
 développement back-end
Tutoriel Python
Pandas+Pyecharts | Visualisation de l'analyse des données de vente de produits électroniques + portrait RFM de l'utilisateur
développement back-end
Tutoriel Python
Pandas+Pyecharts | Visualisation de l'analyse des données de vente de produits électroniques + portrait RFM de l'utilisateur
Pandas+Pyecharts | Visualisation de l'analyse des données de vente de produits électroniques + portrait RFM de l'utilisateur

Ce numéro utilise Python pour analyser des données de ventes de produits électroniques, jetez un œil à :
-
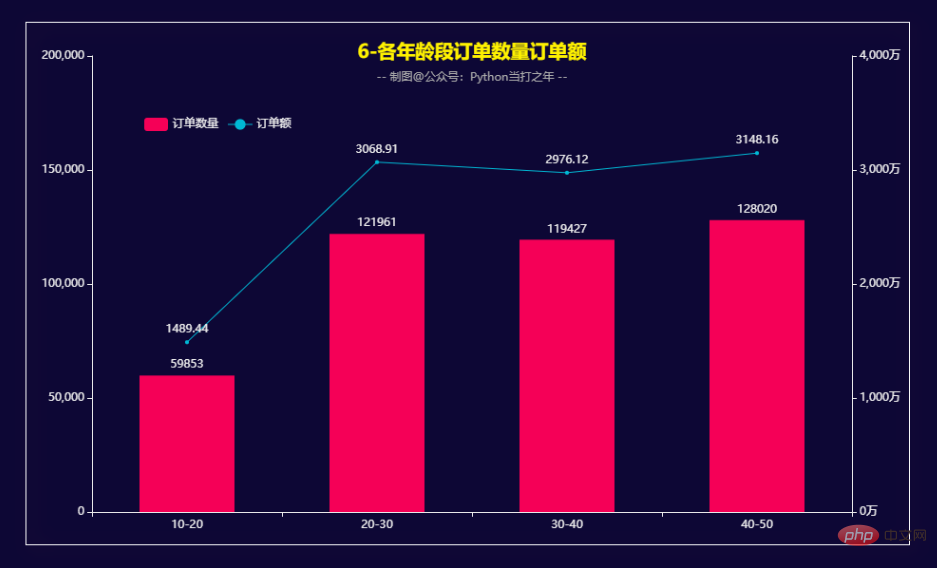
Quantité mensuelle de la commande et montant de la commande
-
Répartition de la quantité commandée quotidiennement
-
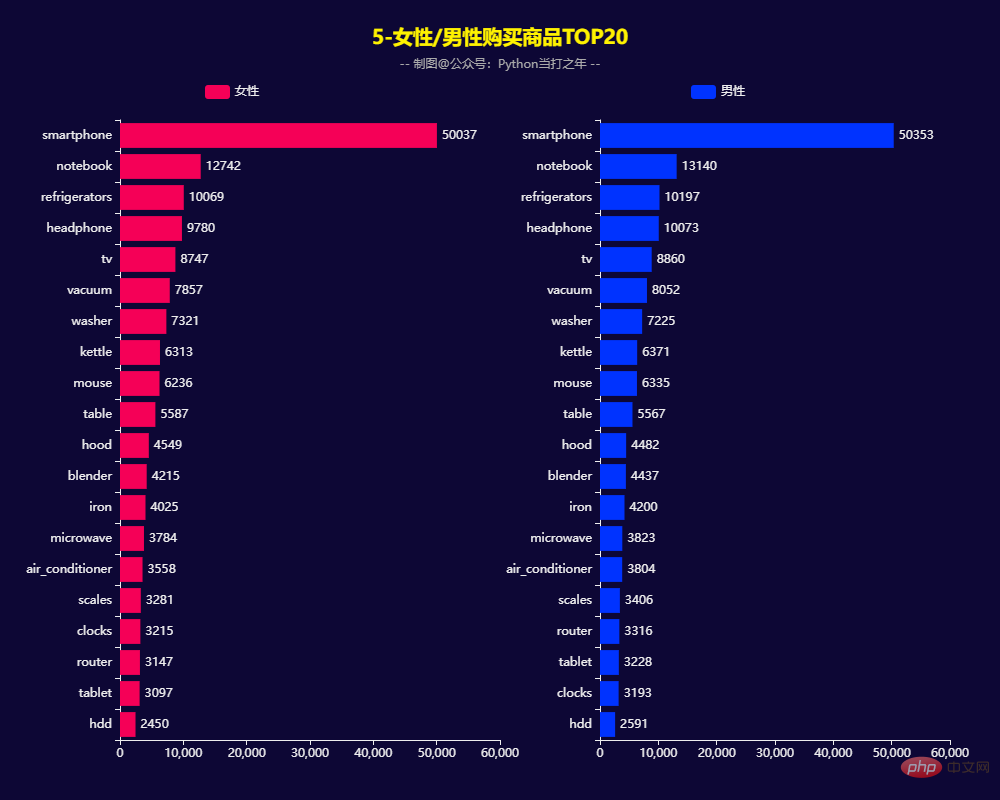
TOP 20 articles achetés par des femmes/ hommes
-
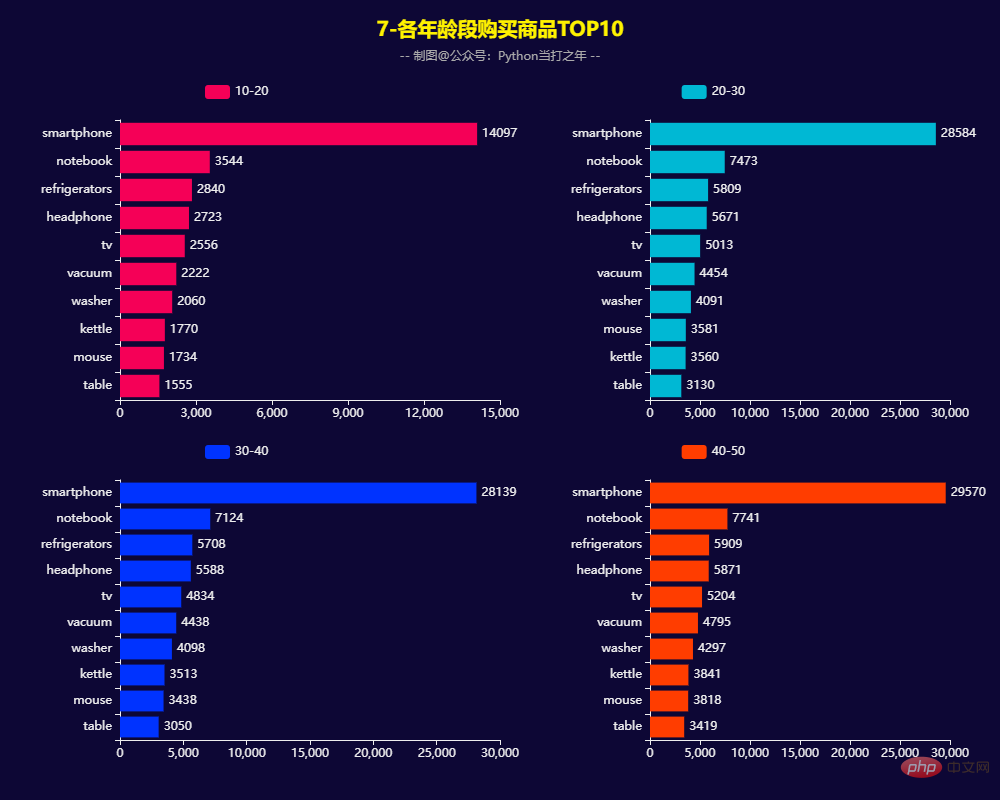
Commandes pour tous les âges Quantité Montant de la commande
