
 Java
javaDidacticiel
Spring Boot implémente la technologie de séparation lecture-écriture MySQL
Java
javaDidacticiel
Spring Boot implémente la technologie de séparation lecture-écriture MySQL
Spring Boot implémente la technologie de séparation lecture-écriture MySQL
Comment implémenter la séparation en lecture et en écriture, projet Spring Boot, la base de données est MySQL et la couche de persistance utilise MyBatis.
En fait, c'est très simple à mettre en œuvre. Réfléchissez d'abord à une question :
Dans les scénarios à haute concurrence, quelles sont les méthodes d'optimisation pour la base de données ?
Les méthodes d'implémentation suivantes sont couramment utilisées : séparation lecture-écriture, mise en cache, cluster d'architecture maître-esclave, sous-base de données et sous-table, etc.
Dans les applications Internet, la plupart lisent davantage et écrivent moins. Deux bibliothèques sont mises en place, la bibliothèque principale et la bibliothèque de lecture.
La bibliothèque principale est responsable de l'écriture et la bibliothèque esclave est principalement responsable de la lecture. Un cluster de bibliothèques de lecture peut être établi grâce à l'isolation des fonctions de lecture et d'écriture sur la source de données, dans le but de réduire les conflits de lecture et d'écriture. , il est possible de soulager la charge de la base de données et de protéger la base de données. En utilisation réelle, toute partie impliquant l'écriture est directement basculée vers la bibliothèque principale, et la partie lecture est directement basculée vers la bibliothèque de lecture. Il s'agit d'une technologie typique de séparation lecture-écriture.
Cet article se concentrera sur la séparation en lecture et en écriture et expliquera comment la mettre en œuvre.
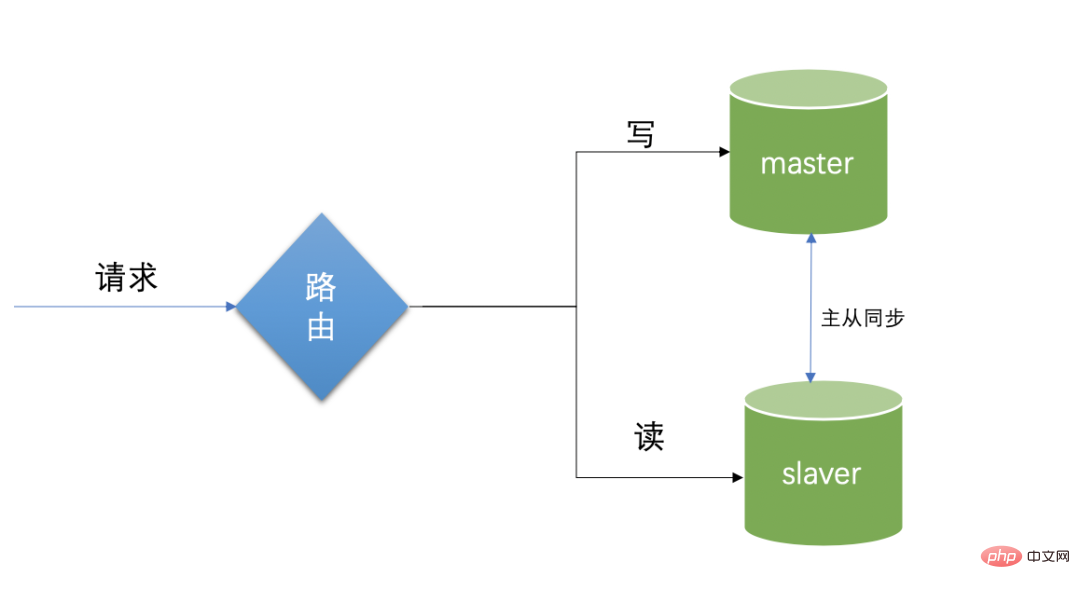
Limitations de la synchronisation maître-esclave : celle-ci est divisée en base de données maître et base de données esclave. La base de données maître et la base de données esclave maintiennent la cohérence de la structure de la base de données. La base de données maître est responsable de l'écriture. les données seront automatiquement synchronisées avec la base de données esclave. La base de données esclave est responsable de la lecture. Lorsqu'une demande de lecture arrive, les données sont lues directement à partir de la base de données de lecture et la base de données maître copie automatiquement les données dans la base de données esclave. Cependant, ce blog n'introduit pas cette partie des connaissances en configuration, car elle est davantage axée sur les travaux d'exploitation et de maintenance.
