

30 images détaillant le résumé du système d'exploitation !
1. Présentation
fonctionnalités de base
1. concurrence
La concurrence fait référence à la possibilité d'exécuter plusieurs programmes en même temps dans un sens macroscopique, tandis que le parallélisme fait référence au possibilité d'exécuter plusieurs programmes en même temps. Exécuter plusieurs instructions.
Le parallélisme nécessite un support matériel, tel que des processeurs multi-pipelines, multicœurs ou des systèmes informatiques distribués.
Le système d'exploitation permet aux programmes de s'exécuter simultanément en introduisant des processus et des threads.
2. Partage
Le partage signifie que les ressources du système peuvent être utilisées par plusieurs processus simultanés.
Il existe deux méthodes de partage : le partage mutuellement exclusif et le partage simultané.
Les ressources partagées mutuellement exclusives sont appelées ressources critiques, telles que les imprimantes, etc., un seul processus est autorisé à y accéder en même temps et un mécanisme de synchronisation est nécessaire pour obtenir un accès mutuellement exclusif.
3. Virtuel
La technologie virtuelle convertit une entité physique en plusieurs entités logiques.
Il existe principalement deux technologies virtuelles : la technologie de multiplexage par répartition temporelle (temporelle) et la technologie de multiplexage par répartition spatiale (espace).
Plusieurs processus peuvent être exécutés simultanément sur le même processeur à l'aide de la technologie de multiplexage temporel, permettant à chaque processus d'occuper le processeur à tour de rôle, en n'exécutant qu'une petite tranche de temps à chaque fois et en commutant rapidement.
La mémoire virtuelle utilise la technologie de multiplexage par répartition spatiale, qui résume la mémoire physique dans l'espace d'adressage, et chaque processus possède son propre espace d'adressage. Les pages de l'espace d'adressage sont mappées à la mémoire physique. Il n'est pas nécessaire que toutes les pages de l'espace d'adressage se trouvent dans la mémoire physique. Lorsqu'une page qui n'est pas dans la mémoire physique est utilisée, l'algorithme de remplacement de page est exécuté pour remplacer la page en mémoire.
4. Asynchrone
Asynchrone signifie que le processus n'est pas exécuté d'un seul coup, mais s'arrête et repart, avançant à une vitesse inconnue.
Fonctions de base
1. Gestion des processus
Contrôle des processus, synchronisation des processus, communication des processus, gestion des blocages, planification du processeur, etc.
2. Gestion de la mémoire
Allocation de mémoire, mappage d'adresses, protection et partage de mémoire, mémoire virtuelle, etc.
3. Gestion des fichiers
Gestion de l'espace de stockage des fichiers, gestion des répertoires, gestion et protection des fichiers en lecture et en écriture, etc.
4. Gestion des appareils
Complétez les demandes d'E/S des utilisateurs, facilitez l'utilisation de divers appareils et améliorez l'utilisation des appareils.
Comprend principalement la gestion des tampons, l'allocation des appareils, le traitement des appareils, les appareils virtuels, etc.
Appel système
Si un processus doit utiliser les fonctions d'état du noyau en mode utilisateur, il effectuera un appel système et tombera dans le noyau, et le système d'exploitation le complétera en son nom.
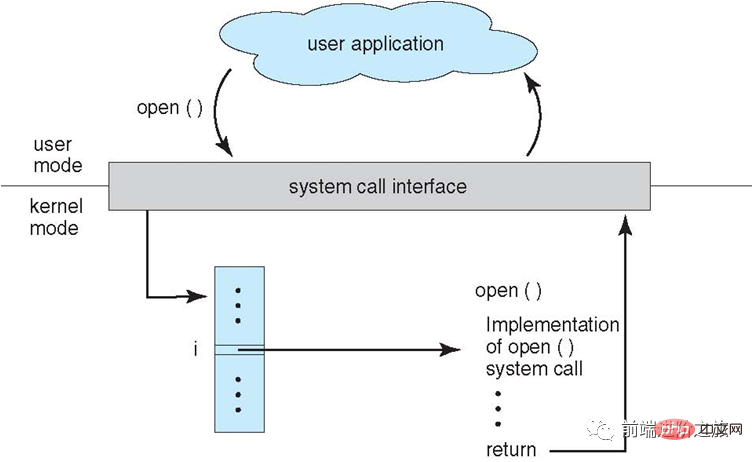
Les appels système de Linux incluent principalement les éléments suivants :

Grand noyau et micro-noyau
1. Grand noyau
Le grand noyau traite les fonctions du système d'exploitation comme un close L'ensemble combiné est mis dans le noyau.
Étant donné que chaque module partage des informations, il est très performant.
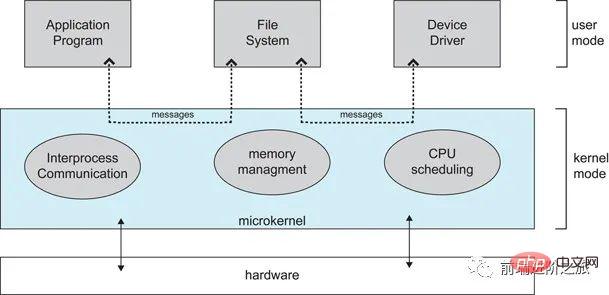
2. Micro-noyau
À mesure que les systèmes d'exploitation continuent de devenir de plus en plus complexes, certaines fonctions du système d'exploitation sont retirées du noyau, réduisant ainsi la complexité du noyau. La partie supprimée est divisée en plusieurs services selon le principe de stratification, indépendants les uns des autres.
Sous la structure du micro-noyau, le système d'exploitation est divisé en petits modules bien définis. Seul le module du micro-noyau s'exécute en mode noyau et les autres modules s'exécutent en mode utilisateur.
Étant donné que vous devez fréquemment basculer entre le mode utilisateur et le mode principal, il y aura une certaine perte de performances.
Classification des interruptions
1. L'interruption externe
est causée par des événements autres que les instructions d'exécution du processeur, telles qu'une interruption d'achèvement d'E/S, qui indique que le traitement d'entrée/sortie du périphérique a a été terminé et le processeur peut envoyer la demande d'entrée/sortie suivante. De plus, il existe des interruptions d'horloge, des interruptions de console, etc.

2. Les exceptions
sont causées par des événements internes lorsque le processeur exécute des instructions, tels que des opcodes illégaux, une adresse hors limites, un débordement arithmétique, etc.
3. Tomber dans
l'utilisation des appels système dans les programmes utilisateur.
2. Gestion des processus
Processus et fils de discussion
1. Processus
Le processus est l'unité de base de l'allocation des ressources.
Le bloc de contrôle de processus (PCB) décrit les informations de base et l'état d'exécution du processus. La création et l'annulation de processus font référence aux opérations sur le PCB.
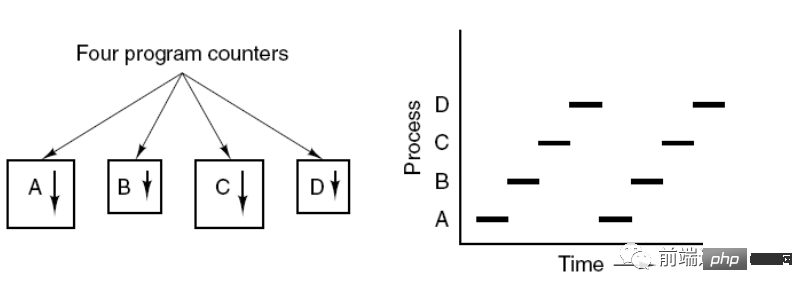
L'image ci-dessous montre que 4 programmes créent 4 processus, et ces 4 processus peuvent être exécutés simultanément.
2. Thread
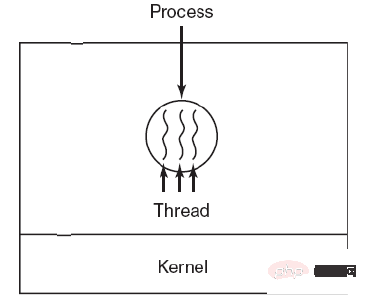
Thread est l'unité de base de la planification indépendante.
Il peut y avoir plusieurs threads dans un processus et ils partagent des ressources de processus.
QQ et le navigateur sont deux processus. Il existe de nombreux threads dans le processus du navigateur, tels que les threads de requête HTTP, les threads de réponse aux événements, les threads de rendu, etc. L'exécution simultanée des threads permet de cliquer sur un nouveau lien dans le navigateur pour lancer un Requête HTTP. Le navigateur peut également répondre à d'autres événements de l'utilisateur.
