
 base de données
SQL
Quand la base de données sera-t-elle divisée en bases de données et en tables ? Comment diviser ?
base de données
SQL
Quand la base de données sera-t-elle divisée en bases de données et en tables ? Comment diviser ?
Quand la base de données sera-t-elle divisée en bases de données et en tables ? Comment diviser ?
1. Segmentation des données
La base de données relationnelle elle-même est plus susceptible de devenir un goulot d'étranglement du système, et la capacité de stockage, le nombre de connexions et les capacités de traitement d'une seule machine sont limités. Lorsque le volume de données d'une seule table atteint 1 000 W ou 100 Go, en raison du grand nombre de dimensions de requête, même si des bases de données esclaves sont ajoutées et des index optimisés, les performances chuteront toujours considérablement lors de l'exécution de nombreuses opérations. A ce stade, il est nécessaire d'envisager de la segmenter. Le but de la segmentation est de réduire la charge sur la base de données et de raccourcir le temps d'interrogation.
1000W ou 100G peut être considéré comme la valeur de référence de l'industrie. Les détails dépendent des installations matérielles actuelles du système, de la conception de la structure de la table et d'autres facteurs.
Le contenu principal de la distribution de bases de données n'est rien d'autre que la segmentation des données (Sharding), ainsi que le positionnement et l'intégration des données après segmentation. La segmentation des données consiste à stocker les données de manière dispersée dans plusieurs bases de données, réduisant ainsi la quantité de données dans une seule base de données. En augmentant le nombre d'hôtes, les problèmes de performances d'une seule base de données peuvent être atténués, atteignant ainsi l'objectif d'améliorer les performances de fonctionnement de la base de données.
La segmentation des données peut être divisée de deux manières selon son type de segmentation : la segmentation verticale (verticale) et la segmentation horizontale (horizontale)
1. Segmentation verticale (verticale)
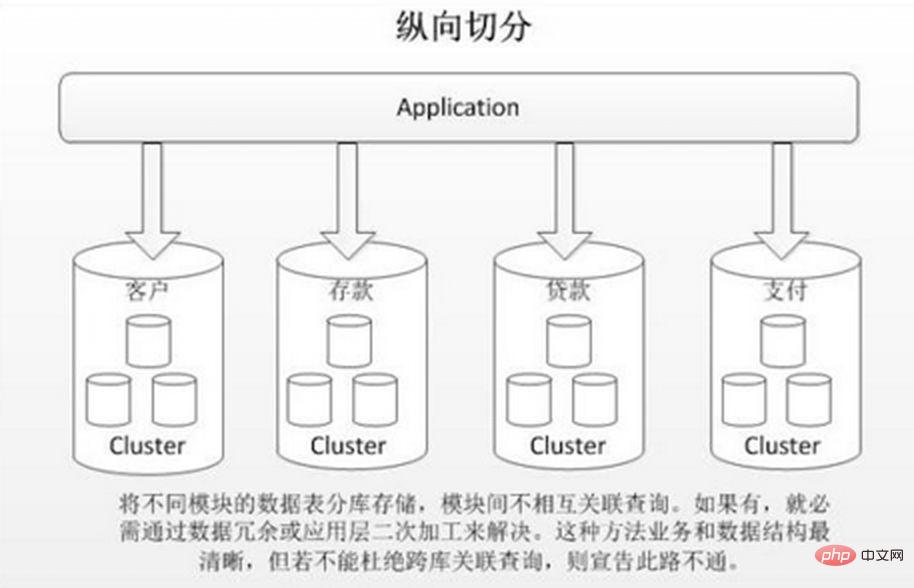
Segmentation verticale Il existe deux types courants : sous-bibliothèque verticale et sous-table verticale.
Le partitionnement vertical consiste à stocker différentes tables à faible corrélation dans différentes bases de données basées sur le couplage métier. L'approche est similaire à la division d'un grand système en plusieurs petits systèmes, qui sont divisés indépendamment selon la classification commerciale. Semblable à l’approche de « gouvernance des microservices », chaque microservice utilise une base de données distincte. Comme le montre l'image :
Le fractionnement vertical de la table est basé sur des « colonnes » dans la base de données. Si une table comporte de nombreux champs, vous pouvez créer une nouvelle table d'extension et diviser les champs qui ne sont pas fréquemment utilisés ou qui ont de grandes longueurs de champ en extensions. tableaux. Lorsqu'il y a de nombreux champs (par exemple, une grande table contient plus de 100 champs), « diviser la grande table en petites tables » est plus facile à développer et à maintenir, et peut également éviter les problèmes de pages croisées. La couche inférieure de MySQL est. stocké dans des pages de données. Un enregistrement qui prend trop de place entraînera des croisements de pages, entraînant une surcharge de performances supplémentaire. De plus, la base de données charge les données dans la mémoire en unités de lignes, de sorte que la longueur des champs dans la table soit plus courte et la fréquence d'accès plus élevée. La mémoire peut charger plus de données, le taux de réussite est plus élevé et les E/S du disque sont plus élevées. réduit, améliorant ainsi les performances de la base de données.
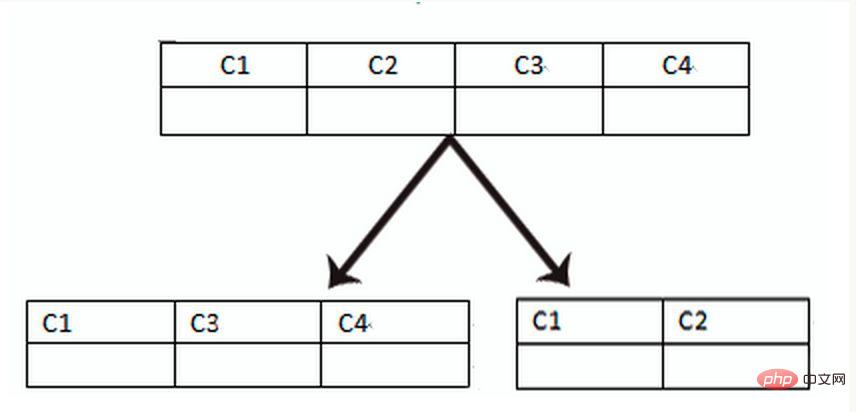
Avantages de la segmentation verticale :
1. Résoudre le couplage au niveau du système d'entreprise et clarifier l'entreprise 2. Semblable à la gouvernance des microservices, elle peut également effectuer la gestion hiérarchique, la maintenance et le suivi des données de différentes entreprises, expansion, etc. 3. Dans les scénarios à forte concurrence, la segmentation verticale augmentera dans une certaine mesure le goulot d'étranglement des E/S, des connexions à la base de données et des ressources matérielles d'une seule machine
Inconvénients :
1. être joint et ne peut être résolu que par l'agrégation d'interface.Amélioration 2. La complexité du traitement des transactions distribuées 3. Il existe toujours le problème du volume de données excessif dans une seule table (nécessitant un découpage horizontal)
2. Horizontal (horizontal) découpage
Lorsqu'une application est difficile. Peu importe la finesse de la segmentation verticale ou le nombre de lignes de données après la segmentation est énorme, il y aura un seul goulot d'étranglement en matière de lecture, d'écriture et de stockage de la base de données. temps, une segmentation horizontale est nécessaire.
