
 Périphériques technologiques
IA
Nouvelle épine dorsale d'un réseau visuel léger : mélangeur de jetons d'opérateur de Fourier efficace
Périphériques technologiques
IA
Nouvelle épine dorsale d'un réseau visuel léger : mélangeur de jetons d'opérateur de Fourier efficace
Nouvelle épine dorsale d'un réseau visuel léger : mélangeur de jetons d'opérateur de Fourier efficace

1. Contexte
Au fil des ans, trois réseaux fédérateurs visuels, Transformer, CNN à grand noyau et MLP, ont obtenu un grand succès dans un large éventail de tâches de vision par ordinateur, principalement en raison de leur efficacité à l'échelle mondiale. pour fusionner les informations
Transformer, CNN et MLP sont actuellement les trois réseaux neuronaux principaux, et ils utilisent chacun des méthodes différentes pour réaliser une fusion mondiale de jetons. Dans le réseau Transformer, le mécanisme d'auto-attention utilise la corrélation des paires requête-clé comme poids de la fusion des jetons. CNN atteint des performances similaires à celles de Transformer en augmentant la taille du noyau de convolution. MLP implémente un autre paradigme puissant entre tous les jetons grâce à une connectivité complète. Bien que ces méthodes soient efficaces, elles ont une complexité de calcul élevée (O(N^2)) et sont difficiles à déployer sur des appareils dotés de capacités de stockage et de calcul limitées, limitant ainsi la portée d'application de nombreux modèles
2 AFF Token Mixer. : Léger, global, adaptatif
Afin de résoudre ce problème coûteux en termes de calcul, les chercheurs ont développé une fusion de jetons globale efficace appelée algorithme de filtre de Fourier adaptatif (AFF). Cet algorithme utilise la transformée de Fourier pour convertir l'ensemble de jetons dans le domaine fréquentiel et apprend un masque de filtre capable d'adapter le contenu dans le domaine fréquentiel pour effectuer des opérations de filtrage adaptatif sur l'ensemble de jetons converti dans l'espace du domaine fréquentiel
