
J'étais assez confus lorsque j'ai commencé à écrire cet article, car vous pouvez trouver beaucoup d'informations en recherchant en ligne "ce qui se passe entre la saisie de l'URL et l'affichage de la page". De plus, cette question d'entretien est fondamentalement une question obligatoire. Lors de l'entretien de février, même si je savais ce qui s'était passé au cours du processus, lorsque l'intervieweur a continué à poser des questions étape par étape, de nombreux détails n'étaient pas clairs.
Le but de cet article est de résumer et d'élargir les connaissances à travers ce qui se passe après la saisie de l'URL. L'article risque donc d'être compliqué.
Le processus global est le suivant :
Lorsque nous commençons à saisir l'URL dans le navigateur, le navigateur correspond déjà intelligemment à l'URL possible, et il commencera à partir de Dans les enregistrements de l'historique, les signets, etc., recherchez l'URL qui peut correspondre à la chaîne saisie, puis envoyez des invites intelligentes afin que vous puissiez compléter l'adresse URL. Pour le navigateur Chrome de Google, il affichera même la page Web directement depuis le cache, c'est-à-dire que la page sortira avant que vous appuyiez sur Entrée.
1. Une fois la demande lancée, la première chose que fait le navigateur est de résoudre le nom de domaine. De manière générale, le navigateur vérifiera d'abord les hôtes. du disque dur local pour voir Y a-t-il des règles correspondant à ce nom de domaine Si oui, utilisez directement l'adresse IP dans le fichier hosts.
2. Si l'adresse IP correspondante est introuvable dans le fichier d'hôtes local, le navigateur enverra une requête DNS au serveur DNS local. Les serveurs DNS locaux sont généralement fournis par votre fournisseur de serveur d'accès réseau, tel que China Telecom et China Mobile.
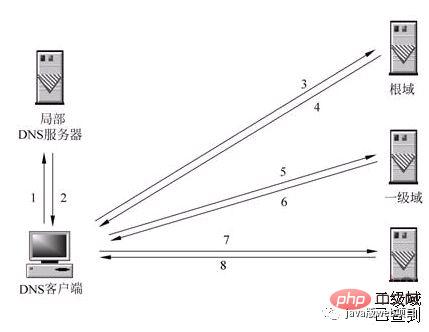
3. Une fois que la requête DNS pour l'URL que vous avez saisie atteint le serveur DNS local, le serveur DNS local interrogera d'abord son enregistrement de cache. S'il y a cet enregistrement dans le cache, le résultat peut être renvoyé directement par ce processus. est une manière récursive d’interroger. Sinon, le serveur DNS local interrogera également le serveur racine DNS.
4. Le serveur DNS racine n'enregistre pas la correspondance spécifique entre les noms de domaine et les adresses IP, mais indique au serveur DNS local que vous pouvez accéder au serveur de domaine pour continuer l'interrogation et donner l'adresse du serveur de domaine. Ce processus est itératif.
5. Le serveur DNS local continue d'envoyer des requêtes au serveur de domaine. Dans cet exemple, l'objet de requête est le serveur de domaine .com. Une fois que le serveur de domaine .com aura reçu la demande, il ne renverra pas directement la correspondance entre le nom de domaine et l'adresse IP, mais indiquera au serveur DNS local l'adresse du serveur de résolution de votre nom de domaine.
6. Enfin, le serveur DNS local envoie une requête au serveur de résolution de nom de domaine, puis reçoit une correspondance entre le nom de domaine et l'adresse IP. Le serveur DNS local renvoie non seulement l'adresse IP à l'ordinateur de l'utilisateur, mais également. renvoie également cette correspondance, enregistrez-la dans le cache afin que la prochaine fois qu'un autre utilisateur interrogera, les résultats puissent être renvoyés directement pour accélérer l'accès au réseau.
L'image ci-dessous explique parfaitement ce processus :

DNS (Domain Name System, Domain Name System), en tant que base de données distribuée sur Internet qui mappe les noms de domaine et les adresses IP les uns aux autres, permet aux utilisateurs d'accéder à Internet plus facilement sans avoir à se souvenir ce qui peut être utilisé La chaîne du numéro IP lue directement par la machine. Le processus permettant d'obtenir finalement l'adresse IP correspondant au nom d'hôte via le nom d'hôte est appelé résolution de nom de domaine (ou résolution de nom d'hôte).
