
Cinq principes architecturaux
Tout d'abord, cela signifie que les données demandées par l'utilisateur doivent être aussi petites que possible. Les données demandées comprennent les données téléchargées sur le système et les données renvoyées par le système à l'utilisateur (généralement une page Web).
Une fois la page demandée par l'utilisateur renvoyée, le navigateur inclura d'autres requêtes supplémentaires lors du rendu de la page, par exemple, le CSS/JavaScript, les images et Ajax. requêtes dont dépend cette page Définies comme des « requêtes supplémentaires », ces requêtes supplémentaires doivent être réduites au minimum.
C'est le nombre de nœuds intermédiaires par lesquels l'utilisateur doit passer dans le processus depuis la demande jusqu'au retour des données.
fait référence au système ou au service sur lequel on doit s'appuyer pour répondre à une demande d'utilisateur. Les dépendances font ici référence à de fortes dépendances.
Un point unique dans le système peut être considéré comme un tabou dans l'architecture système, car un seul point signifie aucune sauvegarde et des risques incontrôlables. Le principe le plus important dans la conception de systèmes distribués est « d'éliminer les points uniques ». , un autre nom est « haute disponibilité ».
L'architecture est un art de l'équilibre, et une fois que la meilleure architecture est séparée de la scène à laquelle elle s'adapte, tout ne sera plus qu'un discours vide de sens. Ce que nous devons retenir, c’est que les points mentionnés ici ne sont que des orientations. Nous devons faire de notre mieux pour travailler dans ces directions, mais nous devons également envisager d’équilibrer d’autres facteurs.
Alors, qu'est-ce que la séparation dynamique et statique exactement ? La soi-disant « séparation dynamique et statique » consiste en fait à diviser les données demandées par les utilisateurs (telles que les pages HTML) en « données dynamiques » et « données statiques ». En termes simples, la principale différence entre les « données dynamiques » et les « données statiques » est de voir si les données affichées dans la page sont liées à l'URL, au navigateur, à l'heure, à la région et si elles contiennent des données privées telles que des cookies.
Tout d'abord, vous devez mettre en cache les données statiques les plus proches de l'utilisateur. Les données statiques sont des données relativement inchangées, nous pouvons donc les mettre en cache. Où est-il mis en cache ? Il en existe trois courants : dans le navigateur de l'utilisateur, sur le CDN ou dans le Cache du serveur. Vous devez les mettre en cache le plus près possible de l'utilisateur en fonction de la situation.
Deuxièmement, la transformation statique consiste à mettre directement en cache les connexions HTTP. Par rapport à la mise en cache de données ordinaire, vous devez avoir entendu parler de transformation statique du système. La transformation statique met directement en cache la connexion HTTP au lieu de simplement mettre les données en cache. Comme le montre la figure ci-dessous, le serveur proxy Web extrait directement l'en-tête de réponse HTTP et le corps de la réponse correspondants en fonction de l'URL de la demande et les renvoie directement par ce processus de réponse. est si simple qu'il n'utilise même pas le protocole HTTP réassemblé, même les en-têtes de requête HTTP n'ont pas besoin d'être analysés.
Troisièmement, qui met en cache les données statiques est également important. Les logiciels de cache écrits dans différentes langues ont des efficacités différentes dans le traitement des données mises en cache. Prenons Java comme exemple, car le système Java lui-même a aussi ses faiblesses (par exemple, il n'est pas efficace pour gérer un grand nombre de demandes de connexion, chaque connexion consomme plus de mémoire et le conteneur Servlet est lent à analyser le protocole HTTP) , vous ne pouvez donc pas effectuer de mise en cache au niveau de la couche Java, mais faites-le directement sur la couche du serveur Web, afin de pouvoir protéger certaines faiblesses au niveau du langage Java. En comparaison, les serveurs Web (tels que Nginx, Apache, Varnish) le sont ; également mieux à gérer les demandes de fichiers statiques simultanées volumineuses.
