
 Opération et maintenance
exploitation et maintenance Linux
Mécanisme de mémoire Linux et libération manuelle du swap, du tampon et du cache
Opération et maintenance
exploitation et maintenance Linux
Mécanisme de mémoire Linux et libération manuelle du swap, du tampon et du cache
Mécanisme de mémoire Linux et libération manuelle du swap, du tampon et du cache
Cet article présente les principes et les opérations pratiques du mécanisme de mémoire Linux, de l'échange de mémoire virtuelle, de la libération de tampon/cache, etc.
1. Quel est le mécanisme de mémoire de Linux ?
2. Quand Linux a-t-il commencé à utiliser la mémoire virtuelle (swap) ?
3. Comment libérer de la mémoire ? 4. Comment libérer le swap ?
1. Quel est le mécanisme de mémoire de Linux ?
Nous savons que la lecture et l'écriture de données directement à partir de la mémoire physique sont beaucoup plus rapides que la lecture et l'écriture de données à partir du disque dur. Par conséquent, nous espérons que toutes les lectures et écritures de données seront effectuées en mémoire et que la mémoire sera limitée. conduit aux concepts de mémoire physique et de mémoire virtuelle.
La mémoire physique est la taille de la mémoire fournie par le matériel du système. Par rapport à la mémoire physique, il existe un concept de mémoire virtuelle sous Linux. La mémoire virtuelle est une stratégie proposée pour répondre au manque de mémoire physique. l'utilisation d'un morceau de mémoire logique virtualisé par l'espace disque. L'espace disque utilisé comme mémoire virtuelle est appelé espace d'échange.
En tant qu'extension de la mémoire physique, Linux utilisera la mémoire virtuelle de la partition de swap lorsque la mémoire physique est insuffisante. Plus précisément, le noyau écrira les informations du bloc de mémoire temporairement inutilisées dans l'espace de swap. la mémoire est libérée, cette mémoire peut être utilisée à d'autres fins. Lorsque le contenu original est nécessaire, les informations seront à nouveau lues de l'espace d'échange dans la mémoire physique.
La gestion de la mémoire de Linux adopte un mécanisme d'accès par pagination. Afin de garantir que la mémoire physique peut être pleinement utilisée, le noyau échangera automatiquement les blocs de données rarement utilisés dans la mémoire physique vers la mémoire virtuelle au moment approprié, tandis que les blocs de données fréquemment utilisés le seront. automatiquement échangées dans la mémoire virtuelle au moment approprié. Les informations utilisées sont conservées dans la mémoire physique.
Pour avoir une compréhension approfondie du mécanisme de fonctionnement de la mémoire Linux, vous devez connaître les aspects suivants :
Le système Linux effectuera des opérations d'échange de pages de temps en temps pour maintenir autant de mémoire physique libre que possible, même s'il n'y a rien. qui nécessite de la mémoire, Linux Les pages de mémoire temporairement inutilisées seront également remplacées. Cela évite le temps nécessaire à l’attente de l’échange.
L'échange de pages sous Linux est conditionnel. Toutes les pages ne sont pas échangées vers la mémoire virtuelle lorsqu'elles ne sont pas utilisées. Le noyau Linux échange uniquement certains fichiers de pages rarement utilisés vers la mémoire virtuelle en fonction de l'algorithme "le plus récemment utilisé". ce phénomène : Linux a encore beaucoup de mémoire physique, mais beaucoup d'espace de swap est également utilisé. En fait, cela n'est pas surprenant.Par exemple, lorsqu'un processus qui occupe beaucoup de mémoire doit consommer beaucoup de ressources mémoire lors de son exécution, certains fichiers d'échange inhabituels seront échangés dans la mémoire virtuelle, mais plus tard, ce processus qui occupe beaucoup Des ressources mémoire seront échangées. Lorsque le processus se termine et qu'une grande partie de la mémoire est libérée, le fichier d'échange qui vient d'être échangé ne sera pas automatiquement échangé dans la mémoire physique. À moins que cela ne soit nécessaire, la mémoire physique du système sera beaucoup plus libre. en ce moment, et l'espace d'échange est également utilisé. Le phénomène que nous venons de mentionner s'est produit. Il n’y a pas de quoi s’inquiéter à ce stade, tant que vous savez ce qui se passe.