Il y a un problème ici :
Le problème de retard de la réplication maître-esclave. Lors de l'écriture dans la base de données principale, une demande de lecture arrive soudainement, et les données ne sont pas complètement synchronisées à ce moment, une demande de lecture apparaîtra. Les données ne peuvent pas être lues ou les données lues sont inférieures à la valeur d'origine. La solution spécifique la plus simple consiste à pointer temporairement la requête de lecture vers la bibliothèque principale, mais en même temps elle perd également une partie du sens de la séparation maître-esclave. C'est-à-dire qu'au sens strict des scénarios de cohérence des données, la séparation lecture-écriture n'est pas tout à fait adaptée. Faites attention à la rapidité des mises à jour comme un défaut de l'utilisation de la séparation lecture-écriture.
D'accord, cette partie est juste pour comprendre. Voyons ensuite comment réaliser la séparation en lecture et en écriture via le code Java :
Remarque : Ce projet doit introduire les dépendances suivantes : Spring Boot, spring-aop, spring-jdbc, aspectjweaver, etc.
Programmeur : Il n'y a que 30 jours, comment se préparer ?
1 : Configuration de la source de données maître-esclave
Nous devons configurer la base de données maître-esclave La configuration de la base de données maître-esclave est généralement écrite dans le fichier de configuration. Grâce à l'annotation @ConfigurationProperties, le fichier de configuration (généralement nommé : application.Properties) sont mappés à des attributs de classe spécifiques, de sorte que les valeurs écrites soient lues et injectées dans la configuration de code spécifique. Selon le principe selon lequel les habitudes sont supérieures aux conventions, nous annotons tous la bibliothèque principale comme. maître, la bibliothèque esclave est marquée comme esclave. application.Properties)里的属性映射到具体的类属性上,从而读取到写入的值注入到具体的代码配置中,按照习惯大于约定的原则,主库我们都是注为 master,从库注为 slave。
本项目采用了阿里的 druid 数据库连接池,使用 build 建造者模式创建 DataSource 对象,DataSource 就是代码层面抽象出来的数据源,接着需要配置 sessionFactory、sqlTemplate、事务管理器等。
/**
* 主从配置
*/
@Configuration
@MapperScan(basePackages = "com.wyq.mysqlreadwriteseparate.mapper", sqlSessionTemplateRef = "sqlTemplate")
public class DataSourceConfig {
/**
* 主库
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource master() {
return DruidDataSourceBuilder.create().build();
}
/**
* 从库
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.slave")
public DataSource slaver() {
return DruidDataSourceBuilder.create().build();
}
/**
* 实例化数据源路由
*/
@Bean
public DataSourceRouter dynamicDB(@Qualifier("master") DataSource masterDataSource,
@Autowired(required = false) @Qualifier("slaver") DataSource slaveDataSource) {
DataSourceRouter dynamicDataSource = new DataSourceRouter();
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DataSourceEnum.MASTER.getDataSourceName(), masterDataSource);
if (slaveDataSource != null) {
targetDataSources.put(DataSourceEnum.SLAVE.getDataSourceName(), slaveDataSource);
}
dynamicDataSource.setTargetDataSources(targetDataSources);