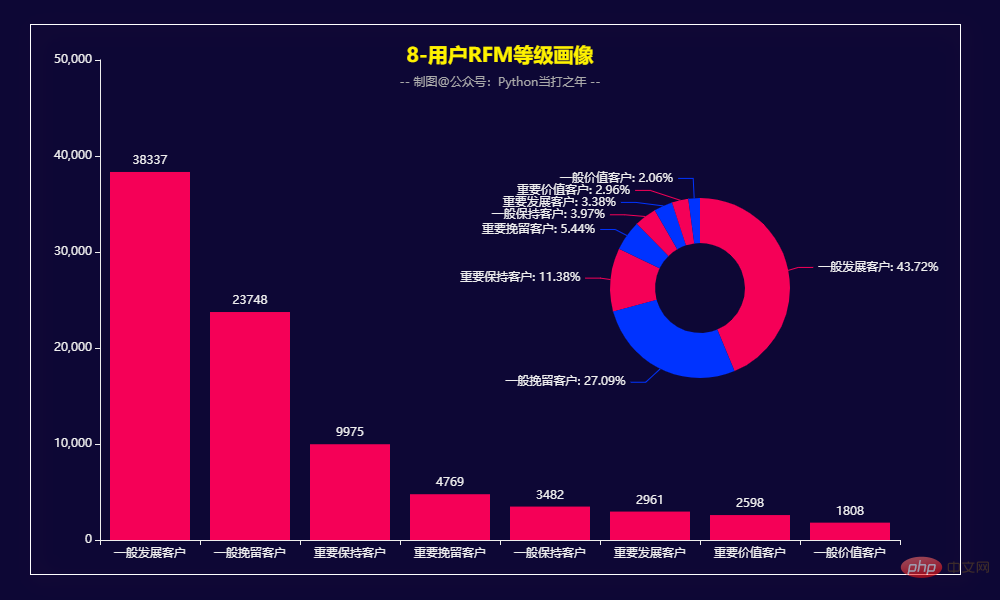
Image du niveau RFM de l'utilisateur
Attendez...
J'espère que ça aide tout le monde, si vous avez des questions. S'il y a des domaines à améliorer, veuillez contacter l'éditeur. Bibliothèques impliquées :
Pandas—Traitement des données
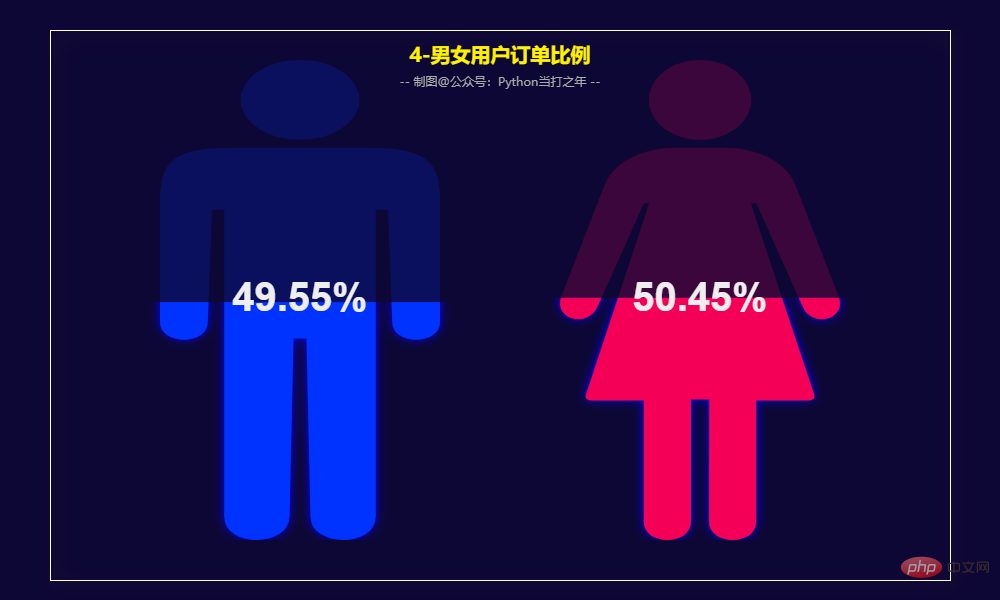
Pyecharts—Visualisation des données 一共有564169条数据,其中category_code、brand两列有部分数据缺失。 2.3 去掉部分用不到的列 (564169, 9) 2.4 去除重复数据 2.5 增加部分时间列 2.6 过滤数据,也可以选择均值填充 8月份的订单量和订单额达到峰值。 男性订单数量占比49.55%,女性订单数量占比50.45%,基本持平。 3.5 女性/男性购买商品TOP20 3.7 各年龄段购买商品TOP10 3.8 用户RFM等级画像 RFM模型是衡量客户价值和客户创利能力的重要工具和手段。该模型通过一个客户的近期购买行为(R)、购买的总体频率(F)以及花了多少钱(M)三项指标来描述该客户的价值状况,从而能够更加准确地将成本和精力更精确的花在用户层次身上,实现针对性的营销。 用户分类: 计算等级: 用户画像: 根据RFM模型可将用户分为以下8类: 重要保持客户:最近消费时间较远,消费金额和频次都很高。 Clients de développement importants : Les utilisateurs ayant un temps de consommation récent et un montant de consommation élevé, mais une faible fréquence et une faible fidélité, qui ont un potentiel élevé, doivent se concentrer sur le développement. Fidélisation client importante : Les utilisateurs dont le temps de consommation récent est éloigné et la fréquence de consommation n'est pas élevée, mais le montant de la consommation est élevé peuvent être des utilisateurs qui seront perdus ou qui ont déjà été perdus, et des mesures de rétention devraient être prises. Clients à valeur générale : temps de consommation récent, fréquence élevée mais faible montant de consommation. Besoin d'augmenter leur prix unitaire. Clients de développement général : Le temps de consommation récent est relativement récent, et le montant et la fréquence de consommation ne sont pas élevés. Gardez généralement les clients : Le temps de consommation récent est éloigné, la fréquence de consommation est élevée et le montant de la consommation n'est pas élevé.