Le partitionnement horizontal est divisé en partitionnement intra-base de données et partitionnement sous-base de données. En fonction de la relation logique inhérente aux données dans la table, la même table est dispersée en plusieurs bases de données ou plusieurs tables selon des conditions différentes. une partie des données est incluse, réduisant ainsi la quantité de données dans une seule table et obtenant un effet distribué. Comme le montre la figure :
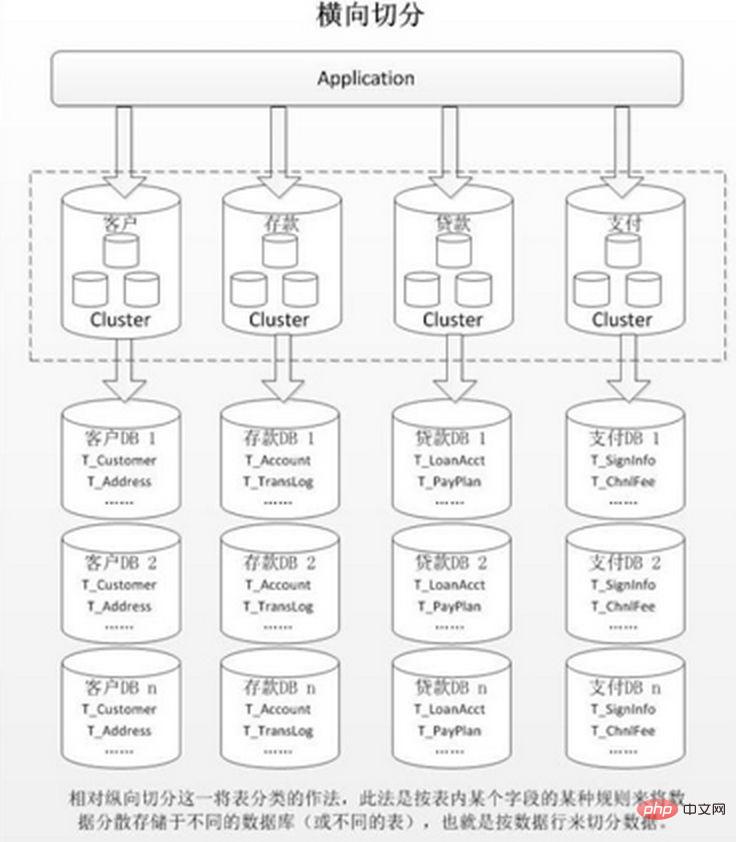
Le partitionnement dans la base de données résout uniquement le problème du volume de données excessif dans une seule table, mais ne distribue pas les tables aux bibliothèques sur différentes machines, il est donc utile de réduire le pression sur la base de données MySQL, ce n'est pas très utile. Tout le monde est toujours en compétition pour le processeur, la mémoire et les E/S réseau de la même machine physique. Il est préférable de le résoudre par une sous-base de données et une sous-table.
Avantages du partitionnement horizontal :
1. Il n'y a pas de goulot d'étranglement en termes de performances causé par un volume de données excessif et une concurrence élevée dans une seule base de données, ce qui améliore la stabilité du système et la capacité de charge. 2. La transformation côté application est faible et il n'y en a pas. besoin de diviser les modules métiers
Inconvénients :
1. Il est difficile d'assurer la cohérence des transactions entre les fragments. 2. Les performances des requêtes de jointure entre bases de données sont médiocres. 3. L'expansion multiple des données est difficile et la quantité de maintenance est énorme.
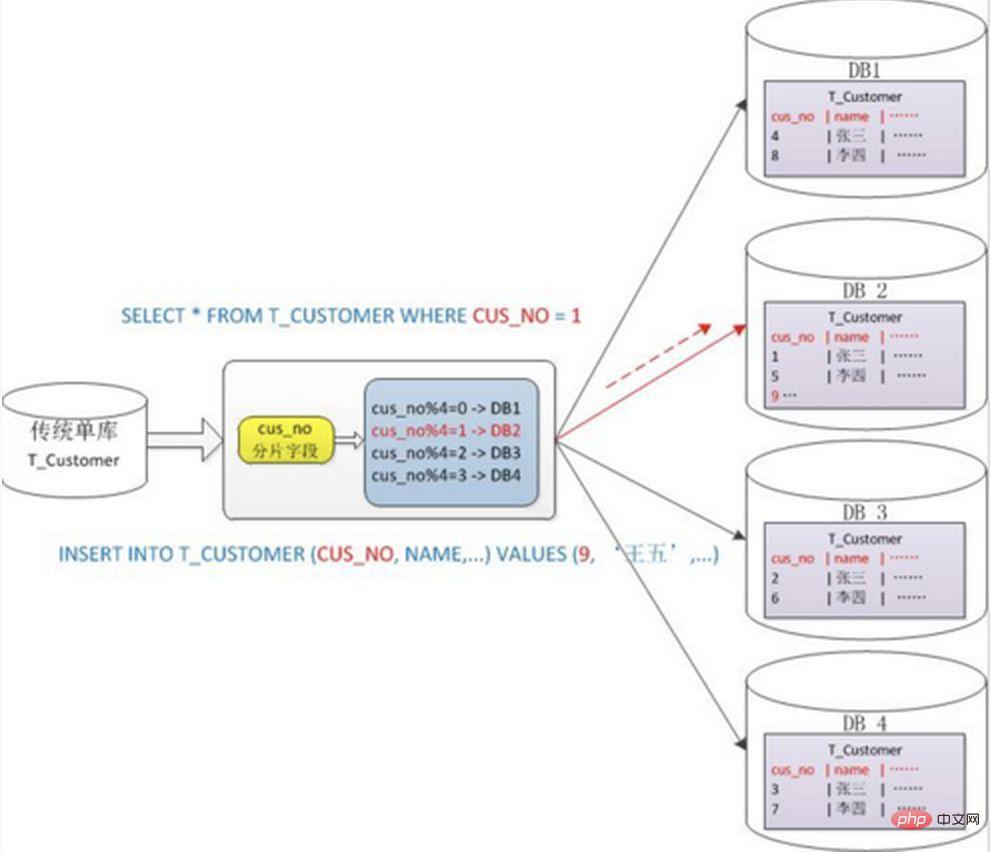
Après le découpage horizontal, la même table sera utilisée. apparaissent dans plusieurs bases de données/table, le contenu de chaque bibliothèque/table est différent. Plusieurs règles typiques de partage de données sont :
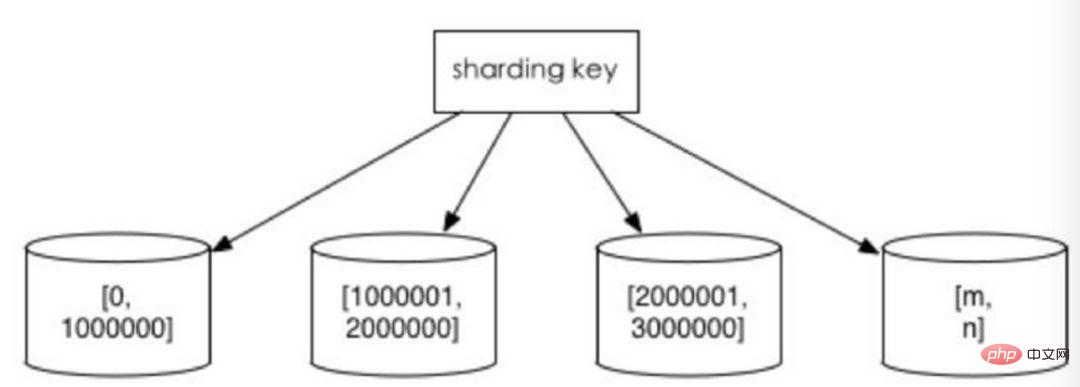
1. Répartir en fonction de la plage de valeurs
en fonction de l'intervalle de temps ou de l'intervalle d'identification. Par exemple : répartissez les données de différents mois ou même de jours dans différentes bibliothèques par date ; attribuez des enregistrements avec des ID utilisateur de 1 à 9999 à la première bibliothèque, des enregistrements avec des ID utilisateur de 10 000 à 20 000 à la deuxième bibliothèque, et ainsi de suite. Dans un sens, la « séparation des données chaudes et froides » utilisée dans certains systèmes, la migration de certaines données historiques moins utilisées vers d'autres bibliothèques et la fourniture uniquement de requêtes de données chaudes dans les fonctions métier, est une pratique similaire.
