
 Périphériques technologiques
IA
Le code source de 25 agents IA est désormais public, inspiré de « Virtual Town » et de « Westworld » de Stanford
Périphériques technologiques
IA
Le code source de 25 agents IA est désormais public, inspiré de « Virtual Town » et de « Westworld » de Stanford
Le code source de 25 agents IA est désormais public, inspiré de « Virtual Town » et de « Westworld » de Stanford

Le public qui connaît "Westworld" sait que ce spectacle se déroule dans un immense parc à thème pour adultes de haute technologie dans le monde futur. Les robots ont des capacités comportementales similaires à celles des humains, et peuvent se souvenir de ce qu'ils voient et entendent, et le répéter. histoire principale. Chaque jour, ces robots seront réinitialisés et ramenés à leur état initial
Après la publication de l'article de Stanford "Generative Agents: Interactive Simulacra of Human Behaviour", ce scénario ne se limite plus aux films et séries télévisées, l'IA a l'a reproduit avec succès Aperçu de cette scène
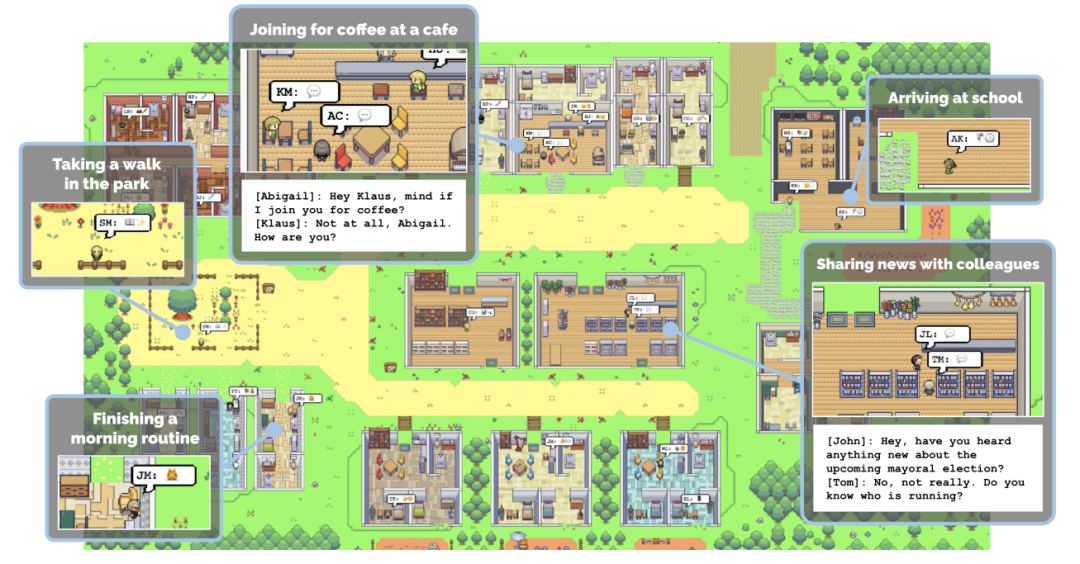 La "ville virtuelle" de Smallville
La "ville virtuelle" de Smallville
- Adresse papier : https://arxiv.org/pdf/2304.03442v1.pdf
- Adresse du projet : https:// github.com/joonspk-research/generative_agents
Les chercheurs ont réussi à créer une ville virtuelle appelée Smallville, avec 25 agents d'IA. Ils vivent dans la ville, ont un emploi, échangent des potins et participent Socialiser, se faire de nouveaux amis. , ou même organiser une fête pour la Saint-Valentin. Chaque habitant de la ville a une personnalité et une histoire uniques
Afin d'augmenter le réalisme des « habitants de la ville », la ville de Smallville propose plusieurs scènes publiques, telles que des cafés, des bars, des parcs, des écoles, des dortoirs, des maisons et des magasins. À Smallville, les habitants peuvent se déplacer librement entre ces lieux, interagir avec d'autres résidents et même se saluer
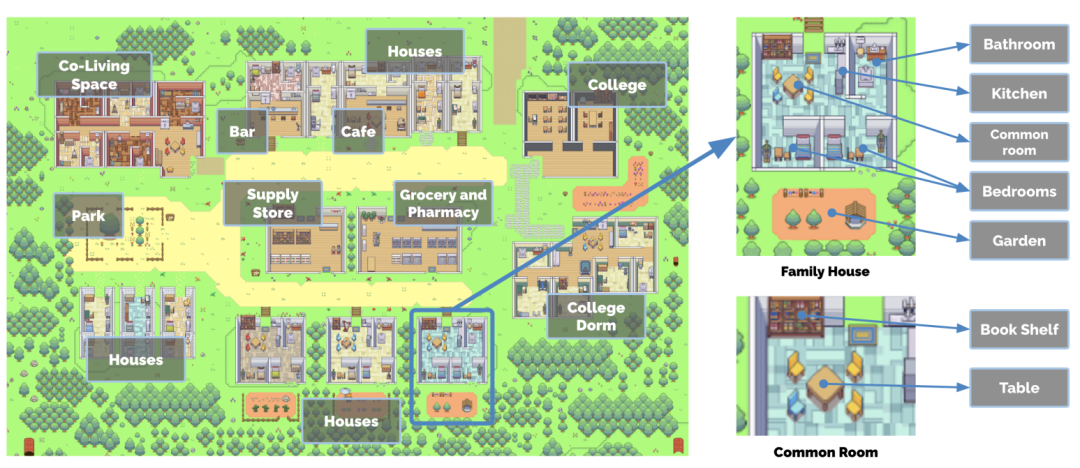
Des scènes où les « résidents de la ville » peuvent aller et venir à volonté
Comment les habitants du la ville se comporte-t-elle comme les humains ? Par exemple, lorsqu'ils voient le petit-déjeuner en feu, ils prennent l'initiative d'aller éteindre la cuisinière ; lorsqu'ils trouvent quelqu'un dans la salle de bain, ils attendent dehors lorsqu'ils rencontrent quelqu'un à qui ils veulent parler, ils s'arrêtent ; et discuter...
