

principe de la liste de notes d'étude Redis
liste Fonctions de base
| Command | Description |
|---|---|
| BLPOP touche 1, touche 2,... délai d'attente | Supprimer et Obtenez le premier élément de la liste S'il n'y a aucun élément dans la liste, la liste sera bloquée jusqu'à ce que le délai d'attente soit écoulé ou que l'élément soit affiché. |
| BRPOP key1 [key2 ] timeout | Supprimer et récupérer le dernier élément de la liste. Si la liste ne contient aucun élément, elle sera bloquée jusqu'au. le délai d'attente est écoulé ou un élément contextuel est trouvé jusqu'à ce que. |
| BRPOPLPUSH source destination timeout | Supprimez une valeur de la liste, insérez l'élément sauté dans une autre liste et renvoyez-le si la liste ne contient aucun élément, elle la bloquera jusqu'à ce que le délai d'attente ou jusqu'à ce que des éléments contextuels soient trouvés. |
| LIndex key index | 通过索引获取列表中的元素 |
| Linsert key before/after pivot value | 在列表的元素前或者后插入元素 |
| LLEN key | 获取列表长度 |
| LPOP key | 移出并获取列表的第一个元素 |
| LPUSH clé valeur1,valeur2,… | Insérez une ou plusieurs valeurs dans la tête de la liste |
| LPUSHX clé valeur | insèrera une valeur dans l'en-tête d'une liste existante |
| LRANGE key srart stop | Obtenir les éléments dans la plage spécifiée de la liste |
| Clé LREM count value | Supprimer l'élément de liste |
| LSET key index value | Définir la valeur de l'élément de liste par index |
| Touche LTRIM start stop | Élaguer une liste signifie que la liste ne conserve que les éléments dans la plage spécifiée et que tous les éléments qui ne se trouvent pas dans la plage spécifiée sont supprimés. L'index commence à 0 et la plage est inclusive. |
| clé RPOP | supprime le dernier de la liste, et la valeur de retour est l'élément supprimé |
| RPOPPUSH source destination | Supprimez le dernier élément de la liste et ajoutez cet élément à une autre liste et revenez |
| RPUSH clé valeur1 valeur2 …… | ajoutez Un ou plus de valeurs à la fin de la liste |
| Valeur clé RPUSHX | Ajouter des valeurs à la liste existante |
Graphique de : https://www.cnblogs.com/amyzhu/p/13466311.html
Liste chaînée unique
Avant d'apprendre l'implémentation de la liste de Redis, jetons un coup d'œil au début Comment implémenter une liste à chaînage unique :
Chaque nœud a un pointeur arrière (référence) pointant vers le nœud suivant, le dernier nœud pointe vers NULL pour indiquer la fin, et il y a un pointeur Head pointant vers le nœud suivant. premier nœud pour indiquer le début.
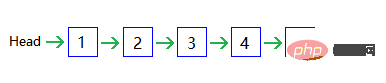
Similaire à ceci, bien que nouveau et supprimé n'ait besoin que de O(1)O(1),但是查找需要 O(n), mais la recherche nécessite O(n)
time ; la recherche inversée n'est pas possible et vous devez commencer depuis le début si vous le manquez.
🎜Ajouter un nœud : 🎜🎜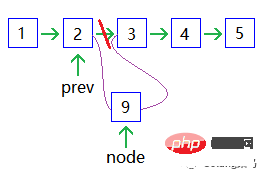
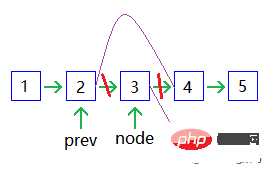
Supprimer un nœud :
Liste double chaînée
Une liste doublement chaînée est également appelée liste doublement chaînée. C'est un type de liste chaînée. Chacun de ses nœuds de données. a deux pointeurs, pointant respectivement vers le successeur immédiat et le prédécesseur immédiat. Par conséquent, à partir de n’importe quel nœud de la liste doublement chaînée, vous pouvez facilement accéder à ses nœuds prédécesseur et successeur.

Caractéristiques :
Chaque fois qu'un nœud est inséré ou supprimé, quatre références de nœud doivent être traitées au lieu de deux. C'est plus difficile à mettre en œuvre
Par rapport à. une liste chaînée à sens unique, elle prendra certainement plus d'espace mémoire.
