
 Opération et maintenance
exploitation et maintenance Linux
Idées de dépannage d'exploitation et de maintenance Linux, cet article suffit ~
Opération et maintenance
exploitation et maintenance Linux
Idées de dépannage d'exploitation et de maintenance Linux, cet article suffit ~
Idées de dépannage d'exploitation et de maintenance Linux, cet article suffit ~
1. Contexte
Parfois, vous rencontrerez des maladies difficiles et compliquées, et le plug-in de surveillance ne peut pas trouver immédiatement la cause profonde du problème en un coup d'œil. À ce stade, vous devez vous connecter au serveur pour analyser plus en détail la cause première du problème. Ensuite, l'analyse des problèmes nécessite une certaine accumulation d'expérience technique, et certains problèmes impliquent des zones très vastes afin de localiser le problème. Par conséquent, analyser les problèmes et éviter les pièges est un excellent exercice pour la croissance et l’amélioration personnelle. Si nous disposons d'un bon ensemble d'outils d'analyse, nous obtiendrons deux fois plus de résultats avec moitié moins d'effort, aidant chacun à localiser rapidement les problèmes et permettant à chacun de gagner beaucoup de temps pour effectuer un travail plus approfondi.

2. Description
Cet article présente principalement divers outils de localisation de problèmes et analyse les problèmes en fonction des cas.
3. Méthodologie d'analyse des problèmes
À quoi ressemble le phénomène -
Quand-quand se produit-il Pourquoi-pourquoi c'est arrivé Où-où le problème s'est produit Combien de ressources ont été consommées -
Comment faire -comment résoudre le problème
4. cpu
4.1 Description
Pour les applications, nous nous concentrons généralement sur la fonction et les performances du planificateur du processeur du noyau.
L'analyse de l'état du thread analyse principalement où le temps du thread est utilisé, et la classification de l'état du thread est généralement divisée en :
sur le CPU : exécution, et le temps pendant l'exécution est généralement divisé en temps en mode utilisateur utilisateur et heure de l'état du système sys.
hors CPU : En attente du prochain cycle de CPU, ou en attente d'E/S, de verrouillage, de changement de page, etc. Son statut peut être subdivisé en exécutable, changement de page anonyme, veille, verrouillage, inactivité, etc. .
Processeur Core Hardware Threads -
CPU Memory Cache Horloge fréquence CPI et instructions par cycle IPC Instructions CPU Utilisation Temps utilisateur/temps noyau Planificateur -
Exécuter la file d'attente Préemption Multi-processus Multi-threading Longueur des mots
4.2 Outils d'analyse
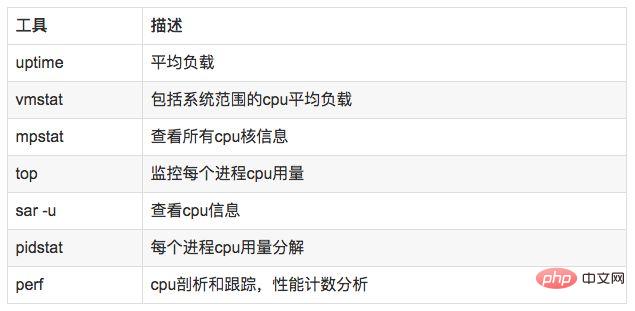
uptime, vmstat, mpstat, top, pidstat ne peuvent interroger que l'utilisation du processeur et la charge. perf peut suivre l'état chronophage de fonctions spécifiques au sein du processus, spécifier les fonctions du noyau pour les statistiques et les cibler en conséquence.