Les avantages de ceci sont :
1. La taille d'une seule table est contrôlable 2. Il est naturellement facile de s'étendre horizontalement si vous souhaitez étendre l'ensemble du cluster fragmenté plus tard, il vous suffit d'ajouter des nœuds. il n'est pas nécessaire de migrer les données d'autres fragments. 3. Lors de l'utilisation de champs de fragments pour la recherche de plage, le partitionnement continu peut localiser rapidement les fragments pour une requête rapide, évitant ainsi les problèmes de requête entre fragments.
Inconvénients :
Les données Hotspot deviennent un goulot d'étranglement en termes de performances. Le partage continu peut avoir des points chauds de données, tels que le partage par champs temporels. Certains fragments stockent des données sur la période la plus récente et peuvent être fréquemment lus et écrits, tandis que certains fragments stockent des données historiques qui sont rarement interrogées
. 2. Prenez le modulo en fonction de la valeur numérique
Utilisez généralement la méthode de segmentation mod hash modulo, par exemple : divisez la table Customer en 4 bibliothèques en fonction du champ cusno, et mettez celles avec un reste de 0. Allez dans la première bibliothèque, mettez le reste avec 1 dans la deuxième bibliothèque, et ainsi de suite. De cette manière, les données du même utilisateur seront dispersées dans la même base de données. Si la condition de requête contient le champ cusno, la base de données correspondante peut être clairement positionnée pour la requête.
Avantages :
Le partage des données est relativement uniforme et il n'est pas sujet aux points chauds et aux goulots d'étranglement d'accès simultanés.
Inconvénients :
1. Lorsque le cluster partitionné est étendu ultérieurement, les anciennes données doivent être migrées (à l'aide de un algorithme de hachage cohérent peut mieux éviter ce problème) 2. Il est facile de faire face au problème complexe des requêtes entre fragments. Par exemple, dans l'exemple ci-dessus, si cusno n'est pas inclus dans les conditions de requête fréquemment utilisées, la base de données ne sera pas localisée. Il est donc nécessaire de lancer des requêtes vers quatre bibliothèques en même temps, puis de fusionner les données dans la mémoire. , prenez l'ensemble minimum et renvoyez-le à l'application. Au lieu de cela, la bibliothèque est devenue un frein.
2. Problèmes causés par la sous-base de données et la sous-table
La sous-base de données et la sous-table peuvent éliminer efficacement les goulots d'étranglement et les pressions de performances causés par des machines uniques et des bases de données uniques, et percer les E/S du réseau et le matériel. Le goulot d'étranglement des ressources et du nombre de connexions pose également certains problèmes. Ces défis techniques et les solutions correspondantes sont décrits ci-dessous.
1. Problème de cohérence des transactions
Transactions distribuées
Lorsque le contenu mis à jour est distribué dans différentes bibliothèques en même temps, des problèmes de transactions entre bases de données se produiront inévitablement. Les transactions entre fragments sont également des transactions distribuées, et il n'existe généralement pas de solution simple, le « protocole XA » et la « validation en deux phases » peuvent être utilisés pour les gérer.
Les transactions distribuées peuvent garantir au maximum l'atomicité des opérations de base de données. Cependant, lors de la soumission d'une transaction, plusieurs nœuds doivent être coordonnés, ce qui retarde le moment de soumission de la transaction et prolonge le temps d'exécution de la transaction. Cela entraîne une probabilité accrue de conflits ou de blocages lorsque les transactions accèdent à des ressources partagées. À mesure que le nombre de nœuds de base de données augmente, cette tendance deviendra de plus en plus grave, devenant ainsi un obstacle à l'expansion horizontale du système au niveau de la base de données.
Cohérence éventuelle
Pour les systèmes ayant des exigences de performances élevées mais de faibles exigences de cohérence, la cohérence en temps réel du système n'est souvent pas requise, tant que la cohérence finale est atteinte dans le délai imparti, transaction une compensation peut être utilisée. Différente de la méthode d'annulation de la transaction immédiatement après qu'une erreur s'est produite lors de l'exécution, la compensation de transaction est une vérification post-mortem et une mesure corrective. Certaines méthodes de mise en œuvre courantes incluent : la vérification de rapprochement des données, la comparaison basée sur les journaux et la comparaison régulière avec la norme. sources de données. Synchronisation et plus encore. La compensation des transactions doit également être envisagée en conjonction avec le système commercial.
2. Problème de jointure de requête associée à des nœuds croisés
Avant la segmentation, les données requises pour de nombreuses listes et pages de détails du système peuvent être complétées via la jointure SQL. Après la segmentation, les données peuvent être distribuées sur différents nœuds. À ce stade, les problèmes causés par la jointure seront plus gênants. Compte tenu des performances, essayez d'éviter d'utiliser une requête de jointure.
Quelques façons de résoudre ce problème :
1) Table globale
Les tables globales peuvent également être considérées comme des « tables de dictionnaire de données », qui sont des tables dont tous les modules du système peuvent dépendre dans l'ordre. pour éviter les requêtes de jointure entre bases de données, vous pouvez enregistrer une copie de ce type de table dans chaque base de données. Ces données sont généralement rarement modifiées, il n’y a donc pas lieu de s’inquiéter des problèmes de cohérence.
2) Redondance de champ
Une conception anti-paradigme typique qui utilise l'espace pour le temps et évite les requêtes de jointure pour les performances. Par exemple : lorsque la table de commande enregistre le userId, elle enregistre également une copie redondante du userName, de sorte que lors de l'interrogation des détails de la commande, il n'est pas nécessaire d'interroger la "table des utilisateurs de l'acheteur".
Cependant, cette méthode a des scénarios applicables limités et est plus adaptée aux situations où il y a peu de champs dépendants. La cohérence des données des champs redondants est également difficile à assurer. Tout comme dans l'exemple du tableau de commande ci-dessus, une fois que l'acheteur a modifié le nom d'utilisateur, doit-il être mis à jour de manière synchrone dans l'historique des commandes ? Cela doit également être considéré en conjonction avec des scénarios commerciaux réels.
3) Assemblage de données
Au niveau du système, il y a deux requêtes. Les résultats de la première requête se concentrent sur la recherche de l'ID de données associé, puis lancent une deuxième requête basée sur l'ID pour obtenir l'ID associé. données. Enfin, les données obtenues sont regroupées en champs.
