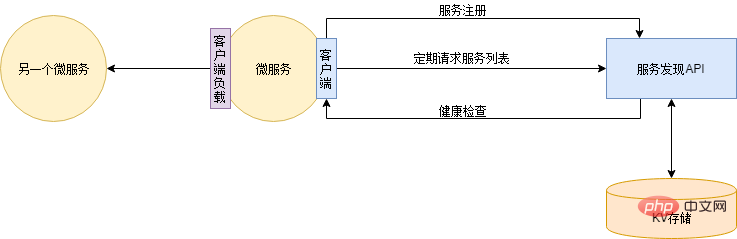
Il existe de nombreux composants parmi lesquels choisir pour la découverte de services, tels que Zookeeper, Eureka, Consul, Etcd, etc. Cependant, Xiao Ming se sentait plutôt bon et voulait montrer ses compétences, alors il en a écrit un basé sur Redis...
Circuits, dégradation du service, limitation de courant
Circuits
Lorsqu'un service cesse de répondre pour diverses raisons, l'appelant attend généralement un certain temps, puis expire ou reçoit un retour d'erreur. Si le lien appelant est relativement long, les demandes peuvent s'accumuler et l'ensemble du lien consomme beaucoup de ressources et attend des réponses en aval. Par conséquent, lorsque l'accès à un service échoue plusieurs fois, le disjoncteur doit être cassé, marquant le service comme ayant cessé de fonctionner et renvoyant directement une erreur. Attendez que le service revienne à la normale avant de rétablir la connexion.
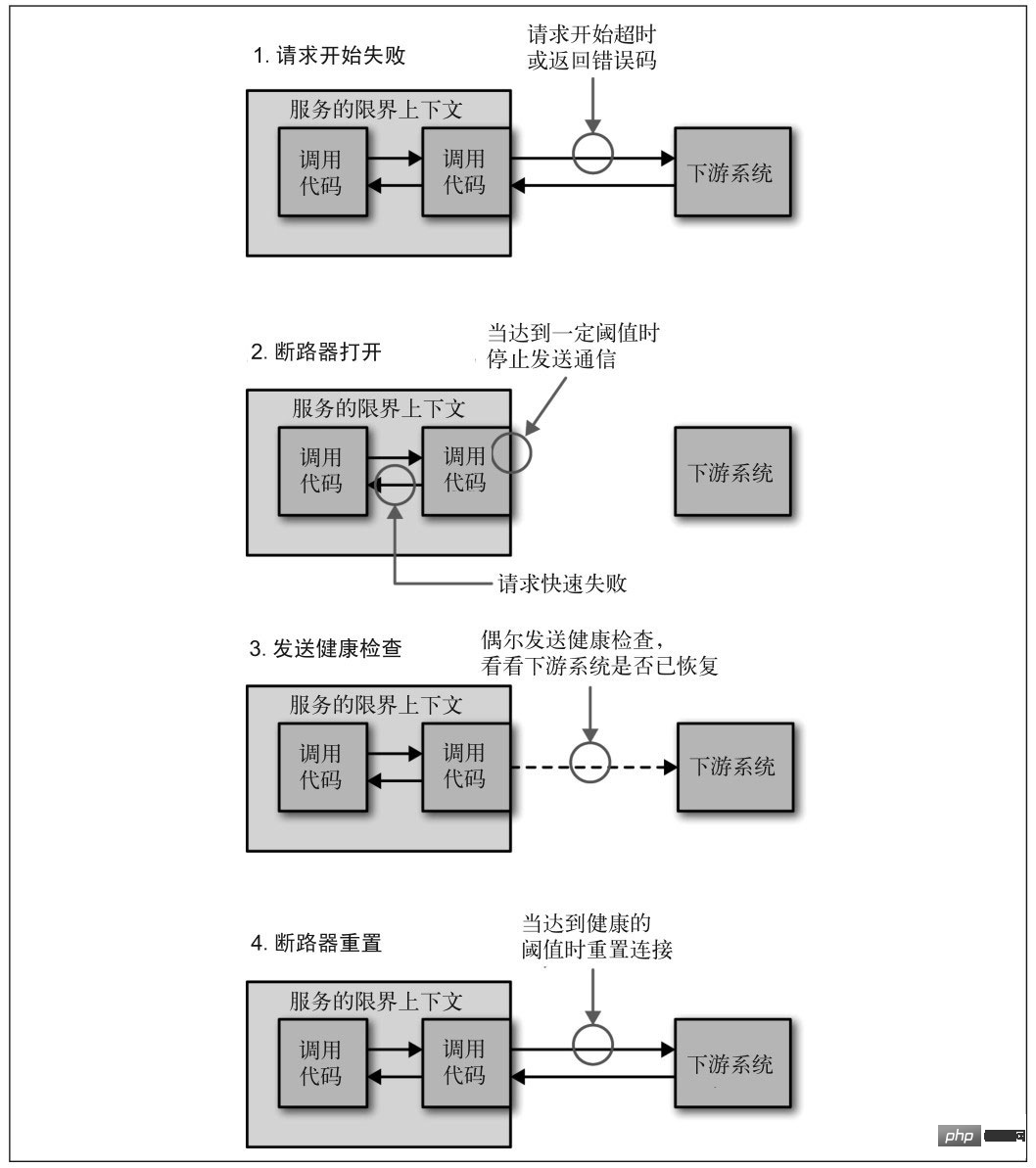
Image de "Microservice Design"
Rétrogradation du service
Lorsque le service en aval cesse de fonctionner, si le service n'est pas l'activité principale, le service en amont doit être rétrogradé pour garantir que l'activité principale n'est pas interrompu. Par exemple, l'interface de commande des supermarchés en ligne dispose d'une fonction permettant de collecter les commandes de produits recommandés. Lorsque le module de recommandation est en panne, la fonction de commande ne peut pas être désactivée en même temps. Il vous suffit de désactiver temporairement la fonction de recommandation.
Limitation de courant
