

Spring Boot+MyBatis+Atomikos+MySQL (avec code source)
Dans les projets réels, nous essayons d'éviter les transactions distribuées. Cependant, il est parfois vraiment nécessaire de procéder à un fractionnement des services, ce qui entraînera des problèmes de transactions distribuées.
Dans le même temps, des transactions distribuées sont également demandées sur le marché lors des entretiens. Vous pouvez vous entraîner avec ce cas et vous pouvez parler 123 lors de l'entretien.
Voici une châtaigne commerciale : lorsqu'un utilisateur reçoit un coupon, le nombre de fois où l'utilisateur reçoit le coupon doit être déduit, puis un enregistrement de l'utilisateur recevant le coupon est enregistré.
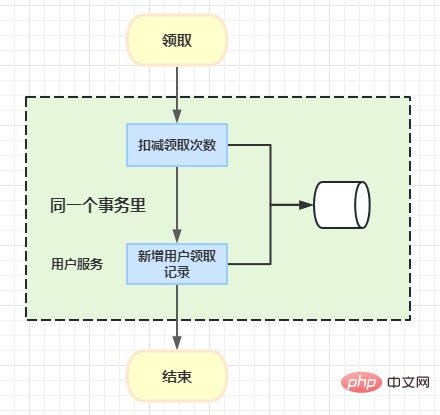
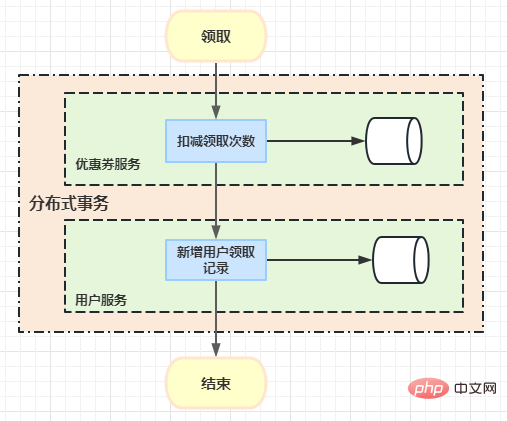
À l'origine, vous pouvez utiliser la méthode de file d'attente de messages ici et utiliser asynchrone pour ajouter des enregistrements de collection d'utilisateurs. Cependant, l'exigence ici est que les utilisateurs doivent pouvoir consulter leurs enregistrements de collecte immédiatement après les avoir reçus, nous avons donc introduit Atomikos ici pour implémenter les problèmes de transactions distribuées.
Transactions distribuées
Les transactions distribuées sont des transactions qui s'étendent sur plusieurs ordinateurs ou bases de données, et il peut y avoir des retards, des pannes ou des incohérences réseau entre ces ordinateurs ou bases de données. Les transactions distribuées doivent garantir l'atomicité, la cohérence, l'isolement et la durabilité de toutes les opérations afin de garantir l'exactitude et l'intégrité des données.
Quels sont les protocoles de transactions distribuées ?
Il existe deux principaux types de protocoles de transaction distribués : 2PC (Two-Phase Commit) et 3PC (Three-Phase Commit).
2PC est actuellement le protocole de transaction distribué le plus couramment utilisé, et son processus est divisé en deux étapes : l'étape de préparation et l'étape de soumission. Au cours de la phase de préparation, le coordinateur de transactions envoie des demandes de préparation à tous les participants, et les participants exécutent des transactions locales à l'état de préparation et renvoient les résultats de préparation au coordinateur de transactions. Lors de la phase de validation, si tous les participants s'exécutent avec succès, le coordinateur de transaction émet une demande de validation à tous les participants et les participants valident la transaction locale. Sinon, le coordinateur de transaction émet une demande d'annulation à tous les participants et les participants annulent la transaction locale. transaction.
3PC est une version améliorée de 2PC, qui ajoute une étape de préparation et de soumission basée sur 2PC. Dans la phase de préparation à la soumission, le coordinateur demande aux participants s'ils peuvent soumettre. Si le participant renvoie son consentement, celui-ci sera soumis directement lors de la phase de soumission, sinon il sera annulé lors de la phase de soumission.
Quelles sont les solutions courantes pour les transactions distribuées ?
Les solutions de mise en œuvre de solutions de transactions distribuées comprennent :
Solutions de transactions distribuées basées sur des files d'attente de messages (telles que la solution open source de RocketMQ) Solutions de transactions distribuées basées sur des cadres de transactions distribuées (tels que Seata, TCC -Transaction et autres frameworks) Solutions de transactions distribuées basées sur le protocole XA (comme JTA, etc.) -
Solutions de transactions distribuées basées sur une cohérence éventuelle des messages fiables (comme le middleware de transactions distribuées GTS d'Alibaba) Distribué solution de transaction basée sur le principe CAP (comme le mode de sourcing d'événements dans l'architecture CQRS)
Qu'est-ce que JTA ?