Filtres de fréquence adaptatifs : Efficient Global Token Mixers

Cliquez sur ce lien pour accéder au texte original : https://arxiv.org/abs/2307.14008
Selon le théorème de convolution du domaine fréquentiel, les mathématiques de AFF Token Mixer L'opération équivalente est une opération de convolution effectuée dans le domaine d'origine, qui équivaut à l'opération produit Hadamard effectuée dans le domaine de Fourier. Cela signifie qu'AFF Token Mixer peut réaliser une fusion globale de jetons adaptative au contenu en utilisant un noyau de convolution dynamique dans le domaine d'origine, dont la résolution spatiale est la même que la taille de l'ensemble de jetons (comme le montre la sous-figure de droite de la figure ci-dessous).
Il est bien connu que la convolution dynamique est coûteuse en termes de calcul, en particulier lors de l'utilisation de noyaux de convolution dynamique avec une grande résolution spatiale. Ce coût semble inacceptable pour une conception de réseau efficace/légère. Cependant, le mélangeur de jetons AFF proposé dans cet article peut répondre simultanément aux exigences ci-dessus dans une implémentation équivalente avec une faible consommation d'énergie, réduisant la complexité de O (N^2) à O (N log N), améliorant ainsi considérablement l'efficacité de calcul
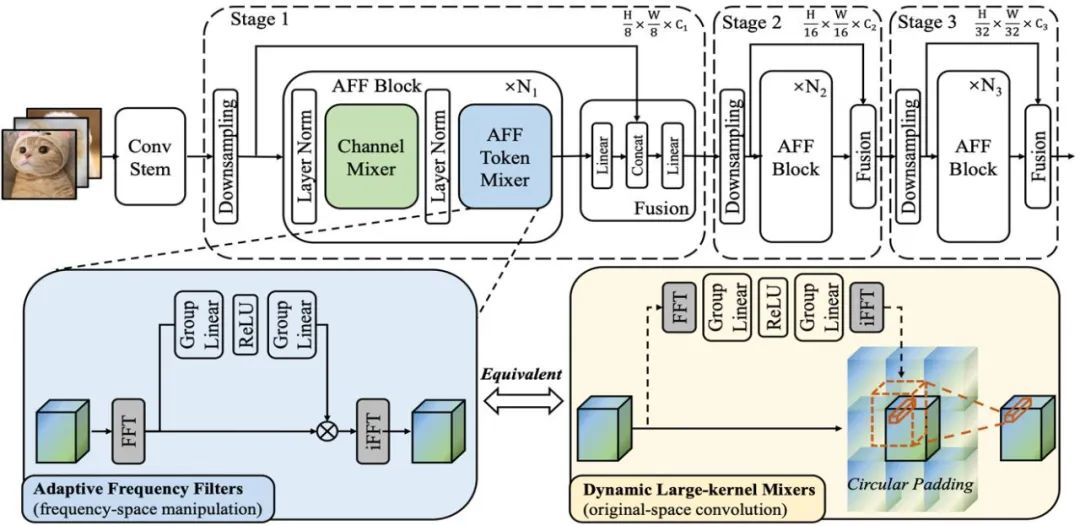
Diagramme schématique 1 : montre la structure du module AFF et du réseau AFFNet
3 AFFNet : la nouvelle épine dorsale du réseau visuel léger
En utilisant AFF Token Mixer comme principal opérateur d'exploitation du réseau neuronal. , Les chercheurs ont réussi à construire un réseau neuronal léger appelé AFFNet. De riches résultats expérimentaux montrent qu'AFF Token Mixer atteint un excellent équilibre entre précision et efficacité dans un large éventail de tâches visuelles, y compris la reconnaissance sémantique visuelle et les tâches de prédiction dense