Désolé Malheureusement, cette recherche n'a pas été rendue publique à l'époque et plus d'informations ne pouvaient être obtenues que par le biais d'articles publiés. Cependant, avec le temps, les chercheurs ont rendu cette recherche open source
Cette nouvelle a également été confirmée par Joon Sung Park, doctorant à Stanford et l'un des auteurs de l'article

Avec L'open source du projet devrait avoir un large impact sur l'industrie du jeu et répondre aux attentes des internautes. Les jeux informatiques du futur pourraient présenter une ville virtuelle où chaque résident a une vie, un travail et des passe-temps indépendants, permettant aux joueurs d'interagir avec eux de manière réaliste

"Je crois que cette étude marque le début du début d'AGI. Bien que nous il y a encore beaucoup de travail à faire, c'est la bonne voie Enfin, l'open source

Les internautes espèrent également appliquer cette recherche au jeu vidéo "Les Sims". , certains s'inquiètent. Nous savons tous que la création d'agents d'IA nécessite de s'appuyer sur de grands modèles, mais nous devons considérer un problème : le LLM est progressivement « apprivoisé » par les humains, il ne peut donc pas refléter pleinement les émotions et les comportements réels des humains, et ne peut montrer que les comportements que les humains pensent. sont bons et les comportements comme la colère, le crime, l'inégalité, la jalousie, la violence, etc. seront considérablement affaiblis. Par conséquent, il est difficile pour les agents d'IA de reproduire complètement la vraie vie humaine

En tout cas, les gens sont toujours passionnés par l'open source de Smallville
En plus de la « ville virtuelle » open source Smallville de Stanford, nous aimerions également lister quelques autres agents IA
La start-up Fable utilise des agents IA pour réaliser l'écriture de scénarios, l'animation, la réalisation, le montage et d'autres processus de production entièrement par l'IA. , a filmé avec succès un épisode de "South Park"
L'agent NVIDIA AI Voyager est connecté à GPT-4 et peut jouer à "Minecraft" sans intervention humaine.