4) Partitionnement ER
Dans une base de données relationnelle, si vous pouvez d'abord déterminer la relation entre les tables et stocker ces enregistrements de table associés sur le même fragment, il sera alors préférable d'éviter les problèmes de jointure entre fragments. Dans le cas de 1:1 ou 1:n, il est généralement divisé en fonction de la clé primaire ID de la table principale. Comme le montre la figure ci-dessous :
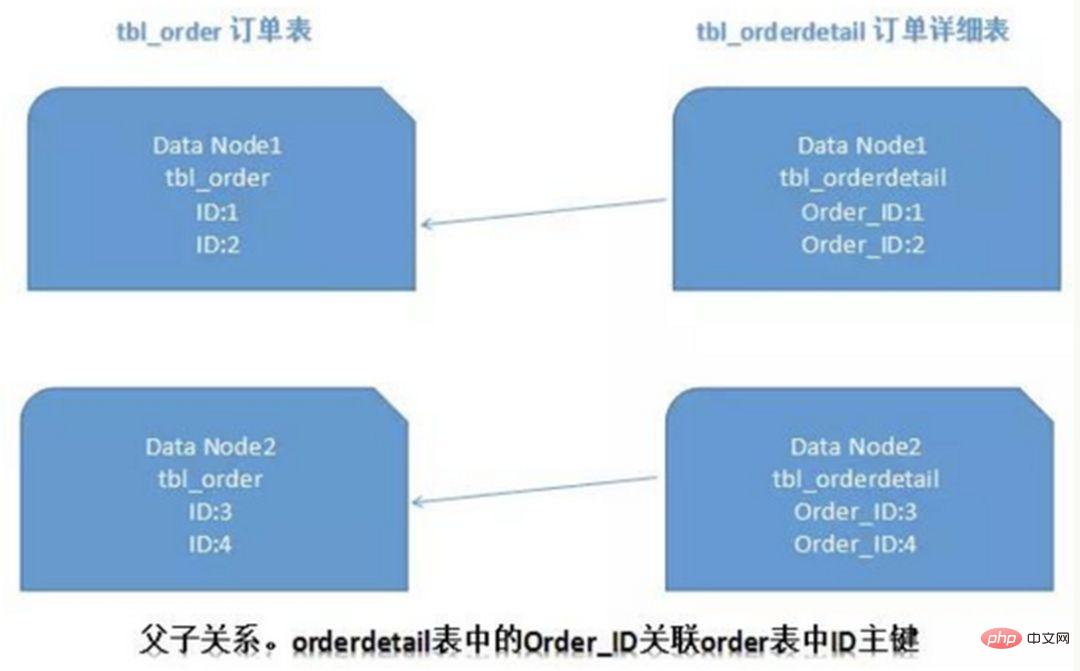
De cette façon, la table de commande et la table de détails de commande orderdetail sur Data Node1 peuvent être partiellement liées à la requête via orderId, et il en va de même sur Data Node2.
3. Problèmes de pagination, de tri et de fonctionnement entre nœuds
Lors d'interrogations sur plusieurs nœuds et plusieurs bases de données, des problèmes tels que la pagination limitée et l'ordre par tri peuvent survenir. La pagination doit être triée en fonction du champ spécifié. Lorsque le champ de tri est un champ de partitionnement, il est plus facile de localiser la partition spécifiée via les règles de partitionnement ; lorsque le champ de tri n'est pas un champ de partitionnement, cela devient plus compliqué. Les données doivent d'abord être triées et renvoyées dans différents nœuds de partition, puis les ensembles de résultats renvoyés par différentes partitions sont résumés et triés à nouveau, et enfin renvoyés à l'utilisateur. Comme le montre l'image :
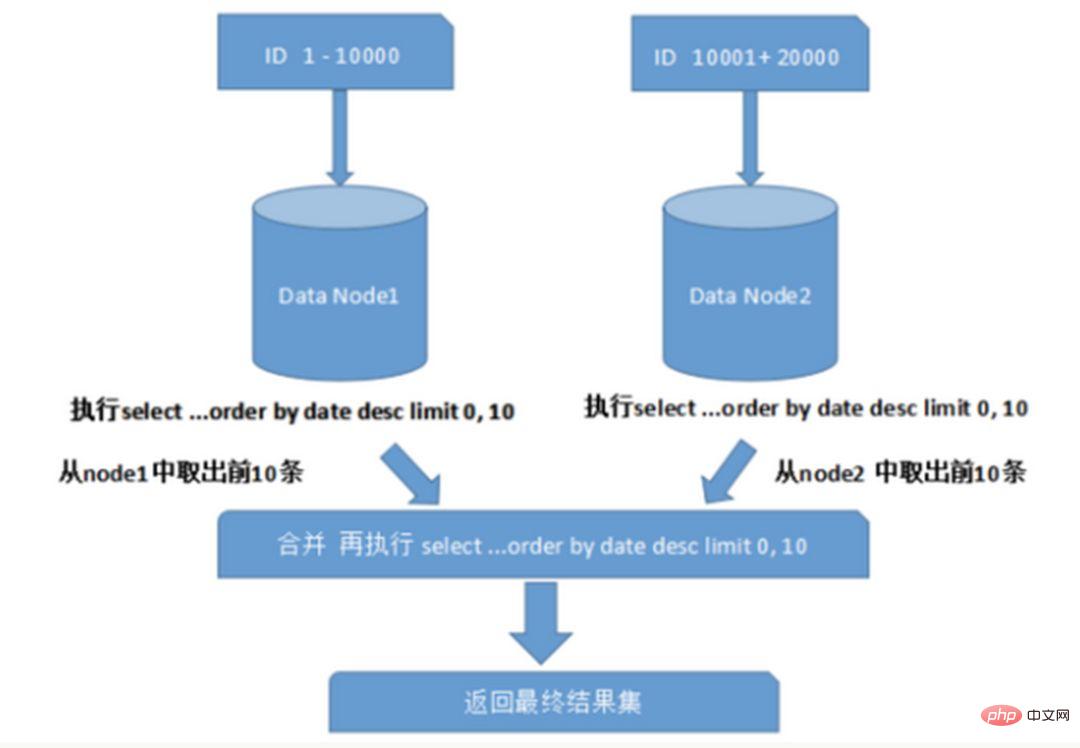
L'image ci-dessus ne reprend que les données de la première page, ce qui n'a pas un grand impact sur les performances. Cependant, si le nombre de pages obtenues est très important, la situation devient beaucoup plus compliquée, car les données de chaque nœud de partition peuvent être aléatoires. Pour la précision du tri, les N premières pages de données de tous les nœuds doivent être triées et. fusionné. Enfin, effectuez ensuite le tri global. Une telle opération consomme des ressources CPU et mémoire, donc plus le nombre de pages est grand, plus les performances du système seront mauvaises.
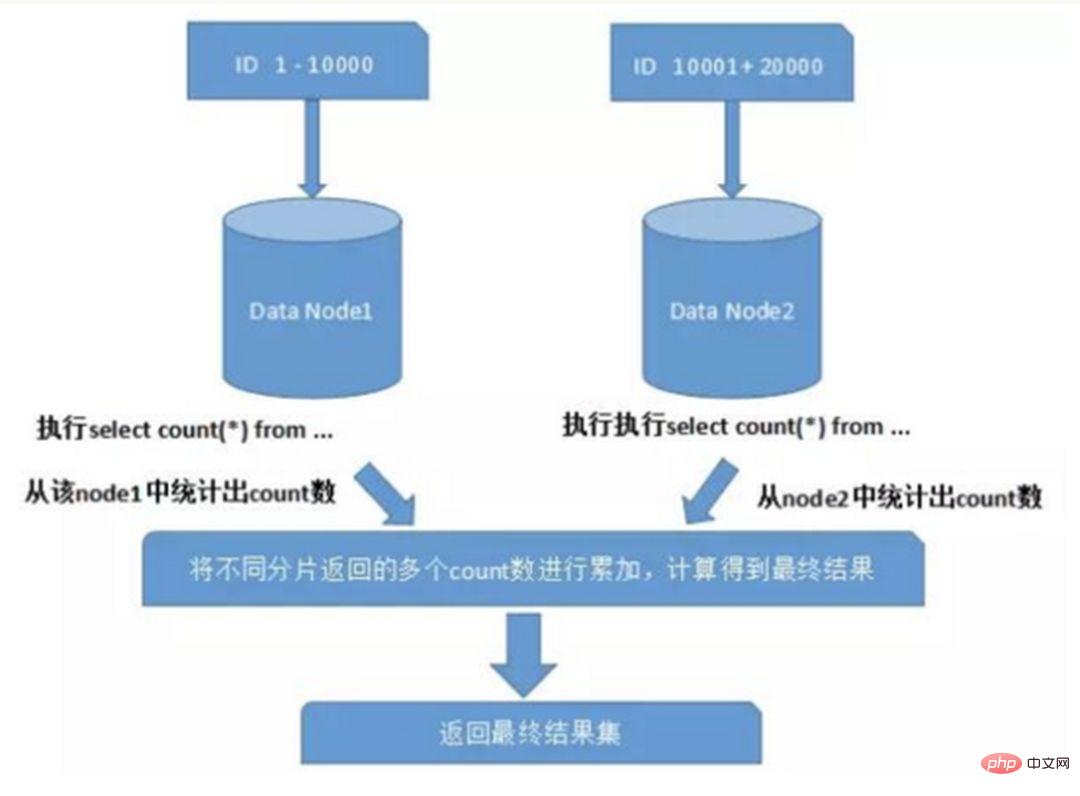
Lorsque vous utilisez des fonctions telles que Max, Min, Sum et Count pour le calcul, vous devez également d'abord exécuter la fonction correspondante sur chaque fragment, puis résumer les ensembles de résultats de chaque fragment et calculer à nouveau, et enfin les résultats reviennent. Comme le montre l'image :
4. Problème global d'évitement de clé primaire
Dans un environnement de sous-base de données et de sous-table, puisque les données de la table existent dans différentes bases de données en même temps, l'auto-habituel l'incrément de la valeur de la clé primaire sera inutile, l'ID généré par une certaine base de données de partition ne peut pas être garanti comme étant globalement unique. Par conséquent, il est nécessaire de concevoir la clé primaire globale séparément pour éviter la duplication des clés primaires entre les bases de données. Il existe quelques stratégies courantes de génération de clé primaire :
1) UUID
La forme standard de l'UUID contient 32 nombres hexadécimaux, divisés en 5 segments, 36 caractères sous la forme 8-4-4-4-12, par exemple : 550e8400-e29b-41d4-a716-446655440000
UUID est la clé primaire, qui est la solution la plus simple. Elle est générée localement, a des performances élevées et n'a aucune consommation de temps réseau. Mais les inconvénients sont également évidents. Parce que l'UUID est très long, il prendra beaucoup d'espace de stockage. De plus, il y aura des problèmes de performances lors de la création d'un index en tant que clé primaire et des requêtes basées sur l'index. le désordre de l'UUID entraînera des changements fréquents dans l'emplacement des données, entraînant une pagination.