3. Différence
Ⅰ Posséder des ressources
Le processus est l'unité de base de l'allocation des ressources, mais les threads ne possèdent pas de ressources et les threads peuvent accéder aux ressources appartenant aux processus.
Ⅱ Planification
Le thread est l'unité de base de la planification indépendante. Dans le même processus, le changement de thread n'entraînera pas de changement de processus. Le passage d'un thread dans un processus à un thread dans un autre processus entraînera un changement de processus.
Ⅲ Frais généraux du système
Étant donné que lors de la création ou de l'annulation d'un processus, le système doit allouer ou recycler des ressources, telles que de l'espace mémoire, des périphériques d'E/S, etc., la surcharge encourue est bien supérieure à la surcharge lors de la création ou de l'annulation d'un thread. De même, lors du changement de processus, cela implique de sauvegarder l'environnement CPU du processus en cours d'exécution et de définir l'environnement CPU du nouveau processus planifié. Cependant, lors du changement de thread, seul un petit nombre de contenus de registre doit être enregistré et défini, ainsi que le changement de processus. les frais généraux sont très faibles.
Ⅳ En termes de communication
Les threads peuvent communiquer en lisant et en écrivant directement des données dans le même processus, mais la communication de processus nécessite l'aide de l'IPC.
Changement de l'état du processus
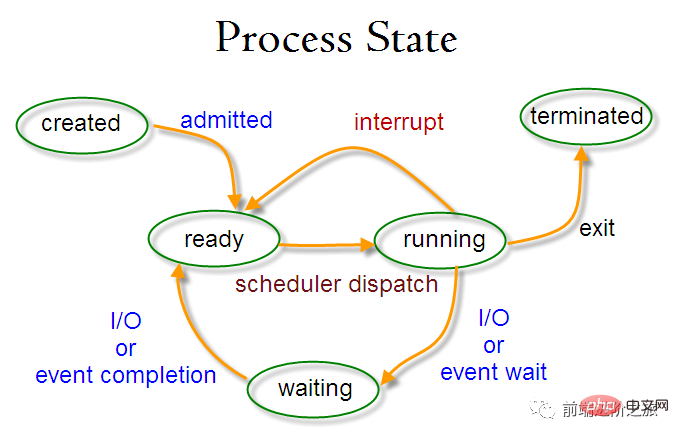
Statut prêt (prêt) : en attente d'être planifié
Statut en cours d'exécution (en cours d'exécution)
-
État de blocage (en attente) : Lorsque vous attendez des ressources
, vous devez faire attention aux points suivants :
Seuls l'état prêt et l'état en cours d'exécution peuvent être convertis l'un en l'autre, et les autres sont des conversions à sens unique. Le processus à l'état prêt obtient du temps CPU via l'algorithme de planification et passe à l'état d'exécution, tandis que le processus à l'état d'exécution passe à l'état prêt une fois la tranche de temps CPU qui lui est allouée est épuisée, en attendant la prochaine planification ; .
L'état de blocage est le manque de ressources requises et est converti de l'état d'exécution, mais cette ressource n'inclut pas le temps CPU. Le manque de temps CPU sera converti de l'état d'exécution à l'état prêt.
Algorithme de planification de processus
Les algorithmes de planification dans différents environnements ont des objectifs différents, les algorithmes de planification doivent donc être discutés pour différents environnements.
1. Système de traitement par lots
Le système de traitement par lots n'a pas trop d'opérations utilisateur dans ce système, les objectifs de l'algorithme de planification sont d'assurer le débit et le délai d'exécution (délai entre la soumission et la résiliation).
1.1 Premier arrivé, premier serveur (FCFS)
Un algorithme de planification non préemptif qui planifie dans l'ordre des requêtes.
C'est bon pour les travaux longs, mais pas pour les travaux courts, car les travaux courts doivent attendre que les travaux longs précédents soient terminés avant de pouvoir être exécutés, et les travaux longs doivent être exécutés pendant une longue période, ce qui entraîne des travaux courts. des emplois qui attendent trop longtemps.
1.2 Le travail le plus court en premier (SJF)
Un algorithme de planification non préemptif qui planifie dans l'ordre de la durée d'exécution estimée la plus courte.
Les travaux longs peuvent mourir de faim et sont dans l'attente que les travaux courts soient terminés. Car s’il y a toujours des tâches courtes à venir, alors les tâches longues ne seront jamais programmées.
1.3 Temps restant le plus court ensuite (SRTN)
Une version préemptive du travail le plus court en premier, planifié dans l'ordre du temps d'exécution restant. Lorsqu'une nouvelle tâche arrive, sa durée d'exécution totale est comparée au temps restant du processus en cours. Si le nouveau processus nécessite moins de temps, le processus en cours est suspendu et le nouveau processus est exécuté. Sinon, le nouveau processus attend.
2. Système interactif
Les systèmes interactifs ont un grand nombre d'interactions utilisateur, et le but de l'algorithme de planification de ce système est de répondre rapidement.
2.1 Rotation des tranches de temps
Organisez tous les processus prêts dans une file d'attente selon le principe FCFS. Chaque fois que cela est planifié, allouez du temps CPU au processus leader de la file d'attente, qui peut exécuter une tranche de temps. Lorsque la tranche de temps est écoulée, une interruption d'horloge est émise par le temporisateur, et le planificateur arrête l'exécution du processus et l'envoie à la fin de la file d'attente prête, tout en continuant à allouer du temps CPU au processus en tête de file. file d'attente.
L'efficacité de l'algorithme de rotation des tranches de temps est étroitement liée à la taille de la tranche de temps :
Parce que la commutation de processus doit enregistrer les informations de processus et charger les nouvelles informations de processus, si la tranche de temps est trop petite, cela entraînera un changement de processus. Trop souvent et trop de temps seront consacrés à changer de processus.
Et si la tranche de temps est trop longue, les performances en temps réel ne peuvent pas être garanties.
2.2 Planification des priorités
Attribuez une priorité à chaque processus et planifiez-le en fonction de la priorité.
Afin d'éviter que les processus peu prioritaires n'attendent jamais la planification, vous pouvez augmenter la priorité des processus en attente au fil du temps.
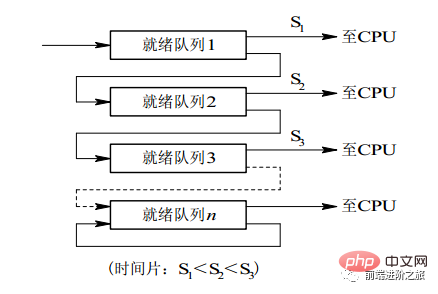
2.3 File d'attente de commentaires à plusieurs niveaux
Un processus doit exécuter 100 tranches de temps Si l'algorithme de planification de rotation des tranches de temps est utilisé, 100 échanges sont nécessaires.
Les files d'attente à plusieurs niveaux sont prises en compte pour les processus qui doivent exécuter plusieurs tranches de temps en continu. Elles configurent plusieurs files d'attente, et chaque file d'attente a une taille de tranche de temps différente, telle que 1,2,4,8,... Si le processus ne termine pas son exécution dans la première file d’attente, il sera déplacé vers la file d’attente suivante. De cette façon, le processus précédent ne doit être permuté que 7 fois.
Chaque file d'attente a une priorité différente, et celle en haut a la priorité la plus élevée. Par conséquent, le processus dans la file d'attente actuelle ne peut être planifié que s'il n'y a aucun processus dans la file d'attente précédente.
Cet algorithme de planification peut être considéré comme une combinaison de l'algorithme de planification de rotation de tranche de temps et de l'algorithme de planification prioritaire.
3. Système en temps réel
Un système en temps réel nécessite qu'une demande reçoive une réponse dans un certain délai.
牛逼啊!接私活必备的 N 个开源项目!赶快收藏吧...
est divisé en temps réel dur et temps réel doux, le premier doit respecter le délai absolu et le second peut tolérer un certain délai.
Synchronisation des processus
1. Section critique
Le code qui accède aux ressources critiques est appelé section critique.
Afin d'exclure mutuellement l'accès aux ressources critiques, chaque processus doit être vérifié avant d'entrer dans la section critique.
// entry section // critical section; // exit section
2. Synchronisation et exclusion mutuelle
Synchronisation : plusieurs processus ont une certaine relation d'exécution séquentielle en raison de la relation de restriction directe causée par la coopération.