4 Résultats expérimentaux
Les chercheurs ont évalué les performances d'AFF. Token Mixer et AFFNet sur plusieurs tâches telles que la reconnaissance sémantique visuelle, la segmentation et la détection sont comparés au réseau fédérateur visuel léger le plus avancé dans le domaine de recherche actuel. Les résultats expérimentaux montrent que la conception du modèle fonctionne bien dans un large éventail de tâches visuelles, confirmant le potentiel d'AFF Token Mixer en tant que nouvelle génération d'opérateur de fusion de jetons léger et efficace
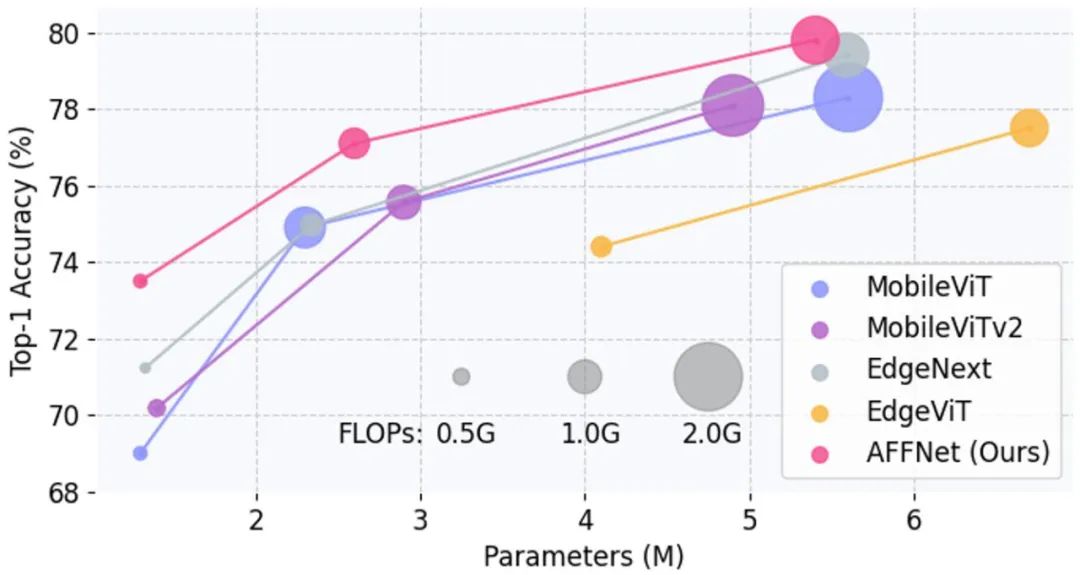
Par rapport à SOTA, la figure 2 montre Acc -Courbes Param et Acc-FLOPs sur l'ensemble de données ImageNet-1K
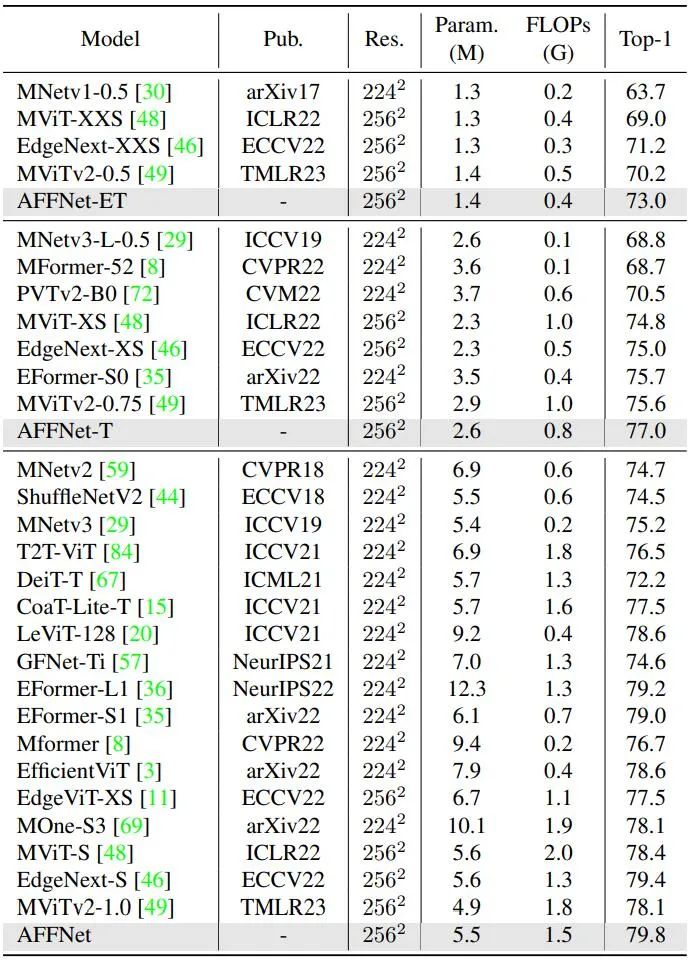
En comparant les résultats des méthodes de pointe avec l'ensemble de données ImageNet-1K, voir Tableau 1
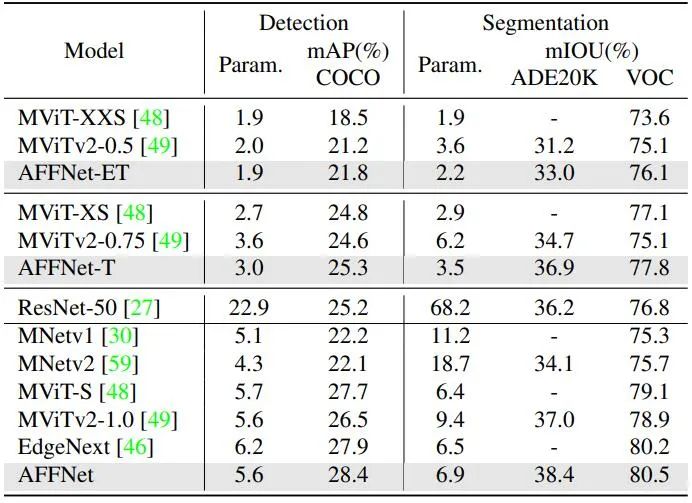
Le tableau 2 montre la comparaison des tâches de détection visuelle et de segmentation avec des techniques de pointe
5. Conclusion
Cette étude prouve que la transformation du domaine fréquentiel dans l'espace latent joue un rôle important dans la fusion adaptative globale des jetons et constitue une implémentation équivalente efficace et de faible consommation. Il fournit de nouvelles idées de recherche pour la conception d'opérateurs de fusion de jetons dans les réseaux de neurones et offre un nouvel espace de développement pour le déploiement de modèles de réseaux de neurones sur des appareils de pointe, en particulier lorsque les capacités de stockage et de calcul sont limitées
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 La multiplication matricielle universelle de CUDA : de l'entrée à la maîtrise !