4.3 Comment utiliser
//查看系统cpu使用情况top //查看所有cpu核信息mpstat -P ALL 1 //查看cpu使用情况以及平均负载vmstat 1 //进程cpu的统计信息pidstat -u 1 -p pid //跟踪进程内部函数级cpu使用情况 perf top -p pid -e cpu-clock
5. Mémoire
5.1 Description
牛逼啊!接私活必备的 N 个开源项目!赶快收藏
主存 虚拟内存 常驻内存 地址空间 OOM 页缓存 缺页 换页 交换空间 交换 用户分配器libc、glibc、libmalloc和mtmalloc LINUX内核级SLUB分配器
5.2 分析工具
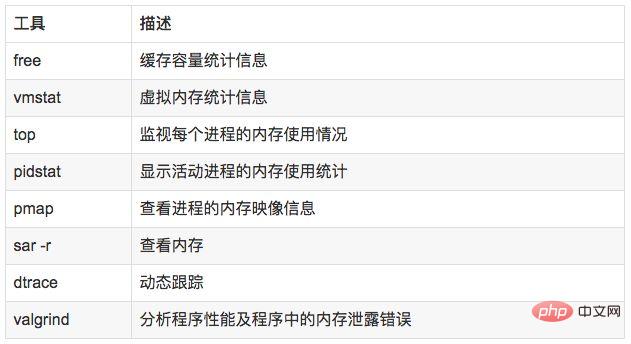
说明:
free,vmstat,top,pidstat,pmap只能统计内存信息以及进程的内存使用情况。
valgrind 可以分析内存泄漏问题。
dtrace 动态跟踪。需要对内核函数有很深入的了解,通过D语言编写脚本完成跟踪。
5.3 使用方式
//查看系统内存使用情况free -m//虚拟内存统计信息vmstat 1//查看系统内存情况top//1s采集周期,获取内存的统计信息pidstat -p pid -r 1//查看进程的内存映像信息pmap -d pid//检测程序内存问题valgrind --tool=memcheck --leak-check=full --log-file=./log.txt ./程序名
6. 磁盘IO
6.1 说明
在理解磁盘IO之前,同样我们需要理解一些概念,例如:
système de fichiers VFS cache du système de fichiers cache de page cache de page buffer cache buffer cache Cache de répertoire 6.2 Outils d'analyse 6.3 使用方式
//查看系统io信息iotop//统计io详细信息iostat -d -x -k 1 10//查看进程级io的信息pidstat -d 1 -p pid//查看系统IO的请求,比如可以在发现系统IO异常时,可以使用该命令进行调查,就能指定到底是什么原因导致的IO异常perf record -e block:block_rq_issue -ag^Cperf report
Copier après la connexion7. 网络
7.1 说明
网络的监测是所有 Linux 子系统里面最复杂的,有太多的因素在里面,比如:延迟、阻塞、冲突、丢包等,更糟的是与 Linux 主机相连的路由器、交换机、无线信号都会影响到整体网络并且很难判断是因为 Linux 网络子系统的问题还是别的设备的问题,增加了监测和判断的复杂度。现在我们使用的所有网卡都称为自适应网卡,意思是说能根据网络上的不同网络设备导致的不同网络速度和工作模式进行自动调整。 7.2 分析工具

7.3 使用方式
//显示网络统计信息netstat -s//显示当前UDP连接状况netstat -nu//显示UDP端口号的使用情况netstat -apu//统计机器中网络连接各个状态个数netstat -a | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'//显示TCP连接ss -t -a//显示sockets摘要信息ss -s//显示所有udp socketsss -u -a//tcp,etcp状态sar -n TCP,ETCP 1//查看网络IOsar -n DEV 1//抓包以包为单位进行输出tcpdump -i eth1 host 192.168.1.1 and port 80 //抓包以流为单位显示数据内容tcpflow -cp host 192.168.1.1Copier après la connexion8. 系统负载
8.1 说明
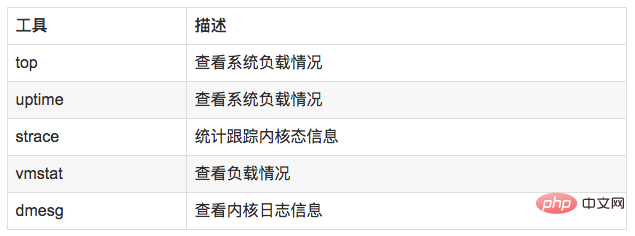
Load 就是对计算机干活多少的度量(WikiPedia:the system Load is a measure of the amount of work that a compute system is doing)简单的说是进程队列的长度。Load Average 就是一段时间(1分钟、5分钟、15分钟)内平均Load。 8.2 分析工具
8.3 使用方式
//查看负载情况uptimetopvmstat//统计系统调用耗时情况strace -c -p pid//跟踪指定的系统操作例如epoll_waitstrace -T -e epoll_wait -p pid//查看内核日志信息dmesg
Copier après la connexion9. 火焰图
9.1 说明
