
 développement back-end
Tutoriel Python
Dix principaux algorithmes de tri que les programmeurs doivent maîtriser (Partie 1)
développement back-end
Tutoriel Python
Dix principaux algorithmes de tri que les programmeurs doivent maîtriser (Partie 1)
Dix principaux algorithmes de tri que les programmeurs doivent maîtriser (Partie 1)

algorithme de tri On peut dire que chaque programmeur doit le maîtriser Il est nécessaire de comprendre leurs principes et leur mise en œuvre Ce qui suit est une introduction à l'implémentation python des dix principaux algorithmes de tri couramment utilisés pour faciliter votre apprentissage.
01 Tri à bulles - Tri par échange
02 Tri rapide - Tri par échange
03 Tri par sélection - Tri par sélection
04 Tri par tas - tri par sélection
05 Tri par insertion - tri par insertion
06 Tri par colline - tri par insertion
07 Tri par fusion - Tri par fusion
08 Tri comptage - tri distribution
09 Tri Radix - tri distribution
10 Tri seau - tri distribution
Comparez les éléments adjacents. Si le premier est plus grand que le second, échangez-les tous les deux.
Faites de même pour chaque paire d'éléments adjacents, en commençant par la première paire au début et en terminant par la dernière paire à la fin. À ce stade, le dernier élément doit être le plus grand nombre.
Répétez les étapes ci-dessus pour tous les éléments sauf le dernier.
Continuez à répéter les étapes ci-dessus pour de moins en moins d'éléments à chaque fois jusqu'à ce qu'il n'y ait plus de paires de nombres à comparer.
'''冒泡排序'''
def Bubble_Sort(arr):
for i in range(1, len(arr)):
for j in range(0, len(arr)-i):
if arr[j] > arr[j+1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
return arr
arr = [29, 63, 41, 5, 62, 66, 57, 34, 94, 22]
result = Bubble_Sort(arr)
print('result list: ', result)
# result list: [5, 22, 29, 34, 41, 57, 62, 63, 66, 94]Concentrez les données supérieures ou égales à la valeur seuil sur le côté droit du tableau et les données plus petites que la valeur seuil sur le côté gauche du tableau. À ce stade, chaque élément de la partie gauche est inférieur ou égal à la valeur de division, et chaque élément de la partie droite est supérieur ou égal à la valeur de division.
Ensuite, les données de gauche et de droite peuvent être triées indépendamment. Pour les données du tableau de gauche, vous pouvez prendre une valeur de division et diviser cette partie des données en parties gauche et droite. De même, placez la plus petite valeur à gauche et la plus grande valeur à droite. Les données du tableau à droite peuvent également être traitées de la même manière.
Répétez le processus ci-dessus jusqu'à ce que le tri des données des parties gauche et droite soit terminé.
'''快速排序'''
def Quick_Sort(arr):
# 递归入口及出口
if len(arr) >= 2:
# 选取基准值,也可以选取第一个或最后一个元素
mid = arr[len(arr) // 2]
# 定义基准值左右两侧的列表
left, right = [], []
# 从原始数组中移除基准值
arr.remove(mid)
for num in arr:
if num >= mid:
right.append(num)
else:
left.append(num)
return Quick_Sort(left) + [mid] + Quick_Sort(right)
else:
return arr
arr = [27, 70, 34, 65, 9, 22, 47, 68, 21, 18]
result = Quick_Sort(arr)
print('result list: ', result)