Après le blocage d'un service, le service ou l'utilisateur en amont réessaye généralement l'accès. Cela signifie qu'une fois le service revenu à la normale, il est susceptible de raccrocher immédiatement en raison d'un trafic réseau excessif et de sit-ups répétés dans le cercueil. Le service doit donc être capable de se protéger lui-même, c'est-à-dire de limiter le trafic. Il existe actuellement de nombreuses stratégies de limitation. La plus simple consiste à éliminer les requêtes excédentaires lorsqu'il y a trop de requêtes par unité de temps. De plus, une limitation du courant de partition peut également être envisagée. Refusez uniquement les demandes provenant de services qui génèrent un grand nombre de demandes. Par exemple, le service produit et le service de commande doivent accéder au service de promotion. Le service produit lance un grand nombre de demandes en raison de problèmes de code. Le service de promotion limite uniquement les demandes du service produit et les demandes du service de commande répondent. normalement.
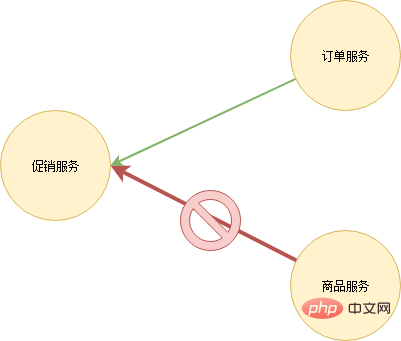
Tests
Dans l'architecture des microservices, les tests sont divisés en trois niveaux :
Tests de bout en bout : couvrant l'ensemble du système, généralement des tests sur des modèles d'interface utilisateur. Test de service : testez l'interface du service. Tests unitaires : tester les unités de code.
La facilité de mise en œuvre des trois tests augmente de haut en bas, mais l'effet du test diminue. Les tests de bout en bout sont les plus longs et les plus laborieux, mais après avoir réussi le test, nous avons le plus confiance dans le système. Les tests unitaires sont les plus simples à mettre en œuvre et les plus efficaces, mais rien ne garantit que l’ensemble du système se déroulera sans problème après le test.