Elle peut être parcourue du début à la fin, et elle peut être parcourue de la queue à la tête
Cela semble résoudre le problème de Redis, qui peut être implémenté avant et après. C'est un problème de traversée.
Alors jetons un coup d'œil à la liste chaînée de redis Comment y faire face :
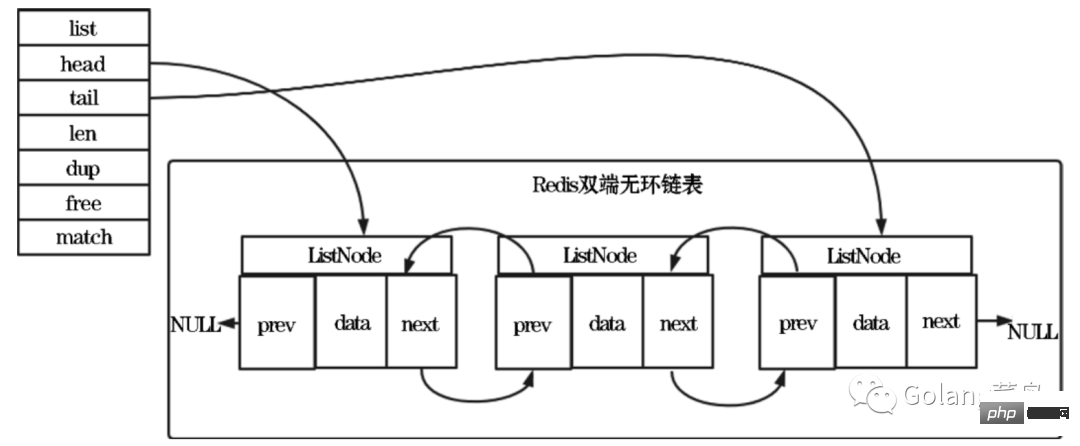
Jetons un coup d'œil au code source de définition de sa structure
ListNode :
typedef struct listNode
{
// 前驱节点
struct listNode *prev;
// 后继节点
struct listNode *next;
// 节点的值
void *value;
} listNode;List :
typedef struct listNode
{
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 链表所包含的节点数量
unsigned long len;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void *(*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr,void *key)
} list;redis Caractéristiques de la liste chaînée :
Acyclique bidirectionnel : nœud de liste chaînée Avec traction avant La complexité temporelle de l'obtention des nœuds prédécesseur et successeur d'un nœud par le pointeur successeur est O(1). Le pointeur prédécesseur du nœud principal et le pointeur successeur du nœud queue pointent tous deux vers NULL et accèdent à. la liste chaînée se termine par NULL.
Compteur de longueur : La complexité temporelle de l'obtention du nombre de nœuds via l'attribut len de la structure List est O(1).
Puisque la liste a toujours un problème d'allocation de mémoire discontinue et de fragmentation de la mémoire, existe-t-il un moyen d'optimiser sa mémoire ?
Liste compressée redis
ZipList n'est pas une structure de données de base, c'est une structure de stockage de données conçue par Redis lui-même. C'est un peu similaire à un tableau, stockant les données dans un espace mémoire continu.
Différent des tableaux, il permet aux éléments de liste stockés d'occuper différents espaces mémoire. Lorsqu'il s'agit du mot compression, la première chose à laquelle tout le monde peut penser est d'économiser de la mémoire. La raison pour laquelle cette structure de stockage permet d'économiser de la mémoire est qu'elle est comparée aux tableaux.
Nous savons tous que les tableaux nécessitent la même taille d'espace de stockage pour chaque élément. Si nous voulons stocker des chaînes de longueurs différentes, nous devons utiliser l'espace de stockage occupé par la chaîne avec la longueur maximale comme chaque élément de la chaîne. array La taille de l'espace (s'il est de 50 octets).
Ainsi, lors du stockage d'une chaîne de moins de 50 octets dans la valeur du numéro de caractère, une partie de l'espace de stockage sera gaspillée. L'avantage de
array est qu'il occupe un espace continu et peut faire bon usage du cache CPU pour accéder rapidement aux données.