# result list: [9, 18, 21, 22, 27, 34, 47, 65, 68, 70]et ainsi de suite jusqu'à ce que tous les éléments soient triés.
'''选择排序'''
def Selection_Sort(arr):
for i in range(len(arr) - 1):
# 记录最小数的索引
minIndex = i
for j in range(i + 1, len(arr)):
if arr[j] < arr[minIndex]:
minIndex = j
# i 不是最小数时,将 i 和最小数进行交换
if i != minIndex:
arr[i], arr[minIndex] = arr[minIndex], arr[i]
return arr
arr = [5, 10, 76, 55, 13, 79, 49, 51, 65, 30]
result = Quick_Sort(arr)
print('result list: ', result)
# result list: [5, 10, 13, 30, 49, 51, 55, 65, 76, 79]将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。
'''插入排序'''
def Insertion_Sort(arr):
for i in range(1, len(arr)):
key = arr[i]
j = i - 1
while j >= 0 and key < arr[j]:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
return arr
arr = [31, 80, 42, 47, 35, 26, 10, 5, 51, 53]
result = Insertion_Sort(arr)
print('result list: ', result)
# result list: [5, 10, 26, 31, 35, 42, 47, 51, 53, 80]创建一个堆 H[0……n-1];
把堆首(最大值)和堆尾互换;
把堆的尺寸缩小 1,并调用 shift_down(0),目的是把新的数组顶端数据调整到相应位置;
重复步骤 2,直到堆的尺寸为 1。
'''堆排序'''
def Heapify(arr, n, i):
largest = i
# 左右节点分块
left = 2 * i + 1
right = 2 * i + 2
if left < n and arr[i] < arr[left]:
largest = left
if right < n and arr[largest] < arr[right]:
largest = right
if largest != i:
# 大小值交换
arr[i], arr[largest] = arr[largest], arr[i]
# 递归
Heapify(arr, n, largest)
def Heap_Sort(arr):
nlen = len(arr)
for i in range(nlen, -1, -1):
# 调整节点
Heapify(arr, nlen, i)
for i in range(nlen - 1, 0, -1):
arr[i], arr[0] = arr[0], arr[i]
# 调整节点
Heapify(arr, i, 0)
return arr
arr = [26, 53, 83, 86, 5, 46, 72, 21, 4, 75]
result = Heap_Sort(arr)
print('result list: ', result)
# result list: [4, 5, 21, 26, 46, 53, 72, 75, 83, 86]Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Problèmes complexes de conception expérimentale sur le marché biface de Kuaishou
Apr 15, 2023 pm 07:40 PM
Problèmes complexes de conception expérimentale sur le marché biface de Kuaishou
Apr 15, 2023 pm 07:40 PM
1. Contexte du problème 1. Introduction à l'expérience du marché biface Le marché biface, c'est-à-dire une plateforme, comprend deux participants, producteurs et consommateurs, et les deux parties se promeuvent mutuellement. Par exemple, Kuaishou a un producteur vidéo et un consommateur vidéo, et les deux identités peuvent se chevaucher dans une certaine mesure. L'expérimentation bilatérale est une méthode expérimentale qui combine des groupes du côté des producteurs et des consommateurs. Les expériences bilatérales présentent les avantages suivants : (1) L'impact de la nouvelle stratégie sur deux aspects peut être détecté simultanément, tels que les changements dans le DAU du produit et le nombre de personnes téléchargeant des œuvres. Les plateformes bilatérales ont souvent des effets de réseau transversaux. Plus il y a de lecteurs, plus les auteurs seront actifs, et plus les auteurs seront actifs, plus les lecteurs suivront. (2) Le débordement et le transfert d'effet peuvent être détectés. (3) Aidez-nous à mieux comprendre le mécanisme d'action. L'expérience AB elle-même ne peut pas nous dire la relation entre la cause et l'effet, seulement.
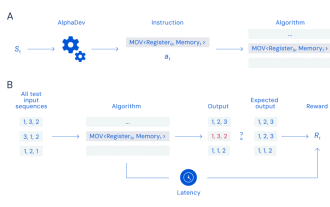 Google utilise l'IA pour briser le sceau de dix ans de l'algorithme de tri. Elle est exécutée des milliards de fois chaque jour, mais les internautes disent que c'est la recherche la plus irréaliste ?
Jun 22, 2023 pm 09:18 PM
Google utilise l'IA pour briser le sceau de dix ans de l'algorithme de tri. Elle est exécutée des milliards de fois chaque jour, mais les internautes disent que c'est la recherche la plus irréaliste ?
Jun 22, 2023 pm 09:18 PM
Tri | Nuka-Cola, Chu Xingjuan Les amis qui ont suivi des cours d'informatique de base doivent avoir personnellement conçu un algorithme de tri, c'est-à-dire utiliser du code pour réorganiser les éléments d'une liste non ordonnée par ordre croissant ou décroissant. C'est un défi intéressant, et il existe de nombreuses façons possibles de le relever. Beaucoup de temps a été investi pour trouver comment accomplir les tâches de tri plus efficacement. En tant qu'opération de base, les algorithmes de tri sont intégrés aux bibliothèques standard de la plupart des langages de programmation. Il existe de nombreuses techniques et algorithmes de tri différents utilisés dans les bases de code du monde entier pour organiser de grandes quantités de données en ligne, mais au moins en ce qui concerne les bibliothèques C++ utilisées avec le compilateur LLVM, le code de tri n'a pas changé depuis plus d'une décennie. . Récemment, l'équipe Google DeepMindAI a développé un
 Comment filtrer et trier les données dans le développement de la technologie Vue
Oct 09, 2023 pm 01:25 PM
Comment filtrer et trier les données dans le développement de la technologie Vue
Oct 09, 2023 pm 01:25 PM
Comment filtrer et trier les données dans le développement de la technologie Vue Dans le développement de la technologie Vue, le filtrage et le tri des données sont des fonctions très courantes et importantes. Grâce au filtrage et au tri des données, nous pouvons rapidement interroger et afficher les informations dont nous avons besoin, améliorant ainsi l'expérience utilisateur. Cet article expliquera comment filtrer et trier les données dans Vue et fournira des exemples de code spécifiques pour aider les lecteurs à mieux comprendre et utiliser ces fonctions. 1. Filtrage des données Le filtrage des données fait référence au filtrage des données qui répondent aux exigences en fonction de conditions spécifiques. Dans Vue, on peut passer comp
 Comment implémenter l'algorithme de tri par sélection en C#
Sep 20, 2023 pm 01:33 PM
Comment implémenter l'algorithme de tri par sélection en C#
Sep 20, 2023 pm 01:33 PM
Comment implémenter l'algorithme de tri par sélection en C# Le tri par sélection (SelectionSort) est un algorithme de tri simple et intuitif. Son idée de base est de sélectionner à chaque fois l'élément le plus petit (ou le plus grand) parmi les éléments à trier et de le placer à la fin de. la séquence triée. Répétez ce processus jusqu'à ce que tous les éléments soient triés. Apprenons-en davantage sur la façon d'implémenter l'algorithme de tri par sélection en C#, ainsi que des exemples de code spécifiques. Création d'une méthode de tri par sélection Tout d'abord, nous devons créer une méthode pour implémenter le tri par sélection. Cette méthode accepte un
 Quels sont les algorithmes de tri des tableaux ?