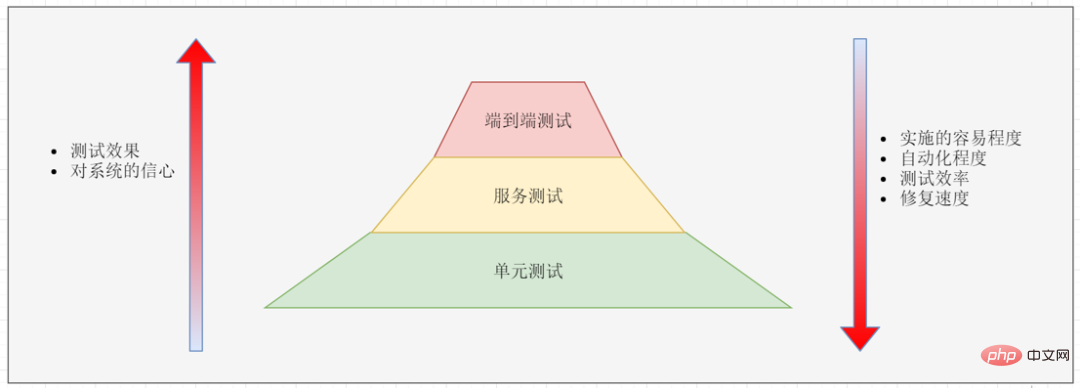
En raison de la difficulté de mise en œuvre des tests de bout en bout, les tests de bout en bout ne sont généralement effectués que sur les fonctions principales. Une fois qu'un test de bout en bout échoue, il doit être décomposé en tests unitaires : la raison de l'échec est ensuite analysée, puis des tests unitaires sont écrits pour reproduire le problème afin que nous puissions détecter la même erreur plus rapidement dans le processus. avenir.
La difficulté des tests de service est que le service dépend souvent de certains autres services. Ce problème peut être résolu via Mock Server :
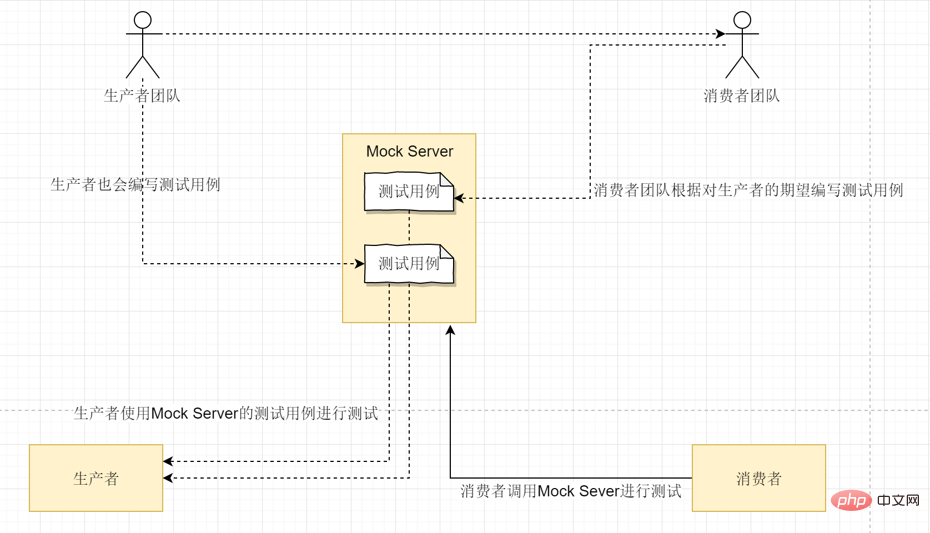
Tout le monde est familier avec les tests unitaires. Nous écrivons généralement un grand nombre de tests unitaires (y compris des tests de régression) pour tenter de couvrir tout le code.
Cadre de microservice
Interface d'indicateur, injection de suivi de lien, détournement de journaux, découverte d'enregistrement de service, règles de routage et autres composants, ainsi que des fonctions telles que le disjoncteur et la limitation de courant, tous doivent ajouter du code d'accueil au service d'application . La mise en œuvre de chaque service d'application individuellement prendrait beaucoup de temps et de main d'œuvre. Sur la base du principe de DRY, Xiao Ming a développé un framework de microservices, extrayant le code qui s'interface avec chaque composant et d'autres codes publics dans le framework, et tous les services d'application sont développés à l'aide de ce framework.