dynamicDataSource.setDefaultTargetDataSource(masterDataSource);
return dynamicDataSource;
}
/**
* 配置sessionFactory
* @param dynamicDataSource
* @return
* @throws Exception
*/
@Bean
public SqlSessionFactory sessionFactory(@Qualifier("dynamicDB") DataSource dynamicDataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setMapperLocations(
new PathMatchingResourcePatternResolver().getResources("classpath*:mapper/*Mapper.xml"));
bean.setDataSource(dynamicDataSource);
return bean.getObject();
}
/**
* 创建sqlTemplate
* @param sqlSessionFactory
* @return
*/
@Bean
public SqlSessionTemplate sqlTemplate(@Qualifier("sessionFactory") SqlSessionFactory sqlSessionFactory) {
return new SqlSessionTemplate(sqlSessionFactory);
}
/**
* 事务配置
*
* @param dynamicDataSource
* @return
*/
@Bean(name = "dataSourceTx")
public DataSourceTransactionManager dataSourceTransactionManager(@Qualifier("dynamicDB") DataSource dynamicDataSource) {
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();
dataSourceTransactionManager.setDataSource(dynamicDataSource);
return dataSourceTransactionManager;
}
}二: 数据源路由的配置
路由在主从分离是非常重要的,基本是读写切换的核心。Spring 提供了 AbstractRoutingDataSource 根据用户定义的规则选择当前的数据源,作用就是在执行查询之前,设置使用的数据源,实现动态路由的数据源,在每次数据库查询操作前执行它的抽象方法 determineCurrentLookupKey()
public class DataSourceRouter extends AbstractRoutingDataSource {
/**
* 最终的determineCurrentLookupKey返回的是从DataSourceContextHolder中拿到的,因此在动态切换数据源的时候注解
* 应该给DataSourceContextHolder设值
*
* @return
*/
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContextHolder.get();
}
}AbstractRoutingDataSource selon les règles définies par l'utilisateur La fonction de sélection de la source de données actuelle est de définir la source de données utilisée avant d'exécuter la requête, d'implémenter la source de données du routage dynamique et d'exécuter sa méthode abstraite avant chaque opération de requête de base de donnéesdetermineCurrentLookupKey() Détermine la source de données à utiliser. 🎜🎜Afin d'avoir un gestionnaire global de sources de données, nous devons actuellement introduire le DataSourceContextHolder, un gestionnaire de contexte de base de données, qui peut être compris comme une variable globale et accessible à tout moment (voir l'introduction détaillée ci-dessous). la fonction principale est de sauvegarder la source de données actuelle. 🎜public class DataSourceRouter extends AbstractRoutingDataSource {
/**
* 最终的determineCurrentLookupKey返回的是从DataSourceContextHolder中拿到的,因此在动态切换数据源的时候注解
* 应该给DataSourceContextHolder设值
*
* @return
*/
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContextHolder.get();
}
}三:数据源上下文环境
数据源上下文保存器,便于程序中可以随时取到当前的数据源,它主要利用 ThreadLocal 封装,因为 ThreadLocal 是线程隔离的,天然具有线程安全的优势。这里暴露了 set 和 get、clear 方法,set 方法用于赋值当前的数据源名,get 方法用于获取当前的数据源名称,clear 方法用于清除 ThreadLocal 中的内容,因为 ThreadLocal 的 key 是 weakReference 是有内存泄漏风险的,通过 remove 方法防止内存泄漏。
/**
* 利用ThreadLocal封装的保存数据源上线的上下文context
*/
public class DataSourceContextHolder {
private static final ThreadLocal<String> context = new ThreadLocal<>();
/**
* 赋值
*
