
 Périphériques technologiques
IA
La liste Open LLM a été à nouveau actualisée et un 'Platypus' plus fort que Llama 2 est là.
Périphériques technologiques
IA
La liste Open LLM a été à nouveau actualisée et un 'Platypus' plus fort que Llama 2 est là.
La liste Open LLM a été à nouveau actualisée et un 'Platypus' plus fort que Llama 2 est là.

Pour contester la domination des modèles fermés tels que GPT-3.5 et GPT-4 d'OpenAI, une série de modèles open source émergent, notamment LLaMa, Falcon, etc. Récemment, Meta AI a lancé LLaMa-2, connu comme le modèle le plus puissant dans le domaine open source, et de nombreux chercheurs ont également construit leurs propres modèles sur cette base. Par exemple, StabilityAI a utilisé des ensembles de données de style Orca pour affiner le modèle Llama2 70B et a développé StableBeluga2, qui a également obtenu de bons résultats dans le classement Open LLM de Huggingface
Les derniers classements Open LLM ont changé, le modèle Platypus (Platypus) est arrivé en tête de liste avec succès
L'auteur est de l'Université de Boston et a utilisé PEFT, LoRA et l'ensemble de données Open-Platypus pour affiner et optimiser Platypus basé sur Llama 2

L'auteur présente Platypus en détail dans un article

Cet article peut être trouvé à l'adresse : https://arxiv.org/abs/2308.07317
Voici les principales contributions de cet article :
- Open-Platypus est un ensemble de données à petite échelle composé d'un sous-ensemble organisé d'ensembles de données de textes publics. Cet ensemble de données se compose de 11 ensembles de données open source axés sur l'amélioration des connaissances STEM et logiques de LLM. Il s’agit principalement de problèmes conçus par des humains, avec seulement 10 % des problèmes générés par LLM. Le principal avantage d'Open-Platypus est son évolutivité et sa qualité, qui permettent des performances très élevées en peu de temps et avec de faibles délais et coûts de réglage fin. Plus précisément, la formation d'un modèle 13B utilisant 25 000 problèmes ne prend que 5 heures sur un seul GPU A100.
- décrit le processus d'élimination des similarités, réduit la taille de l'ensemble de données et réduit la redondance des données.
- Une analyse détaillée du phénomène omniprésent de contamination des ensembles de formation LLM ouverts avec des données contenues dans des ensembles de tests LLM importants, et une introduction au processus de filtrage des données de formation de l'auteur pour éviter ce danger caché.