Traitement des données Pandasimport pandas as pd
from pyecharts.charts import Line
from pyecharts.charts import Bar
from pyecharts.charts import Pie
from pyecharts.charts import Grid
from pyecharts.charts import PictorialBar
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv("电子产品销售分析.csv")df1 = df[['event_time', 'order_id', 'category_code', 'brand', 'price', 'user_id', 'age', 'sex', 'local']]
df1.shape
df1 = df1.drop_duplicates()
df1.shape
(556456, 9)
df1['event_time'] = pd.to_datetime(df1['event_time'].str[:19],format="%Y-%m-%d %H:%M:%S")
df1['Year'] = df1['event_time'].dt.year
df1['Month'] = df1['event_time'].dt.month
df1['Day'] = df1['event_time'].dt.day
df1['hour'] = df1['event_time'].dt.hour
df1.head(10)
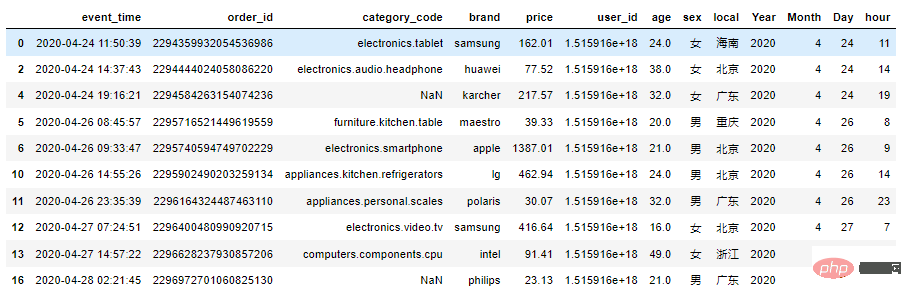
df1 = df1.dropna(subset=['category_code'])
df1 = df1[(df1["Year"] == 2020)&(df1["price"] > 0)]
df1.shape
(429261, 13)
2.7 对年龄分组
df1['age_group'] = pd.cut(df1['age'],[10,20,30,40,50],labels=['10-20','20-30','30-40','40-50'])
2.8 增加商品一、二级分类
df1["category_code_1"] = df1["category_code"].apply(lambda x: x.split(".")[0] if "." in x else x)
df1["category_code_2"] = df1["category_code"].apply(lambda x: x.split(".")[-1] if "." in x else x)
df1.head(10)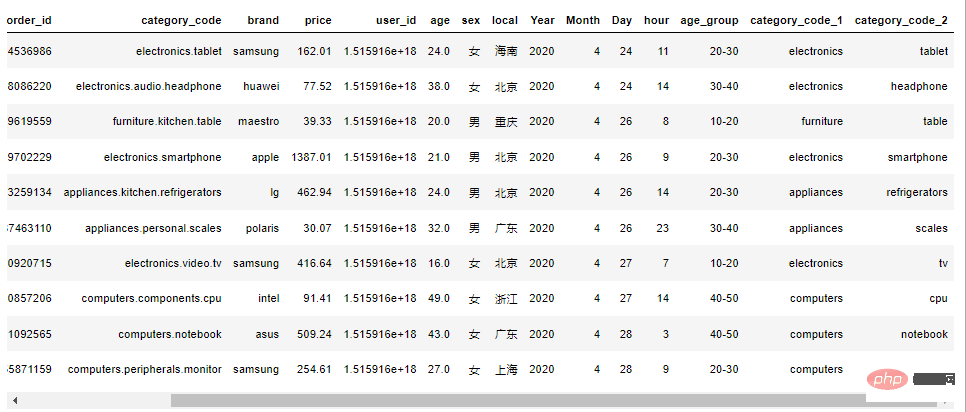
def get_bar1():
bar1 = (
Bar()
.add_xaxis(x_data)
.add_yaxis("订单数量", y_data1)
.extend_axis(yaxis=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter="{value}万")))
.set_global_opts(