2) Combiné avec la base de données pour maintenir la table d'ID de clé primaire
Créez une table de séquence dans la base de données :
CREATE TABLE `sequence` ( `id` bigint(20) unsigned NOT NULL auto_increment, `stub` char(1) NOT NULL default '', PRIMARY KEY (`id`), UNIQUE KEY `stub` (`stub`) ) ENGINE=MyISAM;
Le champ stub est défini comme un index unique. La même valeur de stub n'a qu'un seul enregistrement. dans la table de séquence et peut être utilisé pour plusieurs tables en même temps. Le contenu de la table de séquence est le suivant :
+-------------------+------+ | id | stub | +-------------------+------+ | 72157623227190423 | a | +-------------------+------+
Utilisez le moteur de stockage MyISAM au lieu d'InnoDB pour de meilleures performances. MyISAM utilise des verrous au niveau de la table, et les lectures et écritures dans la table sont en série, vous n'avez donc pas à vous soucier de lire deux fois la même valeur d'ID pendant la concurrence.
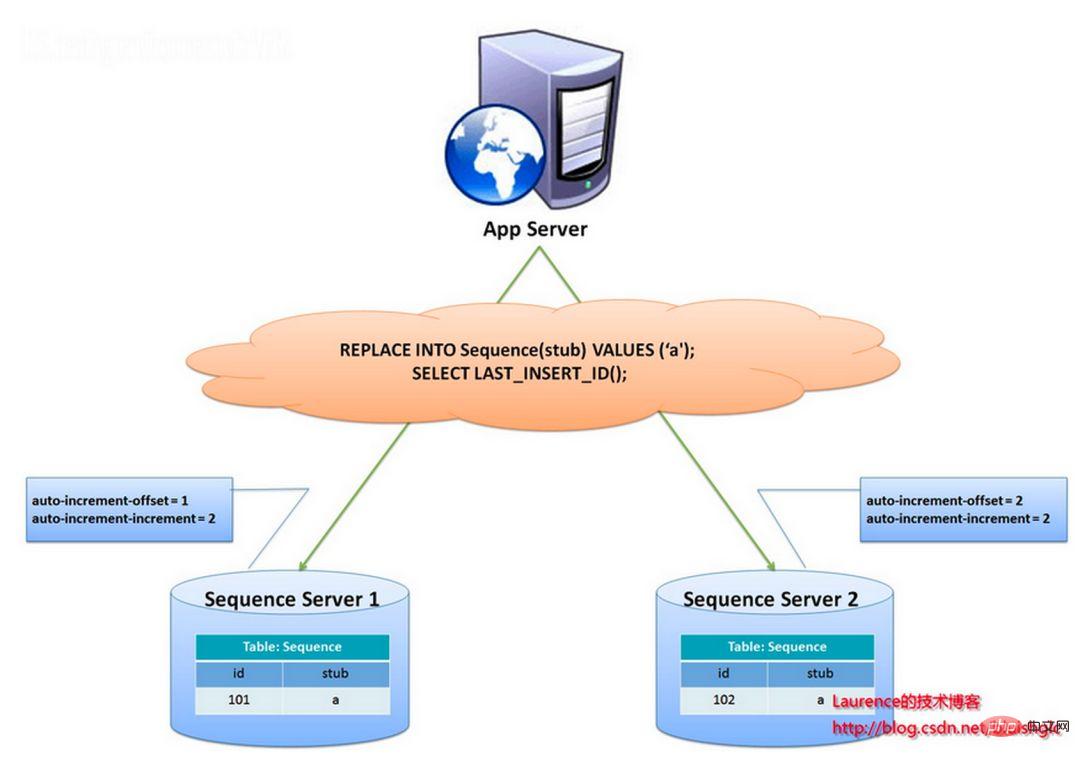
Lorsqu'un identifiant 64 bits unique au monde est nécessaire, exécutez :
REPLACE INTO sequence (stub) VALUES ('a'); SELECT LAST_INSERT_ID();
Ces deux instructions sont au niveau de la connexion. select lastinsertid() doit être sous la même connexion à la base de données que replace into pour obtenir le nouvel identifiant qui vient d'être inséré.
L'avantage d'utiliser replace into au lieu de insert into est que cela évite que le nombre de lignes du tableau soit trop grand et ne nécessite pas de nettoyage régulier.
Cette solution est relativement simple, mais ses inconvénients sont également évidents : il y a un seul point problématique et il dépend fortement de DB. Lorsque DB est anormal, l'ensemble du système sera indisponible. La configuration maître-esclave peut augmenter la disponibilité, mais lorsque la base de données maître tombe en panne et bascule maître-esclave, la cohérence des données est difficile à garantir dans des circonstances particulières. De plus, le goulot d'étranglement des performances est limité aux performances de lecture et d'écriture d'un seul MySQL.
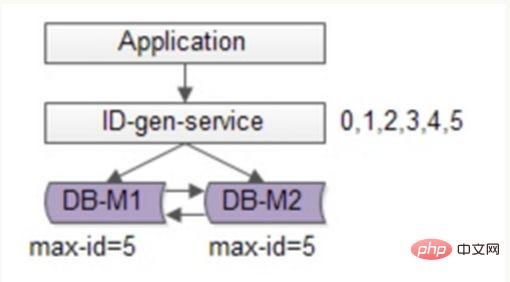
Une stratégie de génération de clé primaire utilisée par l'équipe Flickr est similaire à la solution de table de séquence ci-dessus, mais résout mieux le problème des points uniques et des goulots d'étranglement de performances.
