
 développement back-end
Tutoriel Python
De manière inattendue, Python peut également créer des pages de visualisation Web !
développement back-end
Tutoriel Python
De manière inattendue, Python peut également créer des pages de visualisation Web !
De manière inattendue, Python peut également créer des pages de visualisation Web !

Quand il s'agit de pages Web, la première chose qui vient peut-être à l'esprit est HTML, CSS ou JavaScript.
Cette fois, Xiao F vous présentera comment utiliser Python pour créer une page Web de visualisation de données, à l'aide de la bibliothèque Streamlit.
Convertissez facilement un fichier de données Excel en une page Web que tout le monde peut consulter en ligne.
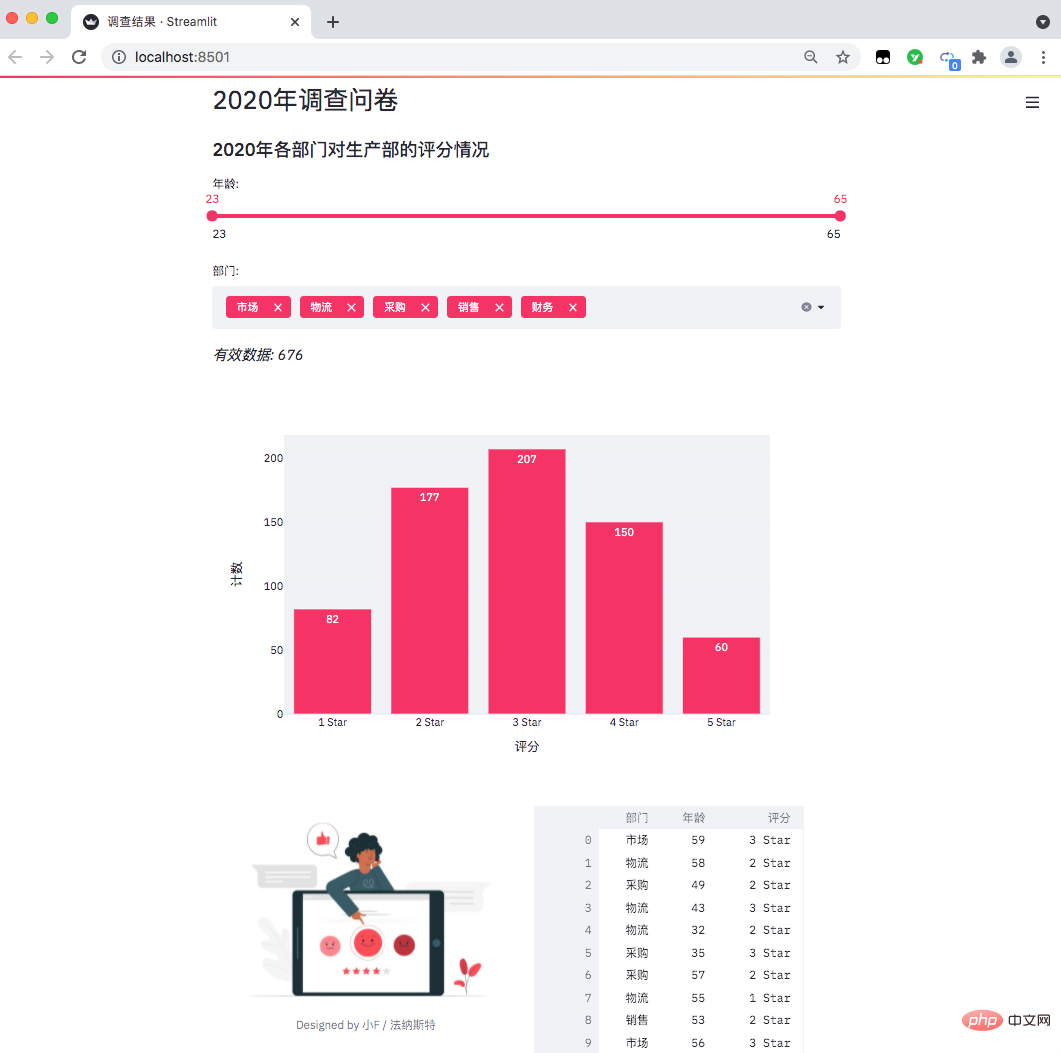
Chaque fois que vous enregistrez des modifications dans le fichier Excel, la page Web peut être mise à jour en temps réel, ce qui est vraiment bien.