L'agent d'IA généraliste Ghost in the Minecraft (GITM) développé conjointement par SenseTime, l'Université Tsinghua et d'autres institutions a démontré des performances exceptionnelles dans Minecraft qui surpassent tous les agents précédents et a considérablement réduit le coût de formation
Depuis il y a d'autres études, nous ne pouvons pas toutes les énumérer. Avec l'open source de Stanford Virtual Town, nous pensons que davantage d'entreprises et d'institutions rejoindront les rangs
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Dix outils d'annotation de texte gratuits open source recommandés
Mar 26, 2024 pm 08:20 PM
Dix outils d'annotation de texte gratuits open source recommandés
Mar 26, 2024 pm 08:20 PM
L'annotation de texte est le travail d'étiquettes ou de balises correspondant à un contenu spécifique dans le texte. Son objectif principal est d’apporter des informations complémentaires au texte pour une analyse et un traitement plus approfondis, notamment dans le domaine de l’intelligence artificielle. L'annotation de texte est cruciale pour les tâches d'apprentissage automatique supervisées dans les applications d'intelligence artificielle. Il est utilisé pour entraîner des modèles d'IA afin de mieux comprendre les informations textuelles en langage naturel et d'améliorer les performances de tâches telles que la classification de texte, l'analyse des sentiments et la traduction linguistique. Grâce à l'annotation de texte, nous pouvons apprendre aux modèles d'IA à reconnaître les entités dans le texte, à comprendre le contexte et à faire des prédictions précises lorsque de nouvelles données similaires apparaissent. Cet article recommande principalement de meilleurs outils d'annotation de texte open source. 1.LabelStudiohttps://github.com/Hu
 15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
L'annotation d'images est le processus consistant à associer des étiquettes ou des informations descriptives à des images pour donner une signification et une explication plus profondes au contenu de l'image. Ce processus est essentiel à l’apprentissage automatique, qui permet d’entraîner les modèles de vision à identifier plus précisément les éléments individuels des images. En ajoutant des annotations aux images, l'ordinateur peut comprendre la sémantique et le contexte derrière les images, améliorant ainsi la capacité de comprendre et d'analyser le contenu de l'image. L'annotation d'images a un large éventail d'applications, couvrant de nombreux domaines, tels que la vision par ordinateur, le traitement du langage naturel et les modèles de vision graphique. Elle a un large éventail d'applications, telles que l'assistance aux véhicules pour identifier les obstacles sur la route, en aidant à la détection. et le diagnostic des maladies grâce à la reconnaissance d'images médicales. Cet article recommande principalement de meilleurs outils d'annotation d'images open source et gratuits. 1.Makesens
 Recommandé : Excellent projet de détection et de reconnaissance des visages open source JS
Apr 03, 2024 am 11:55 AM
Recommandé : Excellent projet de détection et de reconnaissance des visages open source JS
Apr 03, 2024 am 11:55 AM
La technologie de détection et de reconnaissance des visages est déjà une technologie relativement mature et largement utilisée. Actuellement, le langage d'application Internet le plus utilisé est JS. La mise en œuvre de la détection et de la reconnaissance faciale sur le front-end Web présente des avantages et des inconvénients par rapport à la reconnaissance faciale back-end. Les avantages incluent la réduction de l'interaction réseau et de la reconnaissance en temps réel, ce qui réduit considérablement le temps d'attente des utilisateurs et améliore l'expérience utilisateur. Les inconvénients sont les suivants : il est limité par la taille du modèle et la précision est également limitée ; Comment utiliser js pour implémenter la détection de visage sur le web ? Afin de mettre en œuvre la reconnaissance faciale sur le Web, vous devez être familier avec les langages et technologies de programmation associés, tels que JavaScript, HTML, CSS, WebRTC, etc. Dans le même temps, vous devez également maîtriser les technologies pertinentes de vision par ordinateur et d’intelligence artificielle. Il convient de noter qu'en raison de la conception du côté Web
 Le document multimodal Alibaba 7B comprenant le grand modèle remporte le nouveau SOTA
Apr 02, 2024 am 11:31 AM
Le document multimodal Alibaba 7B comprenant le grand modèle remporte le nouveau SOTA
Apr 02, 2024 am 11:31 AM
Nouveau SOTA pour des capacités de compréhension de documents multimodaux ! L'équipe Alibaba mPLUG a publié le dernier travail open source mPLUG-DocOwl1.5, qui propose une série de solutions pour relever les quatre défis majeurs que sont la reconnaissance de texte d'image haute résolution, la compréhension générale de la structure des documents, le suivi des instructions et l'introduction de connaissances externes. Sans plus tarder, examinons d’abord les effets. Reconnaissance et conversion en un clic de graphiques aux structures complexes au format Markdown : Des graphiques de différents styles sont disponibles : Une reconnaissance et un positionnement de texte plus détaillés peuvent également être facilement traités : Des explications détaillées sur la compréhension du document peuvent également être données : Vous savez, « Compréhension du document " est actuellement un scénario important pour la mise en œuvre de grands modèles linguistiques. Il existe de nombreux produits sur le marché pour aider à la lecture de documents. Certains d'entre eux utilisent principalement des systèmes OCR pour la reconnaissance de texte et coopèrent avec LLM pour le traitement de texte.