L'idée générale de cette solution est d'établir plus de 2 serveurs générateurs d'identifiants globaux, de déployer une seule base de données sur chaque serveur, et chaque base de données dispose d'une table de séquence pour enregistrer l'identifiant global actuel. La taille du pas de croissance des identifiants dans le tableau correspond au nombre de bibliothèques, et les valeurs de départ sont échelonnées dans l'ordre, de sorte que la génération des identifiants puisse être hachée dans chaque base de données. Comme le montre l'image ci-dessous :
L'ID est généré par deux serveurs de base de données et différentes valeurs d'auto_increment sont définies. La valeur de départ de la première séquence est 1 et chaque pas augmente de 2. La valeur de départ de l'autre séquence est 2 et chaque pas augmente de 2. De ce fait, les identifiants générés par la première station sont tous des nombres impairs (1, 3, 5, 7...), et les identifiants générés par la deuxième station sont tous des nombres pairs (2, 4, 6, 8...). .).
Cette solution répartit uniformément la pression de génération des identifiants sur les deux machines. Il fournit également une tolérance aux pannes du système. Si une erreur se produit sur la première machine, il peut automatiquement passer à la deuxième machine pour obtenir l'ID. Cependant, il présente les inconvénients suivants : lors de l'ajout de machines au système, l'expansion horizontale est plus compliquée ; chaque fois que l'ID est obtenu, la base de données doit être lue et écrite. La pression sur la base de données est toujours très élevée et les performances. ne peut être amélioré qu'en s'appuyant sur des machines à tas.
Vous pouvez continuer à optimiser sur la base de la solution Flickr, utiliser des méthodes par lots pour réduire la pression d'écriture de la base de données, obtenir une plage de segments de numéro d'identification à chaque fois, puis accéder à la base de données pour les obtenir après utilisation, ce qui peut réduire considérablement la pression sur la base de données. Comme le montre la figure ci-dessous :
Toujours en utilisant deux bases de données pour garantir la disponibilité, seul l'ID maximum actuel est stocké dans la base de données. Le service de génération d'ID extrait 6 ID par lots à chaque fois et modifie d'abord le maximum en 5. Lorsque l'application accède au service de génération d'ID, elle n'a pas besoin d'accéder à la base de données et les ID 0 à 5 sont distribués séquentiellement à partir du segment numérique. cache. Une fois ces identifiants émis, remplacez le maxid par 11 et les identifiants 6 à 11 pourront être distribués la prochaine fois. En conséquence, la pression sur la base de données est réduite à 1/6 de celle d'origine.
3) Algorithme d'identification auto-croissant distribué Snowflake
L'algorithme Snowflake de Twitter résout le besoin des systèmes distribués de générer des identifiants globaux, générant un nombre long de 64 bits. Composants :
Le premier chiffre n'est pas utilisé
.Les 41 bits suivants correspondent à un temps de niveau milliseconde, et la longueur de 41 bits peut représenter 69 ans de temps
ID de centre de données à 5 chiffres, ID de travailleur à 5 chiffres. La longueur de 10 bits prend en charge le déploiement de jusqu'à 1 024 nœuds. Les 12 derniers bits sont comptés en millisecondes, et le numéro de séquence de comptage de 12 bits prend en charge chaque nœud générant 4 096 séquences d'identification par milliseconde. L'avantage est le suivant : le nombre de millisecondes est élevé et les identifiants générés augmentent généralement en fonction de la tendance temporelle ; il ne repose pas sur des systèmes tiers et a une stabilité et une efficacité élevées. Théoriquement, le QPS est d'environ 409,6 w. /s (1000*2^12), et la distribution entière Il n'y aura pas de collision d'ID dans le système ; les bits peuvent être alloués de manière flexible en fonction de sa propre activité.
L'inconvénient est qu'il dépend fortement de l'horloge de la machine. Si l'horloge est décalée, cela peut entraîner une génération d'ID en double.
Pour résumer
En combinant la base de données et la solution d'identification unique de snowflake, vous pouvez vous référer à la solution la plus mature du secteur : Leaf - le système de génération d'identification distribuée de Meituan-Dianping, et prend en compte la haute disponibilité, la reprise après sinistre et déploiement distribué. Horloge et autres problèmes.
5. Problèmes de migration et d'expansion des données
Lorsque l'entreprise se développe rapidement et est confrontée à des goulots d'étranglement en termes de performances et de stockage, la conception du partitionnement sera envisagée à ce stade, il est inévitable de considérer la question de la migration des données historiques. L'approche générale consiste à lire d'abord les données historiques, puis à écrire les données sur chaque nœud de partition conformément aux règles de partitionnement spécifiées. De plus, la planification de la capacité doit être effectuée en fonction du volume de données et du QPS actuels, ainsi que de la vitesse de développement de l'entreprise, pour calculer le nombre approximatif de fragments requis (il est généralement recommandé que le volume de données d'une seule table sur un seul fragment ne dépasse pas 1000W)
Si l'analyse de plage numérique est utilisée Pour les fragments, il vous suffit d'ajouter des nœuds pour les développer, et il n'est pas nécessaire de migrer les données de fragment. Si le partitionnement numérique modulo est utilisé, il sera relativement difficile de prendre en compte les problèmes d'expansion ultérieurs.
3. Quand envisager la segmentation
Parlons de quand envisager la segmentation des données.
1. Essayez de ne pas diviser si possible
Toutes les tables n'ont pas besoin d'être divisées, cela dépend principalement du taux de croissance des données. La segmentation augmentera dans une certaine mesure la complexité de l'entreprise. En plus de transporter les données et les requêtes, la base de données est également l'une de ses tâches importantes pour aider l'entreprise à mieux répondre à ses besoins.
N'utilisez pas l'astuce de la sous-base de données et de la sous-table sauf en cas d'absolue nécessité pour éviter la « surconception » et « l'optimisation prématurée ». Avant de diviser des bases de données et des tables, ne divisez pas simplement pour le plaisir de diviser. Faites de votre mieux pour faire ce que vous pouvez en premier, comme mettre à niveau le matériel, mettre à niveau le réseau, séparer la lecture et l'écriture, optimiser l'index, etc. Lorsque la quantité de données atteint le goulot d'étranglement d'une seule table, envisagez de partitionner les bases de données et les tables.
2. La quantité de données est trop importante et le fonctionnement et la maintenance normaux affectent l'accès de l'entreprise.
Le fonctionnement et la maintenance mentionnés ici font référence à :
1) Pour la sauvegarde de la base de données, si une seule table est trop grande, une grande quantité d’E/S disque est requise lors de la sauvegarde et des E/S réseau. Par exemple, si 1 To de données est transmise sur le réseau et occupe 50 Mo, cela prendra 20 000 secondes. Le risque de l'ensemble du processus est relativement élevé
2) Lorsque le DDL est modifié sur une grande table, MySQL verrouille le. table entière. Cela prendra beaucoup de temps. Pendant cette période, l'entreprise ne pourra pas accéder à cette table, ce qui aura un grand impact. Si vous utilisez pt-online-schema-change, des déclencheurs et des tables fantômes seront créés pendant l'utilisation, ce qui prend également beaucoup de temps. Durant cette opération, il est compté comme temps à risque. Diviser le tableau de données et réduire le montant total peut aider à réduire ce risque.