legend_opts=opts.LegendOpts(pos_top='25%', pos_left='center'),
title_opts=opts.TitleOpts(
title='1-每月订单数量订单额',
subtitle='-- 制图@公众号:Python当打之年 --',
pos_top='7%',
pos_left="center"
)
)
)
line = (
Line()
.add_xaxis(x_data)
.add_yaxis("订单额", y_data2, yaxis_index=1)
)
bar1.overlap(line)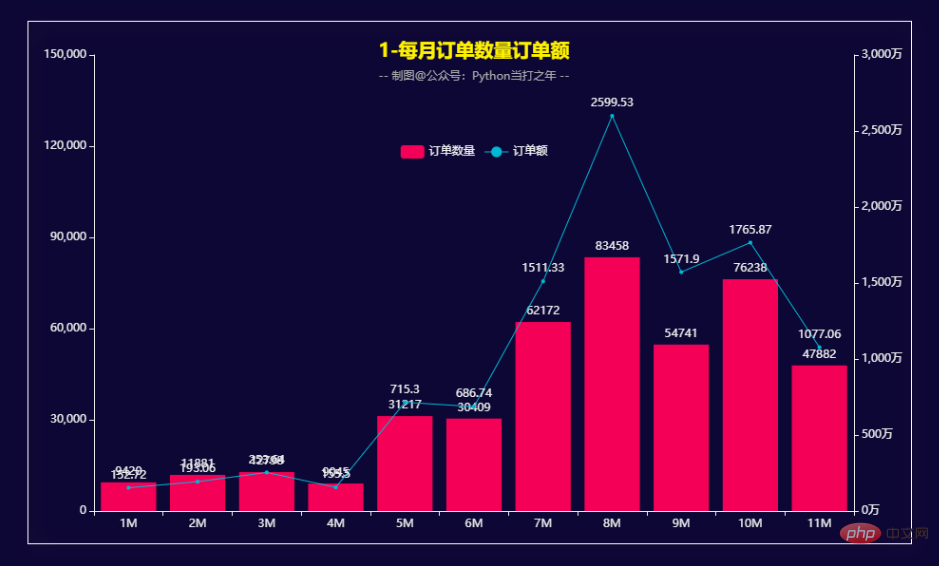
def get_bar2():
pie1 = (
Pie()
.add(
"",
datas,
radius=["13%", "25%"],
label_opts=opts.LabelOpts(formatter="{b}: {d}%"),
)
)
bar1 = (
Bar(init_opts=opts.InitOpts(theme='dark', width='1000px', height='600px', bg_color='#0d0735'))
.add_xaxis(x_data)
.add_yaxis("", y_data, itemstyle_opts=opts.ItemStyleOpts(color=JsCode(color_function)))
.set_global_opts(
legend_opts=opts.LegendOpts(is_show=False),
title_opts=opts.TitleOpts(
title='2-一月各天订单数量分布',
subtitle='-- 制图@公众号:Python当打之年 --',
pos_top='7%',
pos_left="center"
)
)
)
bar1.overlap(pie1)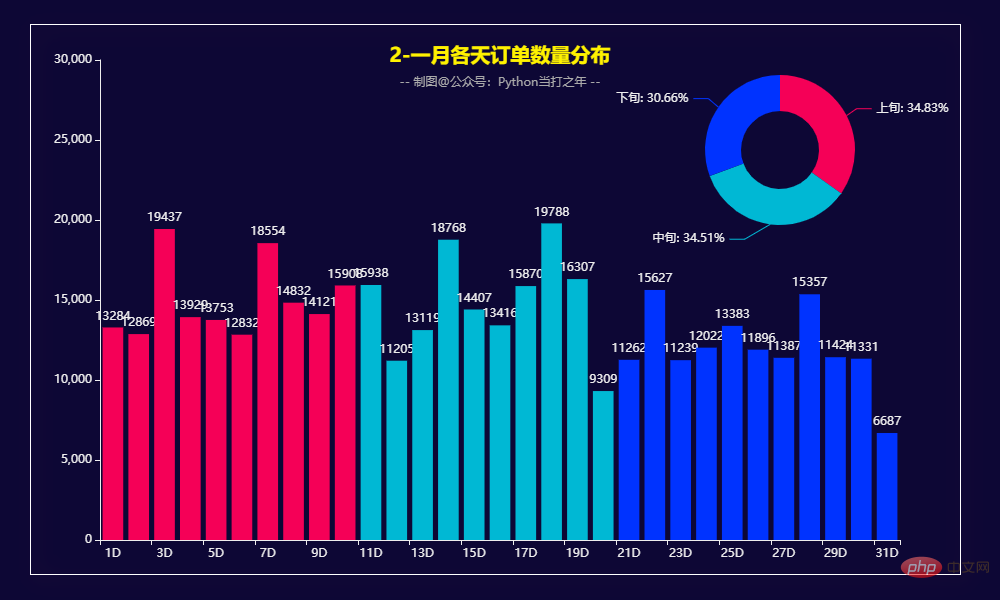
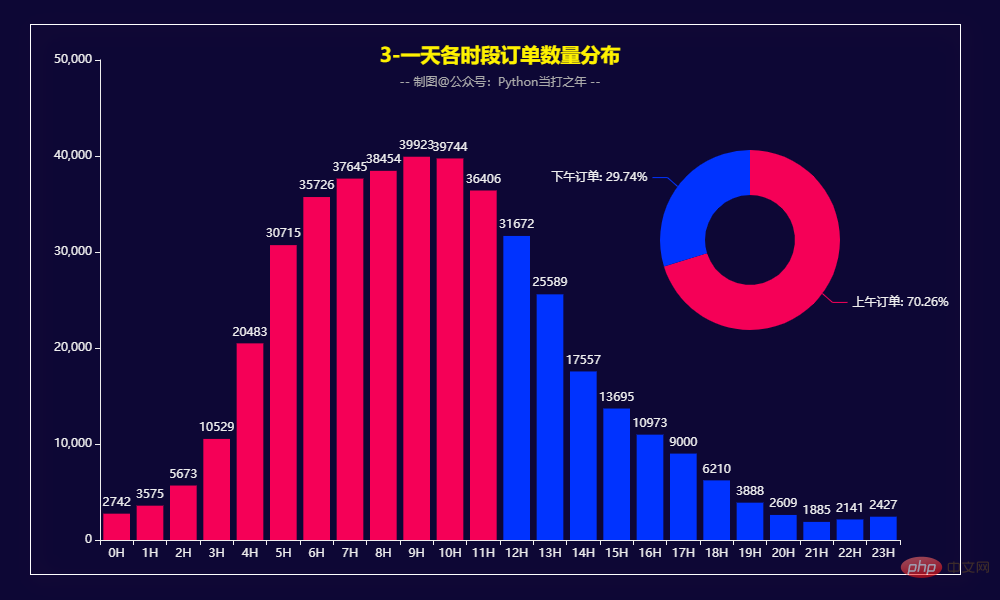
def get_bar3():
bar1 = (
Bar()
.add_xaxis(x_data1)
.add_yaxis('女性', y_data1,
label_opts=opts.LabelOpts(position='right')
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='5-女性/男性购买商品TOP20',
subtitle='-- 制图@公众号:Python当打之年 --',
pos_top='3%',
pos_left="center"),
legend_opts=opts.LegendOpts(pos_left='20%', pos_top='10%')
)
.reversal_axis()
)
bar2 = (
Bar()
.add_xaxis(x_data2)
.add_yaxis('男性', y_data2,
label_opts=opts.LabelOpts(position='right')
)
.set_global_opts(
legend_opts=opts.LegendOpts(pos_right='25%', pos_top='10%')