* @param datasourceType
*/
public static void set(String datasourceType) {
context.set(datasourceType);
}
/**
* 获取值
* @return
*/
public static String get() {
return context.get();
}
public static void clear() {
context.remove();
}
}四:切换注解和 Aop 配置
首先我们来定义一个@DataSourceSwitcher 注解,拥有两个属性
① 当前的数据源② 是否清除当前的数据源,并且只能放在方法上,(不可以放在类上,也没必要放在类上,因为我们在进行数据源切换的时候肯定是方法操作),该注解的主要作用就是进行数据源的切换,在 dao 层进行操作数据库的时候,可以在方法上注明表示的是当前使用哪个数据源。
@DataSourceSwitcher 注解的定义:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Documented
public @interface DataSourceSwitcher {
/**
* 默认数据源
* @return
*/
DataSourceEnum value() default DataSourceEnum.MASTER;
/**
* 清除
* @return
*/
boolean clear() default true;
}DataSourceAop配置:
为了赋予@DataSourceSwitcher 注解能够切换数据源的能力,我们需要使用 AOP,然后使用@Aroud 注解找到方法上有@DataSourceSwitcher.class 的方法,然后取注解上配置的数据源的值,设置到 DataSourceContextHolder 中,就实现了将当前方法上配置的数据源注入到全局作用域当中。
@Slf4j
@Aspect
@Order(value = 1)
@Component
public class DataSourceContextAop {
@Around("@annotation(com.wyq.mysqlreadwriteseparate.annotation.DataSourceSwitcher)")
public Object setDynamicDataSource(ProceedingJoinPoint pjp) throws Throwable {
boolean clear = false;
try {
Method method = this.getMethod(pjp);
DataSourceSwitcher dataSourceSwitcher = method.getAnnotation(DataSourceSwitcher.class);
clear = dataSourceSwitcher.clear();
DataSourceContextHolder.set(dataSourceSwitcher.value().getDataSourceName());
log.info("数据源切换至:{}", dataSourceSwitcher.value().getDataSourceName());
return pjp.proceed();
} finally {
if (clear) {
DataSourceContextHolder.clear();
}
}
}
private Method getMethod(JoinPoint pjp) {
MethodSignature signature = (MethodSignature) pjp.getSignature();
return signature.getMethod();
}
}五:用法以及测试
在配置好了读写分离之后,就可以在代码中使用了,一般而言我们使用在 service 层或者 dao 层,在需要查询的方法上添加@DataSourceSwitcher(DataSourceEnum.SLAVE),它表示该方法下所有的操作都走的是读库。在需要 update 或者 insert 的时候使用@DataSourceSwitcher(DataSourceEnum.MASTER)表示接下来将会走写库。
其实还有一种更为自动的写法,可以根据方法的前缀来配置 AOP 自动切换数据源,比如 update、insert、fresh 等前缀的方法名一律自动设置为写库。select、get、query 等前缀的方法名一律配置为读库,这是一种更为自动的配置写法。缺点就是方法名需要按照 aop 配置的严格来定义,否则就会失效。
@Service
public class OrderService {
@Resource
private OrderMapper orderMapper;
/**
* 读操作
*
* @param orderId
* @return
*/
@DataSourceSwitcher(DataSourceEnum.SLAVE)
public List<Order> getOrder(String orderId) {
return orderMapper.listOrders(orderId);
}
/**
* 写操作
*
* @param orderId
* @return
*/
@DataSourceSwitcher(DataSourceEnum.MASTER)
public List<Order> insertOrder(Long orderId) {
Order order = new Order();
order.setOrderId(orderId);
return orderMapper.saveOrder(order);
}
}六:总结
还是画张图来简单总结一下:
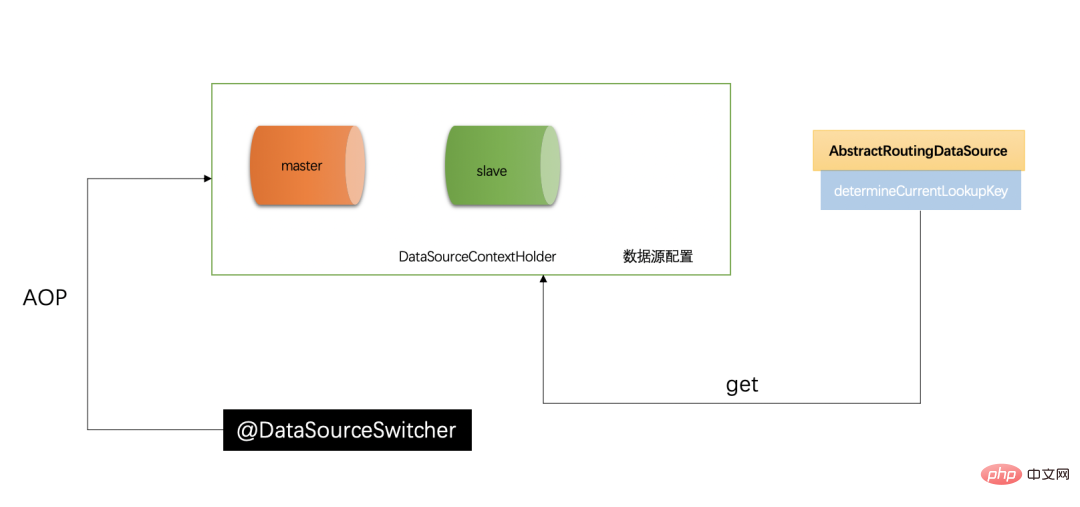
Cet article explique comment implémenter la séparation en lecture-écriture d'une base de données. Notez que le point central de la séparation en lecture-écriture est le routage des données, qui doit être hérité AbstractRoutingDataSource,复写它的 determineCurrentLookupKey ()方法。