3)大表会经常访问与更新,就更有可能出现锁等待。将数据切分,用空间换时间,变相降低访问压力
3、随着业务发展,需要对某些字段垂直拆分
举个例子,假如项目一开始设计的用户表如下:
id bigint #用户的IDname varchar #用户的名字last_login_time datetime #最近登录时间personal_info text #私人信息..... #其他信息字段
在项目初始阶段,这种设计是满足简单的业务需求的,也方便快速迭代开发。而当业务快速发展时,用户量从10w激增到10亿,用户非常的活跃,每次登录会更新 lastloginname 字段,使得 user 表被不断update,压力很大。而其他字段:id, name, personalinfo 是不变的或很少更新的,此时在业务角度,就要将 lastlogintime 拆分出去,新建一个 usertime 表。
personalinfo 属性是更新和查询频率较低的,并且text字段占据了太多的空间。这时候,就要对此垂直拆分出 userext 表了。
4、数据量快速增长
随着业务的快速发展,单表中的数据量会持续增长,当性能接近瓶颈时,就需要考虑水平切分,做分库分表了。此时一定要选择合适的切分规则,提前预估好数据容量
5、安全性和可用性
鸡蛋不要放在一个篮子里。在业务层面上垂直切分,将不相关的业务的数据库分隔,因为每个业务的数据量、访问量都不同,不能因为一个业务把数据库搞挂而牵连到其他业务。利用水平切分,当一个数据库出现问题时,不会影响到100%的用户,每个库只承担业务的一部分数据,这样整体的可用性就能提高。
四. 案例分析
1、用户中心业务场景
用户中心是一个非常常见的业务,主要提供用户注册、登录、查询/修改等功能,其核心表为:
User(uid, login_name, passwd, sex, age, nickname) uid为用户ID, 主键login_name, passwd, sex, age, nickname, 用户属性
任何脱离业务的架构设计都是耍流氓,在进行分库分表前,需要对业务场景需求进行梳理:
用户侧:前台访问,访问量较大,需要保证高可用和高一致性。主要有两类需求:
1. Benutzeranmeldung: Benutzerinformationen über Anmeldename/Telefon/E-Mail abfragen, 1 % der Anfragen gehören zu diesem Typ. 2. Benutzerinformationsabfrage: Nach der Anmeldung Benutzerinformationen über UID abfragen, 99 % der Anfragen gehören zu diesem Typ side: Backend-Zugriff, unterstützt betriebliche Anforderungen und führt Paging-Abfragen basierend auf Alter, Geschlecht, Anmeldezeit, Registrierungszeit usw. durch. Es handelt sich um ein internes System mit geringem Zugriffsvolumen und geringen Anforderungen an Verfügbarkeit und Konsistenz.
Wenn die Datenmenge immer größer wird, muss die Datenbank horizontal segmentiert werden. Zu den oben beschriebenen Segmentierungsmethoden gehören „basierend auf dem numerischen Bereich“ und „basierend auf dem numerischen Modulo“. ". "
Nach numerischem Bereich": Basierend auf der Primärschlüssel-UID werden die Daten entsprechend dem UID-Bereich horizontal in mehrere Datenbanken unterteilt. Beispiel: Benutzer-db1 speichert Daten mit UID-Bereichen von 0 bis 1000w und Benutzer-db2 speichert Daten mit UID-Bereichen von 1000w bis 2000wuid.
Der Vorteil ist: Die Erweiterung ist einfach, wenn die Kapazität nicht ausreicht, fügen Sie einfach eine neue Datenbank hinzu.
Der Nachteil ist : Das Anforderungsvolumen ist im Allgemeinen ungleichmäßig, neu registrierte Benutzer sind aktiver, sodass der neue Benutzer-db2 eine höhere Auslastung hat als Benutzer-db1, was zu einer unausgewogenen Serverauslastung führt
"Demnach zum numerischen Wertmodul ": Die Primärschlüssel-UID wird auch als Grundlage für die Aufteilung verwendet, und die Daten werden basierend auf dem Wertmodulo der UID horizontal in mehrere Datenbanken unterteilt. Beispiel: Benutzer-DB1 speichert UID-Daten Modulo 1, Benutzer-DB2 speichert UID-Daten Modulo 0.
Die Vorteile sind : Die Datenmenge und Anforderungen werden gleichmäßig verteilt
Die Nachteile sind : Wenn die Kapazität nicht ausreicht, ist ein erneutes Aufwärmen erforderlich. Eine reibungslose Migration der Daten muss berücksichtigt werden.
Nach der horizontalen Segmentierung kann die Nachfrage nach UID gut befriedigt und direkt an eine bestimmte Datenbank weitergeleitet werden. Bei Abfragen, die auf Nicht-UID basieren, wie z. B. login_name, ist nicht bekannt, auf welche Bibliothek zugegriffen werden soll. In diesem Fall müssen alle Bibliotheken durchlaufen werden, was die Leistung erheblich verringert. Für die Benutzerseite kann die Lösung „Einrichten einer Zuordnungsbeziehung von Nicht-UID-Attributen zu UID“ übernommen werden, für die Betriebsseite kann die Lösung „Trennung von Front-End und Back-End“ übernommen werden.
1) Zuordnungsbeziehung Zum Beispiel: Anmeldename kann nicht direkt in der Datenbank gefunden werden, er kann erstellt
und in einer Indextabelle gespeichert werden oder Cache. Wenn Sie auf den Anmeldenamen zugreifen, fragen Sie zuerst die dem Anmeldenamen entsprechende UID über die Zuordnungstabelle ab und suchen Sie dann die spezifische Bibliothek über die UID. login_name→uid的映射关系
Die Zuordnungstabelle hat nur zwei Spalten und kann viele Daten enthalten. Wenn die Datenmenge zu groß ist, kann die Zuordnungstabelle auch horizontal geteilt werden. Diese Art der Indexstruktur im KV-Format kann den Cache verwenden, um die Abfrageleistung zu optimieren. Die Zuordnungsbeziehung ändert sich nicht häufig und die Cache-Trefferquote ist sehr hoch. 2) Genmethode Welche Bibliothek sich darin befindet, dann können diese 3 Bits als Unterbibliotheksgene betrachtet werden.
Die obige Zuordnungsbeziehungsmethode erfordert zusätzlichen Speicher der Zuordnungstabelle. Bei Abfragen nach Nicht-UID-Feldern ist ein zusätzlicher Datenbank- oder Cache-Zugriff erforderlich. Wenn Sie redundante Speicherung und Abfragen eliminieren möchten, können Sie die f-Funktion verwenden, um das Loginname-Gen als Unterbibliotheksgen von uid zu verwenden. Beziehen Sie sich beim Generieren der UID auf das oben beschriebene Schema zur verteilten eindeutigen ID-Generierung plus die letzten drei Bitwerte = f (Anmeldename). Wenn Sie den Anmeldenamen abfragen, müssen Sie nur den Wert von f(Anmeldename)%8 berechnen, um die spezifische Bibliothek zu finden. Dafür ist jedoch eine Kapazitätsplanung im Vorfeld erforderlich, die Abschätzung, in wie viele Datenbanken das Datenvolumen in den nächsten Jahren aufgeteilt werden muss, und die Reservierung einer bestimmten Anzahl an Bits von Datenbankgenen.
Für die Benutzerseite besteht die Hauptanforderung darin, sich auf einzeilige Abfragen zu konzentrieren. Es ist notwendig, eine Zuordnungsbeziehung von login_name herzustellen /phone/email an uid, das die Abfrage dieser Felder lösen kann. Auf der Betriebsseite gibt es viele Abfragen mit Batch-Paging und verschiedenen Bedingungen. Solche Abfragen erfordern einen großen Rechenaufwand, geben eine große Datenmenge zurück und verbrauchen eine hohe Leistung der Datenbank. Wenn zu diesem Zeitpunkt derselbe Dienst- oder Datenbankstapel mit der Benutzerseite geteilt wird, kann eine kleine Anzahl von Hintergrundanforderungen eine große Menge an Datenbankressourcen belegen, was zu einer Verschlechterung der Zugriffsleistung oder einer Zeitüberschreitung auf der Benutzerseite führt.