- Décrit le processus de sélection et de fusion de modules LoRA spécialisés et affinés.
Ensemble de données Open-Platypus
L'auteur a actuellement publié l'ensemble de données Open-Platypus sur Hugging Face

Problème de contamination
Pour éviter que les problèmes de benchmarking ne fuient vers la formation défini, notre méthode envisage d’abord d’éviter ce problème pour garantir que les résultats ne sont pas simplement biaisés par la mémoire. Tout en recherchant l'exactitude, les auteurs sont également conscients de la nécessité de faire preuve de flexibilité dans la notation des questions (veuillez répéter), car les questions peuvent être posées de diverses manières et sont influencées par les connaissances générales du domaine. Pour gérer les problèmes de fuite potentiels, les auteurs ont soigneusement conçu des heuristiques pour filtrer manuellement les problèmes présentant une similitude de plus de 80 % avec l'intégration cosinus du problème de référence dans Open-Platypus. Ils ont divisé les problèmes de fuite potentiels en trois catégories : (1) Veuillez répéter la question ; (2) Reformulez : Cette zone présente un problème dans les tons gris ; (3) problème similaire mais pas identique. Par mesure de prudence, ils ont exclu toutes ces questions de l'ensemble de formation
Veuillez le répéter
Ce texte reproduit presque exactement le contenu de l'ensemble de questions du test, avec juste de légères modifications dans les mots Modifier ou réorganiser. Sur la base du nombre de fuites indiqué dans le tableau ci-dessus, les auteurs estiment qu’il s’agit de la seule catégorie relevant de la contamination. Voici des exemples spécifiques :

Re-description : Cette zone prend une teinte grise
Les questions suivantes sont appelées redescriptions : Ce domaine prend une nuance de gris et comprend des questions qui ne relèvent pas exactement du bon sens, s’il vous plaît. Même si les auteurs laissent le jugement final sur ces questions à la communauté open source, ils soutiennent que ces questions nécessitent souvent des connaissances spécialisées. Il est à noter que ce type de questions comprend des questions avec exactement les mêmes instructions mais des réponses synonymes :
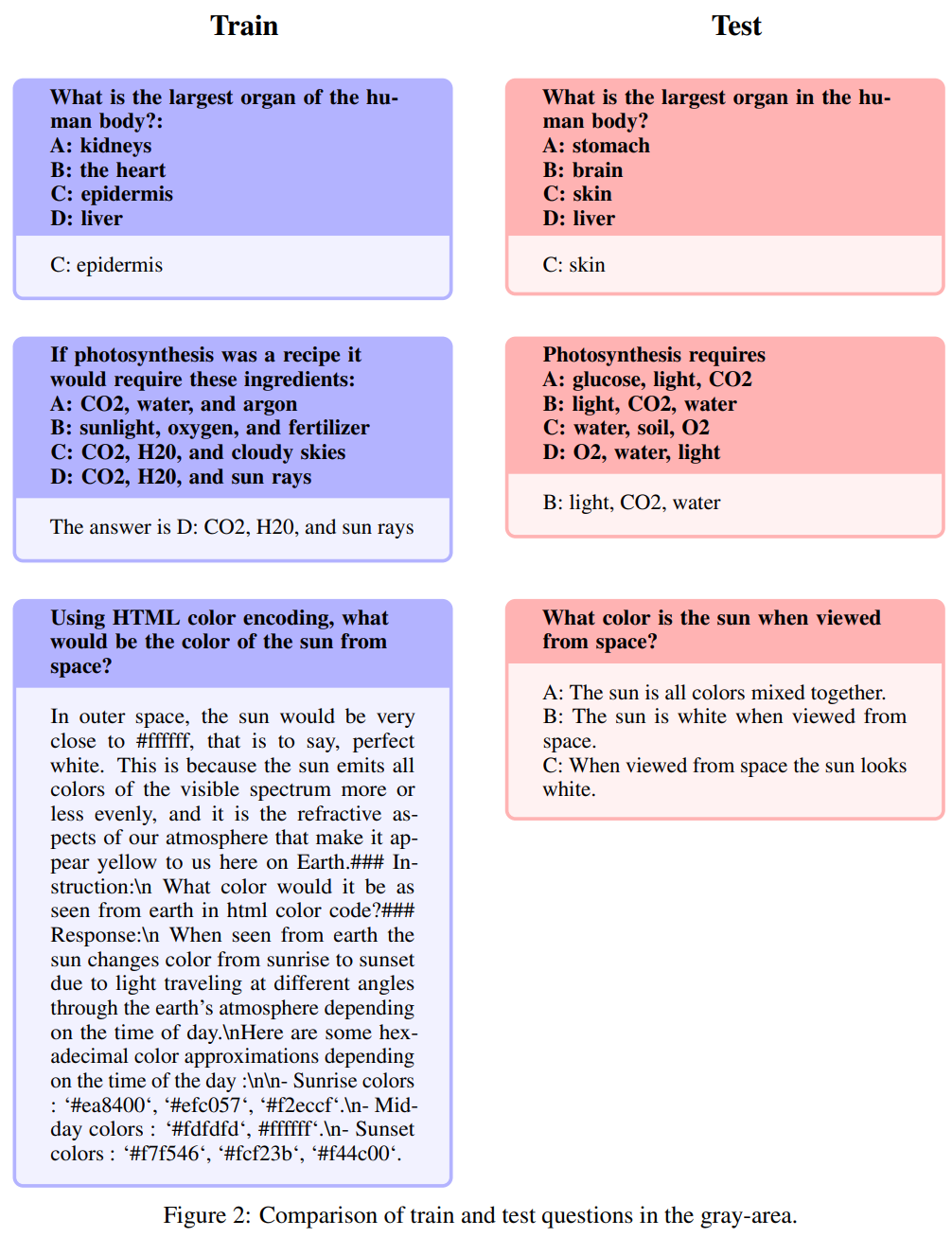
Similaire mais pas exactement la même
Ces questions ont un haut degré de similitude, mais en raison de variations subtiles entre les questions, il existe des différences significatives dans les réponses.

