
 Opération et maintenance
exploitation et maintenance Linux
Je ne sais pas comment utiliser le logiciel de pare-feu Linux IPtables ! Quel genre de personne chargée de l'exploitation et de la maintenance êtes-vous ?
Opération et maintenance
exploitation et maintenance Linux
Je ne sais pas comment utiliser le logiciel de pare-feu Linux IPtables ! Quel genre de personne chargée de l'exploitation et de la maintenance êtes-vous ?
Je ne sais pas comment utiliser le logiciel de pare-feu Linux IPtables ! Quel genre de personne chargée de l'exploitation et de la maintenance êtes-vous ?

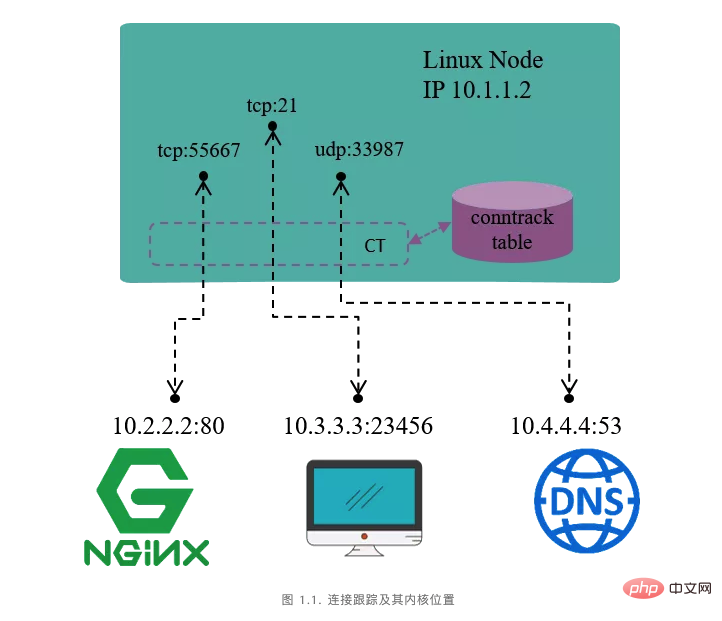
Suivi des connexions (conntrack)
-
La connexion pour que la machine accède au service HTTP externe (destination). port 80) La connexion de la machine d'accès externe au service FTP (port de destination 21) La connexion de la machine au service DNS externe (port de destination 53)
Extraire les informations de tuple du paquet de données, identifier le flux de données (flux) et la connexion correspondante (connexion). Maintenir une base de données d'état (table conntrack) pour toutes les connexions, comme l'heure de création de la connexion, le nombre de paquets envoyés, le nombre d'octets envoyés, etc. Recyclez les connexions expirées (GC). Fournir des services pour les fonctions de niveau supérieur (telles que NAT).
In. le protocole TCP/IP, la connexion est un concept de couche 4. TCP est orienté connexion et tous les paquets envoyés nécessitent une réponse (ACK) de la part du homologue, et il existe un mécanisme de retransmission. UDP est sans connexion, les paquets envoyés ne nécessitent pas de réponse de la part du homologue et il n'existe aucun mécanisme de retransmission. Dans conntrack(CT), un flux de données (flow) défini par un tuple (tuple) représente une connexion (connection). Nous verrons plus tard que les protocoles à trois couches tels que UDP et même ICMP ont également des enregistrements de connexion dans CT, mais tous les protocoles ne seront pas connectés.