Exclusion mutuelle : un seul processus parmi plusieurs processus peut entrer dans la section critique en même temps.
3. Sémaphore
信号量(Semaphore)是一个整型变量,可以对其执行 down 和 up 操作,也就是常见的 P 和 V 操作。
down : 如果信号量大于 0 ,执行 -1 操作;如果信号量等于 0,进程睡眠,等待信号量大于 0;
up :对信号量执行 +1 操作,唤醒睡眠的进程让其完成 down 操作。
down 和 up 操作需要被设计成原语,不可分割,通常的做法是在执行这些操作的时候屏蔽中断。
如果信号量的取值只能为 0 或者 1,那么就成为了 互斥量(Mutex) ,0 表示临界区已经加锁,1 表示临界区解锁。
typedef int semaphore;
semaphore mutex = 1;
void P1() {
down(&mutex);
// 临界区
up(&mutex);
}
void P2() {
down(&mutex);
// 临界区
up(&mutex);
}使用信号量实现生产者-消费者问题
问题描述:使用一个缓冲区来保存物品,只有缓冲区没有满,生产者才可以放入物品;只有缓冲区不为空,消费者才可以拿走物品。
因为缓冲区属于临界资源,因此需要使用一个互斥量 mutex 来控制对缓冲区的互斥访问。
为了同步生产者和消费者的行为,需要记录缓冲区中物品的数量。数量可以使用信号量来进行统计,这里需要使用两个信号量:empty 记录空缓冲区的数量,full 记录满缓冲区的数量。其中,empty 信号量是在生产者进程中使用,当 empty 不为 0 时,生产者才可以放入物品;full 信号量是在消费者进程中使用,当 full 信号量不为 0 时,消费者才可以取走物品。
注意,不能先对缓冲区进行加锁,再测试信号量。也就是说,不能先执行 down(mutex) 再执行 down(empty)。如果这么做了,那么可能会出现这种情况:生产者对缓冲区加锁后,执行 down(empty) 操作,发现 empty = 0,此时生产者睡眠。消费者不能进入临界区,因为生产者对缓冲区加锁了,消费者就无法执行 up(empty) 操作,empty 永远都为 0,导致生产者永远等待下,不会释放锁,消费者因此也会永远等待下去。
#define N 100
typedef int semaphore;
semaphore mutex = 1;
semaphore empty = N;
semaphore full = 0;
void producer() {
while(TRUE) {
int item = produce_item();
down(&empty);
down(&mutex);
insert_item(item);
up(&mutex);
up(&full);
}
}
void consumer() {
while(TRUE) {
down(&full);
down(&mutex);
int item = remove_item();
consume_item(item);
up(&mutex);
up(&empty);
}
}4. 管程
使用信号量机制实现的生产者消费者问题需要客户端代码做很多控制,而管程把控制的代码独立出来,不仅不容易出错,也使得客户端代码调用更容易。
c 语言不支持管程,下面的示例代码使用了类 Pascal 语言来描述管程。示例代码的管程提供了 insert() 和 remove() 方法,客户端代码通过调用这两个方法来解决生产者-消费者问题。
monitor ProducerConsumer integer i; condition c; procedure insert(); begin // ... end; procedure remove(); begin // ... end; end monitor;
管程有一个重要特性:在一个时刻只能有一个进程使用管程。进程在无法继续执行的时候不能一直占用管程,否则其它进程永远不能使用管程。
管程引入了 条件变量 以及相关的操作:wait() 和 signal() 来实现同步操作。对条件变量执行 wait() 操作会导致调用进程阻塞,把管程让出来给另一个进程持有。signal() 操作用于唤醒被阻塞的进程。
使用管程实现生产者-消费者问题
// 管程 monitor ProducerConsumer condition full, empty; integer count := 0; condition c; procedure insert(item: integer); begin if count = N then wait(full); insert_item(item); count := count + 1; if count = 1 then signal(empty); end; function remove: integer; begin if count = 0 then wait(empty); remove = remove_item; count := count - 1; if count = N -1 then signal(full); end; end monitor; // 生产者客户端 procedure producer begin while true do begin item = produce_item; ProducerConsumer.insert(item); end end; // 消费者客户端 procedure consumer begin while true do begin item = ProducerConsumer.remove; consume_item(item); end end;
经典同步问题
生产者和消费者问题前面已经讨论过了。
1. 哲学家进餐问题
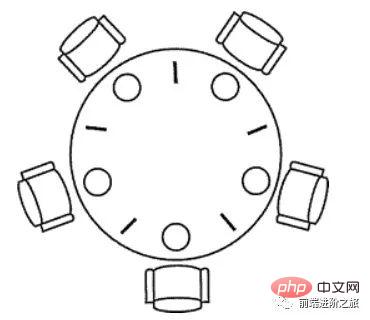
五个哲学家围着一张圆桌,每个哲学家面前放着食物。哲学家的生活有两种交替活动:吃饭以及思考。当一个哲学家吃饭时,需要先拿起自己左右两边的两根筷子,并且一次只能拿起一根筷子。
下面是一种错误的解法,如果所有哲学家同时拿起左手边的筷子,那么所有哲学家都在等待其它哲学家吃完并释放自己手中的筷子,导致死锁。
#define N 5
void philosopher(int i) {
while(TRUE) {
think();
take(i); // 拿起左边的筷子
take((i+1)%N); // 拿起右边的筷子
eat();
put(i);
put((i+1)%N);
}
}为了防止死锁的发生,可以设置两个条件:
必须同时拿起左右两根筷子;
只有在两个邻居都没有进餐的情况下才允许进餐。
#define N 5
#define LEFT (i + N - 1) % N // 左邻居
#define RIGHT (i + 1) % N // 右邻居
#define THINKING 0
#define HUNGRY 1
#define EATING 2
typedef int semaphore;
int state[N]; // 跟踪每个哲学家的状态
semaphore mutex = 1; // 临界区的互斥,临界区是 state 数组,对其修改需要互斥
semaphore s[N]; // 每个哲学家一个信号量
void philosopher(int i) {
while(TRUE) {
think(i);
take_two(i);
eat(i);
put_two(i);
}
}
void take_two(int i) {
down(&mutex);
state[i] = HUNGRY;
check(i);
up(&mutex);
down(&s[i]); // 只有收到通知之后才可以开始吃,否则会一直等下去
}
void put_two(i) {
down(&mutex);
state[i] = THINKING;
check(LEFT); // 尝试通知左右邻居,自己吃完了,你们可以开始吃了
check(RIGHT);
up(&mutex);
}
void eat(int i) {
down(&mutex);
state[i] = EATING;
up(&mutex);
}
// 检查两个邻居是否都没有用餐,如果是的话,就 up(&s[i]),使得 down(&s[i]) 能够得到通知并继续执行
void check(i) {
if(state[i] == HUNGRY && state[LEFT] != EATING && state[RIGHT] !=EATING) {
state[i] = EATING;
up(&s[i]);
}
}2. 读者-写者问题
允许多个进程同时对数据进行读操作,但是不允许读和写以及写和写操作同时发生。另外,搜索公众号顶级算法后台回复“算法”,获取一份惊喜礼包。
一个整型变量 count 记录在对数据进行读操作的进程数量,一个互斥量 count_mutex 用于对 count 加锁,一个互斥量 data_mutex 用于对读写的数据加锁。
typedef int semaphore;
semaphore count_mutex = 1;
semaphore data_mutex = 1;
int count = 0;
void reader() {
while(TRUE) {
down(&count_mutex);
count++;
if(count == 1) down(&data_mutex); // 第一个读者需要对数据进行加锁,防止写进程访问
up(&count_mutex);
read();
down(&count_mutex);
count--;
if(count == 0) up(&data_mutex);
up(&count_mutex);
}
}
void writer() {
while(TRUE) {
down(&data_mutex);
write();
up(&data_mutex);
}
}以下内容由 @Bandi Yugandhar 提供。
The first case may result Writer to starve. This case favous Writers i.e no writer, once added to the queue, shall be kept waiting longer than absolutely necessary(only when there are readers that entered the queue before the writer).