Selon la complexité de l'architecture, 3 options sont possibles :
Déploiement sur une seule machine :
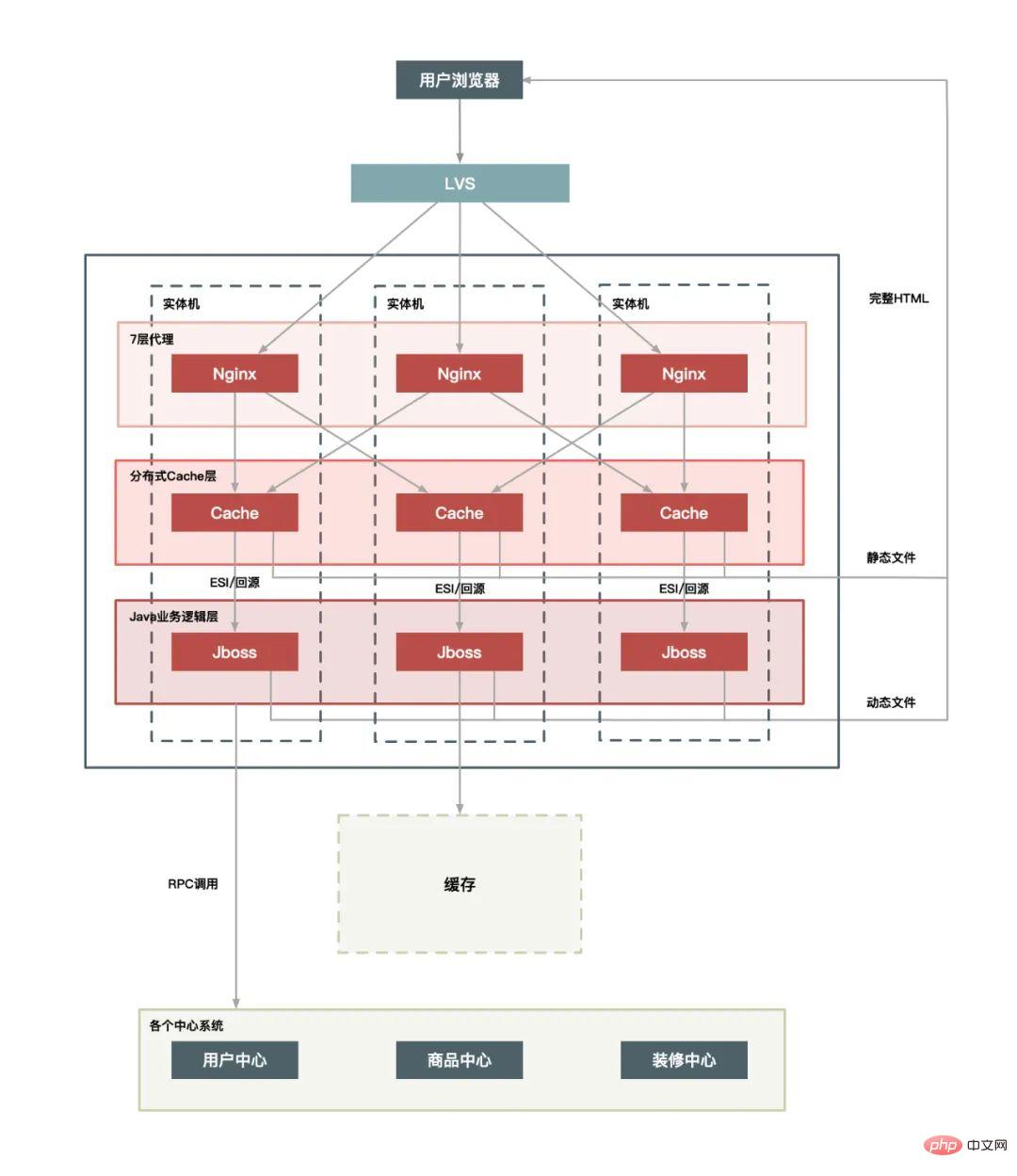
Couche de cache unifiée :
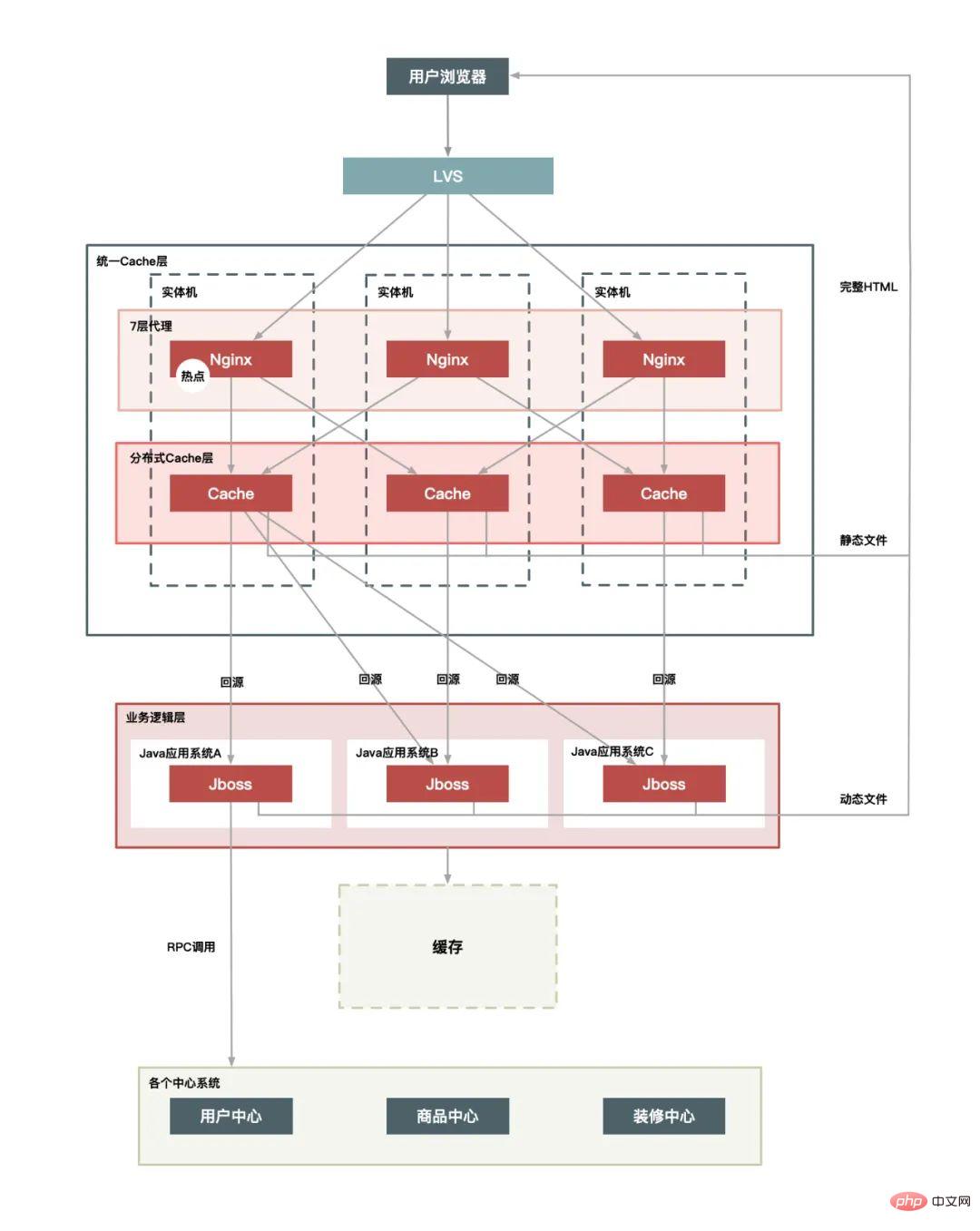
plus CDN Layer :
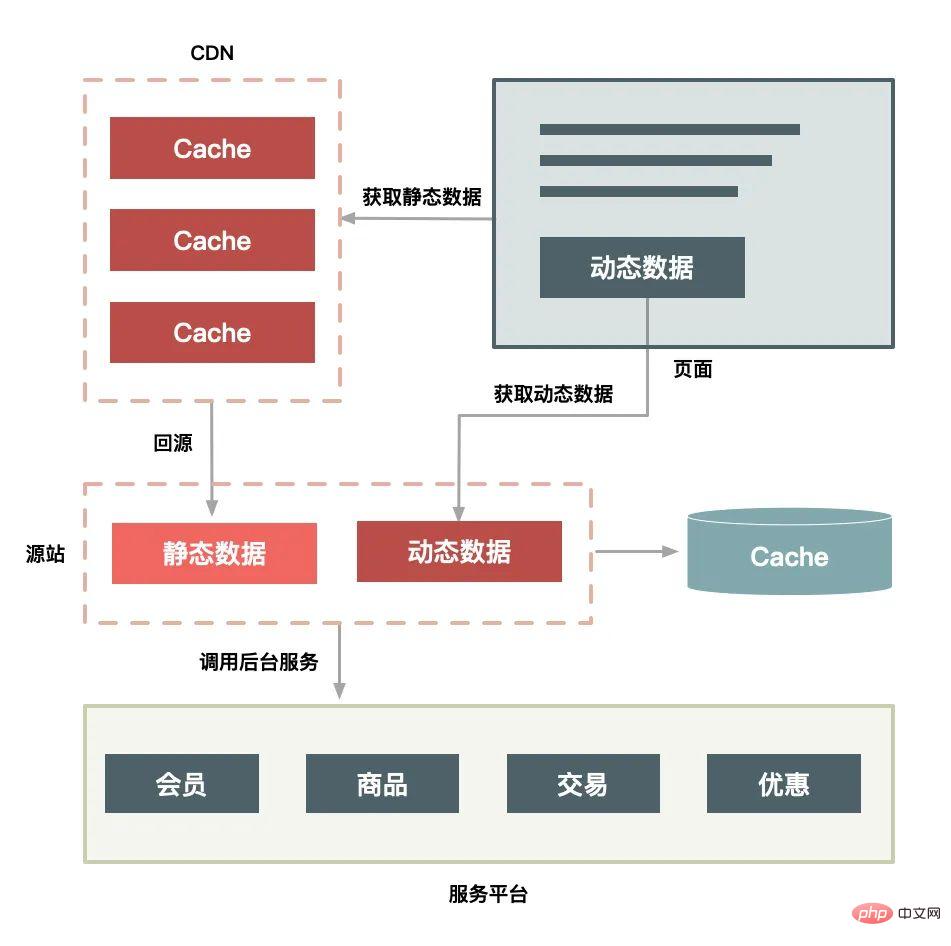
La solution de déploiement CDN présente également les fonctionnalités suivantes :
Les hotspots sont divisés en opérations de hotspot et en données de hotspot.
Les opérations dites "à chaud", comme un grand nombre de rafraîchissements de pages, un grand nombre d'ajouts de paniers, un grand nombre de commandes passées à 0h00 sur Double Eleven, etc., entrent toutes dans cette catégorie. . Pour le système, ces opérations peuvent être résumées en « requêtes de lecture » et « requêtes d'écriture ». Ces deux requêtes de hotspot sont traitées de manières très différentes. L'espace d'optimisation pour les requêtes de lecture est plus grand, tandis