
 développement back-end
C++
Comment gérer la déduplication des données dans le développement C++
développement back-end
C++
Comment gérer la déduplication des données dans le développement C++
Comment gérer la déduplication des données dans le développement C++

Comment résoudre le problème de la déduplication des données dans le développement C++
Dans le processus quotidien de développement C++, nous rencontrons souvent des situations où nous devons gérer la déduplication des données. Que vous dédupliquiez des données dans un conteneur ou entre plusieurs conteneurs, vous devez trouver une méthode efficace et fiable. Cet article présentera quelques techniques courantes de déduplication de données pour aider les lecteurs à résoudre les problèmes de déduplication de données dans le développement C++.
1. Méthode de déduplication de tri
La méthode de déduplication de tri est une méthode de déduplication de données courante et simple. Tout d’abord, les données à dédupliquer sont stockées dans un conteneur, puis le conteneur est trié. Après le tri, en comparant les valeurs des éléments adjacents, si les éléments adjacents s'avèrent identiques, les éléments en double sont supprimés pour atteindre l'objectif de déduplication.
Exemple de code :
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main()
{
vector<int> data = { 1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 8 };
sort(data.begin(), data.end());
data.erase(unique(data.begin(), data.end()), data.end());
for (int num : data)
cout << num << " ";
cout << endl;
return 0;
}Le code ci-dessus affichera : 1 2 3 4 5 6 7 8
2 Méthode de déduplication de la table de hachage
La méthode de déduplication de la table de hachage est une méthode de déduplication qui échange de l'espace contre du temps. En utilisant une table de hachage, la valeur de chaque élément est utilisée comme clé et le nombre d'occurrences est utilisé comme valeur, et les données à dédupliquer sont ajoutées à la table de hachage dans l'ordre. Si un élément existe déjà dans la table de hachage, augmentez le nombre d'occurrences de l'élément de une. Enfin, parcourez la table de hachage et stockez les éléments avec une occurrence dans un nouveau conteneur pour terminer la déduplication.
Exemple de code :
#include <iostream>
#include <vector>
#include <unordered_map>
using namespace std;
int main()
{
vector<int> data = { 1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 8 };
unordered_map<int, int> hashTable;
for (int num : data)
hashTable[num]++;
vector<int> result;
for (auto item : hashTable)
{
if (item.second == 1)
result.push_back(item.first);
}
for (int num : result)
cout << num << " ";
cout << endl;
return 0;
}Le code ci-dessus affichera : 1 2 3 6 7
3. Méthode de déduplication de l'algorithme STL
En plus de la méthode ci-dessus, l'algorithme de la bibliothèque standard C++ fournit également des fonctions de déduplication, telles que la fonction unique和remove_if。unique函数将去除相邻重复的元素,而remove_if Détermine s'il faut supprimer des éléments en fonction de conditions définies par l'utilisateur. Ces deux fonctions peuvent être utilisées en combinaison pour dédupliquer facilement les données.
Exemple de code :
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
bool isOdd(int num)
{
return num % 2 != 0;
}
int main()
{
vector<int> data = { 1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 8 };
auto endIter = unique(data.begin(), data.end());
data.erase(endIter, data.end());
data.erase(remove_if(data.begin(), data.end(), isOdd), data.end());
for (int num : data)
cout << num << " ";
cout << endl;
return 0;
}Le code ci-dessus affichera : 2 4 6 8 8
Ce qui précède présente plusieurs méthodes courantes pour traiter les problèmes de déduplication de données dans le développement C++. Chaque méthode a ses propres caractéristiques et scénarios applicables. Dans le développement réel, les lecteurs peuvent choisir la méthode appropriée en fonction de leurs besoins spécifiques. Dans le même temps, les lecteurs peuvent également mettre en œuvre eux-mêmes des algorithmes de déduplication plus efficaces en fonction de leurs exigences de déduplication de données et de leurs besoins en performances. J'espère que cet article aidera les lecteurs à résoudre le problème de la déduplication des données dans le développement C++.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Raisons pour lesquelles les tables sont verrouillées dans Oracle et comment les gérer
Mar 03, 2024 am 09:36 AM
Raisons pour lesquelles les tables sont verrouillées dans Oracle et comment les gérer
Mar 03, 2024 am 09:36 AM
Raisons du verrouillage des tables dans Oracle et comment y remédier Dans la base de données Oracle, le verrouillage des tables est un phénomène courant et il existe de nombreuses raisons pour le verrouillage des tables. Cet article explorera quelques raisons courantes pour lesquelles les tables sont verrouillées et fournira des méthodes de traitement et des exemples de code associés. 1. Types de verrous Dans la base de données Oracle, les verrous sont principalement divisés en verrous partagés (SharedLock) et verrous exclusifs (ExclusiveLock). Les verrous partagés sont utilisés pour les opérations de lecture, permettant à plusieurs sessions de lire la même ressource en même temps.
