
 Opération et maintenance
Nginx
Analyse de cas d'application du proxy inverse et de l'équilibrage de charge du serveur Nginx dans des scénarios Big Data
Opération et maintenance
Nginx
Analyse de cas d'application du proxy inverse et de l'équilibrage de charge du serveur Nginx dans des scénarios Big Data
Analyse de cas d'application du proxy inverse et de l'équilibrage de charge du serveur Nginx dans des scénarios Big Data

Analyse de cas d'application du proxy inverse et de l'équilibrage de charge du serveur Nginx dans des scénarios Big Data
Introduction :
À l'ère actuelle de l'information, la promotion généralisée des applications Big Data a mis en avant des exigences plus élevées en matière de performances et de capacité de charge du serveur. Afin de répondre aux besoins d'accès simultanés d'un grand nombre d'utilisateurs, l'utilisation d'une architecture de proxy inverse et d'équilibrage de charge est devenue une solution courante. Cet article prendra le serveur Nginx comme exemple pour analyser les cas d'application du proxy inverse et de l'équilibrage de charge dans des scénarios Big Data, et le démontrera avec des exemples de code réels.
1. Cas d'application du proxy inverse Nginx
1.1. Équilibreur de charge
Dans les scénarios Big Data, de nombreuses exigences commerciales sont souvent rencontrées et doivent être distribuées sur plusieurs serveurs via des requêtes pour améliorer les performances et la fiabilité du serveur. La fonction de proxy inverse de Nginx peut être utilisée comme équilibreur de charge pour distribuer les requêtes des utilisateurs au serveur réel back-end selon un certain algorithme afin d'obtenir un équilibrage de charge des requêtes.
Exemple de code :
http {
upstream backend {
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server {
location / {
proxy_pass http://backend;
}
}
}1.2. Demander la mise en cache et la statique des données
Dans les scénarios Big Data, afin d'améliorer la vitesse d'accès et de réduire la pression du serveur, certaines données statiques sont généralement mises en cache et les résultats mis en cache sont renvoyés directement. La fonction de proxy inverse de Nginx peut réaliser la mise en cache des requêtes et la statique des données via le mécanisme de mise en cache.
Exemple de code :
http {
proxy_cache_path /data/nginx/cache levels=1:2 keys_zone=my_cache:10m max_size=10g
inactive=60m use_temp_path=off;
server {
location / {
proxy_pass http://backend;
proxy_cache my_cache;
proxy_cache_valid 200 302 10m;
proxy_cache_valid 404 1m;
}
}
} 2. Cas d'application de l'équilibrage de charge Nginx
2.1. Construction d'un cluster de serveurs
Dans les scénarios Big Data, un énorme cluster de serveurs est généralement construit pour transporter des requêtes et un traitement de données massifs. La fonction d'équilibrage de charge de Nginx peut réaliser une planification dynamique de plusieurs serveurs pour garantir l'utilisation des ressources et l'équilibrage de charge de chaque serveur.
Exemple de code :
http {
upstream backend {
server backend1.example.com weight=5;
server backend2.example.com;
server backend3.example.com max_fails=3 fail_timeout=30s;
}
server {
location / {
proxy_pass http://backend;
}
}
}2.2. Utilisation optimisée des ressources matérielles
Dans les scénarios Big Data, les ressources matérielles du serveur sont très précieuses, elles doivent donc être utilisées et optimisées de manière rationnelle. La fonction d'équilibrage de charge de Nginx peut utiliser des algorithmes intelligents pour distribuer les requêtes aux nœuds offrant les meilleures performances du serveur afin d'améliorer l'utilisation des ressources matérielles.