Si nous voulons conserver cet avantage du tableau et économiser de l'espace de stockage, alors nous pouvons compresser le tableau :
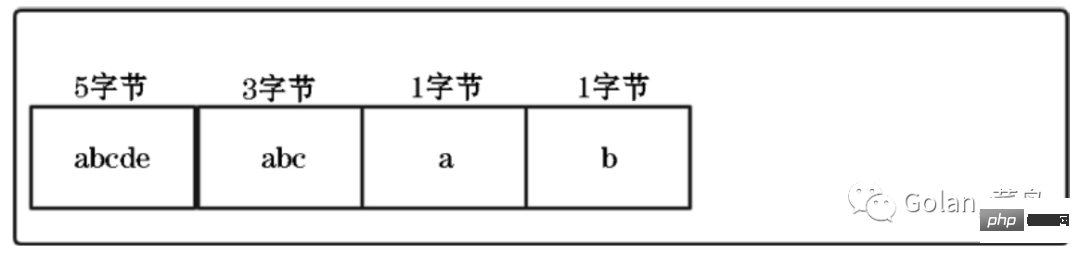
Cependant, il y a un problème que nous ne connaissons pas en parcourant la liste compressée Quelle est la taille de la mémoire occupée par chaque élément, il est donc impossible de calculer la position de départ spécifique de l'élément suivant.
Mais ensuite j'y ai réfléchi, si on pouvait avoir la longueur de chaque élément avant d'y accéder, ce problème ne serait-il pas résolu ?

Voyons ensuite comment Redis implémente ZipList pour le combiner tout en conservant les avantages des tableaux et en économisant de la mémoire.
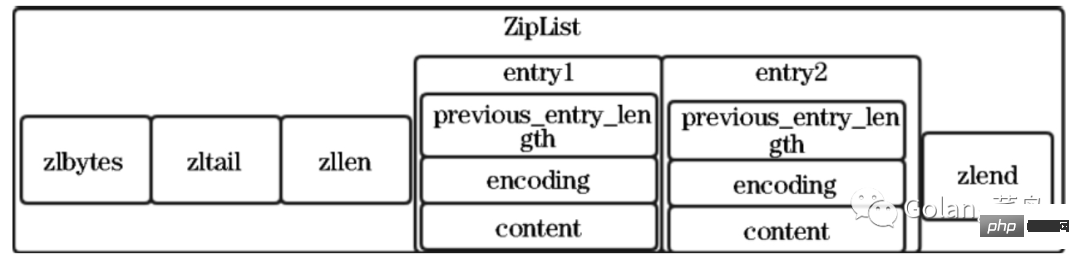
zlbytes:压缩列表的字节长度,是uint32_t类型,占4字节,因此压缩列表最多有232-1字节,可以通过该值计算zlend的位置,也可以在内存重新分配的时候使用。
zltail:压缩列表尾元素相对于压缩列表起始地址的偏移量,是uint32_t类型,占4字节,可以通过该值快速定位到列表尾元素的位置。
zllen:压缩列表元素的个数,是uint16_t类型,占2字节,表示最多存储的元素个数为216-1=65 535,如果需要计算总数量,则需要遍历整个压缩列表。
entryx:压缩列表存储的元素,既可以是字节数组,也可以是整数,长度不限。
zlend:压缩列表的结尾,是uint8_t类型,占1字节,恒为0xFF。
previous_entry_length:表示前一个元素的字节长度,占1字节或者5字节,当前元素的长度小于254时用1字节,大于等于254时用5字节,previous_entry_length 字段的第一个字节固定是0xFE,后面的4字节才是真正的前一个元素的长度。
encoding:表示元素当前的编码,有整数或者字节数。为了节省内存,encoding字段长度可变。
content:表示当前元素的内容。
ZipList变量的读取和赋值都是通过宏来实现的,代码片段如下:
//返回整个压缩列表的总字节 #define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl))) //返回压缩列表的tail_offset变量,方便获取最后一个节点的位置 #define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t)))) //返回压缩列表的节点数量 #define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2))) //返回压缩列表的表头的字节数 //(内存字节数zlbytes,最后一个节点地址ztail_offset,节点总数量zllength) #define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t)) //返回压缩列表最后结尾的字节数 #define ZIPLIST_END_SIZE (sizeof(uint8_t)) //返回压缩列表首节点地址 #define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE) //返回压缩列表尾节点地址 #define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) //返回压缩列表最后结尾的地址 #define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
对此,可以通过定义的结构体和对应的操作定义知道大概 redis 设计 压缩list 的思路;
这种方式虽然节约了空间,但是会存在每次插入和创建存在内存重新分配的问题。
quicklist
quicklist是Redis 3.2中新引入的数据结构,能够在时间效率和空间效率间实现较好的折中。Redis中对quciklist的注释为A doubly linked list of ziplists。顾名思义,quicklist是一个双向链表,链表中的每个节点是一个ziplist结构。quicklist可以看成是用双向链表将若干小型的ziplist连接到一起组成的一种数据结构。
当ziplist节点个数过多,quicklist退化为双向链表,一个极端的情况就是每个ziplist节点只包含一个entry,即只有一个元素。当ziplist元素个数过少时,quicklist可退化为ziplist,一种极端的情况就是quicklist中只有一个ziplist节点。