que le goulot d'étranglement pour les requêtes d'écriture est généralement dans le domaine. couche de stockage. L'idée de l'optimisation est d'équilibrer sur la base de la théorie CAP. Je présenterai ce contenu en détail dans l'article "Réduire les stocks".
Les « données de hotspot » sont plus faciles à comprendre, c'est-à-dire les données correspondant à la demande de hotspot de l'utilisateur. Les données de points d'accès sont divisées en « données de points d'accès statiques » et « données de points d'accès dynamiques ».
Les « données de points d'accès statiques » font référence à des données de points d'accès qui peuvent être prédites à l'avance. Par exemple, nous pouvons filtrer les vendeurs à l'avance grâce à l'enregistrement et marquer ces produits phares via le système d'enregistrement. En outre, nous pouvons également utiliser l'analyse du Big Data pour découvrir à l'avance les produits phares. Par exemple, nous analysons les enregistrements de transactions historiques et les enregistrements de panier d'achat des utilisateurs pour découvrir quels produits peuvent être les plus populaires et les mieux vendus. être analysés au préalable.
Les « données de points chauds dynamiques » font référence à des points chauds qui ne peuvent pas être prédits à l'avance et qui sont temporairement générés pendant le fonctionnement du système. Par exemple, un vendeur fait de la publicité sur Douyin, puis le produit devient immédiatement populaire, ce qui entraîne son achat en grande quantité sur une courte période de temps.
Étant donné que les opérations de hotspot sont des comportements d'utilisateurs, nous ne pouvons pas les modifier, mais nous pouvons mettre en place certaines restrictions et protections. Par conséquent, dans cet article, je présenterai principalement comment optimiser les données de hotspot.