Exemple de code :
http {
upstream backend {
least_conn;
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server {
location / {
proxy_pass http://backend;
}
}
}Conclusion :
Grâce à l'analyse du cas d'application des fonctions de proxy inverse et d'équilibrage de charge de Nginx, nous pouvons constater que dans les scénarios Big Data, l'utilisation du proxy inverse et de l'équilibrage de charge peut considérablement améliorer les performances et la fiabilité du serveur. En configurant correctement les paramètres pertinents de Nginx, des fonctions telles que l'équilibrage de charge du serveur, la mise en cache des requêtes et la statique des données peuvent être mises en œuvre plus efficacement. Par conséquent, le proxy inverse et l'équilibrage de charge de Nginx ont de larges perspectives d'application dans les scénarios Big Data.
Références :
- http://nginx.org/en/docs/http/load_balancing.html
- http://nginx.org/en/docs/http/ngx_http_proxy_module.html
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment générer une URL à partir d'un fichier HTML
Apr 21, 2024 pm 12:57 PM
Comment générer une URL à partir d'un fichier HTML
Apr 21, 2024 pm 12:57 PM
La conversion d'un fichier HTML en URL nécessite un serveur Web, ce qui implique les étapes suivantes : Obtenir un serveur Web. Configurez un serveur Web. Téléchargez le fichier HTML. Créez un nom de domaine. Acheminez la demande.
 Application de la stratégie d'équilibrage de charge dans l'optimisation des performances du framework Java
May 31, 2024 pm 08:02 PM
Application de la stratégie d'équilibrage de charge dans l'optimisation des performances du framework Java
May 31, 2024 pm 08:02 PM
Les stratégies d'équilibrage de charge sont cruciales dans les frameworks Java pour une distribution efficace des requêtes. En fonction de la situation de concurrence, différentes stratégies ont des performances différentes : Méthode d'interrogation : performances stables sous une faible concurrence. Méthode d'interrogation pondérée : les performances sont similaires à la méthode d'interrogation sous faible concurrence. Méthode du moindre nombre de connexions : meilleures performances sous une concurrence élevée. Méthode aléatoire : simple mais peu performante. Hachage cohérent : équilibrage de la charge du serveur. Combiné à des cas pratiques, cet article explique comment choisir des stratégies appropriées basées sur les données de performances pour améliorer significativement les performances des applications.
 Comment déployer et maintenir un site Web en utilisant PHP
May 03, 2024 am 08:54 AM
Comment déployer et maintenir un site Web en utilisant PHP
May 03, 2024 am 08:54 AM
Pour déployer et maintenir avec succès un site Web PHP, vous devez effectuer les étapes suivantes : Sélectionnez un serveur Web (tel qu'Apache ou Nginx) Installez PHP Créez une base de données et connectez PHP Téléchargez le code sur le serveur Configurez le nom de domaine et la maintenance du site Web de surveillance DNS les étapes comprennent la mise à jour de PHP et des serveurs Web, la sauvegarde du site Web, la surveillance des journaux d'erreurs et la mise à jour du contenu.