火焰图(Flame Graph是 Bredan Gregg 创建的一种性能分析图表,因为它的样子近似 ?而得名。 火焰图主要是用来展示 CPU的调用栈。 y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。 x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。 火焰图就是看顶层的哪个函数占据的宽度最大。只要有”平顶”(plateaus),就表示该函数可能存在性能问题。颜色没有特殊含义,因为火焰图表示的是 CPU 的繁忙程度,所以一般选择暖色调。 常见的火焰图类型有 On-CPU、Off-CPU、Memory、Hot/Cold、Differential等等。
9.2 安装依赖库
//安装systemtap,默认系统已安装yum install systemtap systemtap-runtime//内核调试库必须跟内核版本对应,例如:uname -r 2.6.18-308.el5kernel-debuginfo-2.6.18-308.el5.x86_64.rpmkernel-devel-2.6.18-308.el5.x86_64.rpmkernel-debuginfo-common-2.6.18-308.el5.x86_64.rpm//安装内核调试库debuginfo-install --enablerepo=debuginfo search kerneldebuginfo-install --enablerepo=debuginfo search glibc
Copier après la connexion9.3 安装
git clone https://github.com/lidaohang/quick_location.gitcd quick_location
Copier après la connexion9.4 CPU级别火焰图
cpu占用过高,或者使用率提不上来,你能快速定位到代码的哪块有问题吗?
一般的做法可能就是通过日志等方式去确定问题。现在我们有了火焰图,能够非常清晰的发现哪个函数占用cpu过高,或者过低导致的问题。另外,搜索公众号Linux就该这样学后台回复“猴子”,获取一份惊喜礼包。
9.4.1 on-CPU
cpu占用过高,执行中的时间通常又分为用户态时间user和系统态时间sys。 使用方式: //on-CPU usersh ngx_on_cpu_u.sh pid//进入结果目录 cd ngx_on_cpu_u//on-CPU kernelsh ngx_on_cpu_k.sh pid//进入结果目录 cd ngx_on_cpu_k//开一个临时端口 8088 python -m SimpleHTTPServer 8088//打开浏览器输入地址127.0.0.1:8088/pid.svg
Copier après la connexionDEMO:
Copier après la connexion#include <stdio.h>#include <stdlib.h> void foo3(){ } void foo2(){ int i; for(i=0 ; i < 10; i++) foo3();} void foo1(){ int i; for(i = 0; i< 1000; i++) foo3();} int main(void){ int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); }}Copier après la connexionDEMO火焰图:
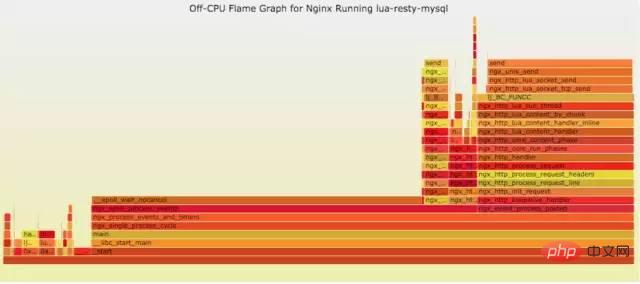
9.4.2 off-CPU
cpu过低,利用率不高。等待下一轮CPU,或者等待I/O、锁、换页等等,其状态可以细分为可执行、匿名换页、睡眠、锁、空闲等状态。
使用方式:
// off-CPU usersh ngx_off_cpu_u.sh pid//进入结果目录cd ngx_off_cpu_u//off-CPU kernelsh ngx_off_cpu_k.sh pid//进入结果目录cd ngx_off_cpu_k//开一个临时端口8088python -m SimpleHTTPServer 8088//打开浏览器输入地址127.0.0.1:8088/pid.svg
Copier après la connexion官网DEMO:
9.5 内存级别火焰图
如果线上程序出现了内存泄漏,并且只在特定的场景才会出现。这个时候我们怎么办呢?有什么好的方式和工具能快速的发现代码的问题呢?同样内存级别火焰图帮你快速分析问题的根源。
使用方式:
sh ngx_on_memory.sh pid//进入结果目录cd ngx_on_memory//开一个临时端口8088python -m SimpleHTTPServer 8088//打开浏览器输入地址127.0.0.1:8088/pid.svg
Copier après la connexion官网DEMO:
9.6 性能回退-红蓝差分火焰图