int readcount, writecount; //(initial value = 0)
semaphore rmutex, wmutex, readLock, resource; //(initial value = 1)
//READER
void reader() {
<ENTRY Section>
down(&readLock); // reader is trying to enter
down(&rmutex); // lock to increase readcount
readcount++;
if (readcount == 1)
down(&resource); //if you are the first reader then lock the resource
up(&rmutex); //release for other readers
up(&readLock); //Done with trying to access the resource
<CRITICAL Section>
//reading is performed
<EXIT Section>
down(&rmutex); //reserve exit section - avoids race condition with readers
readcount--; //indicate you're leaving
if (readcount == 0) //checks if you are last reader leaving
up(&resource); //if last, you must release the locked resource
up(&rmutex); //release exit section for other readers
}
//WRITER
void writer() {
<ENTRY Section>
down(&wmutex); //reserve entry section for writers - avoids race conditions
writecount++; //report yourself as a writer entering
if (writecount == 1) //checks if you're first writer
down(&readLock); //if you're first, then you must lock the readers out. Prevent them from trying to enter CS
up(&wmutex); //release entry section
<CRITICAL Section>
down(&resource); //reserve the resource for yourself - prevents other writers from simultaneously editing the shared resource
//writing is performed
up(&resource); //release file
<EXIT Section>
down(&wmutex); //reserve exit section
writecount--; //indicate you're leaving
if (writecount == 0) //checks if you're the last writer
up(&readLock); //if you're last writer, you must unlock the readers. Allows them to try enter CS for reading
up(&wmutex); //release exit section
}We can observe that every reader is forced to acquire ReadLock. On the otherhand, writers doesn’t need to lock individually. Once the first writer locks the ReadLock, it will be released only when there is no writer left in the queue.
From the both cases we observed that either reader or writer has to starve. Below solutionadds the constraint that no thread shall be allowed to starve; that is, the operation of obtaining a lock on the shared data will always terminate in a bounded amount of time.
int readCount; // init to 0; number of readers currently accessing resource
// all semaphores initialised to 1
Semaphore resourceAccess; // controls access (read/write) to the resource
Semaphore readCountAccess; // for syncing changes to shared variable readCount
Semaphore serviceQueue; // FAIRNESS: preserves ordering of requests (signaling must be FIFO)
void writer()
{
down(&serviceQueue); // wait in line to be servicexs
// <ENTER>
down(&resourceAccess); // request exclusive access to resource
// </ENTER>
up(&serviceQueue); // let next in line be serviced
// <WRITE>
writeResource(); // writing is performed
// </WRITE>
// <EXIT>
up(&resourceAccess); // release resource access for next reader/writer
// </EXIT>
}
void reader()
{
down(&serviceQueue); // wait in line to be serviced
down(&readCountAccess); // request exclusive access to readCount
// <ENTER>
if (readCount == 0) // if there are no readers already reading:
down(&resourceAccess); // request resource access for readers (writers blocked)
readCount++; // update count of active readers
// </ENTER>
up(&serviceQueue); // let next in line be serviced
up(&readCountAccess); // release access to readCount
// <READ>
readResource(); // reading is performed
// </READ>
down(&readCountAccess); // request exclusive access to readCount
// <EXIT>
readCount--; // update count of active readers
if (readCount == 0) // if there are no readers left:
up(&resourceAccess); // release resource access for all
// </EXIT>
up(&readCountAccess); // release access to readCount
}进程通信
进程同步与进程通信很容易混淆,它们的区别在于:
进程同步:控制多个进程按一定顺序执行;
进程通信:进程间传输信息。
进程通信是一种手段,而进程同步是一种目的。也可以说,为了能够达到进程同步的目的,需要让进程进行通信,传输一些进程同步所需要的信息。
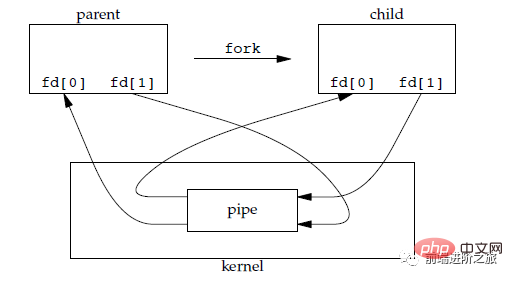
1. 管道
管道是通过调用 pipe 函数创建的,fd[0] 用于读,fd[1] 用于写。
#include <unistd.h> int pipe(int fd[2]);
它具有以下限制:
只支持半双工通信(单向交替传输);
只能在父子进程或者兄弟进程中使用。
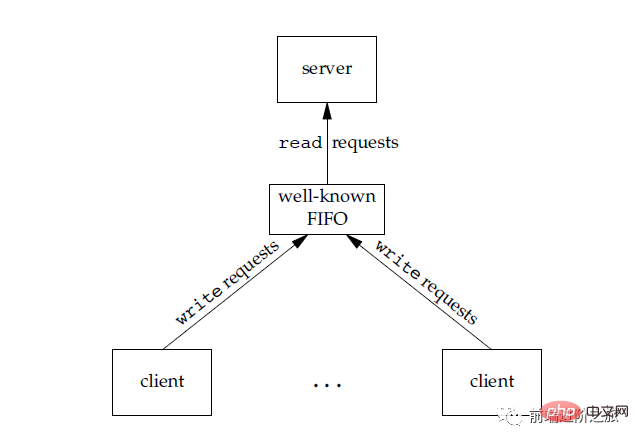
2. FIFO
也称为命名管道,去除了管道只能在父子进程中使用的限制。
#include <sys/stat.h> int mkfifo(const char *path, mode_t mode); int mkfifoat(int fd, const char *path, mode_t mode);
FIFO 常用于客户-服务器应用程序中,FIFO 用作汇聚点,在客户进程和服务器进程之间传递数据。
3. File d'attente des messages
Par rapport au FIFO, la file d'attente des messages présente les avantages suivants :
La file d'attente des messages peut exister indépendamment des processus de lecture et d'écriture, évitant ainsi l'ouverture et la fermeture de la synchronisation. tuyaux en FIFO Difficultés possibles lors de la fermeture
évite le problème de blocage de synchronisation du FIFO et ne nécessite pas que le processus fournisse lui-même les méthodes de synchronisation
Le processus de lecture peut recevoir sélectivement des messages en fonction du message ; type, contrairement au FIFO, ne peut recevoir que par défaut.
4. Sémaphore
C'est un compteur utilisé pour fournir à plusieurs processus un accès aux objets de données partagés.
5. Le stockage partagé
permet à plusieurs processus de partager une zone de stockage donnée. Étant donné que les données n'ont pas besoin d'être copiées entre les processus, il s'agit du type d'IPC le plus rapide.
Vous devez utiliser un sémaphore pour synchroniser l'accès au stockage partagé.
Plusieurs processus peuvent mapper le même fichier dans leur espace d'adressage pour obtenir une mémoire partagée. De plus, la mémoire partagée XSI n'utilise pas de fichiers, mais utilise des segments de mémoire anonymes.
6. Prise
Contrairement à d'autres mécanismes de communication, il peut être utilisé pour la communication de processus entre différentes machines.
3. Gestion de la mémoire
Mémoire virtuelle
Le but de la mémoire virtuelle est d'étendre la mémoire physique en une mémoire logique plus grande, afin que le programme puisse obtenir plus de mémoire disponible.
Afin de mieux gérer la mémoire, le système d'exploitation abstrait la mémoire dans un espace d'adressage. Chaque programme possède son propre espace d'adressage, divisé en plusieurs blocs, chaque bloc étant appelé une page. Les pages sont mappées dans la mémoire physique, mais il n'est pas nécessaire de les mapper dans une mémoire physique contiguë, et il n'est pas non plus nécessaire que toutes les pages se trouvent dans la mémoire physique. Lorsqu'un programme fait référence à une page qui ne se trouve pas dans la mémoire physique, le matériel effectue le mappage nécessaire, charge la partie manquante dans la mémoire physique et réexécute l'instruction ayant échoué.
Comme le montre la description ci-dessus, la mémoire virtuelle permet au programme de ne pas mapper chaque page de l'espace d'adressage sur la mémoire physique, ce qui signifie qu'un programme n'a pas besoin d'être chargé dans la mémoire pour s'exécuter, ce qui rend le programme limité. mémoire Il est possible d'exécuter des programmes volumineux. Par exemple, si un ordinateur peut générer des adresses 16 bits, la plage d'espace d'adressage d'un programme est comprise entre 0 et 64 Ko. L'ordinateur ne dispose que de 32 Ko de mémoire physique et la technologie de mémoire virtuelle permet à l'ordinateur d'exécuter un programme de 64 Ko.