Netfilter
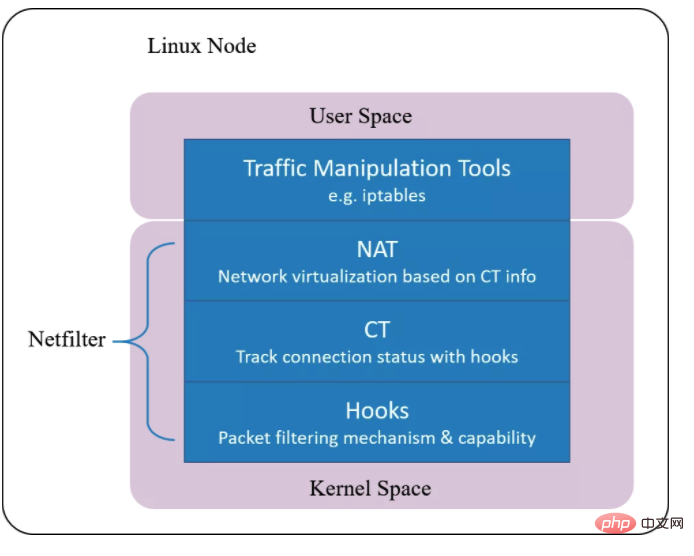
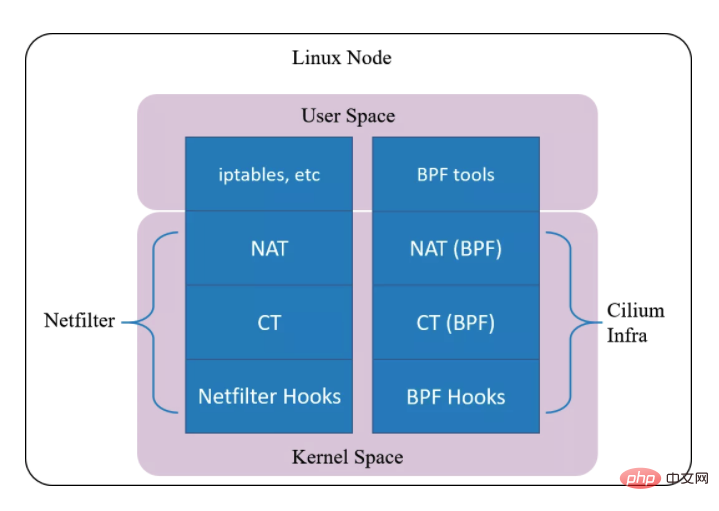
Implémenter une fonction d'interception de paquets basée sur le hook BPF (équivalent au mécanisme de hook dans netfilter) Basé sur le hook BPF, implémenter un nouvel ensemble de conntrack et NAT Par conséquent, même si Netfilter est désinstallé, cela n'affectera pas la prise en charge par Cilium de fonctions telles que Kubernetes ClusterIP, NodePort, ExternalIPs et LoadBalancer. Étant donné que ce mécanisme de suivi des connexions est indépendant de Netfilter, ses informations de connexion et NAT ne sont pas stockées dans la table de connexion et la table NAT du noyau (c'est-à-dire Netfilter).Par conséquent, conntrack/netstats/ss/lsof et d'autres outils ne peuvent pas être vus. Vous devez utiliser les commandes Cilium, telles que :
$ cilium bpf nat list$ cilium bpf ct list global
Iptables
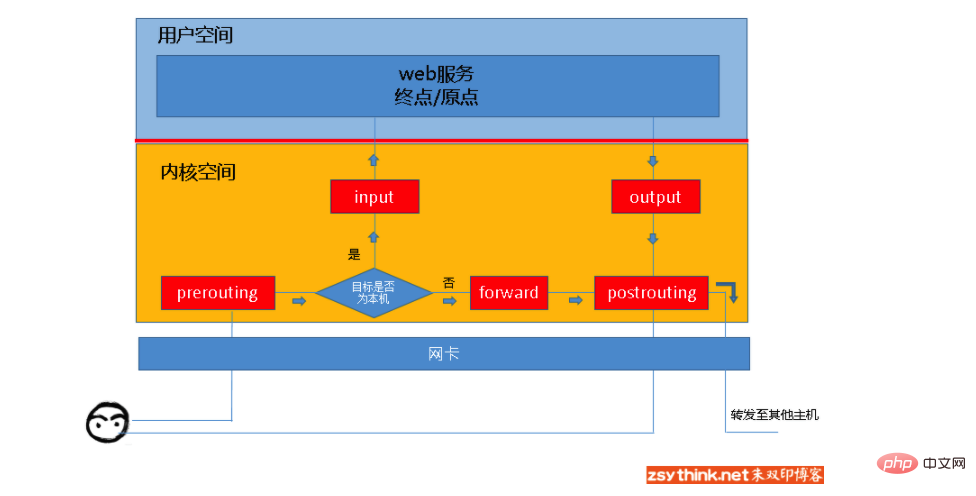
table de filtrage : utilisée pour filtrer les paquets de données. Les exigences de règles spécifiques déterminent comment traiter un paquet de données. Table nat : Principalement utilisée pour modifier les informations sur l'adresse IP et le numéro de port des paquets de données. table mangle : principalement utilisée pour modifier le type de service et le cycle de vie des paquets de données, définir des balises pour les paquets de données, mettre en œuvre la mise en forme du trafic, le routage des politiques, etc. table brute : principalement utilisée pour décider d'effectuer ou non un suivi de l'état des paquets de données.
chaîne d'entrée : Lorsqu'un paquet accédant à l'adresse locale est reçu, les règles de cette chaîne seront appliquées. chaîne de sortie : lorsque la machine envoie un paquet, les règles de cette chaîne seront appliquées. chaîne de transfert : lors de la réception d'un paquet de données qui doit être transféré vers d'autres adresses, les règles de cette chaîne seront appliquées. Notez que si vous devez implémenter le transfert de données, vous devez activer la fonction ip_forward dans. le noyau Linux. chaîne de préroutage : Les règles de cette chaîne seront appliquées avant le routage du paquet. chaîne de postroutage : Après avoir acheminé le paquet, les règles de cette chaîne seront appliquées.
Messages destinés à un certain processus sur la machine locale : PREROUTING –> Messages transmis par cette machine : PREROUTING –> FORWARD –> Un message (généralement un message de réponse) envoyé par un processus sur la machine locale : OUTPUT –>