En termes simples, nous sommes plus habitués à mémoriser le nom d'un site Web, tel que www.baidu.com, plutôt que de mémoriser son adresse IP, telle que : 167.23.10.2. Et les ordinateurs mémorisent mieux l’adresse IP d’un site Web que des liens comme www.baidu.com. Parce que DNS est équivalent à un annuaire téléphonique. Par exemple, si vous recherchez le nom de domaine www.baidu.com, alors je regarde dans mon annuaire téléphonique et je saurai, oh, son numéro de téléphone (IP) est 167.23.10.2. .
1. Analyse récursive
Lorsque le serveur DNS local lui-même ne peut pas répondre à la requête DNS du client, vous devez le faire. interroger d’autres serveurs DNS. Il existe actuellement deux méthodes. Celle illustrée dans la figure est la méthode récursive. Le serveur DNS local est chargé d'interroger les autres serveurs DNS. Généralement, il interroge d'abord le serveur de domaine racine du nom de domaine, puis le serveur de noms de domaine racine interroge vers le bas un niveau à la fois. Le résultat final de la requête est renvoyé au serveur DNS local, puis le serveur DNS local le renvoie au client.

2. Analyse itérative
Lorsque le serveur DNS local lui-même ne peut pas répondre à la requête DNS du client, il peut également être résolu via une requête itérative, comme le montre la figure. Le serveur DNS local n'interroge pas lui-même les autres serveurs DNS, mais renvoie les adresses IP des autres serveurs DNS capables de résoudre le nom de domaine au programme DNS client. Le programme DNS client continue ensuite d'interroger ces serveurs DNS jusqu'à ce que les résultats de la requête soient disponibles. obtenu jusqu'à. En d’autres termes, l’analyse itérative vous aide uniquement à trouver les serveurs pertinents, mais ne vous aidera pas à les vérifier. Par exemple : l'adresse IP du serveur baidu.com est ici 192.168.4.5. Vous pouvez la vérifier vous-même. Je suis très occupé, je ne peux donc que vous aider ici.
Nous avons mentionné plus tôt le serveur DNS racine et le serveur DNS du domaine. C'est ainsi que l'espace des noms de domaine DNS est organisé. Les cinq catégories utilisées pour décrire les noms de domaine DNS dans l'espace de noms en fonction de leurs fonctions sont présentées dans le tableau ci-dessous, ainsi que des exemples de chaque type de nom
 (Stealed Picture)
(Stealed Picture)
Lorsqu'un site web compte suffisamment d'utilisateurs, si les ressources demandées à chaque fois se trouvent sur la même machine, alors la machine peut planter à tout moment. La solution consiste à utiliser la technologie d'équilibrage de charge DNS. Son principe est de configurer plusieurs adresses IP pour le même nom d'hôte dans le serveur DNS. Lors de la réponse aux requêtes DNS, le serveur DNS répondra à chaque requête avec l'adresse IP enregistrée par l'hôte. dans le fichier DNS. Renvoyez différents résultats d'analyse dans l'ordre, guidez l'accès des clients à différentes machines, de sorte que différents clients accèdent à différents serveurs, réalisant ainsi un équilibrage de charge. Par exemple, en fonction de la charge de chaque machine, la distance entre la machine et la machine. l'utilisateur peut être la distance géographique, etc.