你能快速定位CPU性能回退的问题么?如果你的工作环境非常复杂且变化快速,那么使用现有的工具是来定位这类问题是很具有挑战性的。当你花掉数周时间把根因找到时,代码已经又变更了好几轮,新的性能问题又冒了出来。主要可以用到每次构建中,每次上线做对比看,如果损失严重可以立马解决修复。
通过抓取了两张普通的火焰图,然后进行对比,并对差异部分进行标色:红色表示上升,蓝色表示下降。差分火焰图是以当前(“修改后”)的profile文件作为基准,形状和大小都保持不变。因此你通过色彩的差异就能够很直观的找到差异部分,且可以看出为什么会有这样的差异。
使用方式:
cd quick_location//抓取代码修改前的profile 1文件perf record -F 99 -p pid -g -- sleep 30perf script > out.stacks1//抓取代码修改后的profile 2文件perf record -F 99 -p pid -g -- sleep 30perf script > out.stacks2//生成差分火焰图:./FlameGraph/stackcollapse-perf.pl ../out.stacks1 > out.folded1./FlameGraph/stackcollapse-perf.pl ../out.stacks2 > out.folded2./FlameGraph/difffolded.pl out.folded1 out.folded2 | ./FlameGraph/flamegraph.pl > diff2.svg
Copier après la connexionDEMO:
//test.c#include <stdio.h>#include <stdlib.h> void foo3(){ } void foo2(){ int i; for(i=0 ; i < 10; i++) foo3();} void foo1(){ int i; for(i = 0; i< 1000; i++) foo3();} int main(void){ int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); }} //test1.c#include <stdio.h>#include <stdlib.h> void foo3(){ } void foo2(){ int i; for(i=0 ; i < 10; i++) foo3();} void foo1(){ int i; for(i = 0; i< 1000; i++) foo3();} void add(){ int i; for(i = 0; i< 10000; i++) foo3();} int main(void){ int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); add(); }}Copier après la connexionDEMO红蓝差分火焰图:
10. Analyse de cas
10.1 Anomalies dans le cluster nginx au niveau de la couche d'accès
Il a été découvert grâce au plug-in de surveillance qu'un grand nombre de codes d'état 499 et 5xx sont apparus dans le trafic de requêtes du cluster nginx à 19h00. le 25 septembre 2017. Et il a été constaté que l’utilisation du processeur de la machine a augmenté, et cela continue. De plus, recherchez l'arrière-plan de l'algorithme principal du compte public et répondez « algorithme » pour obtenir un paquet cadeau surprise. 10.2 Analyser les indicateurs liés à nginx
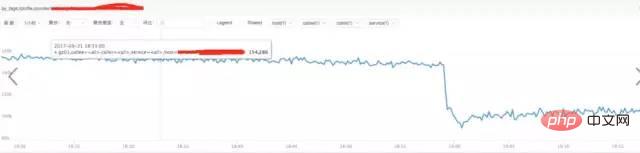
a) **Analyser le trafic des requêtes nginx :
Conclusion :
Grâce au chiffre ci-dessus, nous avons constaté que le trafic n'a pas augmenté soudainement, mais au lieu de cela diminué, suivez Peu importe s'il y a une augmentation soudaine du trafic de requêtes.