Règles de requête
-t : Nom de la table -n : Ne pas résoudre Adresse IP -v : Affichera les informations du compteur, le nombre et la taille des paquets -x : L'option indique d'afficher la valeur exacte du compteur --line-numbers : Le numéro de série de la règle d'affichage (en abrégé --line) De plus, lors de la recherche du compte public Linux, c'est ainsi que vous devez apprendre à répondre "singe" dans le fond et recevez un paquet cadeau surprise. -L:链名
#iptables -t filter -nvxL DOCKER --lineChain DOCKER (1 references)num pkts bytes target prot opt in out source destination1 5076 321478 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.2 tcp dpt:84432 37233 54082508 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.2 tcp dpt:223 1712 255195 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.3 tcp dpt:90004 0 0 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.3 tcp dpt:80005 40224 6343104 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.4 tcp dpt:34436 21034 2227009 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.5 tcp dpt:33067 58 5459 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.6 tcp dpt:808 826 70081 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.6 tcp dpt:4439 10306905 1063612492 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.9 tcp dpt:330610 159775 12297727 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.7 tcp dpt:11111
增加规则
命令语法:iptables -t 表名 -A 链名 匹配条件 -j 动作示例:iptables -t filter -A INPUT -s 192.168.1.146 -j DROP
命令语法:iptables -t 表名 -I 链名 匹配条件 -j 动作示例:iptables -t filter -I INPUT -s 192.168.1.146 -j ACCEPT
命令语法:iptables -t 表名 -I 链名 规则序号 匹配条件 -j 动作示例:iptables -t filter -I INPUT 5 -s 192.168.1.146 -j REJECT
删除规则
命令语法:iptables -t 表名 -D 链名 规则序号示例:iptables -t filter -D INPUT 3
命令语法:iptables -t 表名 -D 链名 匹配条件 -j 动作示例:iptables -t filter -D INPUT -s 192.168.1.146 -j DROP
命令语法:iptables -t 表名 -F 链名示例:iptables -t filter -F INPUT
修改规则
命令语法:iptables -t 表名 -R 链名 规则序号 规则原本的匹配条件 -j 动作示例:iptables -t filter -R INPUT 3 -s 192.168.1.146 -j ACCEPT
命令语法:iptables -t 表名 -P 链名 动作示例:iptables -t filter -P FORWARD ACCEPT
保存规则
方式一
service iptables save
#配置好yum源以后安装iptables-serviceyum install -y iptables-services#停止firewalldsystemctl stop firewalld#禁止firewalld自动启动systemctl disable firewalld#启动iptablessystemctl start iptables#将iptables设置为开机自动启动,以后即可通过iptables-service控制iptables服务systemctl enable iptables