Les adresses de la documentation et des didacticiels de Streamlit sont les suivantes.
https://docs.streamlit.io/en/stable/
https://streamlit.io/gallery

L'utilisation pertinente de l'API peut être consultée dans la documentation, qui contient des explications détaillées.
Le projet comprend un total de trois fichiers, un programme, une image et des données de tableau Excel.
Les données sont les suivantes, une enquête par questionnaire de fin d'année d'une entreprise (données fictives), les scores des départements concernés sur la collaboration au travail du département de production.
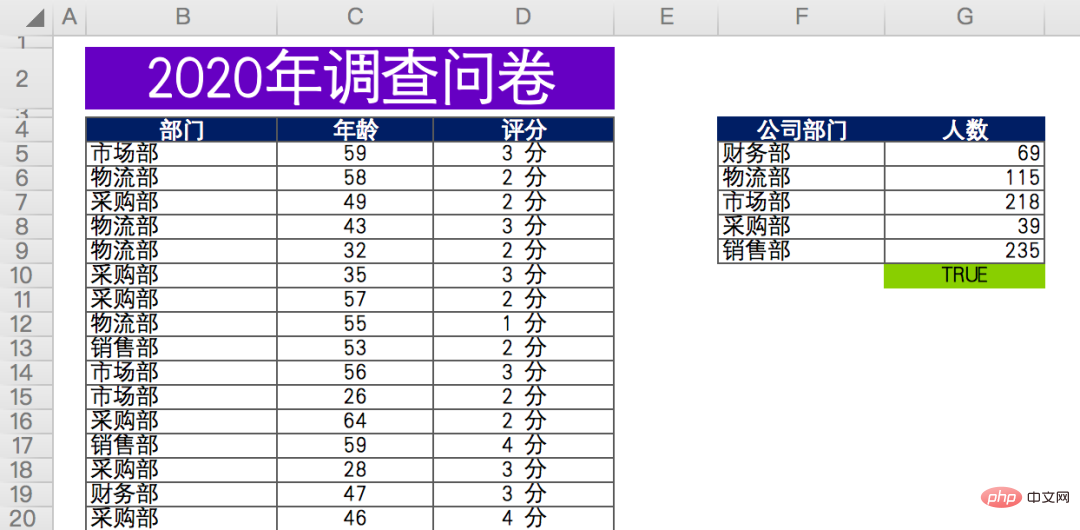
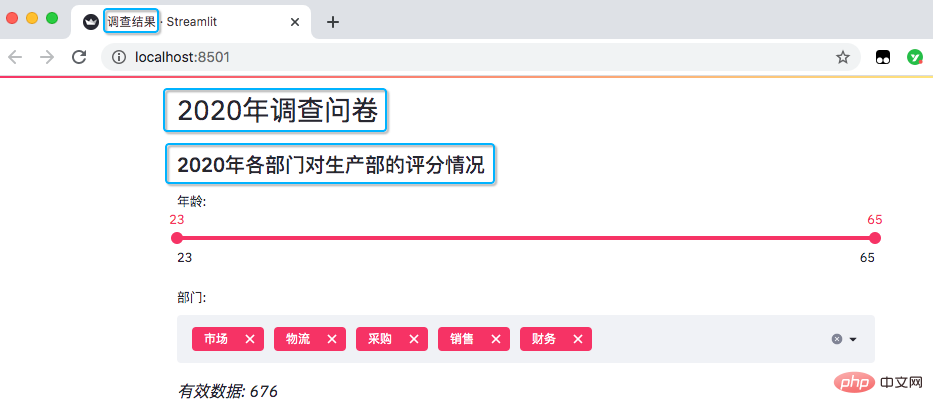
Il y a environ 676 données valides au total. Le questionnaire anonyme comprend le département, l'âge et l'évaluation de la personne qui remplit le questionnaire.
Enfin, le nombre de participants dans chaque département est récapitulé et compté (données à droite).