 Fraichement publié! Un modèle open source pour générer des images de style anime en un seul clic
Apr 08, 2024 pm 06:01 PM
Fraichement publié! Un modèle open source pour générer des images de style anime en un seul clic
Apr 08, 2024 pm 06:01 PM
Permettez-moi de vous présenter le dernier projet open source AIGC-AnimagineXL3.1. Ce projet est la dernière itération du modèle texte-image sur le thème de l'anime, visant à offrir aux utilisateurs une expérience de génération d'images d'anime plus optimisée et plus puissante. Dans AnimagineXL3.1, l'équipe de développement s'est concentrée sur l'optimisation de plusieurs aspects clés pour garantir que le modèle atteigne de nouveaux sommets en termes de performances et de fonctionnalités. Premièrement, ils ont élargi les données d’entraînement pour inclure non seulement les données des personnages du jeu des versions précédentes, mais également les données de nombreuses autres séries animées bien connues dans l’ensemble d’entraînement. Cette décision enrichit la base de connaissances du modèle, lui permettant de mieux comprendre les différents styles et personnages d'anime. AnimagineXL3.1 introduit un nouvel ensemble de balises et d'esthétiques spéciales
 Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Le FP8 et la précision de quantification inférieure en virgule flottante ne sont plus le « brevet » du H100 ! Lao Huang voulait que tout le monde utilise INT8/INT4, et l'équipe Microsoft DeepSpeed a commencé à exécuter FP6 sur A100 sans le soutien officiel de NVIDIA. Les résultats des tests montrent que la quantification FP6 de la nouvelle méthode TC-FPx sur A100 est proche ou parfois plus rapide que celle de INT4, et a une précision supérieure à celle de cette dernière. En plus de cela, il existe également une prise en charge de bout en bout des grands modèles, qui ont été open source et intégrés dans des cadres d'inférence d'apprentissage profond tels que DeepSpeed. Ce résultat a également un effet immédiat sur l'accélération des grands modèles : dans ce cadre, en utilisant une seule carte pour exécuter Llama, le débit est 2,65 fois supérieur à celui des cartes doubles. un
 1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
Adresse papier : https://arxiv.org/abs/2307.09283 Adresse code : https://github.com/THU-MIG/RepViTRepViT fonctionne bien dans l'architecture ViT mobile et présente des avantages significatifs. Ensuite, nous explorons les contributions de cette étude. Il est mentionné dans l'article que les ViT légers fonctionnent généralement mieux que les CNN légers sur les tâches visuelles, principalement en raison de leur module d'auto-attention multi-têtes (MSHA) qui permet au modèle d'apprendre des représentations globales. Cependant, les différences architecturales entre les ViT légers et les CNN légers n'ont pas été entièrement étudiées. Dans cette étude, les auteurs ont intégré des ViT légers dans le système efficace.
 Les indicateurs du MoE open source national explosent : capacités de niveau GPT-4, le prix de l'API n'est que de 1 %
May 07, 2024 pm 05:34 PM
Les indicateurs du MoE open source national explosent : capacités de niveau GPT-4, le prix de l'API n'est que de 1 %
May 07, 2024 pm 05:34 PM
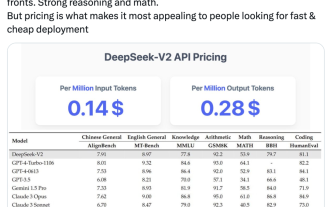
Le dernier modèle open source national à grande échelle du MoE est devenu populaire juste après ses débuts. Les performances de DeepSeek-V2 atteignent le niveau GPT-4, mais il est open source, gratuit pour un usage commercial et le prix de l'API ne représente que 1 % de celui de GPT-4-Turbo. Par conséquent, dès sa sortie, il a immédiatement déclenché de nombreuses discussions. À en juger par les indicateurs de performance publiés, les capacités chinoises complètes de DeepSeekV2 dépassent celles de nombreux modèles open source. Dans le même temps, les modèles fermés tels que GPT-4Turbo et Wenkuai 4.0 sont également au premier échelon. La maîtrise complète de l'anglais se situe également au même premier échelon que LLaMA3-70B et surpasse Mixtral8x22B, qui est également un MoE. Il montre également de bonnes performances en connaissances, mathématiques, raisonnement, programmation, etc. Et prend en charge le contexte 128K. Imaginez ceci