 Comment utiliser Fail2Ban pour protéger votre serveur contre les attaques par force brute
Apr 27, 2024 am 08:34 AM
Comment utiliser Fail2Ban pour protéger votre serveur contre les attaques par force brute
Apr 27, 2024 am 08:34 AM
Une tâche importante pour les administrateurs Linux est de protéger le serveur contre les attaques ou les accès illégaux. Par défaut, les systèmes Linux sont livrés avec des pare-feu bien configurés, tels que iptables, Uncomplicated Firewall (UFW), ConfigServerSecurityFirewall (CSF), etc., qui peuvent empêcher diverses attaques. Toute machine connectée à Internet est une cible potentielle d'attaques malveillantes. Il existe un outil appelé Fail2Ban qui peut être utilisé pour atténuer les accès illégaux sur le serveur. Qu’est-ce que Fail2Ban ? Fail2Ban[1] est un logiciel de prévention des intrusions qui protège les serveurs des attaques par force brute. Il est écrit en langage de programmation Python
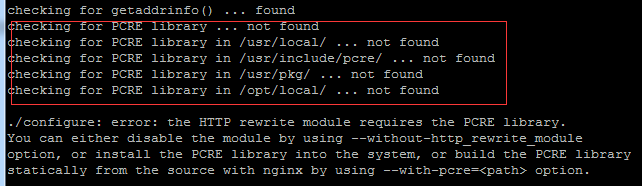 Venez avec moi apprendre Linux et installer Nginx
Apr 28, 2024 pm 03:10 PM
Venez avec moi apprendre Linux et installer Nginx
Apr 28, 2024 pm 03:10 PM
Aujourd'hui, je vais vous amener à installer Nginx dans l'environnement Linux. Le système Linux utilisé ici est CentOS7.2 Préparez les outils d'installation 1. Téléchargez Nginx depuis le site officiel de Nginx. La version utilisée ici est : 1.13.6.2 Téléchargez le Nginx téléchargé sur Linux Ici, le répertoire /opt/nginx est utilisé comme exemple. Exécutez "tar-zxvfnginx-1.13.6.tar.gz" pour décompresser. 3. Basculez vers le répertoire /opt/nginx/nginx-1.13.6 et exécutez ./configure pour la configuration initiale. Si l'invite suivante apparaît, cela signifie que PCRE n'est pas installé sur la machine et que Nginx doit
 Plusieurs points à noter lors de la création d'une haute disponibilité avec keepalived+nginx
Apr 23, 2024 pm 05:50 PM
Plusieurs points à noter lors de la création d'une haute disponibilité avec keepalived+nginx
Apr 23, 2024 pm 05:50 PM
Après que yum ait installé keepalived, configurez le fichier de configuration keepalived. Notez que dans les fichiers de configuration keepalived du maître et de la sauvegarde, le nom de la carte réseau est le nom de la carte réseau de la machine actuelle qui est sélectionnée comme adresse IP disponible. Environnement LAN Il y en a d'autres, donc ce VIP est une IP intranet dans le même segment réseau que les deux machines. S'il est utilisé dans un environnement réseau externe, peu importe qu'il se trouve sur le même segment de réseau, du moment que le client peut y accéder. Arrêtez le service nginx et démarrez le service keepalived. Vous verrez que keepalived démarre le service nginx s'il ne peut pas démarrer et échoue, il s'agit essentiellement d'un problème avec les fichiers de configuration et les scripts, ou d'un problème de prévention.
 Comment implémenter les meilleures pratiques de sécurité PHP
May 05, 2024 am 10:51 AM
Comment implémenter les meilleures pratiques de sécurité PHP
May 05, 2024 am 10:51 AM
Comment mettre en œuvre les meilleures pratiques de sécurité PHP PHP est l'un des langages de programmation Web backend les plus populaires utilisés pour créer des sites Web dynamiques et interactifs. Cependant, le code PHP peut être vulnérable à diverses failles de sécurité. La mise en œuvre des meilleures pratiques de sécurité est essentielle pour protéger vos applications Web contre ces menaces. Validation des entrées La validation des entrées est une première étape essentielle pour valider les entrées utilisateur et empêcher les entrées malveillantes telles que l'injection SQL. PHP fournit une variété de fonctions de validation d'entrée, telles que filter_var() et preg_match(). Exemple : $username=filter_var($_POST['username'],FILTER_SANIT
 L'accès au fichier du site WordPress est restreint: pourquoi mon fichier .txt n'est-il pas accessible via le nom de domaine?
Apr 01, 2025 pm 03:00 PM
L'accès au fichier du site WordPress est restreint: pourquoi mon fichier .txt n'est-il pas accessible via le nom de domaine?
Apr 01, 2025 pm 03:00 PM
L'accès au fichier du site WordPress est restreint: dépannage de la raison pour laquelle le fichier .txt ne peut pas être accessible récemment. Certains utilisateurs ont rencontré un problème lors de la configuration du nom de domaine commercial du programme MINI: � ...