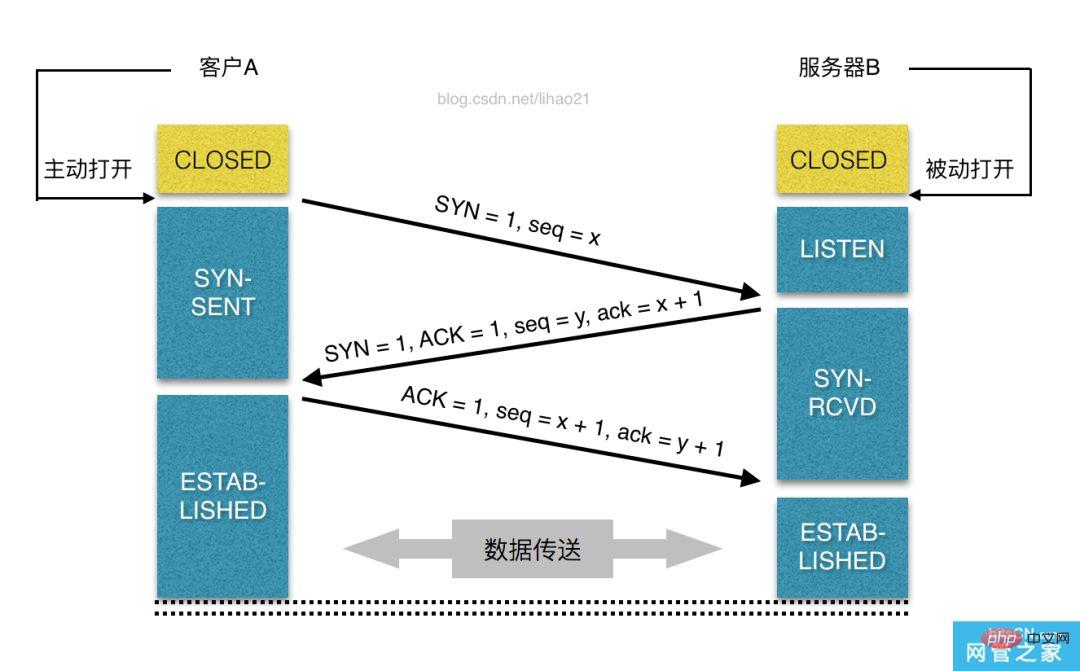
Après avoir obtenu l'adresse IP correspondant au nom de domaine, le navigateur utilisera un port aléatoire (1024<code><span style="font-size: 16px;">。</span>. Une fois que cette demande de connexion atteint le serveur (via divers périphériques de routage, sauf dans le LAN), elle entre dans la carte réseau, puis entre dans la pile de protocole TCP/IP du noyau (utilisée pour identifier la demande de connexion , Décapsuler le paquet, le décoller couche par couche), et peut également être filtré par le pare-feu Netfilter (un module appartenant au noyau), et enfin atteindre le programme WEB, et enfin établir une connexion TCP/IP.
Connexion TCP comme indiqué sur l'image :
Après avoir établi la connexion TCP, lancez une requête http. Un en-tête de requête http typique doit généralement inclure la méthode de requête, telle que GET ou POST, etc. Les méthodes PUT et DELETE, HEAD, OPTION et TRACE sont moins couramment utilisées. Les navigateurs généraux ne peuvent lancer que des requêtes GET ou POST.
Lorsque le client initie une requête http au serveur, il y aura des informations de requête. Les informations de requête contiennent trois parties :
| Protocole/version URI de la méthode de requête
| | Texte de la demande :
Ce qui suit est un exemple complet de requête HTTP :
GET/sample.jspHTTP/1.1Accept:image/gif.image/jpeg,*/*Accept-Language:zh-cn
Connection:Keep-Alive
Host:localhost
User-Agent:Mozila/4.0(compatible;MSIE5.01;Window NT5.0)
Accept-Encoding:gzip,deflate
username=jinqiao&password=1234
(1) La première ligne de la requête est "Proposition/version d'URL de méthode" : GET/sample.jsp HTTP/1.1
(2) En-tête de requête (En-tête de requête)
Accept:image/gif.image/jpeg.*/* Accept-Language:zh-cn Connection:Keep-Alive Host:localhost User-Agent:Mozila/4.0(compatible:MSIE5.01:Windows NT5.0) Accept-Encoding:gzip,deflate.
username=jinqiao&password=1234
Pourquoi le serveur doit-il rediriger au lieu d'envoyer directement le contenu de la page Web que l'utilisateur souhaite voir ? L’une des raisons est liée au classement des moteurs de recherche. Si une page a deux adresses, comme http://www.yy.com/ et http://yy.com/, les moteurs de recherche penseront qu'il s'agit de deux sites Web. En conséquence, chaque lien de recherche sera réduit et. le résultat de la recherche sera réduit. Et les moteurs de recherche savent ce que signifie la redirection permanente 301, ils classeront donc les adresses avec et sans www dans le même classement de sites Web. De plus, l'utilisation d'adresses différentes rendra la convivialité du cache moins bonne. Lorsqu'une page porte plusieurs noms, elle peut apparaître plusieurs fois dans le cache.