Les pages de l'espace d'échange seront d'abord échangées vers la mémoire physique lors de leur utilisation. S'il n'y a pas assez de mémoire physique pour accueillir ces pages à ce moment-là, elles seront immédiatement échangées. Par conséquent, il se peut qu'il n'y ait pas assez d'espace. dans la mémoire virtuelle pour stocker Ces pages d'échange finiront par causer des problèmes tels que de faux plantages et des anomalies de service sous Linux. Bien que Linux puisse récupérer tout seul dans un certain laps de temps, le système récupéré est fondamentalement inutilisable.
Par conséquent, il est très important de planifier et de concevoir correctement l'utilisation de la mémoire Linux.
Dans le système d'exploitation Linux, lorsqu'une application a besoin de lire des données dans un fichier, le système d'exploitation alloue d'abord de la mémoire et lit les données à partir de ce dernier. le disque dans ces mémoires, puis distribue les données à l'application ; lorsqu'il est nécessaire d'écrire des données dans un fichier, le système d'exploitation alloue d'abord de la mémoire pour recevoir les données utilisateur, puis écrit les données de la mémoire sur le disque. Cependant, s'il y a une grande quantité de données qui doivent être lues du disque vers la mémoire ou écrites de la mémoire vers le disque, les performances de lecture et d'écriture du système deviennent très faibles, car s'il lit des données depuis le disque ou écrire des données sur le disque, c'est un processus très long qui consomme du temps et des ressources. Dans ce cas, Linux a introduit les tampons et les mécanismes de mise en cache.
Les tampons et la mise en cache sont deux opérations de mémoire, utilisées pour enregistrer les fichiers et les informations sur les attributs de fichiers qui ont été ouverts par le système. De cette façon, lorsque le système d'exploitation a besoin de lire certains fichiers, il recherchera d'abord dans les tampons et les zones de mémoire mises en cache. .S'ils sont trouvés, ils seront lus directement. Si les données requises ne sont pas trouvées, elles seront lues à partir du disque. Il s'agit du mécanisme de mise en cache du système d'exploitation. Grâce à la mise en cache, les performances du système d'exploitation sont grandement améliorées. Mais le contenu des tampons et des tampons mis en cache est différent.
Les tampons sont utilisés pour mettre en mémoire tampon les périphériques de blocage. Ils enregistrent uniquement les métadonnées du système de fichiers et le suivi des pages en vol, tandis que le cache est utilisé pour mettre les fichiers en mémoire tampon. Pour faire plus simple : les tampons sont principalement utilisés pour stocker le contenu du répertoire, les attributs et autorisations des fichiers, etc. Et le cache est directement utilisé pour mémoriser les fichiers et programmes que nous avons ouverts.
Afin de vérifier si notre conclusion est correcte, vous pouvez ouvrir un très gros fichier via vi pour voir les modifications dans le cache, puis vi à nouveau le fichier pour ressentir les similitudes et les différences dans la vitesse de son ouverture deux fois, et si c'est la deuxième fois qu'il est ouvert nettement plus vite que la première fois ? Exécutez ensuite la commande suivante :
find / -name .conf pour voir si la valeur des tampons change, puis exécutez la commande find à plusieurs reprises pour voir la différence de vitesse d'affichage entre les deux fois.
2. Quand Linux a-t-il commencé à utiliser la mémoire virtuelle (swap) ?
[root@wenwen ~]# cat /proc/sys/vm/swappiness 60
Le 60 ci-dessus signifie que le swap sera utilisé lorsque 40 % de la mémoire physique est utilisée (reportez-vous aux informations réseau : lorsque la mémoire physique restante est inférieure à 40 % (40=100-60), le l'espace d'échange sera utilisé) Lorsque swappiness = 0, cela signifie que la mémoire physique est utilisée au maximum, puis lorsque swappiness = 100, cela signifie que la partition d'échange est activement utilisée et les données sur la partition d'échange. la mémoire est déplacée vers l'espace d'échange en temps opportun.