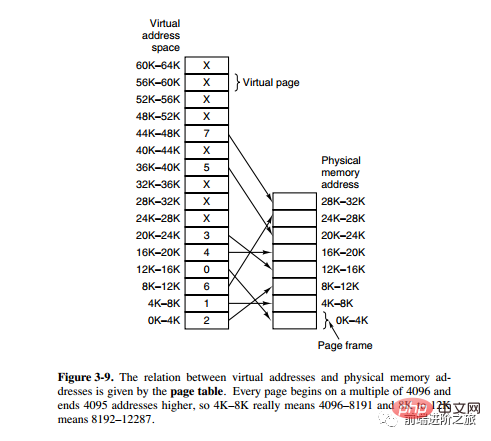
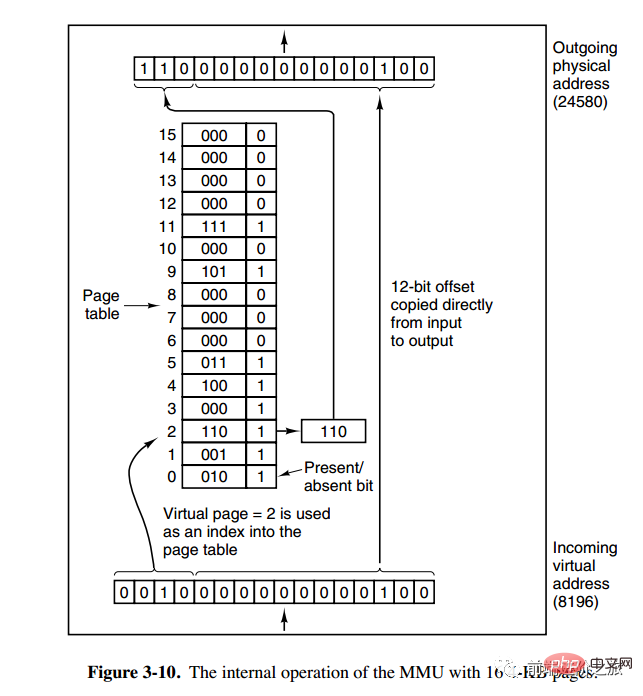
Mappage d'adresses du système de pagination
L'unité de gestion de la mémoire (MMU) gère la conversion de l'espace d'adressage et de la mémoire physique, et la table des pages (Table des pages) stocke les pages (espace d'adressage du programme) et les cadres de page (espace mémoire physique) table de mappage.
Une adresse virtuelle est divisée en deux parties, une partie stocke le numéro de page et l'autre partie stocke le décalage.
下图的页表存放着 16 个页,这 16 个页需要用 4 个比特位来进行索引定位。例如对于虚拟地址(0010 000000000100),前 4 位是存储页面号 2,读取表项内容为(110 1),页表项最后一位表示是否存在于内存中,1 表示存在。后 12 位存储偏移量。这个页对应的页框的地址为 (110 000000000100)。
页面置换算法
在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间。
页面置换算法和缓存淘汰策略类似,可以将内存看成磁盘的缓存。在缓存系统中,缓存的大小有限,当有新的缓存到达时,需要淘汰一部分已经存在的缓存,这样才有空间存放新的缓存数据。
页面置换算法的主要目标是使页面置换频率最低(也可以说缺页率最低)。
1. 最佳
OPT, Optimal replacement algorithm
所选择的被换出的页面将是最长时间内不再被访问,通常可以保证获得最低的缺页率。
是一种理论上的算法,因为无法知道一个页面多长时间不再被访问。
举例:一个系统为某进程分配了三个物理块,并有如下页面引用序列:
7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1
开始运行时,先将 7, 0, 1 三个页面装入内存。当进程要访问页面 2 时,产生缺页中断,会将页面 7 换出,因为页面 7 再次被访问的时间最长。
2. 最近最久未使用
LRU, Least Recently Used
虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU 将最近最久未使用的页面换出。
为了实现 LRU,需要在内存中维护一个所有页面的链表。当一个页面被访问时,将这个页面移到链表表头。这样就能保证链表表尾的页面是最近最久未访问的。
因为每次访问都需要更新链表,因此这种方式实现的 LRU 代价很高。
4,7,0,7,1,0,1,2,1,2,6
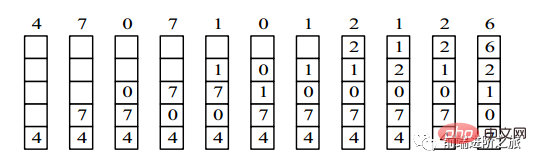
3. 最近未使用
NRU, Not Recently Used
每个页面都有两个状态位:R 与 M,当页面被访问时设置页面的 R=1,当页面被修改时设置 M=1。其中 R 位会定时被清零。可以将页面分成以下四类:
R=0,M=0 R=0,M=1 R=1,M=0 R=1,M=1
当发生缺页中断时,NRU 算法随机地从类编号最小的非空类中挑选一个页面将它换出。
NRU 优先换出已经被修改的脏页面(R=0,M=1),而不是被频繁使用的干净页面(R=1,M=0)。
4. Premier entré, premier sorti
FIFO, Premier entré, premier sorti
La page sélectionnée pour être échangée est la page saisie en premier.
Cet algorithme échangera les pages fréquemment consultées, ce qui entraînera une augmentation du taux de défauts de page.
5. Algorithme de la seconde chance
L'algorithme FIFO peut remplacer les pages fréquemment utilisées. Afin d'éviter ce problème, apportez une simple modification à l'algorithme :
Lorsque la page est consultée (lue ou écrite), définissez le paramètre. R bit de la page à 1. Lorsqu'un remplacement est nécessaire, vérifiez le bit R de la page la plus ancienne. Si le bit R est à 0, alors la page est ancienne et inutilisée et peut être remplacée immédiatement ; s'il est à 1, mettez le bit R à 0, mettez la page en fin de liste chaînée, et modifiez son temps de chargement pour que Il agit comme s'il venait d'être chargé et continue la recherche à partir du début de la liste.

6. Clock
Clock
L'algorithme de la deuxième chance doit déplacer les pages dans la liste chaînée, ce qui réduit l'efficacité. L'algorithme d'horloge utilise une liste chaînée circulaire pour connecter les pages, puis utilise un pointeur pour pointer vers la page la plus ancienne.
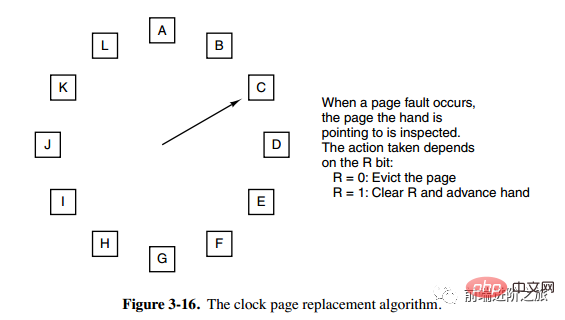
Segmentation
La mémoire virtuelle utilise la technologie de pagination, ce qui signifie que l'espace d'adressage est divisé en pages de taille fixe et que chaque page est mappée à la mémoire.
L'image ci-dessous montre plusieurs tables créées par un compilateur pendant le processus de compilation. Quatre des tables croissent dynamiquement. Si l'espace d'adressage unidimensionnel du système de pagination est utilisé, les caractéristiques de croissance dynamique entraîneront des problèmes de couverture.
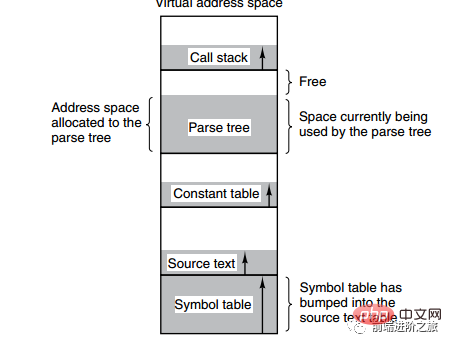
La méthode de segmentation consiste à diviser chaque table en segments, et chaque segment constitue un espace d'adressage indépendant. Chaque segment peut être de longueur différente et croître de manière dynamique.