Les codes d'état 301 et 302 indiquent une redirection, ce qui signifie que le navigateur accédera automatiquement à une nouvelle adresse URL après avoir reçu le code d'état renvoyé par le serveur. Cette adresse peut être obtenue à partir de l'en-tête Location de la réponse (Le. L'effet que l'utilisateur voit est que l'adresse A qu'il a saisie change instantanément en une autre adresse B) - c'est ce qu'ils ont en commun.
Leur différence est. 301 signifie que la ressource à l'ancienne adresse A a été définitivement supprimée (cette ressource n'est plus accessible Le moteur de recherche échangera également l'ancienne URL contre l'URL redirigée lors de l'exploration du nouveau contenu ;
302 signifie). que la ressource à l'ancienne adresse A est toujours là (toujours accessible). Cette redirection ne passe que temporairement de l'ancienne adresse A à l'adresse B. Le moteur de recherche explorera le nouveau contenu et enregistrera l'ancienne URL. SEO302 est meilleur que 301
2) Raisons de la redirection :
(1) Ajustement du site Web (comme la modification de la structure du répertoire Web
(2) La page Web a été déplacée vers une nouvelle adresse) ;
(3) Changement d'extension de page Web (si l'application doit changer .php en .Html ou .shtml).
Dans ce cas, si aucune redirection n'est effectuée, l'ancienne adresse dans les favoris de l'utilisateur ou dans la base de données du moteur de recherche ne fera que provoquer chez le client visiteur un message d'erreur de 404 pages, et le trafic d'accès sera en plus perdu en vain ; certains sites Web de noms de domaine multiples enregistrés doivent également rediriger les utilisateurs qui visitent ces noms de domaine pour accéder automatiquement au site principal.
Lorsqu'un site Web ou une page Web est temporairement déplacé vers un nouvel emplacement dans les 24 à 48 heures, un saut 302 sera effectué à ce moment-là. Le scénario dans lequel un saut 301 est utilisé est que le site Web précédent doit être supprimé pour certains. raison. L’accès à la nouvelle adresse est alors permanent.
Pour être clair et précis : les scénarios généraux d'utilisation de 301 jumps sont les suivants :
1. Le nom de domaine expire et ne veut pas être renouvelé (ou un nom de domaine plus adapté au site Web est trouvé) et veut changer le nom de domaine.
2. Le nom de domaine sans www apparaît dans les résultats de recherche du moteur de recherche, mais le nom de domaine avec www n'est pas inclus. A ce moment, vous pouvez utiliser la redirection 301 pour indiquer au moteur de recherche quel est le nom de domaine notre cible.
3. Le serveur d'espace est instable lors du changement d'espace.
Maintenant, le navigateur sait que "http://www.google.com/" est la bonne adresse d'accès, il enverra donc une autre requête http. Il n'y a rien à dire ici
Après les étapes précédentes, nous avons finalement envoyé notre requête http au serveur. En fait, la redirection précédente a déjà atteint le serveur. le faire ? Et si nous traitions nos demandes ?