Diese Art von Geschäft eignet sich am besten für die Lösung „Trennung von Front-End und Back-End“. Das Back-End-Geschäft auf der Betriebsseite extrahiert unabhängige Dienste und DBs, um die Kopplung mit dem Front-End-Geschäftssystem zu lösen. Da die Betriebsseite keine hohen Anforderungen an Verfügbarkeit und Konsistenz stellt, ist es möglich, nicht auf die Echtzeitbibliothek zuzugreifen, sondern die Daten für den Zugriff über Binlog asynchron mit der Betriebsbibliothek zu synchronisieren. Wenn die Datenmenge groß ist, können Sie auch die ES-Suchmaschine oder Hive verwenden, um die komplexen Abfragemethoden im Hintergrund zu erfüllen. 5. Unterstützt Unterdatenbanken und Untertabellen-Middleware -Tabelle:
sharding-jdbc (Dangdang) TSharding (Mogujie) Atlas (Qihoo 360) Cobar (Alibaba) -
My CAT (basierend auf Cobar) Oceanus ( 58.com) Vitess (Google)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment le langage Go implémente-t-il les opérations d'ajout, de suppression, de modification et de requête de la base de données ?
Mar 27, 2024 pm 09:39 PM
Comment le langage Go implémente-t-il les opérations d'ajout, de suppression, de modification et de requête de la base de données ?
Mar 27, 2024 pm 09:39 PM
Le langage Go est un langage de programmation efficace, concis et facile à apprendre. Il est privilégié par les développeurs en raison de ses avantages en programmation simultanée et en programmation réseau. Dans le développement réel, les opérations de base de données font partie intégrante. Cet article explique comment utiliser le langage Go pour implémenter les opérations d'ajout, de suppression, de modification et de requête de base de données. Dans le langage Go, nous utilisons généralement des bibliothèques tierces pour faire fonctionner les bases de données, telles que les packages SQL couramment utilisés, gorm, etc. Ici, nous prenons le package SQL comme exemple pour présenter comment implémenter les opérations d'ajout, de suppression, de modification et de requête de la base de données. Supposons que nous utilisons une base de données MySQL.
 iOS 18 ajoute une nouvelle fonction d'album 'Récupéré' pour récupérer les photos perdues ou endommagées
Jul 18, 2024 am 05:48 AM
iOS 18 ajoute une nouvelle fonction d'album 'Récupéré' pour récupérer les photos perdues ou endommagées
Jul 18, 2024 am 05:48 AM
Les dernières versions d'Apple des systèmes iOS18, iPadOS18 et macOS Sequoia ont ajouté une fonctionnalité importante à l'application Photos, conçue pour aider les utilisateurs à récupérer facilement des photos et des vidéos perdues ou endommagées pour diverses raisons. La nouvelle fonctionnalité introduit un album appelé "Récupéré" dans la section Outils de l'application Photos qui apparaîtra automatiquement lorsqu'un utilisateur a des photos ou des vidéos sur son appareil qui ne font pas partie de sa photothèque. L'émergence de l'album « Récupéré » offre une solution aux photos et vidéos perdues en raison d'une corruption de la base de données, d'une application d'appareil photo qui n'enregistre pas correctement dans la photothèque ou d'une application tierce gérant la photothèque. Les utilisateurs n'ont besoin que de quelques étapes simples
 Comment Hibernate implémente-t-il le mappage polymorphe ?
Apr 17, 2024 pm 12:09 PM
Comment Hibernate implémente-t-il le mappage polymorphe ?
Apr 17, 2024 pm 12:09 PM
Le mappage polymorphe Hibernate peut mapper les classes héritées à la base de données et fournit les types de mappage suivants : join-subclass : crée une table séparée pour la sous-classe, incluant toutes les colonnes de la classe parent. table par classe : créez une table distincte pour les sous-classes, contenant uniquement des colonnes spécifiques aux sous-classes. union-subclass : similaire à join-subclass, mais la table de classe parent réunit toutes les colonnes de la sous-classe.
 Tutoriel détaillé sur l'établissement d'une connexion à une base de données à l'aide de MySQLi en PHP
Jun 04, 2024 pm 01:42 PM
Tutoriel détaillé sur l'établissement d'une connexion à une base de données à l'aide de MySQLi en PHP
Jun 04, 2024 pm 01:42 PM
Comment utiliser MySQLi pour établir une connexion à une base de données en PHP : Inclure l'extension MySQLi (require_once) Créer une fonction de connexion (functionconnect_to_db) Appeler la fonction de connexion ($conn=connect_to_db()) Exécuter une requête ($result=$conn->query()) Fermer connexion ( $conn->close())
 Comment gérer les erreurs de connexion à la base de données en PHP
Jun 05, 2024 pm 02:16 PM
Comment gérer les erreurs de connexion à la base de données en PHP
Jun 05, 2024 pm 02:16 PM
Pour gérer les erreurs de connexion à la base de données en PHP, vous pouvez utiliser les étapes suivantes : Utilisez mysqli_connect_errno() pour obtenir le code d'erreur. Utilisez mysqli_connect_error() pour obtenir le message d'erreur. En capturant et en enregistrant ces messages d'erreur, les problèmes de connexion à la base de données peuvent être facilement identifiés et résolus, garantissant ainsi le bon fonctionnement de votre application.
 Une analyse approfondie de la façon dont HTML lit la base de données
Apr 09, 2024 pm 12:36 PM
Une analyse approfondie de la façon dont HTML lit la base de données
Apr 09, 2024 pm 12:36 PM
HTML ne peut pas lire directement la base de données, mais cela peut être réalisé via JavaScript et AJAX. Les étapes comprennent l'établissement d'une connexion à la base de données, l'envoi d'une requête, le traitement de la réponse et la mise à jour de la page. Cet article fournit un exemple pratique d'utilisation de JavaScript, AJAX et PHP pour lire les données d'une base de données MySQL, montrant comment afficher dynamiquement les résultats d'une requête dans une page HTML. Cet exemple utilise XMLHttpRequest pour établir une connexion à la base de données, envoyer une requête et traiter la réponse, remplissant ainsi les données dans les éléments de la page et réalisant la fonction de lecture HTML de la base de données.
 Conseils et pratiques pour gérer les caractères chinois tronqués dans les bases de données avec PHP
Mar 27, 2024 pm 05:21 PM
Conseils et pratiques pour gérer les caractères chinois tronqués dans les bases de données avec PHP
Mar 27, 2024 pm 05:21 PM
PHP est un langage de programmation back-end largement utilisé dans le développement de sites Web. Il possède de puissantes fonctions d'exploitation de bases de données et est souvent utilisé pour interagir avec des bases de données telles que MySQL. Cependant, en raison de la complexité du codage des caractères chinois, des problèmes surviennent souvent lorsqu'il s'agit de caractères chinois tronqués dans la base de données. Cet article présentera les compétences et les pratiques de PHP dans la gestion des caractères chinois tronqués dans les bases de données, y compris les causes courantes des caractères tronqués, les solutions et des exemples de code spécifiques. Les raisons courantes pour lesquelles les caractères sont tronqués sont des paramètres de jeu de caractères incorrects dans la base de données : le jeu de caractères correct doit être sélectionné lors de la création de la base de données, comme utf8 ou u.
 Comment se connecter à une base de données distante à l'aide de Golang ?
Jun 01, 2024 pm 08:31 PM
Comment se connecter à une base de données distante à l'aide de Golang ?
Jun 01, 2024 pm 08:31 PM
Grâce au package base de données/sql de la bibliothèque standard Go, vous pouvez vous connecter à des bases de données distantes telles que MySQL, PostgreSQL ou SQLite : créez une chaîne de connexion contenant les informations de connexion à la base de données. Utilisez la fonction sql.Open() pour ouvrir une connexion à la base de données. Effectuez des opérations de base de données telles que des requêtes SQL et des opérations d'insertion. Utilisez defer pour fermer la connexion à la base de données afin de libérer des ressources.