)
.reversal_axis()
)
grid1 = (
Grid()
.add(bar1, grid_opts=opts.GridOpts(pos_left='12%', pos_right='50%', pos_top='15%'))
.add(bar2, grid_opts=opts.GridOpts(pos_left='60%', pos_right='5%', pos_top='15%'))
)
def rfm_func(x):
level = x.apply(lambda x:"1" if x > 0 else '0')
RMF = level.R + level.F + level.M
dic_rfm ={
'111':'重要价值客户',
'011':'重要保持客户',
'101':'重要发展客户',
'001':'重要挽留客户',
'110':'一般价值客户',
'100':'一般发展客户',
'010':'一般保持客户',
'000':'一般挽留客户'
}
result = dic_rfm[RMF]
return resultdf_rfm = df1.copy()
df_rfm = df_rfm[['user_id','event_time','price']]
# 时间以当年年底为准
df_rfm['days'] = (pd.to_datetime("2020-12-31")-df_rfm["event_time"]).dt.days
# 计算等级
df_rfm = pd.pivot_table(df_rfm,index="user_id",
values=["user_id","days","price"],
aggfunc={"user_id":"count","days":"min","price":"sum"})
df_rfm = df_rfm[["days","user_id","price"]]
df_rfm.columns = ["R","F","M"]
df_rfm['RMF'] = df_rfm[['R','F','M']].apply(lambda x:x-x.mean()).apply(rfm_func,axis=1)
df_rfm.head()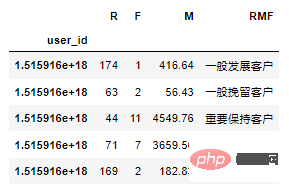
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Résoudre les problèmes courants d'installation de pandas : interprétation et solutions aux erreurs d'installation
Feb 19, 2024 am 09:19 AM
Résoudre les problèmes courants d'installation de pandas : interprétation et solutions aux erreurs d'installation
Feb 19, 2024 am 09:19 AM