后端从在固定的端口接收到TCP报文开始,它会对TCP连接进行处理,对HTTP协议进行解析,并按照报文格式进一步封装成HTTP Request对象,供上层使用。
一些大一点的网站会将你的请求到反向代理服务器中,因为当网站访问量非常大,网站越来越慢,一台服务器已经不够用了。于是将同一个应用部署在多台服务器上,将大量用户的请求分配给多台机器处理。此时,客户端不是直接通过HTTP协议访问某网站应用服务器,而是先请求到Nginx,Nginx再请求应用服务器,然后将结果返回给客户端,这里Nginx的作用是反向代理服务器。同时也带来了一个好处,其中一台服务器万一挂了,只要还有其他服务器正常运行,就不会影响用户使用。
如图所示:
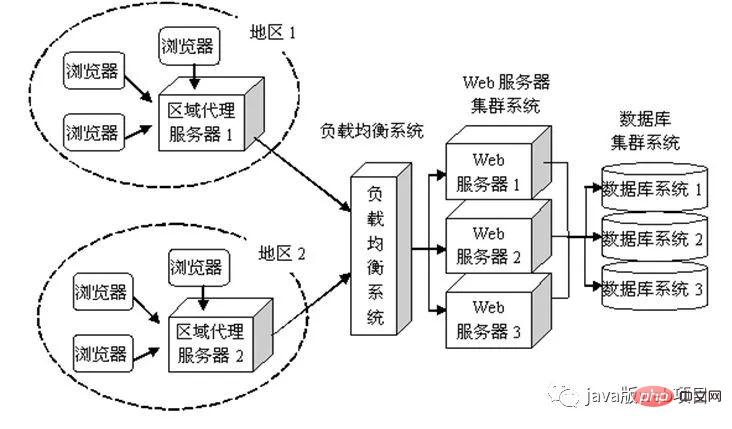
通过Nginx的反向代理,我们到达了web服务器,服务端脚本处理我们的请求,访问我们的数据库,获取需要获取的内容等等,当然,这个过程涉及很多后端脚本的复杂操作。由于对这一块不熟,所以这一块只能介绍这么多了。
经过前面的6个步骤,服务器收到了我们的请求,也处理我们的请求,到这一步,它会把它的处理结果返回,也就是返回一个HTPP响应。
HTTP响应与HTTP请求相似,HTTP响应也由3个部分构成,分别是:
l 状态行
l 响应头(Response Header)
l 响应正文
HTTP/1.1 200 OK Date: Sat, 31 Dec 2005 23:59:59 GMT Content-Type: text/html;charset=ISO-8859-1 Content-Length: 122<html> <head> <title>http</title> </head><body> <!-- body goes here --> </body> </html>
状态行:
状态行由协议版本、数字形式的状态代码、及相应的状态描述,各元素之间以空格分隔。
格式: HTTP-Version Status-Code Reason-Phrase CRLF
例如: HTTP/1.1 200 OK
--Version du protocole : s'il faut utiliser http1.0 ou d'autres versions
-- Description du statut : La description du statut donne une brève description textuelle du code de statut. Par exemple, lorsque le code d'état est 200, la description est ok
-- Code d'état : Le code d'état est composé de trois chiffres. Le premier chiffre définit la catégorie de la réponse et a cinq valeurs possibles. Comme suit
1xx : Code d'état informatif, indiquant que le serveur a reçu la demande du client et que le client peut continuer à envoyer des demandes.
100 Continue
101 Switching Protocols
2xx : Code d'état de réussite, indiquant que le serveur a reçu avec succès la demande et l'a traitée.
200 OK Indique que la demande du client est réussie
204 Aucun contenu réussi, mais ne renvoie la partie principale d'aucune entité
206 Contenu partiel Une demande de plage a été exécutée avec succès
3xx : Code d'état de redirection, indiquant que le serveur demande au client de rediriger.
301 Déplacé de façon permanente Redirection permanente, l'en-tête Location du message de réponse doit avoir la nouvelle URL de la ressource
302 Trouvé Redirection temporaire, l'URL donnée dans l'en-tête Location du message de réponse est utilisée pour la localisation temporaire Ressource
303 Voir Autre La ressource demandée a un autre URI Le client doit utiliser la méthode GET pour obtenir la ressource demandée
304 Non modifié Le contenu du serveur n'a pas été mis à jour et le cache du navigateur peut être lu directement .
307 Redirection Temporaire Redirection temporaire. La même signification que 302 Found. 302 interdit la conversion de POST en GET, mais ce n'est pas nécessairement le cas en utilisation réelle. 307 autres navigateurs peuvent suivre cette norme, mais cela dépend aussi de l'implémentation spécifique du navigateur
4xx : Statut d'erreur du client. code, Indique que la demande du client contient du contenu illégal.
400 Bad Request indique que la requête du client comporte une erreur de syntaxe et ne peut pas être comprise par le serveur
401 Unauthonzed indique que la requête n'est pas autorisée. Ce code d'état doit être utilisé avec le champ d'en-tête WWW-Authenticate
. 403 Forbidden indique que le serveur Lorsqu'une demande est reçue, mais que le service est refusé, la raison pour laquelle le service n'est pas fourni sera généralement indiquée dans le corps de la réponse
404 Not Found La ressource demandée n'existe pas, par exemple , une mauvaise URL a été saisie
5xx : Code d'état d'erreur du serveur, indiquant que le serveur n'a pas réussi à traiter normalement la demande du client et qu'une erreur inattendue s'est produite.