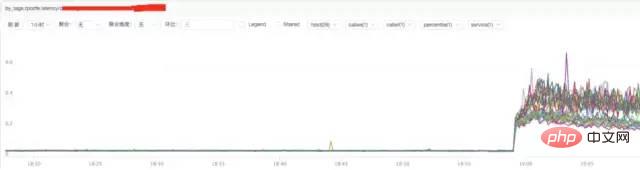
b) **Analyse du temps de réponse de nginx
Conclusion :
On peut constater à partir de la figure ci-dessus que l'augmentation du temps de réponse de nginx peut être liée à nginx lui-même ou au backend temps de réponse en amont.
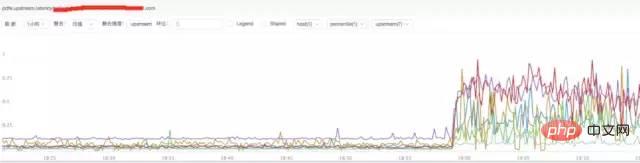
c) **Analyse du temps de réponse en amont de nginx
Conclusion :
Il ressort de la figure ci-dessus que le temps de réponse en amont de nginx a augmenté. Le temps de réponse du backend en amont peut retenir nginx, ce qui entraîne un trafic de requêtes anormal pour nginx.
10.3 Analyser la situation du processeur du système
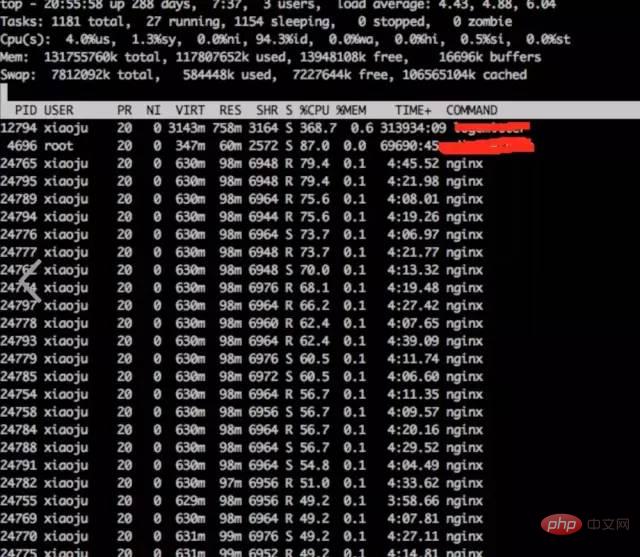
a) **Observer les indicateurs du système via top
toptop结论:
发现nginx worker cpu比较高
b) **分析nginx进程内部cpu情况
perf top -p pid🎜🎜🎜Conclusion :🎜🎜🎜🎜a constaté que le processeur du travailleur Nginx est relativement élevé🎜🎜🎜🎜 b) 🎜**🎜Analyser la situation interne du processeur du processus nginx🎜🎜🎜perf top -p pid🎜结论:
发现主要开销在free,malloc,json解析上面
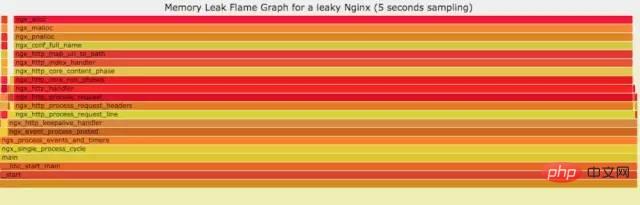
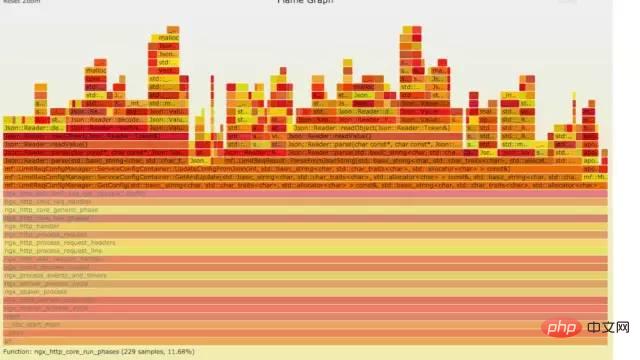
10.4 火焰图分析cpu
a) **生成用户态cpu火焰图//on-CPU usersh ngx_on_cpu_u.sh pid//进入结果目录cd ngx_on_cpu_u//开一个临时端口8088python -m SimpleHTTPServer 8088//打开浏览器输入地址127.0.0.1:8088/pid.svg
Copier après la connexion结论:
发现代码里面有频繁的解析json操作,并且发现这个json库性能不高,占用cpu挺高。
10.5 案例总结
a) 分析请求流量异常,得出nginx upstream后端机器响应时间拉长