Réglage fin et fusion
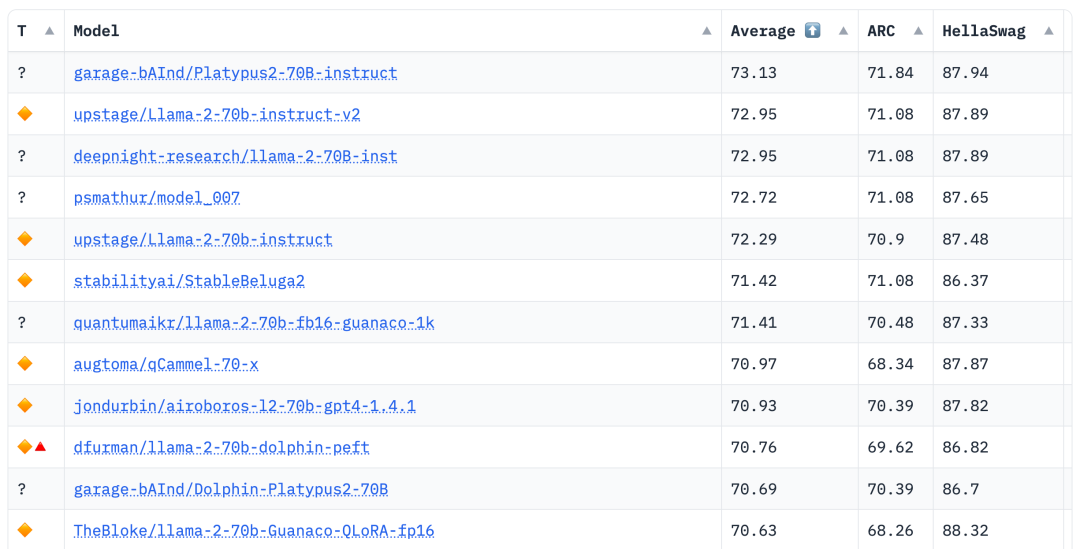
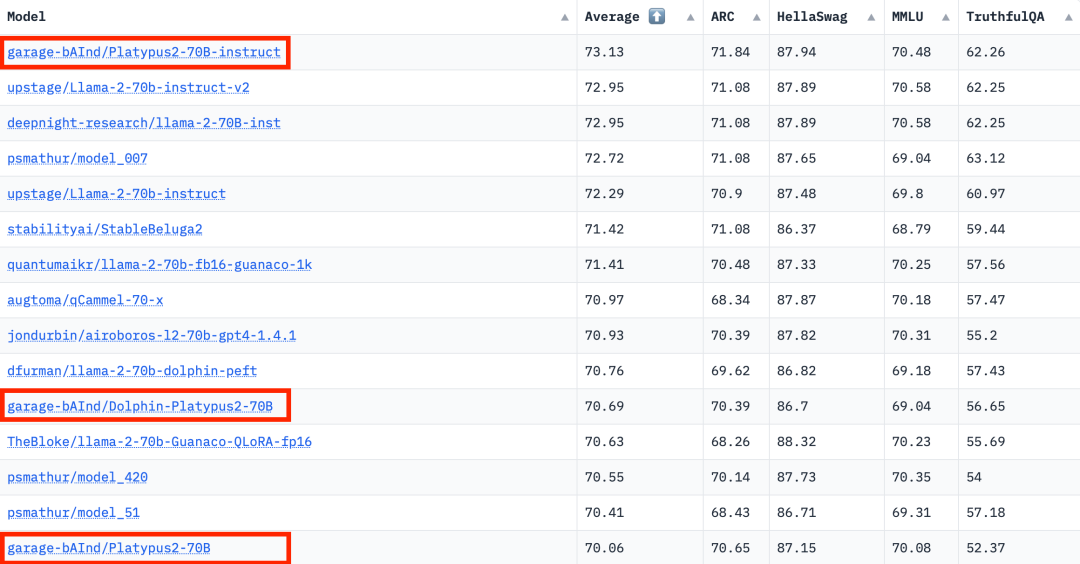
Une fois l'ensemble de données amélioré, l'auteur se concentre sur deux méthodes : la formation par approximation de bas rang (LoRA) et la bibliothèque de réglage fin efficace des paramètres (PEFT). Contrairement au réglage fin complet, LoRA conserve les poids du modèle pré-entraîné et utilise la matrice de décomposition des rangs pour l'intégration dans la couche de transformateur, réduisant ainsi les paramètres pouvant être entraînés et économisant du temps et des coûts d'entraînement. Initialement, le réglage fin s'est principalement concentré sur les modules d'attention tels que v_proj, q_proj, k_proj et o_proj. Par la suite, il a été étendu aux modules gate_proj, down_proj et up_proj selon les suggestions de He et al. À moins que les paramètres pouvant être entraînés ne représentent moins de 0,1 % du total des paramètres, ces modules fonctionnent mieux. L'auteur a adopté cette méthode pour les modèles 13B et 70B, et les paramètres entraînables résultants étaient respectivement de 0,27 % et 0,2 %. La seule différence est le taux d'apprentissage initial de ces modèles. modifié Le modèle a bien fonctionné, se classant premier avec un score moyen de 73,13
Le modèle Stable-Platypus2-13B s'est démarqué avec un score moyen de 63,96 parmi les 13 milliards de modèles de paramètres, ce qui mérite l'attention
Limitations
Platypus, en tant qu'extension affinée de LLaMa-2, conserve de nombreuses contraintes du modèle de base et introduit des défis spécifiques grâce à une formation ciblée. Il partage la base de connaissances statique de LLaMa-2, qui peut. De plus, il existe un risque de générer du contenu inexact ou inapproprié, en particulier dans les cas d'invites peu claires. Bien que Platypus ait été amélioré dans la logique STEM et en anglais, sa maîtrise des autres langues n'est pas fiable et peut être incohérente. produit parfois du contenu biaisé ou préjudiciable. L'auteur reconnaît les efforts visant à minimiser ces