 Étapes pour résoudre le problème de l'utilisation élevée de la mémoire dans Win7
Dec 27, 2023 pm 10:27 PM
Étapes pour résoudre le problème de l'utilisation élevée de la mémoire dans Win7
Dec 27, 2023 pm 10:27 PM
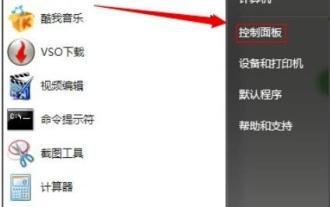
L'espace mémoire de l'ordinateur dépend de la fluidité du fonctionnement de l'ordinateur. Au fil du temps, la mémoire deviendra pleine et l'utilisation sera trop élevée, ce qui entraînera un retard de l'ordinateur. Alors, comment résoudre ce problème ? Jetons un coup d'œil aux solutions ci-dessous. Que faire si l'utilisation de la mémoire Win7 est trop élevée : Méthode 1. Désactivez les mises à jour automatiques 1. Cliquez sur "Démarrer" pour ouvrir le "Panneau de configuration" 2. Cliquez sur "Windows Update" 3. Cliquez sur "Modifier les paramètres" à gauche 4. Sélectionnez le Méthode « Ne jamais rechercher les mises à jour » 2. Suppression de logiciels : désinstallez tous les logiciels inutiles. Méthode 3 : fermez les processus et mettez fin à tous les processus inutiles, sinon de nombreuses publicités en arrière-plan rempliront la mémoire. Méthode 4 : Désactiver les services De nombreux services inutiles du système sont également fermés, ce qui garantit non seulement la sécurité mais permet également d'économiser de l'espace.
 Comment gérer les conflits de noms dans le développement C++
Aug 22, 2023 pm 01:46 PM
Comment gérer les conflits de noms dans le développement C++
Aug 22, 2023 pm 01:46 PM
Comment gérer les conflits de noms dans le développement C++ Les conflits de noms sont un problème courant lors du développement C++. Lorsque plusieurs variables, fonctions ou classes portent le même nom, le compilateur ne peut pas déterminer laquelle est référencée, ce qui entraîne des erreurs de compilation. Pour résoudre ce problème, C++ propose plusieurs méthodes pour gérer les conflits de noms. Utilisation des espaces de noms Les espaces de noms constituent un moyen efficace de gérer les conflits de noms en C++. Les conflits de noms peuvent être évités en plaçant les variables, fonctions ou classes associées dans le même espace de noms. Par exemple, vous pouvez créer
 Comment résoudre les problèmes de connexion au bureau à distance QQ
Dec 26, 2023 am 11:55 AM
Comment résoudre les problèmes de connexion au bureau à distance QQ
Dec 26, 2023 am 11:55 AM
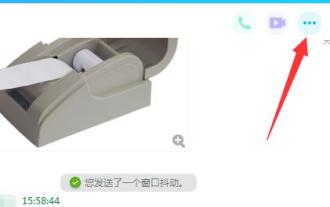
QQ est un logiciel de chat produit par Tencent. Presque tout le monde possède un compte QQ et peut se connecter et fonctionner à distance lorsqu'il discute. Cependant, certains utilisateurs rencontrent le problème de ne pas pouvoir se connecter, alors que doivent-ils faire ? Jetons un coup d'oeil ci-dessous. Que faire si QQ Remote Desktop ne parvient pas à se connecter : 1. Ouvrez l'interface de discussion, cliquez sur l'icône "..." dans le coin supérieur droit 2. Sélectionnez l'icône rouge de l'ordinateur et cliquez sur "Paramètres" 3. Cliquez sur "Définir les autorisations—> Bureau à distance" 4. Cochez "Autoriser le Bureau à distance à se connecter à cet ordinateur"
 Plug-in de base de données React Query : un moyen de réaliser la déduplication et le débruitage des données
Sep 27, 2023 pm 03:30 PM
Plug-in de base de données React Query : un moyen de réaliser la déduplication et le débruitage des données
Sep 27, 2023 pm 03:30 PM