500 Internel Server Error signifie qu'une erreur inattendue s'est produite sur le serveur, entraînant l'incapacité de répondre à la demande du client
503 Service Unavailable signifie que le serveur est actuellement incapable de traiter la demande du client après une période. Pendant un certain temps, le serveur peut revenir à la normale
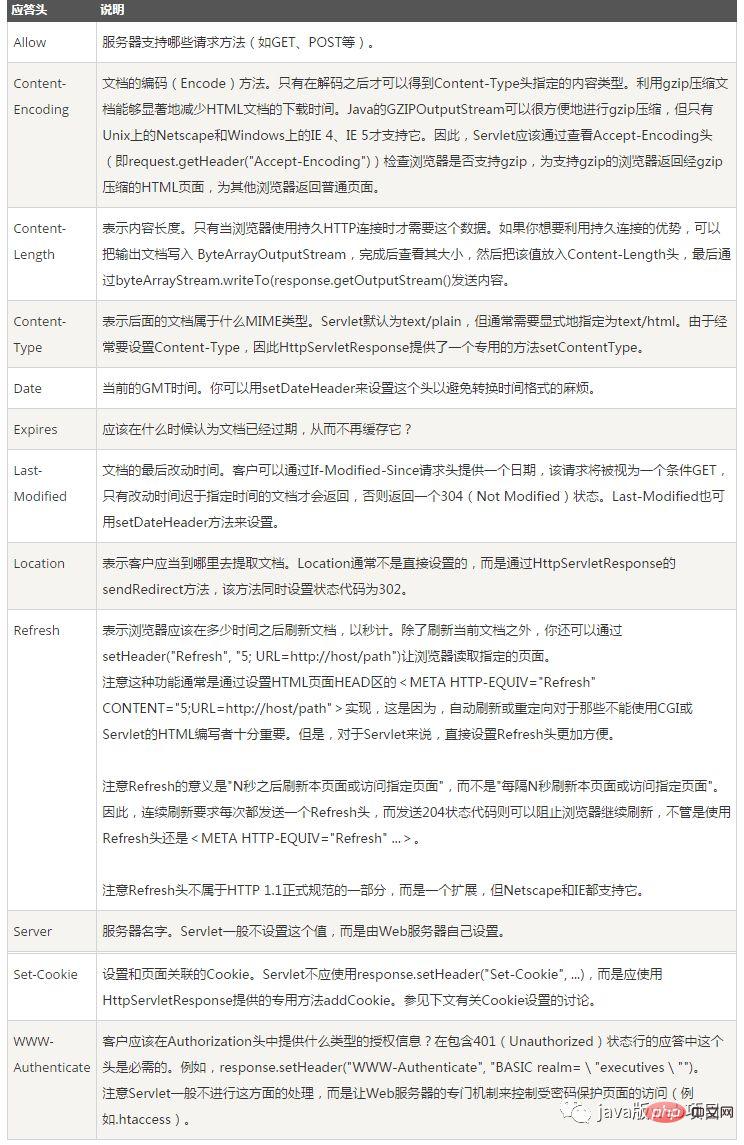
En-tête de réponse :
En-tête de réponse : composé de paires mot-clé/valeur, une paire par ligne, les mots-clés et les valeurs sont séparés par deux points anglais : : : , les en-têtes de réponse typiques sont :
Le corps de la réponse
contient certaines informations spécifiques dont nous avons besoin, telles que les cookies, le HTML, l'image, les données de demande renvoyées par le backend, etc. Il convient de noter ici qu'il y a une ligne d'espace entre le corps de la réponse et l'en-tête de la réponse, indiquant que les informations de l'en-tête de la réponse vont jusqu'à l'espace. L'image ci-dessous est le corps de la requête capturé par fiddler, dans la case rouge : . Corps de la réponse :
Lorsque le navigateur n'accepte pas entièrement tous les documents HTML, il a déjà commencé à afficher cette page. Comment le navigateur présente-t-il la page sur le. écran? Différents navigateurs peuvent avoir des processus d'analyse différents. Ici, nous présentons uniquement le processus de rendu de webkit. L'image ci-dessous correspond au processus de rendu de WebKit. Ce processus comprend :
.Analyser le HTML pour créer une arborescence DOM-> Créer une arborescence de rendu-> Disposition d'une arborescence de rendu-> Dessiner une arborescence de rendu
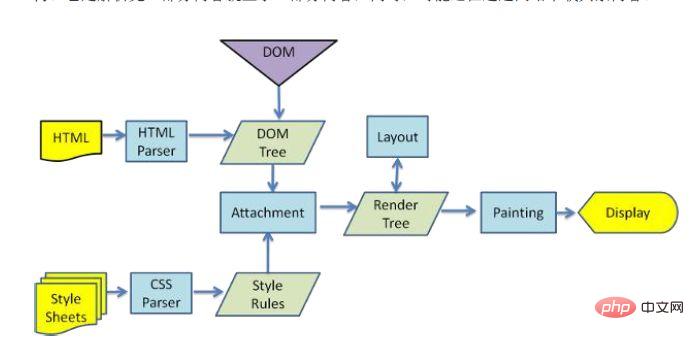
Lorsque le navigateur analyse le fichier HTML, il sera chargé "de haut en bas". . Et effectuez l'analyse et le rendu pendant le processus de chargement. Pendant le processus d'analyse, s'il y a une demande de ressources externes, telles que des images, un lien externe CSS, une police d'icônes, etc., le processus de demande est asynchrone et n'affectera pas le chargement du document HTML.