Installez d'abord la bibliothèque Python appropriée et utilisez la source Baidu.
# 安装streamlit pip install streamlit -i https://mirror.baidu.com/pypi/simple/ # 安装Plotly Express pip install plotly_express==0.4.0 -i https://mirror.baidu.com/pypi/simple/ # 安装xlrd pip install xlrd==1.2.0 -i https://mirror.baidu.com/pypi/simple/
Étant donné que nos fichiers de données sont au format xlsx, la dernière version de xlrd ne prend en charge que les fichiers xls.
Vous devez donc spécifier la version xlrd comme 1.2.0 pour que les pandas puissent lire avec succès les données.
Démarrez la page Web à partir du terminal de ligne de commande.
# 命令行终端打开文件所在路径 cd Excel_Webapp # 运行网页 streamlit run app.py
Il y aura une invite après le succès et le navigateur affichera automatiquement la page Web.
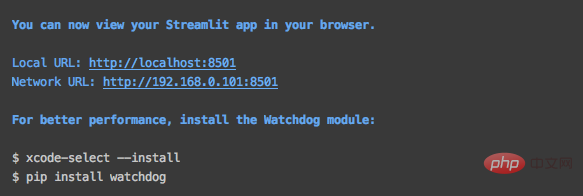
S'il ne s'affiche pas automatiquement, vous pouvez accéder directement à l'adresse indiquée dans l'image ci-dessus.
Le résultat est le suivant, une page web de visualisation de données sort.
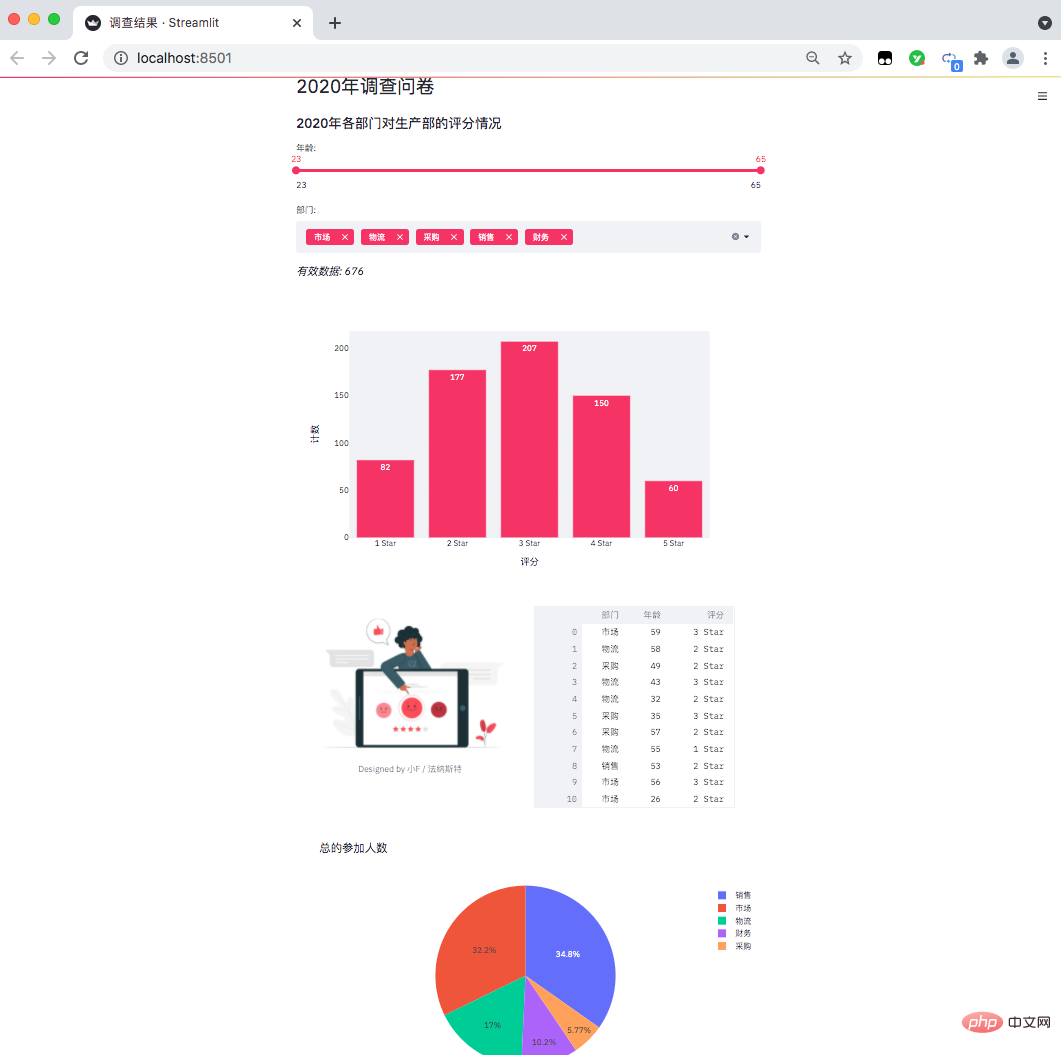
Actuellement, il ne peut être consulté que localement. Si vous souhaitez le mettre en ligne, vous pouvez le déployer via le serveur. Vous devez l'étudier par vous-même~.