方式二
iptables-save > /etc/sysconfig/iptables
加载规则
iptables-restore < /etc/sysconfig/iptables
匹配条件
#示例如下iptables -t filter -I INPUT -s 192.168.1.111,192.168.1.118 -j DROPiptables -t filter -I INPUT -s 192.168.1.0/24 -j ACCEPTiptables -t filter -I INPUT ! -s 192.168.1.0/24 -j ACCEPT
#示例如下iptables -t filter -I OUTPUT -d 192.168.1.111,192.168.1.118 -j DROPiptables -t filter -I INPUT -d 192.168.1.0/24 -j ACCEPTiptables -t filter -I INPUT ! -d 192.168.1.0/24 -j ACCEPT
#示例如下iptables -t filter -I INPUT -p tcp -s 192.168.1.146 -j ACCEPTiptables -t filter -I INPUT ! -p udp -s 192.168.1.146 -j ACCEPT
#示例如下iptables -t filter -I INPUT -p icmp -i eth4 -j DROPiptables -t filter -I INPUT -p icmp ! -i eth4 -j DROP
#示例如下iptables -t filter -I OUTPUT -p icmp -o eth4 -j DROPiptables -t filter -I OUTPUT -p icmp ! -o eth4 -j DROP
扩展匹配条件
tcp扩展模块
–sport:用于匹配 tcp 协议报文的源端口,可以使用冒号指定一个连续的端口范围。 –dport:用于匹配 tcp 协议报文的目标端口,可以使用冒号指定一个连续的端口范围。 –tcp-flags:用于匹配报文的tcp头的标志位。 –syn:用于匹配 tcp 新建连接的请求报文,相当于使用 <span style="outline: 0px;font-size: 17px;">–tcp-flags SYN,RST,ACK,FIN SYN</span>。
#示例如下iptables -t filter -I OUTPUT -d 192.168.1.146 -p tcp -m tcp --sport 22 -j REJECTiptables -t filter -I INPUT -s 192.168.1.146 -p tcp -m tcp --dport 22:25 -j REJECTiptables -t filter -I INPUT -s 192.168.1.146 -p tcp -m tcp --dport :22 -j REJECTiptables -t filter -I INPUT -s 192.168.1.146 -p tcp -m tcp --dport 80: -j REJECTiptables -t filter -I OUTPUT -d 192.168.1.146 -p tcp -m tcp ! --sport 22 -j ACCEPTiptables -t filter -I INPUT -p tcp -m tcp --dport 22 --tcp-flags SYN,ACK,FIN,RST,URG,PSH SYN -j REJECTiptables -t filter -I OUTPUT -p tcp -m tcp --sport 22 --tcp-flags SYN,ACK,FIN,RST,URG,PSH SYN,ACK -j REJECTiptables -t filter -I INPUT -p tcp -m tcp --dport 22 --tcp-flags ALL SYN -j REJECTiptables -t filter -I OUTPUT -p tcp -m tcp --sport 22 --tcp-flags ALL SYN,ACK -j REJECTiptables -t filter -I INPUT -p tcp -m tcp --dport 22 --syn -j REJECT
udp 扩展模块
–sport:匹配udp报文的源地址。 –dport:匹配udp报文的目标地址。
#示例iptables -t filter -I INPUT -p udp -m udp --dport 137 -j ACCEPTiptables -t filter -I INPUT -p udp -m udp --dport 137:157 -j ACCEPT
icmp 扩展模块
–icmp-type:匹配icmp报文的具体类型。
#示例iptables -t filter -I INPUT -p icmp -m icmp --icmp-type 8/0 -j REJECTiptables -t filter -I INPUT -p icmp --icmp-type 8 -j REJECTiptables -t filter -I OUTPUT -p icmp -m icmp --icmp-type 0/0 -j REJECTiptables -t filter -I OUTPUT -p icmp --icmp-type 0 -j REJECTiptables -t filter -I INPUT -p icmp --icmp-type "echo-request" -j REJECT