同时需要注意全局的上下文管理器 DataSourceContextHolder est la classe principale qui enregistre le contexte de la source de données et qui est également. la valeur de la source de données trouvée dans la méthode de routage. C'est l'équivalent d'une station de transfert pour les sources de données, et combiné avec la couche inférieure de jdbc-Template pour créer et gérer des sources de données, des transactions, etc., la séparation en lecture et en écriture de notre base de données est parfaitement réalisée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL convient aux débutants car il est simple à installer, puissant et facile à gérer les données. 1. Installation et configuration simples, adaptées à une variété de systèmes d'exploitation. 2. Prise en charge des opérations de base telles que la création de bases de données et de tables, d'insertion, d'interrogation, de mise à jour et de suppression de données. 3. Fournir des fonctions avancées telles que les opérations de jointure et les sous-questionnaires. 4. Les performances peuvent être améliorées par l'indexation, l'optimisation des requêtes et le partitionnement de la table. 5. Prise en charge des mesures de sauvegarde, de récupération et de sécurité pour garantir la sécurité et la cohérence des données.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Créez une base de données à l'aide de NAVICAT Premium: Connectez-vous au serveur de base de données et entrez les paramètres de connexion. Cliquez avec le bouton droit sur le serveur et sélectionnez Créer une base de données. Entrez le nom de la nouvelle base de données et le jeu de caractères spécifié et la collation. Connectez-vous à la nouvelle base de données et créez le tableau dans le navigateur d'objet. Cliquez avec le bouton droit sur le tableau et sélectionnez Insérer des données pour insérer les données.
 Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Vous pouvez créer une nouvelle connexion MySQL dans NAVICAT en suivant les étapes: ouvrez l'application et sélectionnez une nouvelle connexion (CTRL N). Sélectionnez "MySQL" comme type de connexion. Entrez l'adresse Hostname / IP, le port, le nom d'utilisateur et le mot de passe. (Facultatif) Configurer les options avancées. Enregistrez la connexion et entrez le nom de la connexion.
 Comment exécuter SQL dans Navicat
Apr 08, 2025 pm 11:42 PM
Comment exécuter SQL dans Navicat
Apr 08, 2025 pm 11:42 PM
Étapes pour effectuer SQL dans NAVICAT: Connectez-vous à la base de données. Créez une fenêtre d'éditeur SQL. Écrivez des requêtes ou des scripts SQL. Cliquez sur le bouton Exécuter pour exécuter une requête ou un script. Affichez les résultats (si la requête est exécutée).
 Navicat se connecte au code et à la solution d'erreur de base de données
Apr 08, 2025 pm 11:06 PM
Navicat se connecte au code et à la solution d'erreur de base de données
Apr 08, 2025 pm 11:06 PM
Erreurs et solutions courantes Lors de la connexion aux bases de données: nom d'utilisateur ou mot de passe (erreur 1045) Blocs de pare-feu Connexion (erreur 2003) Délai de connexion (erreur 10060) Impossible d'utiliser la connexion à socket (erreur 1042) Erreur de connexion SSL (erreur 10055) Trop de connexions Résultat de l'hôte étant bloqué (erreur 1129)