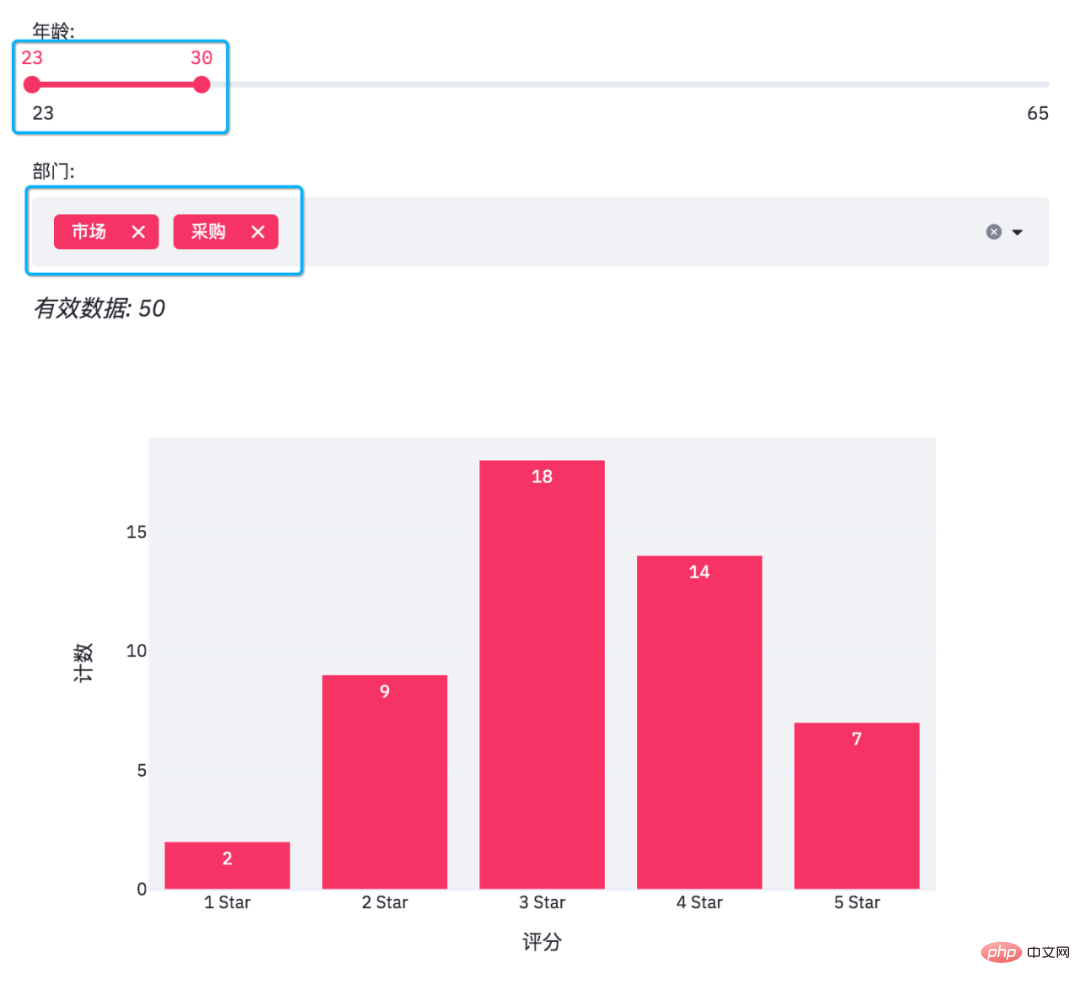
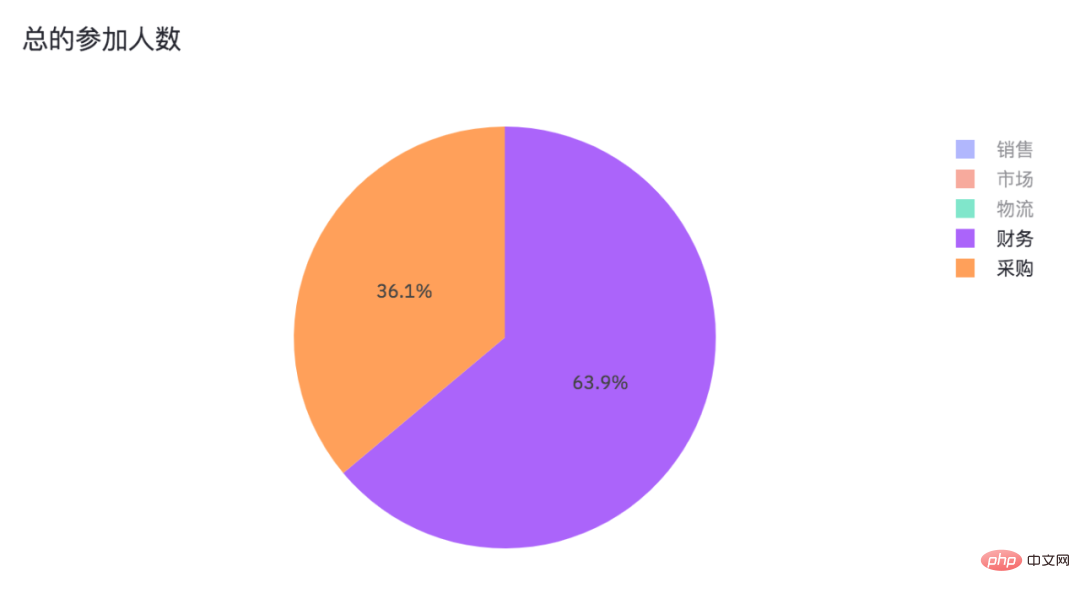
导入相关的Python包,pandas处理数据,streamlit用来生成网页,plotly.express则是生成图表,PIL读取图片。 设置了网页名称,以及网页里的标题和子标题。 读取Excel表格数据,并且得出年龄分布以及部门情况,一共是有5个部门。 添加滑动条和多重选择的数据选项。 结果如下。 年龄是从23至65,部门则是市场、物流、采购、销售、财务这几个。 由于滑动条和多重选择是可变的,需要根据过滤条件得出最终数据。 得到数据便可以绘制柱状图了。 使用plotly绘制柱状图。 当我们在网页调整选项时,有效数据和柱状图也会随之变化。 此外streamlit还可以给网页添加图片和交互式表格。 得到结果如下。 可以看到表格有一个滑动条,可以使用鼠标滚轮滚动查看。 最后便是绘制一个饼图啦! 结果如下。 各部门参加问卷调查的人数,也是一个可以交互的图表。 En annulant les ventes, le marketing et la logistique, nous pouvons voir la proportion de personnes de la finance et des achats qui ont participé à l'enquête. import pandas as pd
import streamlit as st
import plotly.express as px
from PIL import Image
# 设置网页名称
st.set_page_config(page_title='调查结果')
# 设置网页标题
st.header('2020年调查问卷')
# 设置网页子标题
st.subheader('2020年各部门对生产部的评分情况')
# 读取数据
excel_file = '各部门对生产部的评分情况.xlsx'
sheet_name = 'DATA'
df = pd.read_excel(excel_file,
sheet_name=sheet_name,
usecols='B:D',
header=3)
# 此处为各部门参加问卷调查人数
df_participants = pd.read_excel(excel_file,
sheet_name=sheet_name,
usecols='F:G',
header=3)
df_participants.dropna(inplace=True)
# streamlit的多重选择(选项数据)
department = df['部门'].unique().tolist()