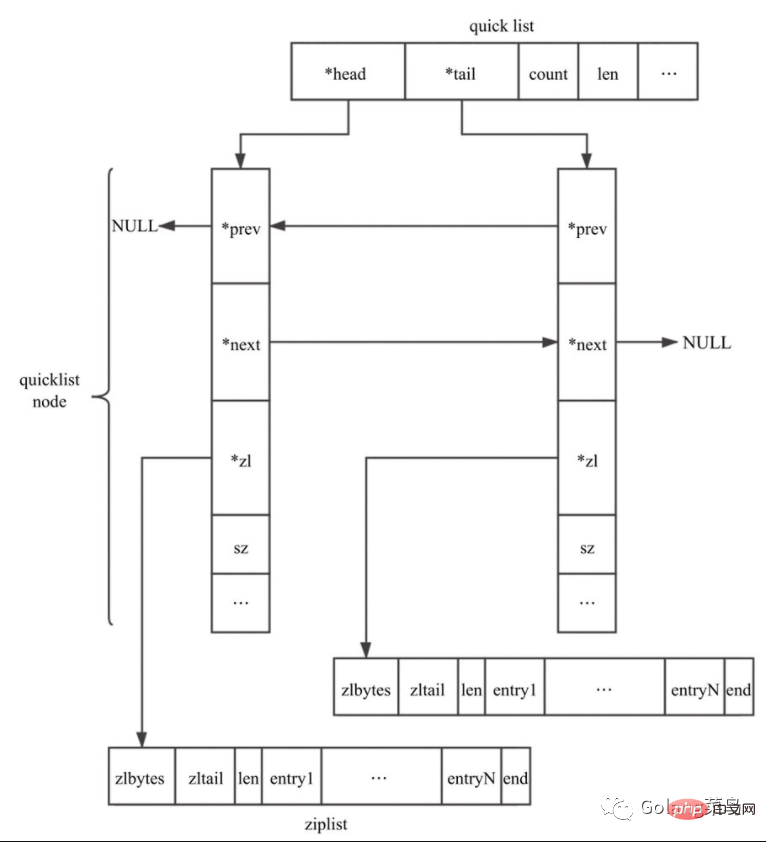
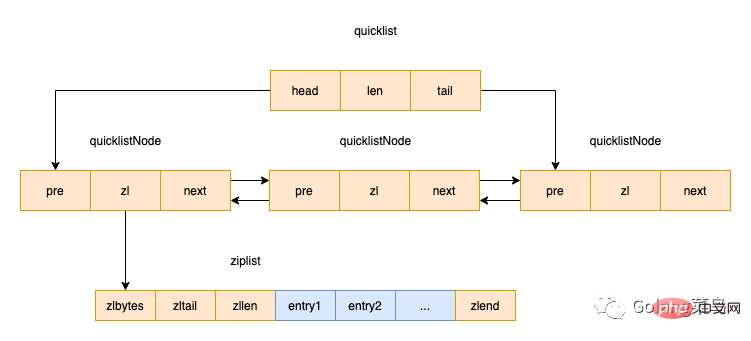
quicklist 结构定义:
typedef struct quicklist {
// 指向quicklist的首节点
quicklistNode *head;
// 指向quicklist的尾节点
quicklistNode *tail;
// quicklist中元素总数
unsigned long count; /* total count of all entries in all ziplists */
// quicklistNode节点个数
unsigned long len; /* number of quicklistNodes */
// ziplist大小设置,存放list-max-ziplist-size参数的值
int fill : 16; /* fill factor for individual nodes */
// 节点压缩深度设置,存放list-compress-depth参数的值
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: 4;
quicklistBookmark bookmarks[];
} quicklist;
typedef struct quicklistBookmark {
quicklistNode *node;
char *name;
} quicklistBookmark;quicklistNode定义如下:
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;redis为了节省内存空间,会将quicklist的节点用LZF压缩后存储,但这里不是全部压缩,可以配置compress的值,compress为0表示所有节点都不压缩,否则就表示从两端开始有多少个节点不压缩;compress如果是1,表示从两端开始,有1个节点不做LZF压缩。compress默认是0(不压缩),具体可以根据你们业务实际使用场景去配置。
redis 的配置文件可以配置该参数
list-compress-depth 0
| Valeur | Signification |
|---|---|
| 0 | Une valeur spéciale signifie aucune compression |
| 1 | Il y a 1 nœud à chaque extrémité de la liste rapide qui n'est pas compressé, et le nœud du milieu est compressé |
| 2 | Il y a 2 nœuds à chaque extrémité de la liste rapide qui ne sont pas compressés, et le nœud du milieu est compressé |
| n | Il y a n nœuds aux deux extrémités de la liste rapide qui ne sont pas compressés, et les nœuds du milieu sont compressés |
Il existe également un champ de remplissage, ce qui signifie que la capacité maximale de chaque nœud quicknode Différentes valeursont des significations différentes. La valeur par défaut est -2. Bien sûr, cela peut. également être configuré sur d'autres valeurs. ;
list-max-ziplist-size -2
Lorsque la valeur est un nombre positif, elle représente la longueur de la liste zip sur le nœud quicklistNode. Par exemple, lorsque la valeur est 5, la liste zip de chaque nœud quicklistNode contient au plus 5 éléments de données
Lorsque la valeur est un nombre négatif, cela signifie que la longueur de la liste zip sur le nœud quicklistNode est limité en fonction du nombre d'octets. Les valeurs possibles sont de -1 à -5.
| valeur | signification |
|---|---|
| -1 | La taille maximale du nœud Ziplist est de 4 Ko |
| - 2 | Le nœud maximum de la liste zip est de 8 Ko |
| -3 | Le nœud maximum de la liste zip est de 16 Ko |