Plus la valeur est grande, plus vous êtes susceptible d'utiliser le swap. Il peut être fixé à 0, ce qui n'interdit pas l'utilisation du swap, mais minimise seulement la possibilité d'utiliser le swap.
通常情况下:swap分区设置建议是内存的两倍 (内存小于等于4G时),如果内存大于4G,swap只要比内存大就行。另外尽量的将swappiness调低,这样系统的性能会更好。
B.修改swappiness参数
临时性修改: [root@wenwen ~]# sysctl vm.swappiness=10 vm.swappiness = 10 [root@wenwen ~]# cat /proc/sys/vm/swappiness 10
永久性修改:
[root@wenwen ~]# vim /etc/sysctl.conf 加入参数: vm.swappiness = 35 然后在直接: [root@wenwen ~]# sysctl -p /etc/sysctl.conf 查看是否生效: cat /proc/sys/vm/swappiness 35
立即生效,重启也可以生效。
三、怎么释放内存?
一般系统是不会自动释放内存的关键的配置文件/proc/sys/vm/drop_caches。这个文件中记录了缓存释放的参数,默认值为0,也就是不释放缓存。他的值可以为0~3之间的任意数字,代表着不同的含义:
0 – 不释放1 – 释放页缓存2 – 释放dentries和inodes3 – 释放所有缓存
实操:

很明显多出来很多空闲的内存了吧
4. Comment libérer le swap ?
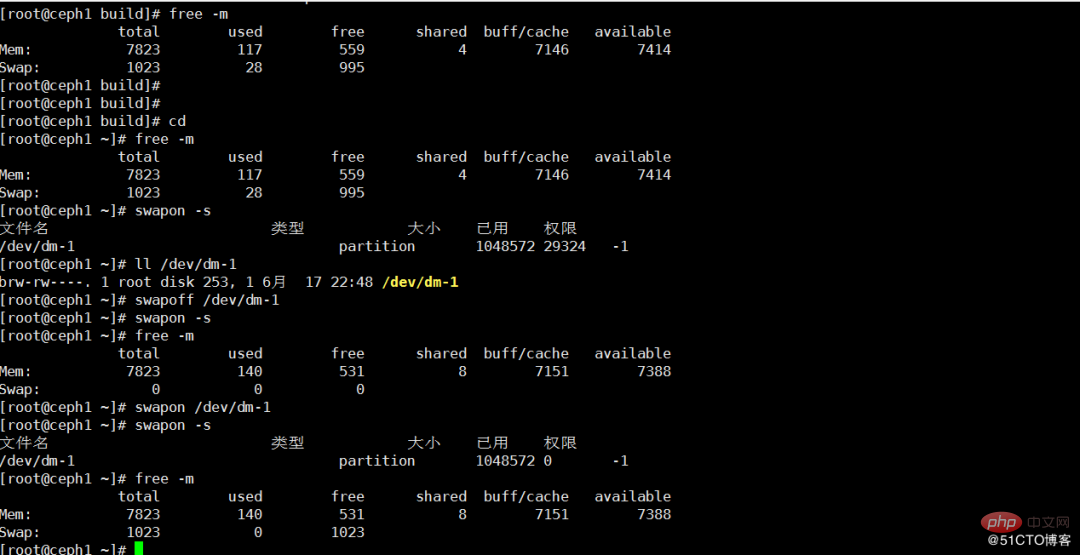
Prérequis : Tout d'abord, assurez-vous que la mémoire restante est supérieure ou égale à l'utilisation du swap, sinon il plantera ! Selon le mécanisme de mémoire, une fois la partition d'échange libérée, tous les fichiers stockés dans la partition d'échange seront transférés vers la mémoire physique. La libération du swap s'effectue généralement en remontant la partition de swap.