Pendant le processus d'analyse, le navigateur analysera d'abord le fichier HTML pour créer une arborescence DOM, puis analysera le fichier CSS pour créer une arborescence de rendu. Une fois l'arborescence de rendu créée, le navigateur commence à présenter le rendu. arbre et dessinez-le sur l’écran. Ce processus est relativement complexe et implique deux concepts : refusion et repeinture.
Chaque élément du nœud DOM existe sous la forme d'un modèle de boîte, ce qui nécessite que le navigateur calcule sa position et sa taille. Ce processus est appelé relow lorsque la position, la taille et d'autres attributs du modèle de boîte, tels que. as Une fois la couleur, la police, etc. déterminées, le navigateur commence à dessiner le contenu. Ce processus est appelé repeindre.
La page sera inévitablement redistribuée et repeinte lorsqu'elle sera chargée pour la première fois. Le processus de redistribution et de réparation consomme beaucoup de performances, en particulier sur les appareils mobiles. Il détruira l'expérience utilisateur et provoquera parfois le blocage de la page. Nous devrions donc réduire le reflux et repeindre le moins possible.
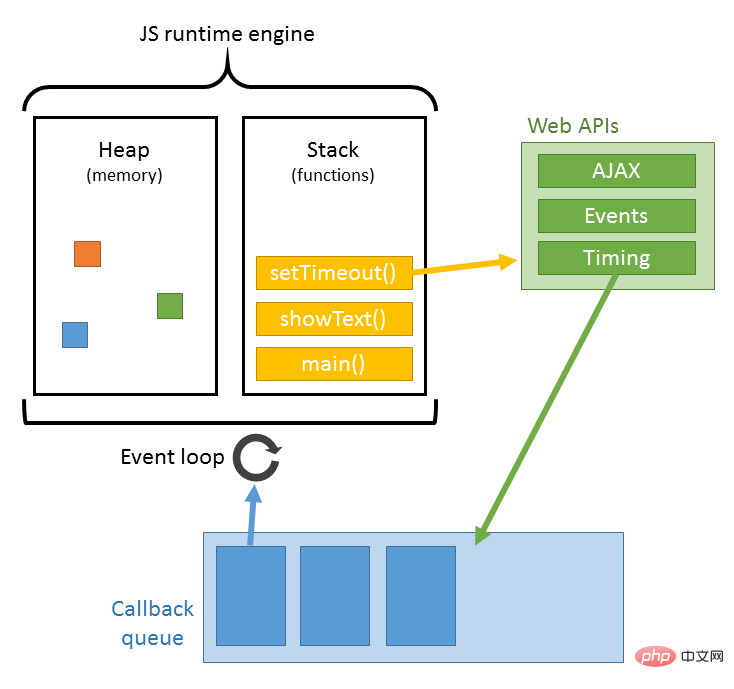
Lorsqu'un fichier js est rencontré lors du chargement d'un document, le document HTML suspendra le thread de rendu (chargement, analyse et synchronisation du rendu), n'attendant pas seulement que le fichier js dans le document soit chargé , mais aussi attendre que l'analyse soit exécutée. Une fois terminé, le fil de rendu du document html peut être repris. Étant donné que JS peut modifier le DOM, le documentwrite le plus classique, cela signifie que le téléchargement ultérieur de toutes les ressources peut ne pas être nécessaire avant la fin de l'exécution de JS. C'est la raison fondamentale pour laquelle js bloque les téléchargements ultérieurs de ressources. Je comprends donc que dans le code habituel, js est placé à la fin du document html.