De nombreuses fonctions personnalisées peuvent être réalisées à l'aide du framework microservice. Vous pouvez même injecter des informations sur la pile d'appels de programme dans le suivi des liens pour obtenir un suivi des liens au niveau du code. Ou affichez les informations d'état du pool de threads et du pool de connexions et surveillez l'état sous-jacent du service en temps réel.
L'utilisation d'un framework de microservices unifié pose un sérieux problème : le coût de mise à jour du framework est très élevé. Chaque fois que le framework est mis à niveau, tous les services d'application doivent coopérer avec la mise à niveau. Bien entendu, une solution de compatibilité est généralement utilisée, permettant une période d'attente parallèle pour que tous les services applicatifs soient mis à niveau. Cependant, s'il existe de nombreux services d'application, le temps de mise à niveau peut être très long. Et il existe des services d'application très stables qui sont rarement mis à jour, et le responsable peut refuser de mettre à niveau... Par conséquent, l'utilisation d'un cadre de microservices unifié nécessite des méthodes complètes de gestion des versions et des spécifications de gestion du développement.
Une autre façon - Service Mesh
Une autre façon d'abstraire le code commun consiste à extraire ce code directement dans un composant de proxy inverse. Chaque service déploie en outre ce composant proxy, et tout le trafic sortant et entrant est traité et transmis via ce composant. Ce composant s'appelle Sidecar.
Sidecar n'entraînera pas de frais de réseau supplémentaires. Sidecar sera déployé sur le même hôte que le nœud du microservice et partagera la même carte réseau virtuelle. Par conséquent, la communication entre les nœuds side-car et microservice n’est en réalité réalisée que via une copie de mémoire.
Photo de : Modèle : Service Mesh
Sidecar est uniquement responsable de la communication réseau. Un composant est également nécessaire pour gérer uniformément la configuration de tous les side-cars. Dans Service Mesh, la partie responsable de la communication réseau est appelée le plan de données et la partie responsable de la gestion de la configuration est appelée le plan de contrôle. Le plan de données et le plan de contrôle constituent l’architecture de base de Service Mesh.
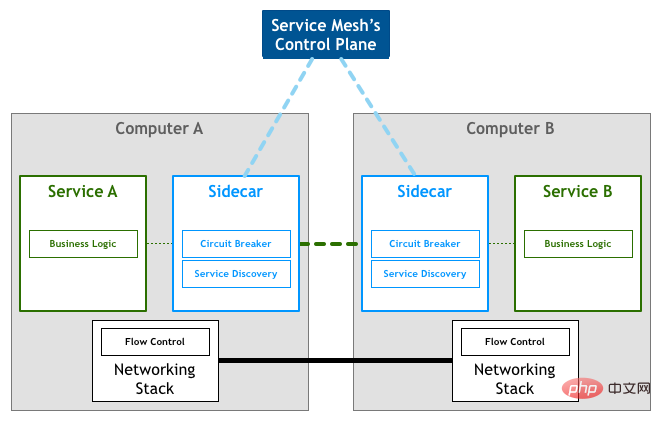
Photo de : Modèle : Service Mesh
L'avantage de Service Mesh par rapport au framework de microservices est qu'il n'envahit pas le code et qu'il est plus pratique à mettre à niveau et à maintenir. Il est souvent critiqué pour des problèmes de performances. Même si le réseau de bouclage ne génère pas de requêtes réseau réelles, il existe toujours un coût supplémentaire lié à la copie de la mémoire. De plus, certains traitements centralisés du trafic affecteront également les performances.
La fin est aussi le début
Les microservices ne sont pas la fin de l'évolution de l'architecture. Pour aller plus loin, il existe le Serverless, le FaaS et d'autres directions. D'un autre côté, il y a aussi des gens qui chantent qu'il faut diviser l'harmonie dans le temps et redécouvrir l'architecture monolithique...