Optimisation
Le moyen le plus efficace d'optimiser les données des points d'accès est de mettre en cache données de point d'accès , si les données de point d'accès sont séparées des données statiques, les données statiques peuvent être mises en cache pendant une longue période. Cependant, la mise en cache des données de hotspot est davantage un cache « temporaire », c'est-à-dire qu'il s'agit de données statiques ou de données dynamiques, elles sont brièvement mises en cache dans une file d'attente pendant quelques secondes. La longueur de la file d'attente étant limitée, elle peut être remplacée par. l'algorithme d'élimination LRU.
Restrictions
La restriction est davantage un mécanisme de protection, et il existe de nombreuses façons de la restreindre. Par exemple, effectuez un hachage cohérent sur l'ID du produit accédé, puis regroupez-le en fonction du hachage. afin que les produits chauds puissent être limités à une file d'attente de requêtes pour éviter que certains produits chauds ne consomment trop de ressources du serveur et que d'autres demandes ne reçoivent jamais de ressources de traitement du serveur.
Isolement
Le premier principe de la conception d'un système de vente flash est d'isoler ce type de données chaudes. Ne laissez pas 1% des demandes affecter les 99% restants. Après l'isolement, il sera plus pratique de gérer les. 1% des demandes. Optimisation ciblée. L'isolation peut être divisée en : isolation de l'entreprise, isolation du système et isolation des données.
Comment réduire les pointes de circulation
Tout comme les routes de la ville, en raison des problèmes de pointe du matin et de pointe du soir, il existe une solution de déplacement des pointes et de restriction de circulation.
L'existence d'écrêtage de pointe peut, d'une part, rendre le traitement du serveur plus stable, et d'autre part, elle peut économiser le coût des ressources du serveur.
Pour le scénario de vente flash, le Peak Clipping consiste essentiellement à retarder davantage l'émission des demandes des utilisateurs afin de réduire et de filtrer certaines demandes invalides. Il suit le principe selon lequel « le nombre de demandes doit être aussi petit que possible ».
Pour atteindre les pics de trafic, la solution la plus simple à laquelle penser est d'utiliser des files d'attente de messages pour tamponner le trafic instantané, convertir les appels directs synchrones en push indirects asynchrones et transmettre une file d'attente qui gère le trafic instantané. atteint un sommet à une extrémité et diffuse les messages en douceur à l'autre extrémité.
En plus des files d'attente de messages, il existe de nombreuses méthodes de mise en file d'attente similaires, telles que :
On peut voir que ces méthodes ont une caractéristique commune, qui est de transformer « l'opération en une étape » en une « opération en deux étapes », dans laquelle l'opération en une étape ajoutée est utilisée pour agir comme un tampon.
"Inventaire" logique de base de réduction"C'est-à-dire qu'une fois que l'acheteur a passé une commande, la quantité achetée par l'acheteur sera soustraite de l'inventaire total du produit. Passer une commande pour réduire les stocks est le moyen le plus simple de réduire les stocks, mais c'est aussi la méthode de contrôle la plus précise. Lors de la passation d'une commande, l'inventaire des marchandises est directement contrôlé par le mécanisme de transaction de la base de données, de sorte que les conditions de survente soient prises en compte. ne se produit pas. Mais il faut savoir que certaines personnes peuvent ne pas payer après avoir passé une commande.
C'est-à-dire qu'une fois que l'acheteur a passé la commande, l'inventaire n'est pas réduit immédiatement, mais l'inventaire est en fait réduit jusqu'à ce qu'un utilisateur paie, sinon l'inventaire sera réservé à d'autres acheteurs. Toutefois, étant donné que les stocks ne sont réduits qu'après le paiement, si la concurrence est relativement élevée, il peut arriver que l'acheteur ne puisse pas payer après avoir passé la commande, car les marchandises peuvent avoir été achetées par d'autres.
Cette méthode est relativement compliquée. Une fois que l'acheteur a passé une commande, l'inventaire est réservé pendant une certaine période (par exemple 10 minutes). Passé ce délai, l'inventaire sera automatiquement remis à d'autres. acheteurs après la sortie. Vous pouvez continuer à acheter. Avant que l'acheteur ne paie, le système vérifiera si l'inventaire de la commande est toujours réservé : s'il n'y a pas de réservation, la retenue sera retentée si l'inventaire est insuffisant (c'est-à-dire que la retenue échoue), le paiement ne sera pas effectué ; être autorisé à continuer si la retenue réussit, Le paiement est alors effectué et l'inventaire est effectivement déduit.