Jun 02, 2024 pm 10:33 PM
Quels sont les algorithmes de tri des tableaux ?
Jun 02, 2024 pm 10:33 PM
Les algorithmes de tri de tableaux sont utilisés pour organiser les éléments dans un ordre spécifique. Les types courants d'algorithmes incluent : Tri à bulles : échangez les positions en comparant les éléments adjacents. Tri par sélection : recherchez le plus petit élément et remplacez-le par la position actuelle. Tri par insertion : insérez les éléments un par un à la bonne position. Tri rapide : méthode diviser pour mieux régner, sélectionnez l'élément pivot pour diviser le tableau. Tri par fusion : diviser pour mieux régner, tri récursif et fusion de sous-tableaux.
 Swoole Advanced : Comment utiliser le multithreading pour implémenter un algorithme de tri à grande vitesse
Jun 14, 2023 pm 09:16 PM
Swoole Advanced : Comment utiliser le multithreading pour implémenter un algorithme de tri à grande vitesse
Jun 14, 2023 pm 09:16 PM
Swoole est un framework de communication réseau hautes performances basé sur le langage PHP. Il prend en charge la mise en œuvre de plusieurs modes IO asynchrones et de plusieurs protocoles réseau avancés. Sur la base de Swoole, nous pouvons utiliser sa fonction multi-threading pour implémenter des opérations algorithmiques efficaces, telles que des algorithmes de tri à grande vitesse. L'algorithme de tri à grande vitesse (QuickSort) est un algorithme de tri courant. En localisant un élément de référence, les éléments sont divisés en deux sous-séquences. Celles plus petites que l'élément de référence sont placées à gauche et celles supérieures ou égales à la référence. L'élément est placé à droite. Ensuite, les sous-séquences gauche et droite sont placées par récursion.
 Comment utiliser l'algorithme de tri par base en C++
Sep 19, 2023 pm 12:15 PM
Comment utiliser l'algorithme de tri par base en C++
Sep 19, 2023 pm 12:15 PM
Comment utiliser l'algorithme de tri par base en C++ L'algorithme de tri par base est un algorithme de tri non comparatif qui termine le tri en divisant les éléments à trier en un ensemble limité de chiffres. En C++, nous pouvons utiliser l’algorithme de tri par base pour trier un ensemble d’entiers. Ci-dessous, nous verrons en détail comment implémenter l'algorithme de tri par base, avec des exemples de code spécifiques. Idée d'algorithme L'idée de l'algorithme de tri par base est de diviser les éléments à trier en un ensemble limité de bits numériques, puis de trier les éléments sur chaque bit tour à tour. Le tri sur chaque bit est terminé
 Comment implémenter une fonction d'algorithme de tri simple à l'aide de MySQL et Java
Sep 20, 2023 am 09:45 AM
Comment implémenter une fonction d'algorithme de tri simple à l'aide de MySQL et Java
Sep 20, 2023 am 09:45 AM
Comment utiliser MySQL et Java pour implémenter une fonction d'algorithme de tri simple Introduction : Dans le développement de logiciels, les algorithmes de tri sont l'une des fonctions les plus basiques et les plus couramment utilisées. Cet article expliquera comment utiliser MySQL et Java pour implémenter une fonction d'algorithme de tri simple et fournira des exemples de code spécifiques. 1. Présentation des algorithmes de tri Les algorithmes de tri sont des algorithmes qui organisent un ensemble de données selon des règles spécifiques. Les algorithmes de tri couramment utilisés incluent le tri à bulles, le tri par insertion, le tri par sélection, le tri rapide, etc. Cet article utilisera le tri à bulles comme exemple pour l'expliquer et le mettre en œuvre. 2.M