multiport 扩展模块
-p tcp -m multiport –sports 用于匹配报文的源端口,可以指定离散的多个端口号,端口之间用”逗号”隔开。 -p udp -m multiport –dports 用于匹配报文的目标端口,可以指定离散的多个端口号,端口之间用”逗号”隔开。
#示例如下iptables -t filter -I OUTPUT -d 192.168.1.146 -p udp -m multiport --sports 137,138 -j REJECTiptables -t filter -I INPUT -s 192.168.1.146 -p tcp -m multiport --dports 22,80 -j REJECTiptables -t filter -I INPUT -s 192.168.1.146 -p tcp -m multiport ! --dports 22,80 -j REJECTiptables -t filter -I INPUT -s 192.168.1.146 -p tcp -m multiport --dports 80:88 -j REJECTiptables -t filter -I INPUT -s 192.168.1.146 -p tcp -m multiport --dports 22,80:88 -j REJECT
iprange 模块
–src-range:指定连续的源地址范围。 –dst-range:指定连续的目标地址范围。
#示例iptables -t filter -I INPUT -m iprange --src-range 192.168.1.127-192.168.1.146 -j DROPiptables -t filter -I OUTPUT -m iprange --dst-range 192.168.1.127-192.168.1.146 -j DROPiptables -t filter -I INPUT -m iprange ! --src-range 192.168.1.127-192.168.1.146 -j DROP
牛逼啊!接私活必备的 N 个开源项目!赶快收藏
string 模块
–algo:指定对应的匹配算法,可用算法为bm、kmp,此选项为必需选项。 –string:指定需要匹配的字符串
#示例 iptables -t filter -I INPUT -m string --algo bm --string "OOXX" -j REJECT
time 模块
–timestart:用于指定时间范围的开始时间,不可取反。 –timestop:用于指定时间范围的结束时间,不可取反。 –weekdays:用于指定”星期几”,可取反。 –monthdays:用于指定”几号”,可取反。 –datestart:用于指定日期范围的开始日期,不可取反。 –datestop:用于指定日期范围的结束时间,不可取反。
#示例 iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --timestart 09:00:00 --timestop 19:00:00 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 443 -m time --timestart 09:00:00 --timestop 19:00:00 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --weekdays 6,7 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --monthdays 22,23 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time ! --monthdays 22,23 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --timestart 09:00:00 --timestop 18:00:00 --weekdays 6,7 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --weekdays 5 --monthdays 22,23,24,25,26,27,28 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --datestart 2017-12-24 --datestop 2017-12-27 -j REJECT
connlimit 模块
–connlimit-above:单独使用此选项时,表示限制每个IP的链接数量。 –connlimit-mask:此选项不能单独使用,在使用–connlimit-above选项时,配合此选项,则可以针对”某类IP段内的一定数量的IP”进行连接数量的限制,如果不明白可以参考上文的详细解释。
#示例 iptables -I INPUT -p tcp --dport 22 -m connlimit --connlimit-above 2 -j REJECT iptables -I INPUT -p tcp --dport 22 -m connlimit --connlimit-above 20 --connlimit-mask 24 -j REJECT iptables -I INPUT -p tcp --dport 22 -m connlimit --connlimit-above 10 --connlimit-mask 27 -j REJECT