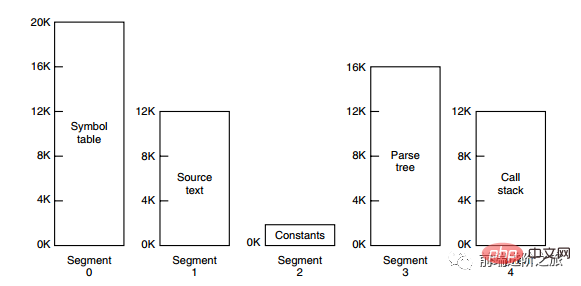
Pagination des segments
L'espace d'adressage du programme est divisé en plusieurs segments avec des espaces d'adressage indépendants, et l'espace d'adressage de chaque segment est divisé en pages de même taille. Cela permet non seulement le partage et la protection du système segmenté, mais également la fonction de mémoire virtuelle du système de radiomessagerie.
Comparaison de la pagination et de la segmentation
Transparence pour les programmeurs : la pagination est transparente, mais la segmentation nécessite que le programmeur divise explicitement chaque segment.
Dimensions de l'espace d'adressage : la pagination est un espace d'adressage unidimensionnel et la segmentation est bidimensionnelle.
Si la taille peut être modifiée : la taille de la page est immuable et la taille du segment peut être modifiée dynamiquement.
Raisons de l'apparition : la pagination est principalement utilisée pour implémenter la mémoire virtuelle afin d'obtenir un espace d'adressage plus grand ; la segmentation sert principalement à diviser les programmes et les données en espaces d'adressage logiquement indépendants et à faciliter le partage et la protection.
4. Gestion des périphériques
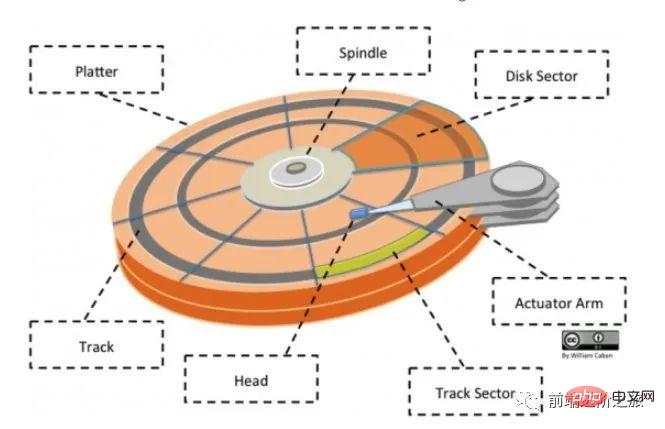
Structure du disque
Plateau : Un disque a plusieurs disques
Piste : Un cercle sur le disque Une zone de bande, un disque peut avoir plusieurs pistes ;
Track Sector : un segment d'arc sur une piste, une piste peut avoir plusieurs secteurs, c'est la plus petite unité de stockage physique, actuellement disponible principalement en deux tailles : 512 octets et 4 K ;
- Tête : très proche de la surface du disque, capable de convertir le champ magnétique à la surface du disque en signaux électriques (lecture), ou de convertir les signaux électriques en champ magnétique à la surface du disque (Écriture) ; en recherchant le compte public Linux, voici comment vous devez apprendre à répondre "Linux" en arrière-plan pour obtenir un paquet cadeau surprise.
- Bras d'actionneur : utilisé pour déplacer la tête magnétique entre les pistes
;
Broche : fait tourner tout le disque.
Algorithme de planification de disque
Les facteurs qui affectent le temps de lecture et d'écriture d'un bloc de disque sont :
Le temps de rotation (la broche fait tourner la surface du disque pour déplacer la tête au secteur approprié) )
Temps de recherche (mouvement du bras de freinage, faisant bouger la tête vers la piste appropriée)
Temps réel de transfert de données
Parmi eux, le temps de recherche est le le plus long, donc l'objectif principal de la planification du disque est de minimiser le temps moyen de recherche du disque.
1. Premier arrivé, premier servi
FCFS, Premier arrivé, premier servi
La planification est effectuée dans l'ordre des requêtes de disque.
Les avantages sont l'équité et la simplicité. L'inconvénient est également évident, car aucune optimisation n'a été effectuée pour la recherche, le temps de recherche moyen peut donc être plus long.
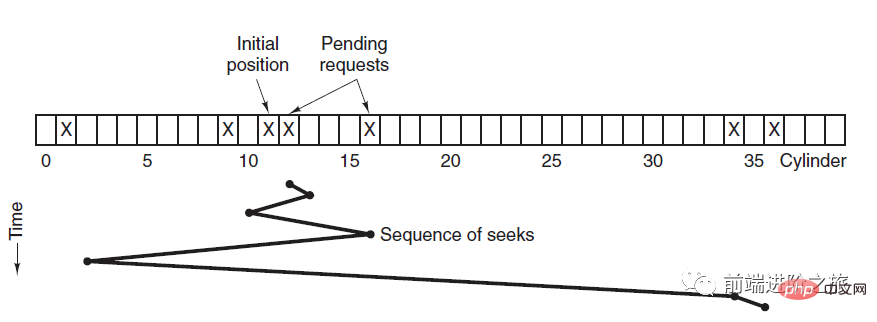
2. Temps de recherche le plus court en premier
SSTF, Temps de recherche le plus court en premier
donne la priorité à la planification de la piste la plus proche de la piste où se trouve la tête actuelle.
Bien que le temps de recherche moyen soit relativement faible, il n'est pas assez juste. Si une demande de suivi nouvellement arrivée est toujours plus proche qu'une demande de suivi en attente, alors la demande de suivi en attente attendra indéfiniment, c'est-à-dire qu'une famine se produit. Plus précisément, les demandes de suivi aux deux extrémités sont plus sujettes à l'échec. Regardez ce système de télécommande, il est tellement élégant (code source ci-joint) !
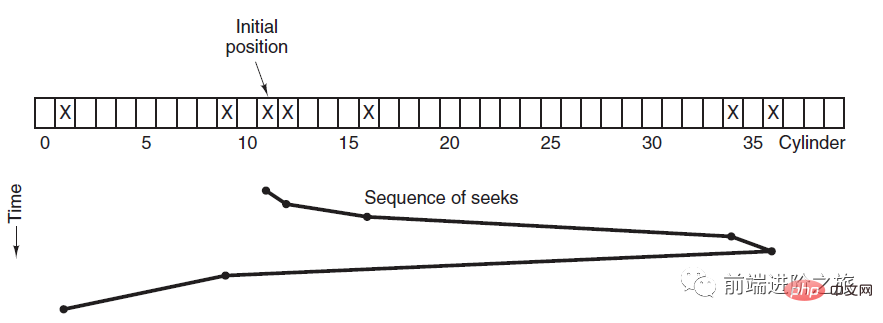
3. Algorithme de l'ascenseur
SCAN
L'ascenseur continue toujours de fonctionner dans une direction jusqu'à ce qu'il n'y ait aucune demande dans cette direction, puis change la direction de marche.
L'algorithme d'ascenseur (algorithme d'analyse) est similaire au processus de fonctionnement d'un ascenseur. Il planifie toujours les disques dans une direction jusqu'à ce qu'il n'y ait plus de demandes de disque en attente dans cette direction, puis change la direction.
Étant donné que la direction du mouvement est prise en compte, toutes les demandes de disque seront satisfaites, résolvant ainsi le problème de famine SSTF.
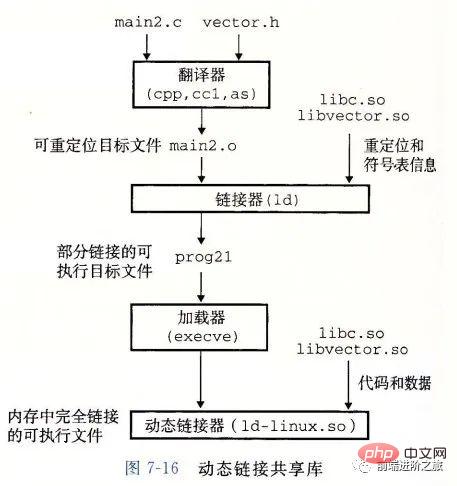
五、链接
编译系统
以下是一个 hello.c 程序:
#include <stdio.h>
int main()
{
printf("hello, world\n");
return 0;
}在 Unix 系统上,由编译器把源文件转换为目标文件。
gcc -o hello hello.c
这个过程大致如下:

预处理阶段:处理以 # 开头的预处理命令;
编译阶段:翻译成汇编文件;
汇编阶段:将汇编文件翻译成可重定位目标文件;
链接阶段:将可重定位目标文件和 printf.o 等单独预编译好的目标文件进行合并,得到最终的可执行目标文件。
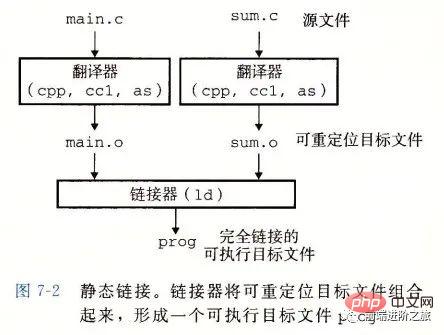
静态链接
静态链接器以一组可重定位目标文件为输入,生成一个完全链接的可执行目标文件作为输出。链接器主要完成以下两个任务:
Résolution de symbole : Chaque symbole correspond à une fonction, une variable globale ou une variable statique. Le but de la résolution de symbole est d'associer chaque référence de symbole à une définition de symbole.