# streamlit的滑动条(年龄数据)
ages = df['年龄'].unique().tolist()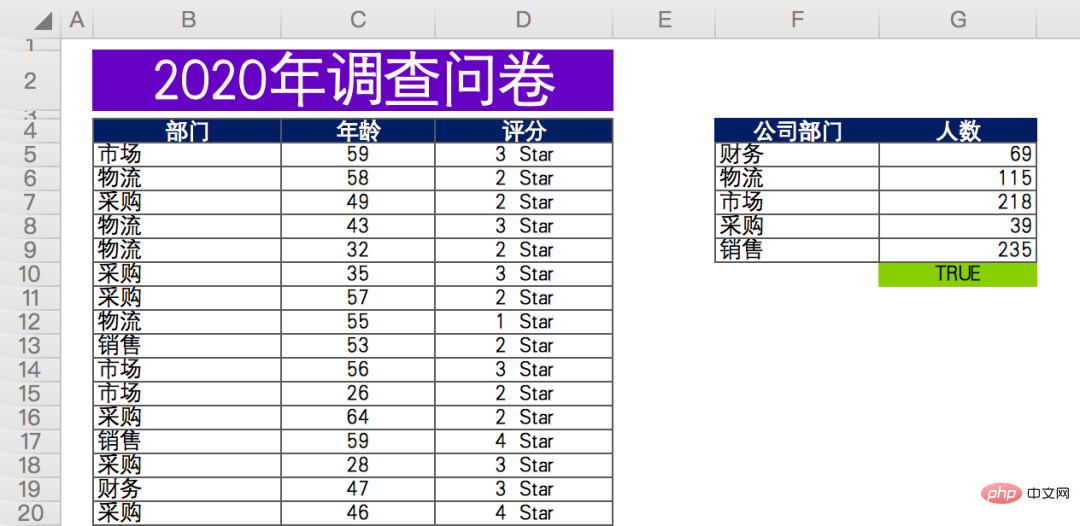
# 滑动条, 最大值、最小值、区间值
age_selection = st.slider('年龄:',
min_value=min(ages),
max_value=max(ages),
value=(min(ages), max(ages)))
# 多重选择, 默认全选
department_selection = st.multiselect('部门:',
department,
default=department)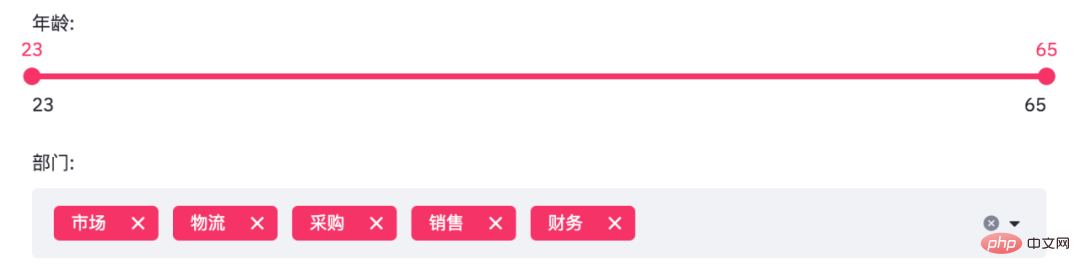
# 根据选择过滤数据
mask = (df['年龄'].between(*age_selection)) & (df['部门'].isin(department_selection))
number_of_result = df[mask].shape[0]
# 根据筛选条件, 得到有效数据
st.markdown(f'*有效数据: {number_of_result}*')
# 根据选择分组数据
df_grouped = df[mask].groupby(by=['评分']).count()[['年龄']]
df_grouped = df_grouped.rename(columns={'年龄': '计数'})
df_grouped = df_grouped.reset_index()# 绘制柱状图, 配置相关参数
bar_chart = px.bar(df_grouped,
x='评分',
y='计数',
text='计数',
color_discrete_sequence=['#F63366']*len(df_grouped),
template='plotly_white')
st.plotly_chart(bar_chart)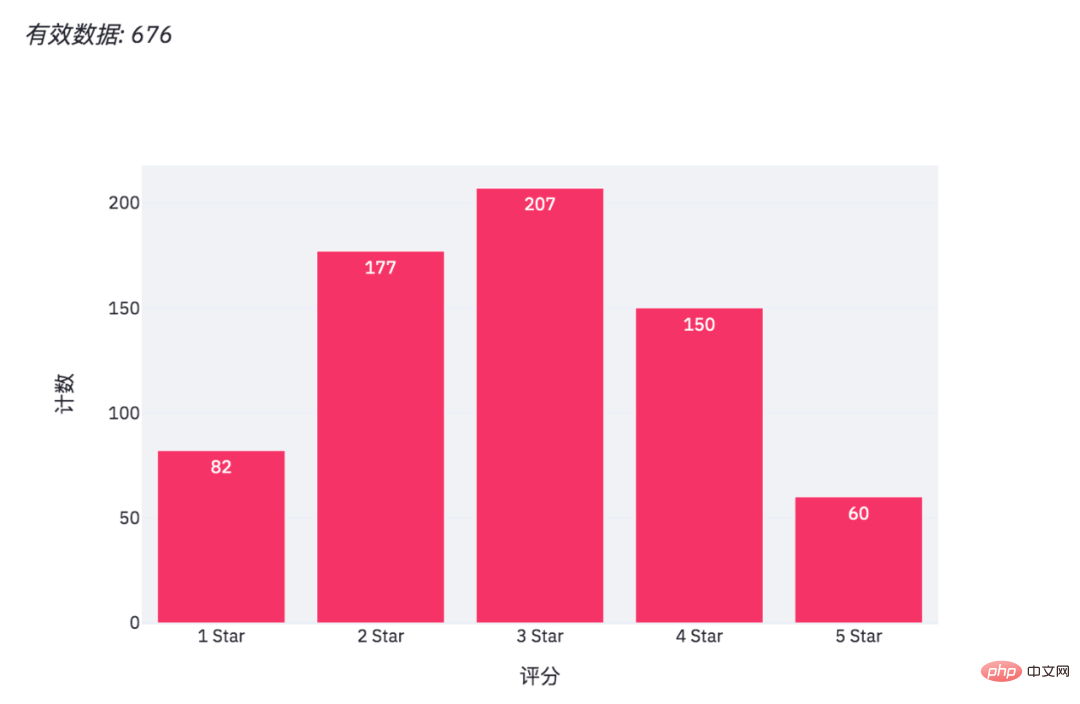
# 添加图片和交互式表格
col1, col2 = st.beta_columns(2)
image = Image.open('survey.jpg')
col1.image(image,
caption='Designed by 小F / 法纳斯特',
use_column_width=True)
col2.dataframe(df[mask], width=300)
# 绘制饼图
pie_chart = px.pie(df_participants,
title='总的参加人数',
values='人数',
names='公司部门')