limit 模块
–limit-burst:类比”令牌桶”算法,此选项用于指定令牌桶中令牌的最大数量。 –limit:类比”令牌桶”算法,此选项用于指定令牌桶中生成新令牌的频率,可用时间单位有second、minute 、hour、day。
#示例,注意,如下两条规则需配合使用 #令牌桶中最多能存放3个令牌,每分钟生成10个令牌(即6秒钟生成一个令牌)。 iptables -t filter -I INPUT -p icmp -m limit --limit-burst 3 --limit 10/minute -j ACCEPT #默认将icmp包丢弃 iptables -t filter -A INPUT -p icmp -j REJECT
state 扩展模块
NEW : Le premier paquet dans la connexion, l'état est NEW, nous On comprend que l'état du premier paquet de la nouvelle connexion est NEW. ESTABLISHED : Nous pouvons comprendre l'état du paquet après le NOUVEAU paquet d'état comme ESTABLISHED, indiquant que la connexion a été établie. RELATED : Littéralement compris, RELATED se traduit par relation, mais ce n'est toujours pas facile à comprendre. Donnons un exemple. Par exemple, dans le service FTP, le serveur FTP créera deux processus, un processus de commande et un processus de données. Le processus de commande est responsable de la transmission des commandes entre le serveur et le client (on peut comprendre ce processus de transmission comme un état dit de « connexion », temporairement appelé « connexion de commande »). Le processus de données est responsable de la transmission des données entre le serveur et le client (nous appelons temporairement ce processus « connexion de données »). Cependant, les données spécifiques à transmettre sont contrôlées par la commande. Par conséquent, les messages dans la « connexion de données » sont « liés » à la « connexion de commande ». Ensuite, les paquets dans la « connexion de données » peuvent être dans l'état RELATED, car ces paquets sont liés aux paquets dans la « connexion de commande ». (Remarque : si vous souhaitez effectuer un suivi de connexion pour FTP, vous devez charger le module de noyau correspondant nf_conntrack_ftp séparément. Si vous souhaitez le charger automatiquement, vous pouvez configurer le fichier /etc/sysconfig/iptables-config) -
INVALIDE : si un paquet n'a aucun moyen de l'identifier, ou si le paquet n'a aucun statut, alors le statut de ce paquet est INVALIDE. Nous pouvons bloquer activement les paquets avec le statut INVALIDE. UNTRACKED : lorsque l'état du paquet est non suivi, cela signifie que le paquet n'a pas été suivi. Lorsque l'état du paquet est non suivi, cela signifie généralement que la connexion correspondante est introuvable.