Relocalisation : L'éditeur de liens associe chaque définition de symbole à un emplacement mémoire, puis modifie toutes les références à ces symboles pour qu'elles pointent vers cet emplacement mémoire.
Fichier cible
Fichier cible exécutable : peut être exécuté directement en mémoire
Fichier cible relocalisable : peut être combiné avec d'autres ; cibles relocalisables Les fichiers sont fusionnés pendant la phase de liaison pour créer un fichier objet exécutable ;
Fichier objet partagé : il s'agit d'un fichier objet spécial déplaçable qui peut être chargé dynamiquement en mémoire et lié au moment de l'exécution ; Les bibliothèques statiques rencontrent les deux problèmes suivants :
Lorsque la bibliothèque statique est mise à jour, l'ensemble du programme doit être reconnecté ;Pour les bibliothèques de fonctions standard comme printf, si chaque programme doit avoir du code, ce sera un énorme gaspillage de ressources.
Les bibliothèques partagées sont conçues pour résoudre ces deux problèmes des bibliothèques statiques. Elles sont généralement représentées par le suffixe .so sur les systèmes Linux et elles sont appelées DLL sur les systèmes Windows. Il présente les caractéristiques suivantes :
Il n'existe qu'un seul fichier pour une bibliothèque dans un système de fichiers donné. Ce fichier est partagé par tous les fichiers objets exécutables qui référencent la bibliothèque. Il ne sera pas copié dans les fichiers exécutables qui référencent. it. ;
En mémoire, une copie de la section .text d'une bibliothèque partagée (le code machine du programme compilé) peut être partagée par différents processus en cours d'exécution.
Pour les bibliothèques de fonctions standard comme printf, si chaque programme doit avoir du code, ce sera un énorme gaspillage de ressources.
Il n'existe qu'un seul fichier pour une bibliothèque dans un système de fichiers donné. Ce fichier est partagé par tous les fichiers objets exécutables qui référencent la bibliothèque. Il ne sera pas copié dans les fichiers exécutables qui référencent. it. ;
En mémoire, une copie de la section .text d'une bibliothèque partagée (le code machine du programme compilé) peut être partagée par différents processus en cours d'exécution.
6. Impasse
Conditions nécessaires
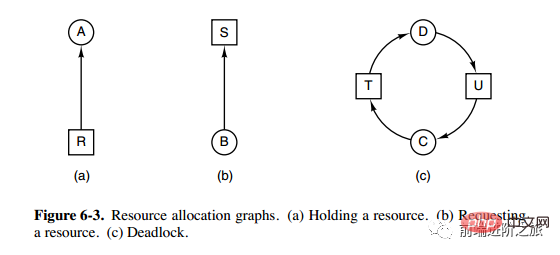
Exclusion mutuelle : Chaque ressource est soit déjà allouée à un processus, soit disponible.
Occuper et attendre : Un processus qui a déjà obtenu une ressource peut demander une nouvelle ressource.
Non préemptible : Une ressource qui a été allouée à un processus ne peut pas être préemptée de force, elle ne peut être explicitement libérée que par le processus qui l'occupe.
Boucle en attente : il y a deux processus ou plus formant une boucle, et chaque processus de la boucle attend les ressources occupées par le processus suivant.
Méthodes de traitement
Il existe principalement quatre méthodes :
Stratégie de l'autruche
Détection des blocages et récupération des blocages
Prévention des impasses
impasse Évitement
Stratégie de l'autruche
Enfouissez votre tête dans le sable et faites comme s'il n'y avait aucun problème.
Étant donné que le coût de la résolution du problème de l'impasse est très élevé, la stratégie de l'autruche, qui ne prend pas de mesures de tâches, permettra d'obtenir des performances plus élevées.
Lorsqu'un blocage se produit, cela n'aura pas beaucoup d'impact sur les utilisateurs, ou la probabilité d'un blocage est très faible, vous pouvez utiliser la stratégie de l'autruche.
La plupart des systèmes d'exploitation, notamment Unix, Linux et Windows, résolvent le problème de blocage simplement en l'ignorant.
Détection des blocages et récupération des blocages
n'essaie pas d'empêcher les blocages, mais prend des mesures pour récupérer lorsqu'un blocage est détecté.
1. Détection de blocage d'une ressource de chaque type
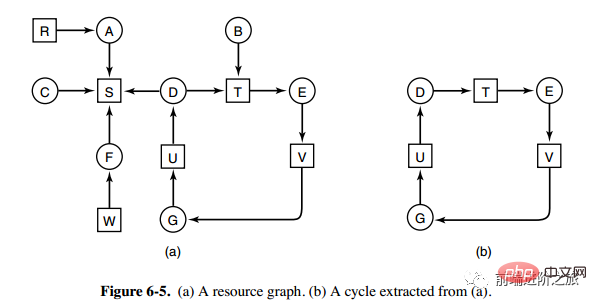
L'image ci-dessus est un diagramme d'allocation des ressources, où les cases représentent les ressources et les cercles représentent les processus. La ressource pointant vers le processus signifie que la ressource a été allouée au processus, et le processus pointant vers la ressource signifie que le processus demande à obtenir la ressource.
La boucle peut être extraite de la figure a, comme le montre la figure b, qui satisfait la condition d'attente de la boucle, donc une impasse se produira.
L'algorithme de détection de blocage pour chaque type de ressource est implémenté en détectant s'il existe un cycle dans le graphe orienté, en partant d'un nœud, en effectuant une recherche en profondeur d'abord et en marquant les nœuds visités si un nœud marqué est visité, Indique qu'il existe un cycle dans le graphique orienté, c'est-à-dire qu'un blocage est détecté.
2. Détection de blocage pour plusieurs ressources de chaque type

Dans l'image ci-dessus, il y a trois processus et quatre ressources. La signification de chaque donnée est la suivante :
Vecteur E : quantité totale de ressources
Vecteur : quantité restante de ressources.
-
Matrice C : Le nombre de ressources possédées par chaque processus. Chaque ligne représente le nombre de ressources possédées par un processus. Matrice R : Le nombre de ressources demandées par chaque processus Aucune. les ressources sont satisfaites. Seul le processus P3 peut laisser P3 s'exécuter puis libérer les ressources possédées par P3. A ce moment, A = (2 2 2 0). P2 peut être exécuté et les ressources possédées par P2 sont libérées après exécution, A = (4 2 2 1). P1 peut également être exécuté. Tous les processus s’exécutent sans problème, sans blocage.
L'algorithme est résumé comme suit : - Chaque processus n'est pas marqué au début, et le processus d'exécution peut être marqué. Lorsque l'algorithme se termine, tout processus qui n'est pas marqué est un processus bloqué.
Trouvez un processus Pi non marqué dont la ressource demandée est inférieure ou égale à A.
Si un tel processus est trouvé, ajoutez le i-ème vecteur de ligne de la matrice C à A, marquez le processus et revenez à 1.
3. Récupération de blocage
Utiliser la récupération par préemption
Utiliser la récupération par restauration
Récupérez en tuant le processus
Prévention des blocages
Prévenez les blocages avant l'exécution du programme.
1. Briser les conditions d'exclusion mutuelle
Par exemple, la technologie d'imprimante spool permet à plusieurs processus de produire en même temps, et le seul processus qui demande réellement une imprimante physique est le démon d'imprimante.
2. Destruction de possession et conditions d'attente
Une façon d'y parvenir est de préciser que tous les processus demandent toutes les ressources nécessaires avant de commencer leur exécution.
3. Détruisez la condition non préemptive
4. Détruisez la boucle en attente
Numérotez les ressources de manière uniforme et les processus ne peuvent demander des ressources que par ordre numérique.