st.plotly_chart(pie_chart)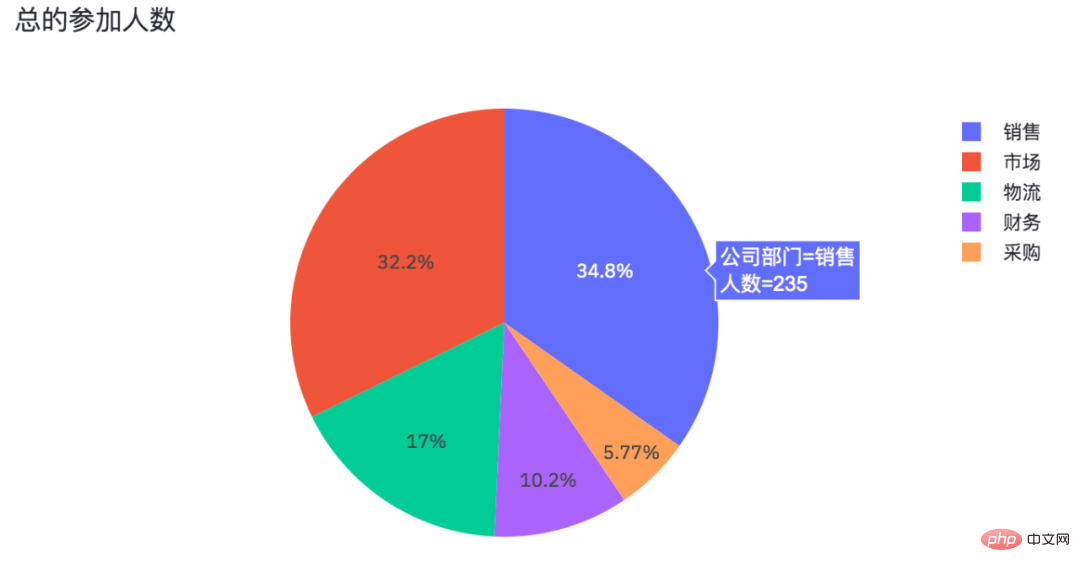
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le plan Python de 2 heures: une approche réaliste
Apr 11, 2025 am 12:04 AM
Le plan Python de 2 heures: une approche réaliste
Apr 11, 2025 am 12:04 AM
Vous pouvez apprendre les concepts de programmation de base et les compétences de Python dans les 2 heures. 1. Apprenez les variables et les types de données, 2. Flux de contrôle maître (instructions et boucles conditionnelles), 3. Comprenez la définition et l'utilisation des fonctions, 4. Démarrez rapidement avec la programmation Python via des exemples simples et des extraits de code.
 Python: Explorer ses applications principales
Apr 10, 2025 am 09:41 AM
Python: Explorer ses applications principales
Apr 10, 2025 am 09:41 AM
Python est largement utilisé dans les domaines du développement Web, de la science des données, de l'apprentissage automatique, de l'automatisation et des scripts. 1) Dans le développement Web, les cadres Django et Flask simplifient le processus de développement. 2) Dans les domaines de la science des données et de l'apprentissage automatique, les bibliothèques Numpy, Pandas, Scikit-Learn et Tensorflow fournissent un fort soutien. 