a. Vérifiez où la partition de swap actuelle est montée ? b. Arrêtez cette partition c. Vérifiez l'état : d. Vérifiez si la partition de swap est arrêtée. e. Montez le swap sur /dev/sda5 f.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Les principales différences entre Centos et Ubuntu sont: l'origine (Centos provient de Red Hat, pour les entreprises; Ubuntu provient de Debian, pour les particuliers), la gestion des packages (Centos utilise Yum, se concentrant sur la stabilité; Ubuntu utilise APT, pour une fréquence de mise à jour élevée), le cycle de support (CentOS fournit 10 ans de soutien, Ubuntu fournit un large soutien de LT tutoriels et documents), utilisations (Centos est biaisé vers les serveurs, Ubuntu convient aux serveurs et aux ordinateurs de bureau), d'autres différences incluent la simplicité de l'installation (Centos est mince)
 Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Étapes d'installation de CentOS: Téléchargez l'image ISO et Burn Bootable Media; démarrer et sélectionner la source d'installation; sélectionnez la langue et la disposition du clavier; configurer le réseau; partitionner le disque dur; définir l'horloge système; créer l'utilisateur racine; sélectionnez le progiciel; démarrer l'installation; Redémarrez et démarrez à partir du disque dur une fois l'installation terminée.
 Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
CentOS a été interrompu, les alternatives comprennent: 1. Rocky Linux (meilleure compatibilité); 2. Almalinux (compatible avec CentOS); 3. Serveur Ubuntu (configuration requise); 4. Red Hat Enterprise Linux (version commerciale, licence payante); 5. Oracle Linux (compatible avec Centos et Rhel). Lors de la migration, les considérations sont: la compatibilité, la disponibilité, le soutien, le coût et le soutien communautaire.
 Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop? Docker Desktop est un outil pour exécuter des conteneurs Docker sur les machines locales. Les étapes à utiliser incluent: 1. Installer Docker Desktop; 2. Démarrer Docker Desktop; 3. Créer une image Docker (à l'aide de DockerFile); 4. Build Docker Image (en utilisant Docker Build); 5. Exécuter Docker Container (à l'aide de Docker Run).
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Une fois CentOS arrêté, les utilisateurs peuvent prendre les mesures suivantes pour y faire face: sélectionnez une distribution compatible: comme Almalinux, Rocky Linux et CentOS Stream. Migrez vers les distributions commerciales: telles que Red Hat Enterprise Linux, Oracle Linux. Passez à Centos 9 Stream: Rolling Distribution, fournissant les dernières technologies. Sélectionnez d'autres distributions Linux: comme Ubuntu, Debian. Évaluez d'autres options telles que les conteneurs, les machines virtuelles ou les plates-formes cloud.
 Que faire si l'image Docker échoue
Apr 15, 2025 am 11:21 AM
Que faire si l'image Docker échoue
Apr 15, 2025 am 11:21 AM
Dépannage des étapes pour la construction d'image Docker échouée: cochez la syntaxe Dockerfile et la version de dépendance. Vérifiez si le contexte de construction contient le code source et les dépendances requis. Affichez le journal de construction pour les détails d'erreur. Utilisez l'option - cibler pour créer une phase hiérarchique pour identifier les points de défaillance. Assurez-vous d'utiliser la dernière version de Docker Engine. Créez l'image avec --t [Image-Name]: Debug Mode pour déboguer le problème. Vérifiez l'espace disque et assurez-vous qu'il est suffisant. Désactivez SELINUX pour éviter les interférences avec le processus de construction. Demandez de l'aide aux plateformes communautaires, fournissez Dockerfiles et créez des descriptions de journaux pour des suggestions plus spécifiques.
 Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Vs Code Système Exigences: Système d'exploitation: Windows 10 et supérieur, MacOS 10.12 et supérieur, processeur de distribution Linux: minimum 1,6 GHz, recommandé 2,0 GHz et au-dessus de la mémoire: minimum 512 Mo, recommandée 4 Go et plus d'espace de stockage: Minimum 250 Mo, recommandée 1 Go et plus d'autres exigences: connexion du réseau stable, xorg / wayland (Linux) recommandé et recommandée et plus