JTA (Java Transaction API) est la spécification de l'interface de programmation de J2EE. C'est l'implémentation JAVA du protocole XA. Il définit principalement :
Une interface de gestionnaire de transactions javax.transaction .TransactionManager, définit les opérations de démarrage, de validation, de retrait, etc. de la transaction. javax.transaction.TransactionManager,定义了有关事务的开始、提交、撤回等>操作。
一个满足XA规范的资源定义接口javax.transaction.xa.XAResource,一种资源如果要支持JTA事务,就需要让它的资源实现该XAResource
, si une ressource souhaite prendre en charge les transactions JTA, ses ressources doivent implémenter le <code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right: 2px;marge gauche : 2px;couleur d'arrière-plan : rgba(27, 31, 35, 0,05);famille de polices : " operator mono consolas monaco menlo monospace de mot couleur break-all rgb>XAResource et implémente l'interface liée à la soumission en deux phases définie par cette interface.
Si nous avons une application qui utilise l'interface JTA pour implémenter les transactions, lorsque l'application est en cours d'exécution, elle a besoin d'un conteneur qui implémente JTA. Généralement, il s'agit d'un conteneur J2EE, tel que JBoss, Websphere et d'autres serveurs d'applications. Cependant, il existe également des frameworks indépendants qui implémentent JTA. Par exemple, Atomikos et bitronix fournissent tous des frameworks d'implémentation JTA sous la forme de packages jar. De cette manière, nous pouvons exécuter des systèmes d'application qui utilisent JTA pour implémenter des transactions sur des serveurs tels que Tomcat ou Jetty. 🎜Comme mentionné ci-dessus dans la différence entre les transactions locales et les transactions externes, les transactions JTA sont des transactions externes et peuvent être utilisées pour implémenter la transactionnalité sur plusieurs ressources. C'est exactement ce qu'il fait avec chaque ressource XAResource来进行两阶段提交的控制。感兴趣的同学可以看看这个接口的方法,除了commit, rollback等方法以外,还有end(), forget(), isSameRM(), prepare() et plus encore. À partir de ces seules interfaces, vous pouvez imaginer la complexité de JTA dans la mise en œuvre de transactions en deux phases.
Qu'est-ce que XA ?
XA est une architecture (ou protocole) de transactions distribuées proposée par l'organisation X/Open. L'architecture XA définit principalement l'interface entre le Transaction Manager (global) et le Resource Manager (local). L'interface XA est une interface système bidirectionnelle qui forme un pont de communication entre le Transaction Manager et un ou plusieurs Resource Managers. En d'autres termes, dans une transaction basée sur XA, nous pouvons effectuer une gestion des transactions sur plusieurs ressources. Par exemple, un système accède à plusieurs bases de données, ou accède à la fois aux bases de données et aux ressources telles que le middleware de messages. De cette manière, nous pouvons directement implémenter toutes les transactions soumises ou annulées dans plusieurs bases de données et middleware de messages. La spécification XA n'est pas une spécification Java, mais une spécification universelle. Actuellement, diverses bases de données et de nombreux middlewares de messages prennent en charge la spécification XA.
JTA est une spécification pour le développement Java qui répond à la spécification XA. Par conséquent, lorsque nous disons que nous utilisons JTA pour implémenter des transactions distribuées, nous entendons en fait utiliser les spécifications JTA pour implémenter des transactions avec plusieurs bases de données, middleware de messages et autres ressources du système.
Qu'est-ce qu'Atomikos
Atomikos est un gestionnaire de transactions open source très populaire et peut être intégré à votre application Spring Boot. Le serveur d'applications Tomcat n'implémente pas la spécification JTA. Lorsque vous utilisez Tomcat comme serveur d'applications, vous devez utiliser une classe de gestionnaire de transactions tierce comme gestionnaire de transactions global, et le framework Atomikos le fait, en intégrant la gestion des transactions dans l'application. Ne dépend pas du serveur d'applications.
Spring Boot intègre Atomikos
Ça ne sert à rien de parler d'un tas de théories, montre-moi le code.
Pile technologique : Spring Boot+MyBatis+Atomikos+MySQL
Si vous suivez le code de cet article, faites attention à votre version MySQL.
Construisez d'abord deux bases de données (my-db_0 et my-db_1), puis créez une table dans chaque base de données.