3) En termes d'automatisation et de script, Python convient aux tâches telles que les tests automatisés et la gestion du système.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
En tant que professionnel des données, vous devez traiter de grandes quantités de données provenant de diverses sources. Cela peut poser des défis à la gestion et à l'analyse des données. Heureusement, deux services AWS peuvent aider: AWS Glue et Amazon Athena.
 Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Les étapes pour démarrer un serveur Redis incluent: Installez Redis en fonction du système d'exploitation. Démarrez le service Redis via Redis-Server (Linux / MacOS) ou Redis-Server.exe (Windows). Utilisez la commande redis-Cli Ping (Linux / MacOS) ou redis-Cli.exe Ping (Windows) pour vérifier l'état du service. Utilisez un client redis, tel que redis-cli, python ou node.js pour accéder au serveur.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment afficher la version serveur de redis
Apr 10, 2025 pm 01:27 PM
Comment afficher la version serveur de redis
Apr 10, 2025 pm 01:27 PM
Question: Comment afficher la version Redis Server? Utilisez l'outil de ligne de commande redis-Cli --version pour afficher la version du serveur connecté. Utilisez la commande Info Server pour afficher la version interne du serveur et devez analyser et retourner des informations. Dans un environnement de cluster, vérifiez la cohérence de la version de chaque nœud et peut être vérifiée automatiquement à l'aide de scripts. Utilisez des scripts pour automatiser les versions de visualisation, telles que la connexion avec les scripts Python et les informations d'impression.
 Dans quelle mesure le mot de passe de Navicat est-il sécurisé?
Apr 08, 2025 pm 09:24 PM
Dans quelle mesure le mot de passe de Navicat est-il sécurisé?
Apr 08, 2025 pm 09:24 PM
La sécurité du mot de passe de Navicat repose sur la combinaison de cryptage symétrique, de force de mot de passe et de mesures de sécurité. Des mesures spécifiques incluent: l'utilisation de connexions SSL (à condition que le serveur de base de données prenne en charge et configure correctement le certificat), à la mise à jour régulièrement de NAVICAT, en utilisant des méthodes plus sécurisées (telles que les tunnels SSH), en restreignant les droits d'accès et, surtout, à ne jamais enregistrer de mots de passe.