Évitement des impasses
Évitez les impasses pendant l'exécution du programme.
1. Statut de sécurité
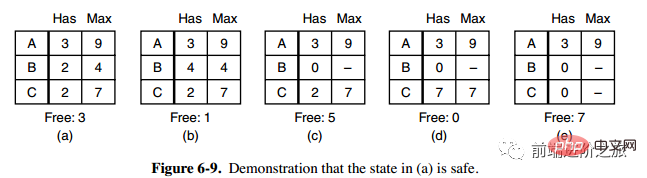
La deuxième colonne Has dans la figure a représente le nombre de ressources déjà possédées, la troisième colonne Max représente le nombre total de ressources requises et Free représente le nombre de ressources pouvant être utilisées. En partant de l'image a, laissez d'abord B disposer de toutes les ressources dont il a besoin (image b). Une fois l'opération terminée, relâchez B. A ce moment, Free devient 5 (image c) puis exécutez C et A de la même manière, afin que tous les processus puissent s'exécuter avec succès, de sorte que l'état illustré sur la figure a peut être considéré comme sûr.
Définition : Si aucune impasse ne se produit, et même si tous les processus demandent soudainement la demande maximale de ressources, il existe toujours un ordre de planification qui permet à chaque processus de s'exécuter jusqu'à son terme, alors l'état est dit sûr.
La détection d'un état sûr est similaire à la détection d'un blocage, car l'état sûr doit exiger qu'un blocage ne puisse pas se produire. L'algorithme du banquier suivant est très similaire à l'algorithme de détection de blocage et peut être combiné à des fins de référence et de comparaison.
2. Algorithme du banquier pour une ressource unique
Un banquier d'une petite ville a promis un certain montant à un groupe de clients. Ce que l'algorithme doit faire est de déterminer si la satisfaction de la demande entrera dans un état dangereux. . Si Si oui, rejetez la demande ; sinon attribuez-la.
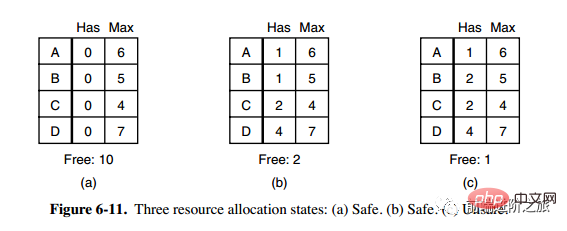
C dans la figure ci-dessus est un état dangereux, donc l'algorithme rejettera la demande précédente pour éviter d'entrer dans l'état de la figure c.
3. Algorithme bancaire pour ressources multiples
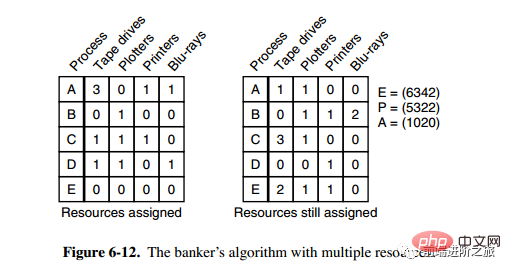
Il y a cinq processus et quatre ressources dans l'image ci-dessus. L'image de gauche représente les ressources qui ont été allouées et l'image de droite représente les ressources qui doivent encore être allouées. Les éléments E, P et A les plus à droite représentent respectivement : les ressources totales, les ressources allouées et les ressources disponibles. Notez que ces trois sont des vecteurs et non des valeurs spécifiques. Par exemple, A = (1020), ce qui signifie qu'il reste respectivement 1/4 des ressources. 0/2/0.
L'algorithme pour vérifier si un état est sûr est le suivant :
Trouvez s'il y a une ligne dans la matrice de droite qui est inférieure ou égale au vecteur A. Si aucune ligne de ce type n’existe, le système se bloquera et l’état sera dangereux.
Si une telle ligne est trouvée, marquez le processus comme terminé et ajoutez ses ressources allouées à A.
Répétez les deux étapes ci-dessus jusqu'à ce que tous les processus soient marqués comme terminés, le statut est alors sécurisé.
Si un État n'est pas sûr, vous devez refuser d'entrer dans cet État.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:36 PM
Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:36 PM
Pour créer une base de données Oracle, la méthode commune consiste à utiliser l'outil graphique DBCA. Les étapes sont les suivantes: 1. Utilisez l'outil DBCA pour définir le nom DBN pour spécifier le nom de la base de données; 2. Définissez Syspassword et SystemPassword sur des mots de passe forts; 3. Définir les caractères et NationalCharacterset à Al32Utf8; 4. Définissez la taille de mémoire et les espaces de table pour s'ajuster en fonction des besoins réels; 5. Spécifiez le chemin du fichier log. Les méthodes avancées sont créées manuellement à l'aide de commandes SQL, mais sont plus complexes et sujets aux erreurs. Faites attention à la force du mot de passe, à la sélection du jeu de caractères, à la taille et à la mémoire de l'espace de table
 Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Le réglage des performances de Zookeeper sur CentOS peut commencer à partir de plusieurs aspects, notamment la configuration du matériel, l'optimisation du système d'exploitation, le réglage des paramètres de configuration, la surveillance et la maintenance, etc. Assez de mémoire: allouez suffisamment de ressources de mémoire à Zookeeper pour éviter la lecture et l'écriture de disques fréquents. CPU multi-core: utilisez un processeur multi-core pour vous assurer que Zookeeper peut le traiter en parallèle.
 Comment Debian améliore la vitesse de traitement des données Hadoop
Apr 13, 2025 am 11:54 AM
Comment Debian améliore la vitesse de traitement des données Hadoop
Apr 13, 2025 am 11:54 AM
Cet article examine comment améliorer l'efficacité du traitement des données Hadoop sur les systèmes Debian. Les stratégies d'optimisation couvrent les mises à niveau matérielle, les ajustements des paramètres du système d'exploitation, les modifications de configuration de Hadoop et l'utilisation d'algorithmes et d'outils efficaces. 1. Le renforcement des ressources matérielles garantit que tous les nœuds ont des configurations matérielles cohérentes, en particulier en faisant attention aux performances du CPU, de la mémoire et de l'équipement réseau. Le choix des composants matériels de haute performance est essentiel pour améliorer la vitesse de traitement globale. 2. Réglage des paramètres JVM: Ajustez dans le fichier hadoop-env.sh
 À quoi sert Linux?
Apr 12, 2025 am 12:20 AM
À quoi sert Linux?
Apr 12, 2025 am 12:20 AM
Linux convient aux serveurs, aux environnements de développement et aux systèmes intégrés. 1. En tant que système d'exploitation de serveurs, Linux est stable et efficace, et est souvent utilisé pour déployer des applications à haute monnaie. 2. En tant qu'environnement de développement, Linux fournit des outils de ligne de commande efficaces et des systèmes de gestion des packages pour améliorer l'efficacité du développement. 3. Dans les systèmes intégrés, Linux est léger et personnalisable, adapté aux environnements avec des ressources limitées.
 Où est le service redémarré redis
Apr 10, 2025 pm 02:36 PM
Où est le service redémarré redis
Apr 10, 2025 pm 02:36 PM
Comment redémarrer le service Redis dans différents systèmes d'exploitation: Linux / MacOS: utilisez la commande SystemCTL (SystemCTL Restart Redis-Server) ou la commande Service (Service Redis-Server Restart). Windows: Utilisez l'outil Services.MSC (entrez "Services.MSC" dans la boîte de dialogue Exécuter et appuyez sur Entrée) et cliquez avec le bouton droit sur le service "Redis" et sélectionnez "Redémarrer".
 Dans quelle langue Apache est-elle écrite?
Apr 13, 2025 pm 12:42 PM
Dans quelle langue Apache est-elle écrite?
Apr 13, 2025 pm 12:42 PM
Apache est écrit en C. La langue offre la vitesse, la stabilité, la portabilité et l'accès direct au matériel, ce qui le rend idéal pour le développement du serveur Web.
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Qui a inventé le système Mac
Apr 12, 2025 pm 05:12 PM
Qui a inventé le système Mac
Apr 12, 2025 pm 05:12 PM
Le système d'exploitation MacOS a été inventé par Apple. Son prédécesseur, System Software, a été lancé en 1984. Après de nombreuses itérations, il a été mis à jour vers Mac OS X en 2001 et a changé son nom en macOS en 2012.