Mar 25, 2024 pm 12:30 PM
La multiplication matricielle universelle de CUDA : de l'entrée à la maîtrise !
Mar 25, 2024 pm 12:30 PM
La multiplication matricielle générale (GEMM) est un élément essentiel de nombreuses applications et algorithmes, et constitue également l'un des indicateurs importants pour évaluer les performances du matériel informatique. Une recherche approfondie et l'optimisation de la mise en œuvre de GEMM peuvent nous aider à mieux comprendre le calcul haute performance et la relation entre les systèmes logiciels et matériels. En informatique, une optimisation efficace de GEMM peut augmenter la vitesse de calcul et économiser des ressources, ce qui est crucial pour améliorer les performances globales d’un système informatique. Une compréhension approfondie du principe de fonctionnement et de la méthode d'optimisation de GEMM nous aidera à mieux utiliser le potentiel du matériel informatique moderne et à fournir des solutions plus efficaces pour diverses tâches informatiques complexes. En optimisant les performances de GEMM
 Comment calculer l'addition, la soustraction, la multiplication et la division dans un document Word
Mar 19, 2024 pm 08:13 PM
Comment calculer l'addition, la soustraction, la multiplication et la division dans un document Word
Mar 19, 2024 pm 08:13 PM
WORD est un traitement de texte puissant. Nous pouvons utiliser Word pour éditer divers textes. Dans les tableaux Excel, nous maîtrisons les méthodes de calcul d'addition, de soustraction et de multiplicateurs. Ainsi, si nous avons besoin de calculer l'addition de valeurs numériques dans les tableaux Word, Comment soustraire le multiplicateur ? Puis-je utiliser uniquement une calculatrice pour le calculer ? La réponse est bien sûr non, WORD peut aussi le faire. Aujourd'hui, je vais vous apprendre à utiliser des formules pour calculer des opérations de base telles que l'addition, la soustraction, la multiplication et la division dans des tableaux dans des documents Word. Apprenons ensemble. Alors, aujourd'hui, permettez-moi de vous montrer en détail comment calculer l'addition, la soustraction, la multiplication et la division dans un document WORD ? Étape 1 : ouvrez un WORD, cliquez sur [Tableau] sous [Insérer] dans la barre d'outils et insérez un tableau dans le menu déroulant.
 Une plongée approfondie dans les modèles, les données et les frameworks : une revue exhaustive de 54 pages de grands modèles de langage efficaces
Jan 14, 2024 pm 07:48 PM
Une plongée approfondie dans les modèles, les données et les frameworks : une revue exhaustive de 54 pages de grands modèles de langage efficaces
Jan 14, 2024 pm 07:48 PM
Les modèles linguistiques à grande échelle (LLM) ont démontré des capacités convaincantes dans de nombreuses tâches importantes, notamment la compréhension du langage naturel, la génération de langages et le raisonnement complexe, et ont eu un impact profond sur la société. Cependant, ces capacités exceptionnelles nécessitent des ressources de formation importantes (illustrées dans l’image de gauche) et de longs temps d’inférence (illustrés dans l’image de droite). Les chercheurs doivent donc développer des moyens techniques efficaces pour résoudre leurs problèmes d’efficacité. De plus, comme on peut le voir sur le côté droit de la figure, certains LLM (LanguageModels) efficaces tels que Mistral-7B ont été utilisés avec succès dans la conception et le déploiement de LLM. Ces LLM efficaces peuvent réduire considérablement la mémoire d'inférence tout en conservant une précision similaire à celle du LLaMA1-33B
 Comment compter le nombre d'éléments dans une liste à l'aide de la fonction count() de Python
Nov 18, 2023 pm 02:53 PM
Comment compter le nombre d'éléments dans une liste à l'aide de la fonction count() de Python
Nov 18, 2023 pm 02:53 PM
Comment utiliser la fonction count() de Python pour compter le nombre d'éléments dans une liste nécessite des exemples de code spécifiques. En tant que langage de programmation puissant et facile à apprendre, Python fournit de nombreuses fonctions intégrées pour gérer différentes structures de données. L'une d'elles est la fonction count(), qui peut être utilisée pour compter le nombre d'éléments dans une liste. Dans cet article, nous expliquerons en détail comment utiliser la fonction count() et fournirons des exemples de code spécifiques. La fonction count() est une fonction intégrée de Python, utilisée pour calculer un certain
 Compter le nombre d'occurrences d'une sous-chaîne de manière récursive en Java
Sep 17, 2023 pm 07:49 PM
Compter le nombre d'occurrences d'une sous-chaîne de manière récursive en Java
Sep 17, 2023 pm 07:49 PM
Étant donné deux chaînes str_1 et str_2. Le but est de compter le nombre d'occurrences de la sous-chaîne str2 dans la chaîne str1 en utilisant une procédure récursive. Une fonction récursive est une fonction qui s'appelle dans sa définition. Si str1 est "Je sais que vous savez que je sais" et str2 est "savoir", le nombre d'occurrences est de -3 Comprenons à travers des exemples. Par exemple, entrez str1="TPisTPareTPamTP", str2="TP" ; sortie Countofoccurrencesofasubstringrecursi.