| -4 | nœud ziplist La taille maximale est de 32 Ko |
| -5 | la taille maximale du nœud ziplist est de 64 Ko |
Pourquoi une configuration est-elle fournie ?
Plus la liste zip est courte, plus il y aura de fragments de mémoire, affectant l'efficacité du stockage. Lorsqu'une liste zip ne stocke qu'un seul élément, la liste rapide dégénère en une liste doublement chaînée. Plus la liste zip est longue, plus il est difficile d'allouer un grand espace mémoire continu pour la liste zip, ce qui entraînera l'utilisation de nombreux petits blocs d'espace mémoire. . Waste, lorsque quicklist n'a qu'un seul nœud et que tous les éléments sont stockés dans une ziplist, quicklist dégénère en ziplist
Conclusion
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Pour afficher toutes les touches dans Redis, il existe trois façons: utilisez la commande Keys pour retourner toutes les clés qui correspondent au modèle spécifié; Utilisez la commande SCAN pour itérer les touches et renvoyez un ensemble de clés; Utilisez la commande info pour obtenir le nombre total de clés.
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment implémenter Redis Counter
Apr 10, 2025 pm 10:21 PM
Comment implémenter Redis Counter
Apr 10, 2025 pm 10:21 PM
Redis Counter est un mécanisme qui utilise le stockage de la paire de valeurs de clés Redis pour implémenter les opérations de comptage, y compris les étapes suivantes: création de clés de comptoir, augmentation du nombre, diminution du nombre, réinitialisation du nombre et objet de comptes. Les avantages des compteurs Redis comprennent une vitesse rapide, une concurrence élevée, une durabilité et une simplicité et une facilité d'utilisation. Il peut être utilisé dans des scénarios tels que le comptage d'accès aux utilisateurs, le suivi des métriques en temps réel, les scores de jeu et les classements et le comptage de traitement des commandes.
 Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Les étapes pour démarrer un serveur Redis incluent: Installez Redis en fonction du système d'exploitation. Démarrez le service Redis via Redis-Server (Linux / MacOS) ou Redis-Server.exe (Windows). Utilisez la commande redis-Cli Ping (Linux / MacOS) ou redis-Cli.exe Ping (Windows) pour vérifier l'état du service. Utilisez un client redis, tel que redis-cli, python ou node.js pour accéder au serveur.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