b) En analysant le processeur élevé du processus nginx, il est conclu que le code du module interne nginx a des opérations fastidieuses d'analyse json, d'allocation de mémoire et de recyclage
10.5.1 Analyse approfondie
Conclusion basée sur l'analyse des deux points ci-dessus, nous analysons plus en profondeur.
La réponse en amont du backend est étendue, ce qui peut tout au plus affecter les capacités de traitement de nginx. Mais il est peu probable que cela affecte les modules internes de nginx qui nécessitent trop d'opérations CPU. Et les modules qui occupaient beaucoup de CPU à cette époque avaient une logique qui ne serait exécutée que sur demande. Il est peu probable que le backend amont retienne nginx, déclenchant ainsi cette opération fastidieuse du processeur.
10.5.2 Solution
Lorsque nous rencontrerons ce genre de problème, nous donnerons la priorité à la résolution de problèmes connus et très clairs. C'est le problème avec un processeur élevé. La solution est de rétrograder et de fermer le module qui consomme trop de CPU, puis d'observer. Après la mise à niveau et l'arrêt du module, le processeur a chuté et le trafic de requêtes nginx est devenu normal. La raison pour laquelle le temps en amont est allongé est que l'interface appelée par le service backend en amont peut être une boucle et revenir à nouveau à nginx.