Tutoriel d'installation de Pandas : analyse des erreurs d'installation courantes et de leurs solutions, des exemples de code spécifiques sont requis Introduction : Pandas est un puissant outil d'analyse de données largement utilisé dans le nettoyage des données, le traitement des données et la visualisation des données, il est donc très respecté dans le domaine de la science des données. Cependant, en raison de problèmes de configuration de l'environnement et de dépendances, vous pouvez rencontrer des difficultés et des erreurs lors de l'installation de pandas. Cet article vous fournira un didacticiel d'installation de pandas et analysera certaines erreurs d'installation courantes et leurs solutions. 1. Installez les pandas
 Comment lire correctement le fichier txt à l'aide de pandas
Jan 19, 2024 am 08:39 AM
Comment lire correctement le fichier txt à l'aide de pandas
Jan 19, 2024 am 08:39 AM
Comment utiliser pandas pour lire correctement les fichiers txt nécessite des exemples de code spécifiques. Pandas est une bibliothèque d'analyse de données Python largement utilisée. Elle peut être utilisée pour traiter une variété de types de données, notamment des fichiers CSV, des fichiers Excel, des bases de données SQL, etc. En même temps, il peut également être utilisé pour lire des fichiers texte, tels que des fichiers txt. Cependant, lors de la lecture de fichiers txt, nous rencontrons parfois quelques problèmes, comme des problèmes d'encodage, des problèmes de délimiteur, etc. Cet article explique comment lire correctement le txt à l'aide de pandas.