iptables -t filter -I INPUT -m state --state ESTABLISHED -j ACCEPT
mangle 表
TOS:用来设置或改变数据包的服务类型域。这常用来设置网络上的数据包如何被路由等策略。注意这个操作并不完善,有时得不所愿。它在Internet 上还不能使用,而且很多路由器不会注意到这个域值。换句话说,不要设置发往 Internet 的包,除非你打算依靠 TOS 来路由,比如用 iproute2。 TTL:用来改变数据包的生存时间域,我们可以让所有数据包只有一个特殊的 TTL。它的存在有 一个很好的理由,那就是我们可以欺骗一些ISP。为什么要欺骗他们呢?因为他们不愿意让我们共享一个连接。那些 ISP 会查找一台单独的计算机是否使用不同的 TTL,并且以此作为判断连接是否被共享的标志。 MARK 用来给包设置特殊的标记。iproute 2能识别这些标记,并根据不同的标记(或没有标记) 决定不同的路由。用这些标记我们可以做带宽限制和基于请求的分类。
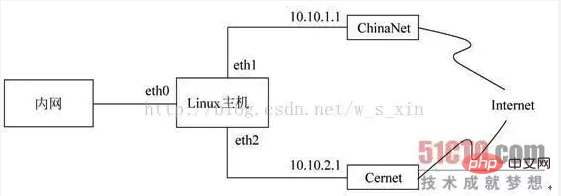
iptables -t mangle -A PREROUTING -i eth0 -p tcp --dport 80 -j MARK --set-mark 1; iptables -t mangle -A PREROUTING -i eth0 -p udp --dprot 53 -j MARK --set-mark 2;
ip rule add from all fwmark 1 table 10 ip rule add from all fwmark 2 table 20
ip route add default via 10.10.1.1 dev eth1 table 10 ip route add default via 10.10.2.1 dev eth2 table 20
Chaîne personnalisée
创建自定义链
#在filter表中创建IN_WEB自定义链 iptables -t filter -N IN_WEB
引用自定义链
#在INPUT链中引用刚才创建的自定义链 iptables -t filter -I INPUT -p tcp --dport 80 -j IN_WEB
重命名自定义链
#将IN_WEB自定义链重命名为WEB iptables -E IN_WEB WEB
删除自定义链
1、自定义链没有被引用。 2、自定义链中没有任何规则。
#第一步:清除自定义链中的规则 iptables -t filter -F WEB #第二步:删除自定义链 iptables -t filter -X WEB
LOG 动作
kern.warning /var/log/iptables.log
service rsyslog restart
–log-level 选项可以指定记录日志的日志级别,可用级别有 emerg,alert,crit,error,warning,notice,info,debug。 –log-prefix 选项可以给记录到的相关信息添加”标签”之类的信息,以便区分各种记录到的报文信息,方便在分析时进行过滤。–log-prefix 对应的值不能超过 29 个字符。
iptables -I INPUT -p tcp --dport 22 -m state --state NEW -j LOG --log-prefix "want-in-from-port-22"

参考链接
https://www.zsythink.net/archives/category/%e8%bf%90%e7%bb%b4%e7%9b%b8%e5%85%b3 /iptables/ https://my.oschina.net/mojiewhy/blog/3039897 https://www.frozentux.net/iptables-tutorial/cn/iptables-tutorial- cn-1.1.19.html#MARKTARGET https://mp.weixin.qq.com/s/NOxY4ZC7Cay4LCWlMkVx8A
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Entrée de la version Web Deepseek Entrée du site officiel Deepseek
Feb 19, 2025 pm 04:54 PM
Entrée de la version Web Deepseek Entrée du site officiel Deepseek
Feb 19, 2025 pm 04:54 PM
Deepseek est un puissant outil de recherche et d'analyse intelligent qui fournit deux méthodes d'accès: la version Web et le site officiel. La version Web est pratique et efficace et peut être utilisée sans installation; Que ce soit des individus ou des utilisateurs d'entreprise, ils peuvent facilement obtenir et analyser des données massives via Deepseek pour améliorer l'efficacité du travail, aider la prise de décision et promouvoir l'innovation.
 Comment installer Deepseek
Feb 19, 2025 pm 05:48 PM
Comment installer Deepseek
Feb 19, 2025 pm 05:48 PM
Il existe de nombreuses façons d'installer Deepseek, notamment: Compiler à partir de Source (pour les développeurs expérimentés) en utilisant des packages précompilés (pour les utilisateurs de Windows) à l'aide de conteneurs Docker (pour le plus pratique, pas besoin de s'inquiéter de la compatibilité), quelle que soit la méthode que vous choisissez, veuillez lire Les documents officiels documentent soigneusement et les préparent pleinement à éviter des problèmes inutiles.
 Comment résoudre le problème des autorisations rencontré lors de la visualisation de la version Python dans le terminal Linux?