En tout cas, la transformation de l'architecture des microservices est pour le moment terminée. être. Xiao Ming tapota sa tête de plus en plus lisse avec satisfaction et prévoyait de faire une pause ce week-end et de rencontrer Xiao Hong pour une tasse de café.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Top 4 frameworks JavaScript en 2025: React, Angular, Vue, Svelte
Mar 07, 2025 pm 06:09 PM
Top 4 frameworks JavaScript en 2025: React, Angular, Vue, Svelte
Mar 07, 2025 pm 06:09 PM
Cet article analyse les quatre premiers cadres JavaScript (React, Angular, Vue, Svelte) en 2025, en comparant leurs performances, leur évolutivité et leurs perspectives d'avenir. Alors que tous restent dominants en raison de fortes communautés et écosystèmes, leur populaire relatif
 Spring Boot SnakeyAml 2.0 CVE-2022-1471 Issue fixe
Mar 07, 2025 pm 05:52 PM
Spring Boot SnakeyAml 2.0 CVE-2022-1471 Issue fixe
Mar 07, 2025 pm 05:52 PM
Cet article aborde la vulnérabilité CVE-2022-1471 dans SnakeyAml, un défaut critique permettant l'exécution du code distant. Il détaille comment la mise à niveau des applications de démarrage de printemps vers SnakeyAml 1.33 ou ultérieurement atténue ce risque, en soulignant cette mise à jour de dépendance
 Comment fonctionne le mécanisme de chargement de classe de Java, y compris différents chargeurs de classe et leurs modèles de délégation?
Mar 17, 2025 pm 05:35 PM
Comment fonctionne le mécanisme de chargement de classe de Java, y compris différents chargeurs de classe et leurs modèles de délégation?
Mar 17, 2025 pm 05:35 PM
Le chargement de classe de Java implique le chargement, la liaison et l'initialisation des classes à l'aide d'un système hiérarchique avec Bootstrap, Extension et Application Classloaders. Le modèle de délégation parent garantit que les classes de base sont chargées en premier, affectant la classe de classe personnalisée LOA
 Comment implémenter la mise en cache à plusieurs niveaux dans les applications Java à l'aide de bibliothèques comme la caféine ou le cache de goyave?
Mar 17, 2025 pm 05:44 PM
Comment implémenter la mise en cache à plusieurs niveaux dans les applications Java à l'aide de bibliothèques comme la caféine ou le cache de goyave?
Mar 17, 2025 pm 05:44 PM
L'article examine la mise en œuvre de la mise en cache à plusieurs niveaux en Java à l'aide de la caféine et du cache de goyave pour améliorer les performances de l'application. Il couvre les avantages de configuration, d'intégration et de performance, ainsi que la gestion de la politique de configuration et d'expulsion le meilleur PRA
 Node.js 20: Boosts de performances clés et nouvelles fonctionnalités
Mar 07, 2025 pm 06:12 PM
Node.js 20: Boosts de performances clés et nouvelles fonctionnalités
Mar 07, 2025 pm 06:12 PM
Node.js 20 améliore considérablement les performances via des améliorations du moteur V8, notamment la collecte des ordures et les E / S plus rapides. Les nouvelles fonctionnalités incluent une meilleure prise en charge de Webassembly et des outils de débogage raffinés, augmentant la productivité des développeurs et la vitesse d'application.
 Iceberg: L'avenir des tables de Data Lake
Mar 07, 2025 pm 06:31 PM
Iceberg: L'avenir des tables de Data Lake
Mar 07, 2025 pm 06:31 PM
Iceberg, un format de table ouverte pour les grands ensembles de données analytiques, améliore les performances et l'évolutivité du lac Data. Il aborde les limites du parquet / orc par le biais de la gestion interne des métadonnées, permettant une évolution efficace du schéma, un voyage dans le temps, un W simultanément
 Comment puis-je implémenter des techniques de programmation fonctionnelle en Java?
Mar 11, 2025 pm 05:51 PM
Comment puis-je implémenter des techniques de programmation fonctionnelle en Java?
Mar 11, 2025 pm 05:51 PM
Cet article explore l'intégration de la programmation fonctionnelle dans Java à l'aide d'expressions Lambda, de flux API, de références de méthode et facultatif. Il met en évidence des avantages tels que l'amélioration de la lisibilité au code et de la maintenabilité grâce à la concision et à l'immuabilité
 Comment partager les données entre les étapes du concombre
Mar 07, 2025 pm 05:55 PM
Comment partager les données entre les étapes du concombre
Mar 07, 2025 pm 05:55 PM
Cet article explore les méthodes de partage des données entre les étapes du concombre, la comparaison du contexte de scénario, les variables globales, le passage des arguments et les structures de données. Il met l'accent