Dans la base de données my-db_0 :
CREATE TABLE `t_user_0` ( `id` bigint NOT NULL AUTO_INCREMENT, `user_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `age` int NOT NULL, `gender` int NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=21 DEFAULT CHARSET=utf8;
Dans la base de données my-db_1 :
CREATE TABLE `t_user_1` ( `id` bigint NOT NULL AUTO_INCREMENT, `user_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `age` int NOT NULL, `gender` int NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8;
Ceci est juste pour démontrer les transactions distribuées, ne vous inquiétez pas de la signification spécifique de la table. Structure globale du projet
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tian</groupId>
<artifactId>spring-boot-atomikos</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>
<name>spring-boot-atomikos</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- mybatis依赖 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- mysql依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
<!--分布式事务-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jta-atomikos</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 要使生成的jar可运行,需要加入此插件 -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
<resources>
<resource>
<directory>src/main/java</directory>
<excludes>
<exclude>**/*.java</exclude>
</excludes>
</resource>
<resource>
<!-- 编译xml文件 -->
<directory>src/main/resources</directory>
<includes>
<include>**/*.*</include>
</includes>
</resource>
</resources>
</build>
</project>Copier après la connexion
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tian</groupId>
<artifactId>spring-boot-atomikos</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>
<name>spring-boot-atomikos</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- mybatis依赖 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- mysql依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
<!--分布式事务-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jta-atomikos</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 要使生成的jar可运行,需要加入此插件 -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
<resources>
<resource>
<directory>src/main/java</directory>
<excludes>
<exclude>**/*.java</exclude>
</excludes>
</resource>
<resource>
<!-- 编译xml文件 -->
<directory>src/main/resources</directory>
<includes>
<include>**/*.*</include>
</includes>
</resource>
</resources>
</build>
</project>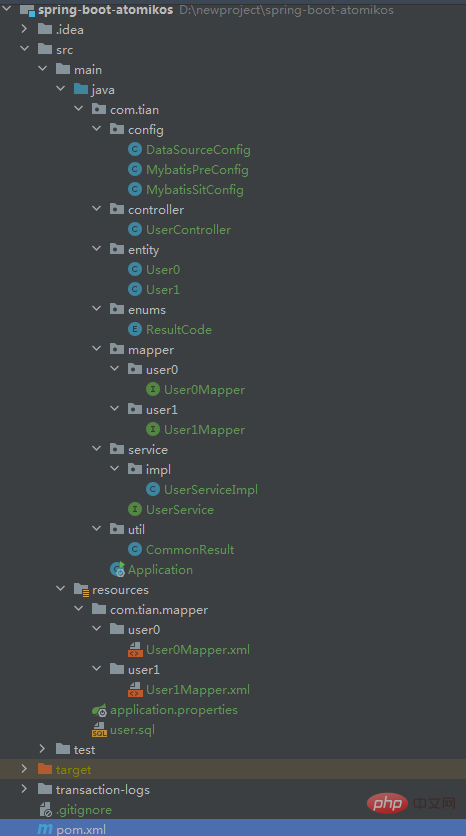 MyBatis Scan
MyBatis Scan server.port=9001 spring.application.name=atomikos-demo spring.datasource.user0.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.user0.url=jdbc:mysql://localhost:3306/my-db_0?characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true spring.datasource.user0.user=root spring.datasource.user0.password=123456 spring.datasource.user1.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.user1.url=jdbc:mysql://localhost:3306/my-db_1?characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true spring.datasource.user1.user=root spring.datasource.user1.password=123456 mybatis.mapperLocations=classpath:/com/tian/mapper/*/*.xml mybatis.typeAliasesPackage=com.tian.entity mybatis.configuration.cache-enabled=true
L'autre est fondamentalement le même, c'est-à-dire que le chemin d'analyse est modifié en : mapper.xml
L'autre est fondamentalement le même, et il est publié ici. L'interface du mappeur correspondante est également très simple. En voici une :
("classpath*:com/tian/mapper/user1/*.xml")service
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.tian.mapper.user0.User0Mapper">
<!-- -->
<cache eviction="LRU" flushInterval="10000" size="1024" />
<resultMap id="BaseResultMap" type="com.tian.entity.User0">
<id column="id" jdbcType="BIGINT" property="id" />
<result column="user_name" jdbcType="VARCHAR" property="userName" />
<result column="age" jdbcType="INTEGER" property="age" />
<result column="gender" jdbcType="INTEGER" property="gender" />
</resultMap>
<sql id="Base_Column_List">
id, user_name, age, gender
</sql>
<insert id="insert" parameterType="com.tian.entity.User0">
insert into t_user_0 (id, user_name,age, gender)
values (#{id,jdbcType=BIGINT}, #{userName,jdbcType=VARCHAR},#{age,jdbcType=INTEGER},#{gender,jdbcType=INTEGER})
</insert>
</mapper>controller
public interface User0Mapper {
int insert(User0 record);
}project startup class
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
La surveillance efficace des bases de données Redis est essentielle pour maintenir des performances optimales, identifier les goulots d'étranglement potentiels et assurer la fiabilité globale du système. Le service Redis Exporter est un utilitaire puissant conçu pour surveiller les bases de données Redis à l'aide de Prometheus. Ce didacticiel vous guidera à travers la configuration et la configuration complètes du service Redis Exportateur, en vous garantissant de créer des solutions de surveillance de manière transparente. En étudiant ce tutoriel, vous réaliserez les paramètres de surveillance entièrement opérationnels
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