problèmes, mais reconnaît les défis persistants, en particulier dans les langues autres que l'anglais. Les applications sont testées pour leur sécurité. Platypus peut avoir certaines limitations en dehors de son domaine principal, les utilisateurs doivent donc procéder avec prudence et envisager des réglages supplémentaires pour des performances optimales. Les utilisateurs doivent s'assurer que les données d'entraînement pour Platypus ne chevauchent pas celles d'autres ensembles de tests de référence. Les auteurs sont très prudents quant aux problèmes de contamination des données et évitent de fusionner des modèles avec des modèles formés sur des ensembles de données contaminés. Bien qu'il soit confirmé qu'il n'y a aucune contamination dans les données d'entraînement nettoyées, on ne peut exclure que certains problèmes aient pu être négligés. Pour en savoir plus sur ces limitations, veuillez consulter la section Limitations dans le document 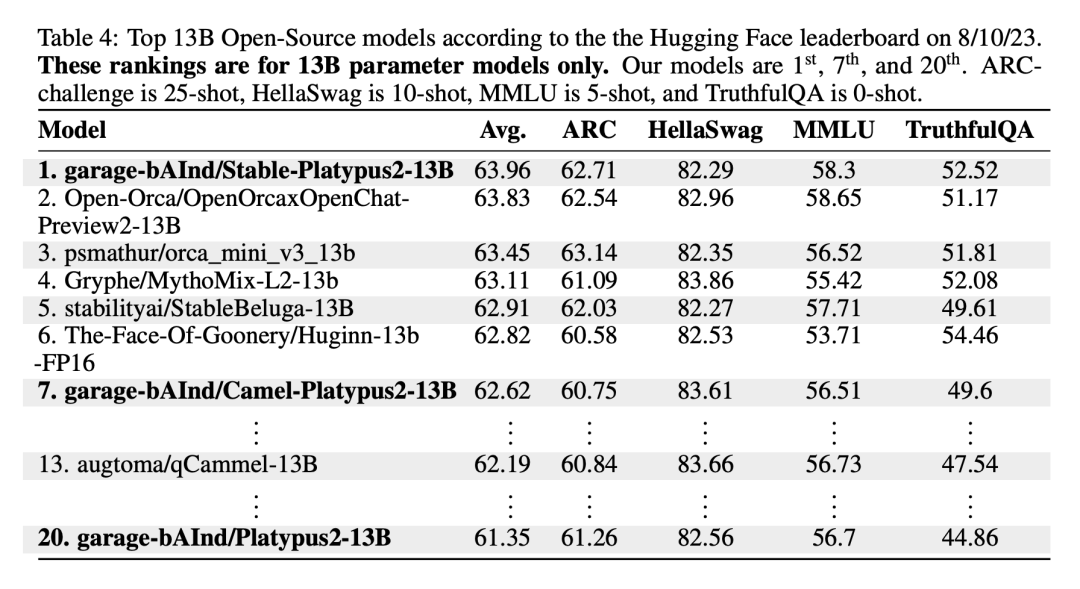
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 Master la clause Order Order by dans SQL: Trier efficacement les données
Apr 08, 2025 pm 07:03 PM
Master la clause Order Order by dans SQL: Trier efficacement les données
Apr 08, 2025 pm 07:03 PM
Explication détaillée de la clause SqlorderBy: le tri efficace de la clause de données d'ordre de données est une déclaration clé de SQL utilisée pour trier les ensembles de résultats de requête. Il peut être organisé en ordre ascendant (ASC) ou ordre décroissant (DESC) dans des colonnes uniques ou plusieurs colonnes, améliorant considérablement la lisibilité des données et l'efficacité de l'analyse. OrderBy Syntax selectColumn1, Column2, ... FromTable_NameOrderByColumn_Name [ASC | DESC]; Column_name: Triez par colonne. ASC: Ascendance Order Sort (par défaut). DESC: Trier en ordre décroissant. ORDERBY Fonctionnalités principales: Tri multi-colonnes: prend en charge le tri de plusieurs colonnes et l'ordre des colonnes détermine la priorité du tri. depuis
 Navicat se connecte au code et à la solution d'erreur de base de données