 Lisez des fichiers CSV et effectuez une analyse de données à l'aide de pandas
Jan 09, 2024 am 09:26 AM
Lisez des fichiers CSV et effectuez une analyse de données à l'aide de pandas
Jan 09, 2024 am 09:26 AM
Pandas est un puissant outil d'analyse de données qui peut facilement lire et traiter différents types de fichiers de données. Parmi eux, les fichiers CSV sont l’un des formats de fichiers de données les plus courants et les plus utilisés. Cet article expliquera comment utiliser Pandas pour lire des fichiers CSV et effectuer une analyse de données, et fournira des exemples de code spécifiques. 1. Importez les bibliothèques nécessaires Tout d'abord, nous devons importer la bibliothèque Pandas et les autres bibliothèques associées qui peuvent être nécessaires, comme indiqué ci-dessous : importpandasaspd 2. Lisez le fichier CSV à l'aide de Pan
 méthode d'installation de python pandas
Nov 22, 2023 pm 02:33 PM
méthode d'installation de python pandas
Nov 22, 2023 pm 02:33 PM
Python peut installer des pandas en utilisant pip, en utilisant conda, à partir du code source et en utilisant l'outil de gestion de packages intégré IDE. Introduction détaillée : 1. Utilisez pip et exécutez la commande pip install pandas dans le terminal ou l'invite de commande pour installer pandas ; 2. Utilisez conda et exécutez la commande conda install pandas dans le terminal ou l'invite de commande pour installer pandas ; installation et plus encore.
 Comment installer des pandas en python
Dec 04, 2023 pm 02:48 PM
Comment installer des pandas en python
Dec 04, 2023 pm 02:48 PM
Étapes pour installer pandas en python : 1. Ouvrez le terminal ou l'invite de commande ; 2. Entrez la commande "pip install pandas" pour installer la bibliothèque pandas ; 3. Attendez la fin de l'installation et vous pourrez importer et utiliser la bibliothèque pandas. dans le script Python ; 4. Utiliser Il s'agit d'un environnement virtuel spécifique. Assurez-vous d'activer l'environnement virtuel correspondant avant d'installer pandas ; 5. Si vous utilisez un environnement de développement intégré, vous pouvez ajouter le code « importer des pandas en tant que pd » ; importez la bibliothèque pandas.
 Conseils pratiques pour lire les fichiers txt à l'aide de pandas
Jan 19, 2024 am 09:49 AM
Conseils pratiques pour lire les fichiers txt à l'aide de pandas
Jan 19, 2024 am 09:49 AM
Conseils pratiques pour lire les fichiers txt à l'aide de pandas, des exemples de code spécifiques sont requis Dans l'analyse et le traitement des données, les fichiers txt sont un format de données courant. L'utilisation de pandas pour lire les fichiers txt permet un traitement des données rapide et pratique. Cet article présentera plusieurs techniques pratiques pour vous aider à mieux utiliser les pandas pour lire les fichiers txt, ainsi que des exemples de code spécifiques. Lire des fichiers txt avec des délimiteurs Lorsque vous utilisez pandas pour lire des fichiers txt avec des délimiteurs, vous pouvez utiliser read_c
 Pandas lit facilement les données de la base de données SQL
Jan 09, 2024 pm 10:45 PM
Pandas lit facilement les données de la base de données SQL
Jan 09, 2024 pm 10:45 PM
Outil de traitement des données : Pandas lit les données dans les bases de données SQL et nécessite des exemples de code spécifiques. À mesure que la quantité de données continue de croître et que leur complexité augmente, le traitement des données est devenu une partie importante de la société moderne. Dans le processus de traitement des données, Pandas est devenu l'un des outils préférés de nombreux analystes de données et scientifiques. Cet article explique comment utiliser la bibliothèque Pandas pour lire les données d'une base de données SQL et fournit des exemples de code spécifiques. Pandas est un puissant outil de traitement et d'analyse de données basé sur Python
 Révéler la méthode efficace de déduplication des données dans Pandas : conseils pour supprimer rapidement les données en double
Jan 24, 2024 am 08:12 AM
Révéler la méthode efficace de déduplication des données dans Pandas : conseils pour supprimer rapidement les données en double
Jan 24, 2024 am 08:12 AM
Le secret de la méthode de déduplication Pandas : un moyen rapide et efficace de dédupliquer les données, qui nécessite des exemples de code spécifiques. Dans le processus d'analyse et de traitement des données, une duplication des données est souvent rencontrée. Les données en double peuvent induire en erreur les résultats de l'analyse, la déduplication est donc une étape très importante. Pandas, une puissante bibliothèque de traitement de données, fournit une variété de méthodes pour réaliser la déduplication des données. Cet article présentera certaines méthodes de déduplication couramment utilisées et joindra des exemples de code spécifiques. Le cas le plus courant de déduplication basée sur une seule colonne dépend de la duplication ou non de la valeur d'une certaine colonne.