11.参考资料
http://www.brendangregg.com/index.html
http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
-
http://www.brendangregg.com/FlameGraphs/memoryflamegraphs.html
http://www.brendangregg.com/FlameGraphs/offcpuflamegraphs.html
http://www.brendangregg. com/blog/2014-11-09/différential-flame-graphs.html
https://github.com/openresty/openresty-systemtap-toolkit
https://github. com/brendangregg/FlameGraph
https://www.slideshare.net/brendangregg/blazing-performance-with-flame-graphs



 🎜🎜🎜Conclusion :🎜🎜🎜🎜a constaté que le processeur du travailleur Nginx est relativement élevé🎜🎜🎜🎜 b) 🎜**🎜Analyser la situation interne du processeur du processus nginx🎜🎜🎜
🎜🎜🎜Conclusion :🎜🎜🎜🎜a constaté que le processeur du travailleur Nginx est relativement élevé🎜🎜🎜🎜 b) 🎜**🎜Analyser la situation interne du processeur du processus nginx🎜🎜🎜Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Les principales différences entre Centos et Ubuntu sont: l'origine (Centos provient de Red Hat, pour les entreprises; Ubuntu provient de Debian, pour les particuliers), la gestion des packages (Centos utilise Yum, se concentrant sur la stabilité; Ubuntu utilise APT, pour une fréquence de mise à jour élevée), le cycle de support (CentOS fournit 10 ans de soutien, Ubuntu fournit un large soutien de LT tutoriels et documents), utilisations (Centos est biaisé vers les serveurs, Ubuntu convient aux serveurs et aux ordinateurs de bureau), d'autres différences incluent la simplicité de l'installation (Centos est mince)
 Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
CentOS a été interrompu, les alternatives comprennent: 1. Rocky Linux (meilleure compatibilité); 2. Almalinux (compatible avec CentOS); 3. Serveur Ubuntu (configuration requise); 4. Red Hat Enterprise Linux (version commerciale, licence payante); 5. Oracle Linux (compatible avec Centos et Rhel). Lors de la migration, les considérations sont: la compatibilité, la disponibilité, le soutien, le coût et le soutien communautaire.
 Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Étapes d'installation de CentOS: Téléchargez l'image ISO et Burn Bootable Media; démarrer et sélectionner la source d'installation; sélectionnez la langue et la disposition du clavier; configurer le réseau; partitionner le disque dur; définir l'horloge système; créer l'utilisateur racine; sélectionnez le progiciel; démarrer l'installation; Redémarrez et démarrez à partir du disque dur une fois l'installation terminée.
 Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop? Docker Desktop est un outil pour exécuter des conteneurs Docker sur les machines locales. Les étapes à utiliser incluent: 1. Installer Docker Desktop; 2. Démarrer Docker Desktop; 3. Créer une image Docker (à l'aide de DockerFile); 4. Build Docker Image (en utilisant Docker Build); 5. Exécuter Docker Container (à l'aide de Docker Run).
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Vs Code Système Exigences: Système d'exploitation: Windows 10 et supérieur, MacOS 10.12 et supérieur, processeur de distribution Linux: minimum 1,6 GHz, recommandé 2,0 GHz et au-dessus de la mémoire: minimum 512 Mo, recommandée 4 Go et plus d'espace de stockage: Minimum 250 Mo, recommandée 1 Go et plus d'autres exigences: connexion du réseau stable, xorg / wayland (Linux) recommandé et recommandée et plus
 Comment afficher le processus Docker
Apr 15, 2025 am 11:48 AM
Comment afficher le processus Docker
Apr 15, 2025 am 11:48 AM
Méthode de visualisation du processus docker: 1. Commande Docker CLI: Docker PS; 2. Commande CLI Systemd: Docker d'état SystemCTL; 3. Docker Compose CLI Commande: Docker-Compose PS; 4. Process Explorer (Windows); 5. / Répertoire proc (Linux).
 Que faire si l'image Docker échoue
Apr 15, 2025 am 11:21 AM
Que faire si l'image Docker échoue
Apr 15, 2025 am 11:21 AM
Dépannage des étapes pour la construction d'image Docker échouée: cochez la syntaxe Dockerfile et la version de dépendance. Vérifiez si le contexte de construction contient le code source et les dépendances requis. Affichez le journal de construction pour les détails d'erreur. Utilisez l'option - cibler pour créer une phase hiérarchique pour identifier les points de défaillance. Assurez-vous d'utiliser la dernière version de Docker Engine. Créez l'image avec --t [Image-Name]: Debug Mode pour déboguer le problème. Vérifiez l'espace disque et assurez-vous qu'il est suffisant. Désactivez SELINUX pour éviter les interférences avec le processus de construction. Demandez de l'aide aux plateformes communautaires, fournissez Dockerfiles et créez des descriptions de journaux pour des suggestions plus spécifiques.