ReactQuery est une puissante bibliothèque de gestion de données qui fournit de nombreuses fonctions et fonctionnalités pour travailler avec des données. Lorsque nous utilisons ReactQuery pour la gestion des données, nous rencontrons souvent des scénarios nécessitant une déduplication et un débruitage des données. Afin de résoudre ces problèmes, nous pouvons utiliser le plug-in de base de données ReactQuery pour réaliser des fonctions de déduplication et de débruitage des données d'une manière spécifique. Dans ReactQuery, vous pouvez utiliser des plug-ins de base de données pour traiter facilement les données
 Comment mettre en œuvre un système de fabrication intelligent grâce au développement C++ ?
Aug 26, 2023 pm 07:27 PM
Comment mettre en œuvre un système de fabrication intelligent grâce au développement C++ ?
Aug 26, 2023 pm 07:27 PM
Comment mettre en œuvre un système de fabrication intelligent grâce au développement C++ ? Avec le développement des technologies de l'information et les besoins de l'industrie manufacturière, les systèmes de fabrication intelligents sont devenus une direction de développement importante de l'industrie manufacturière. En tant que langage de programmation efficace et puissant, C++ peut apporter un soutien important au développement de systèmes de fabrication intelligents. Cet article présentera comment implémenter des systèmes de fabrication intelligents via le développement C++ et donnera des exemples de code correspondants. 1. Composants de base d'un système de fabrication intelligent Un système de fabrication intelligent est un système de production hautement automatisé et intelligent. Il se compose principalement des composants suivants :
 Comment gérer les problèmes de blocage dans le développement C++
Aug 22, 2023 pm 02:24 PM
Comment gérer les problèmes de blocage dans le développement C++
Aug 22, 2023 pm 02:24 PM
Comment gérer les problèmes de blocage dans le développement C++ Le blocage est l'un des problèmes courants dans la programmation multithread, en particulier lors du développement en C++. Des problèmes de blocage peuvent survenir lorsque plusieurs threads attendent les ressources de chacun. S'il n'est pas traité à temps, un blocage entraînera non seulement le gel du programme, mais affectera également les performances et la stabilité du système. Par conséquent, il est très important d’apprendre à gérer les problèmes de blocage dans le développement C++. 1. Comprendre les causes des blocages. Pour résoudre le problème de blocage, vous devez d'abord comprendre les causes des blocages. Une impasse se produit généralement lorsque
 Comment résoudre le problème de connexion à distance Win10
Dec 27, 2023 pm 11:09 PM
Comment résoudre le problème de connexion à distance Win10
Dec 27, 2023 pm 11:09 PM
Lors de l'utilisation de Win10 Remote Desktop pour une connexion à distance, de nombreux utilisateurs ont déclaré que lorsqu'ils se connectaient, l'invite échouait et la connexion ne pouvait pas aboutir. En fait, il se peut que les autorisations appropriées ne soient pas ouvertes dans les paramètres système. ouvrez-le. Résolu. Que faire si la connexion à distance Win10 échoue : Méthode 1 : 1. Cliquez avec le bouton droit sur le bureau et sélectionnez. 2. Cliquez ensuite sur la colonne de gauche. 3. Ensuite, vérifiez. Très bien. Méthode 2 : 1. Ouvrez d'abord le panneau de configuration de Win10, remplacez le coin supérieur droit par une petite icône et ouvrez « Pare-feu Windows ». 2. Après l'avoir ouvert, entrez les paramètres « Autoriser les applications ou fonctions via le pare-feu Windows Defender », où assurer "Assistance à distance" et "bureau à distance"