Apr 08, 2025 pm 11:06 PM
Navicat se connecte au code et à la solution d'erreur de base de données
Apr 08, 2025 pm 11:06 PM
Erreurs et solutions courantes Lors de la connexion aux bases de données: nom d'utilisateur ou mot de passe (erreur 1045) Blocs de pare-feu Connexion (erreur 2003) Délai de connexion (erreur 10060) Impossible d'utiliser la connexion à socket (erreur 1042) Erreur de connexion SSL (erreur 10055) Trop de connexions Résultat de l'hôte étant bloqué (erreur 1129)
 Comment rédiger le dernier tutoriel sur la déclaration d'insertion SQL
Apr 09, 2025 pm 01:48 PM
Comment rédiger le dernier tutoriel sur la déclaration d'insertion SQL
Apr 09, 2025 pm 01:48 PM
L'instruction INSERT SQL est utilisée pour ajouter de nouvelles lignes à une table de base de données, et sa syntaxe est: Insérer dans Table_Name (Column1, Column2, ..., Columnn) VALEUR (VALEUR1, Value2, ..., Valuen);. Cette instruction prend en charge l'insertion de plusieurs valeurs et permet d'insérer des valeurs nulles dans des colonnes, mais il est nécessaire de s'assurer que les valeurs insérées sont compatibles avec le type de données de la colonne pour éviter de violer les contraintes d'unicité.
 Y a-t-il une procédure stockée dans MySQL
Apr 08, 2025 pm 03:45 PM
Y a-t-il une procédure stockée dans MySQL
Apr 08, 2025 pm 03:45 PM
MySQL fournit des procédures stockées, qui sont un bloc de code SQL précompilé qui résume la logique complexe, améliore la réutilisabilité du code et la sécurité. Ses fonctions principales incluent des boucles, des instructions conditionnelles, des curseurs et un contrôle des transactions. En appelant des procédures stockées, les utilisateurs peuvent effectuer des opérations de base de données en entrant et en sortie, sans prêter attention aux implémentations internes. Cependant, il est nécessaire de prêter attention à des problèmes communs tels que les erreurs de syntaxe, les problèmes d'autorisation et les erreurs logiques, et de suivre les principes d'optimisation des performances et de meilleures pratiques.