L'analyse JS est complétée par le moteur d'analyse JS du navigateur, tel que le V8 de Google. JS s'exécute dans un seul thread, ce qui signifie qu'il ne peut faire qu'une seule chose à la fois. Toutes les tâches doivent être mises en file d'attente. La tâche précédente se termine avant que la suivante puisse démarrer. Cependant, certaines tâches prennent du temps, telles que la lecture et l'écriture des E/S, etc., un mécanisme est donc nécessaire pour exécuter en premier les tâches ultérieures, à savoir : les tâches synchrones (synchrones) et les tâches asynchrones (asynchrones).
Le mécanisme d'exécution de JS peut être considéré comme un thread principal plus une file d'attente de tâches. Les tâches synchrones sont des tâches exécutées sur le thread principal et les tâches asynchrones sont des tâches placées dans la file d'attente des tâches. Toutes les tâches synchrones sont exécutées sur le thread principal, formant une pile d'exécution ; une tâche asynchrone placera un événement dans la file d'attente des tâches lorsqu'elle aura le résultat en cours d'exécution, lorsque le script est en cours d'exécution, elle exécutera d'abord la pile d'exécution en séquence, et puis extrayez l'événement de la file d'attente des tâches et exécutez-le. Pour les tâches de la file d'attente des tâches, ce processus est répété en continu, c'est pourquoi il est également appelé boucle d'événements. Pour le processus spécifique, vous pouvez lire mon article : Cliquez ici
En fait, cette étape peut être mise en parallèle à l'étape 8. Lorsque le navigateur affiche du HTML , il remarquera la nécessité d'obtenir des balises pour d'autres contenus d'adresse. À ce stade, le navigateur enverra une requête get pour récupérer les fichiers. Par exemple, je souhaite obtenir des images externes, des fichiers CSS, JS, etc., similaires au lien suivant :
Picture : http://static.ak.fbcdn.net/rsrc.php/z12E0/hash/ 8q2anwu7.gif
Feuille de style CSS : http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css
Fichier JavaScript : http://static.ak.fbcdn. net/rsrc.php/zEMOA/hash/c8yzb6ub.js
Ces adresses doivent passer par un processus similaire à la lecture HTML. Ainsi le navigateur va rechercher ces noms de domaine dans DNS, envoyer des requêtes, rediriger etc...
Contrairement aux pages dynamiques, les fichiers statiques permettront au navigateur de les mettre en cache. Certains fichiers n'ont peut-être pas besoin de communiquer avec le serveur, mais peuvent être lus directement depuis le cache, ou peuvent être placés dans un CDN
À ce stade, le processus depuis la saisie de l'URL jusqu'à l'affichage de la page est enfin terminé. Bien sûr, le style d'écriture est limité et il y a des erreurs. Vous êtes invités à souligner que cet article fait référence à de nombreux articles, mais je ne me souviens pas des liens vers de nombreux articles, je ne liste donc que les trois liens de référence suivants.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Que signifie l'URL ?
Que signifie l'URL ?
 que signifie l'URL
que signifie l'URL
 quelle est l'URL
quelle est l'URL
 Trois méthodes d'encodage couramment utilisées
Trois méthodes d'encodage couramment utilisées
 La différence entre HTML et URL
La différence entre HTML et URL
 Pourquoi n'y a-t-il pas de son dans les réunions Tencent ?
Pourquoi n'y a-t-il pas de son dans les réunions Tencent ?
 Comment écrire des contraintes de vérification MySQL
Comment écrire des contraintes de vérification MySQL
 Comment créer des graphiques et des graphiques d'analyse de données en PPT
Comment créer des graphiques et des graphiques d'analyse de données en PPT
 Les caractéristiques les plus importantes des réseaux informatiques
Les caractéristiques les plus importantes des réseaux informatiques









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