 Comment utiliser la fonction Math.Pow en C# pour calculer la puissance d'un nombre spécifié
Nov 18, 2023 am 11:32 AM
Comment utiliser la fonction Math.Pow en C# pour calculer la puissance d'un nombre spécifié
Nov 18, 2023 am 11:32 AM
En C#, il existe une bibliothèque de classes Math, qui contient de nombreuses fonctions mathématiques. Il s'agit notamment de la fonction Math.Pow, qui calcule les puissances, ce qui peut nous aider à calculer la puissance d'un nombre spécifié. L'utilisation de la fonction Math.Pow est très simple, il suffit de spécifier la base et l'exposant. La syntaxe est la suivante : Math.Pow(base,exponent) ; où base représente la base et exponent représente l'exposant. Cette fonction renvoie un résultat de type double, c'est-à-dire le résultat du calcul de puissance. Allons
 Crushing H100, le GPU nouvelle génération de Nvidia se dévoile ! La première conception de module multipuce 3 nm, dévoilée en 2024
Sep 30, 2023 pm 12:49 PM
Crushing H100, le GPU nouvelle génération de Nvidia se dévoile ! La première conception de module multipuce 3 nm, dévoilée en 2024
Sep 30, 2023 pm 12:49 PM
Processus 3 nm, les performances dépassent le H100 ! Récemment, le média étranger DigiTimes a annoncé que Nvidia développait le GPU de nouvelle génération, le B100, dont le nom de code est "Blackwell". Il s'agirait d'un produit destiné aux applications d'intelligence artificielle (IA) et de calcul haute performance (HPC). , le B100 utilisera le processus de traitement 3 nm de TSMC, ainsi qu'une conception de module multi-puces (MCM) plus complexe, et apparaîtra au quatrième trimestre 2024. Pour Nvidia, qui monopolise plus de 80 % du marché des GPU d’intelligence artificielle, il peut utiliser le B100 pour frapper pendant que le fer est chaud et attaquer davantage des challengers comme AMD et Intel dans cette vague de déploiement d’IA. Selon les estimations de NVIDIA, d'ici 2027, la valeur de production de ce domaine devrait atteindre environ
 Programme Java pour calculer l'aire d'un triangle à l'aide de déterminants
Aug 31, 2023 am 10:17 AM
Programme Java pour calculer l'aire d'un triangle à l'aide de déterminants
Aug 31, 2023 am 10:17 AM
Introduction Le programme Java pour calculer l'aire d'un triangle à l'aide d'un déterminant est un programme concis et efficace qui peut calculer l'aire d'un triangle à partir des coordonnées de trois sommets. Ce programme est utile à toute personne qui apprend ou travaille avec la géométrie, car il montre comment utiliser les calculs arithmétiques et algébriques de base en Java, ainsi que comment utiliser la classe Scanner pour lire les entrées de l'utilisateur. Le programme demande à l'utilisateur les coordonnées de trois points du triangle, qui sont ensuite lues et utilisées pour calculer le déterminant de la matrice de coordonnées. Utilisez la valeur absolue du déterminant pour vous assurer que l'aire est toujours positive, puis utilisez une formule pour calculer l'aire du triangle et l'afficher à l'utilisateur. Le programme peut être facilement modifié pour accepter des entrées dans différents formats ou pour effectuer des calculs supplémentaires, ce qui en fait un outil polyvalent pour les calculs géométriques. rangs de déterminants