Apr 01, 2025 pm 05:09 PM
Comment résoudre le problème des autorisations rencontré lors de la visualisation de la version Python dans le terminal Linux?
Apr 01, 2025 pm 05:09 PM
Solution aux problèmes d'autorisation Lors de la visualisation de la version Python dans Linux Terminal Lorsque vous essayez d'afficher la version Python dans Linux Terminal, entrez Python ...
 Installation officielle du site officiel de Bitget (Guide du débutant 2025)
Feb 21, 2025 pm 08:42 PM
Installation officielle du site officiel de Bitget (Guide du débutant 2025)
Feb 21, 2025 pm 08:42 PM
Bitget est un échange de crypto-monnaie qui fournit une variété de services de trading, notamment le trading au comptant, le trading de contrats et les dérivés. Fondée en 2018, l'échange est basée à Singapour et s'engage à fournir aux utilisateurs une plate-forme de trading sûre et fiable. Bitget propose une variété de paires de trading, notamment BTC / USDT, ETH / USDT et XRP / USDT. De plus, l'échange a une réputation de sécurité et de liquidité et offre une variété de fonctionnalités telles que les types de commandes premium, le trading à effet de levier et le support client 24/7.
 Obtenez le package d'installation Gate.io gratuitement
Feb 21, 2025 pm 08:21 PM
Obtenez le package d'installation Gate.io gratuitement
Feb 21, 2025 pm 08:21 PM
Gate.io est un échange de crypto-monnaie populaire que les utilisateurs peuvent utiliser en téléchargeant son package d'installation et en l'installant sur leurs appareils. Les étapes pour obtenir le package d'installation sont les suivantes: Visitez le site officiel de Gate.io, cliquez sur "Télécharger", sélectionnez le système d'exploitation correspondant (Windows, Mac ou Linux) et téléchargez le package d'installation sur votre ordinateur. Il est recommandé de désactiver temporairement les logiciels antivirus ou le pare-feu pendant l'installation pour assurer une installation fluide. Une fois terminé, l'utilisateur doit créer un compte Gate.io pour commencer à l'utiliser.
 Comment définir automatiquement les autorisations d'UnixSocket après le redémarrage du système?
Mar 31, 2025 pm 11:54 PM
Comment définir automatiquement les autorisations d'UnixSocket après le redémarrage du système?
Mar 31, 2025 pm 11:54 PM
Comment définir automatiquement les autorisations d'UnixSocket après le redémarrage du système. Chaque fois que le système redémarre, nous devons exécuter la commande suivante pour modifier les autorisations d'UnixSocket: sudo ...
 Le package d'installation OUYI OKX est directement inclus
Feb 21, 2025 pm 08:00 PM
Le package d'installation OUYI OKX est directement inclus
Feb 21, 2025 pm 08:00 PM
OUYI OKX, le premier échange mondial d'actifs numériques, a maintenant lancé un package d'installation officiel pour offrir une expérience de trading sûre et pratique. Le package d'installation OKX de OUYI n'a pas besoin d'être accessible via un navigateur. Le processus d'installation est simple et facile à comprendre.
 OUYI Exchange Télécharger le portail officiel
Feb 21, 2025 pm 07:51 PM
OUYI Exchange Télécharger le portail officiel
Feb 21, 2025 pm 07:51 PM
Ouyi, également connu sous le nom d'OKX, est une plate-forme de trading de crypto-monnaie de pointe. L'article fournit un portail de téléchargement pour le package d'installation officiel d'Ouyi, qui facilite les utilisateurs pour installer le client Ouyi sur différents appareils. Ce package d'installation prend en charge les systèmes Windows, Mac, Android et iOS. Une fois l'installation terminée, les utilisateurs peuvent s'inscrire ou se connecter au compte OUYI, commencer à négocier des crypto-monnaies et profiter d'autres services fournis par la plate-forme.