En parlant de construction à haute disponibilité du système, il s'agit en fait d'un projet de système qui doit prendre en compte toutes les étapes de la construction du système, ce qui signifie qu'il passe par tout le cycle de vie de la construction du système, comme le montre l'image ci-dessous :
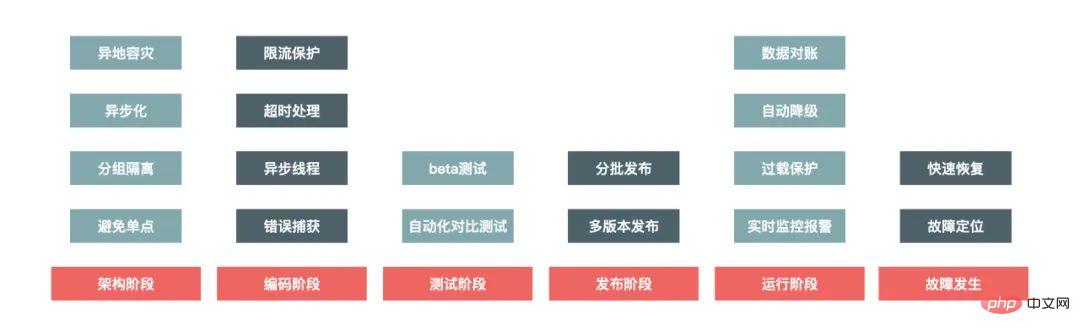
La phase d'architecture prend principalement en compte l'évolutivité et la tolérance aux pannes du système, et évite les problèmes ponctuels dans le système. Par exemple, dans le déploiement unitaire de plusieurs salles informatiques, même si une certaine salle informatique dans une certaine ville souffre d'une panne globale, cela n'affectera toujours pas le fonctionnement de l'ensemble du site Web.
La chose la plus importante dans le codage est de garantir la robustesse du code. Par exemple, lorsqu'il s'agit de problèmes d'appels à distance, un mécanisme de sortie de délai d'attente raisonnable doit être mis en place pour éviter d'être entraîné par d'autres. systèmes, et l'ensemble de résultats renvoyé par l'appel doit également être garanti. Afin d'éviter que les résultats renvoyés ne dépassent la plage de traitement du programme, la méthode la plus courante consiste à capturer les exceptions d'erreur et à avoir des résultats de traitement par défaut pour les erreurs imprévues.
Les tests visent principalement à assurer la couverture des cas de test et à garantir que lorsque le pire des cas se produit, nous disposons également de procédures de traitement correspondantes.
Il y a également certaines choses auxquelles il faut prêter attention lors de la publication, car des erreurs sont plus susceptibles de se produire pendant la publication, un mécanisme de restauration d'urgence doit donc être en place.
Le temps de fonctionnement est l'état normal du système. Le système sera en état de fonctionnement la plupart du temps. La chose la plus importante dans l'état de fonctionnement est que la surveillance du système doit être précise et. en temps opportun. Si des problèmes sont détectés, l'alarme doit être précise et les données d'alarme doivent être précises et détaillées pour faciliter le dépannage.
Lorsqu'un défaut se produit, la première et la plus importante chose est d'arrêter la perte de temps. Par exemple, si le prix du produit est erroné en raison d'un problème de programme, le produit doit être retiré des rayons. ou le lien d'achat doit être fermé à temps pour éviter des pertes d'actifs importantes. Ensuite, il est nécessaire de pouvoir restaurer les services en temps opportun, localiser la cause et résoudre le problème.
Comment devrions-nous maximiser le fonctionnement normal de notre système lorsque nous sommes confrontés à un trafic intense ?
Le soi-disant « downgrade » signifie que lorsque la capacité du système atteint un certain niveau, certaines fonctions non essentielles du système sont restreintes ou arrêtées, réservant ainsi des ressources limitées à des activités plus essentielles. Il s’agit d’un processus d’exécution ciblé et planifié, donc pour un déclassement, nous avons généralement besoin d’un ensemble de plans pour coordonner l’exécution. Si nous le systématisons, nous pouvons parvenir à une dégradation grâce à un système de planification et un système de commutation.
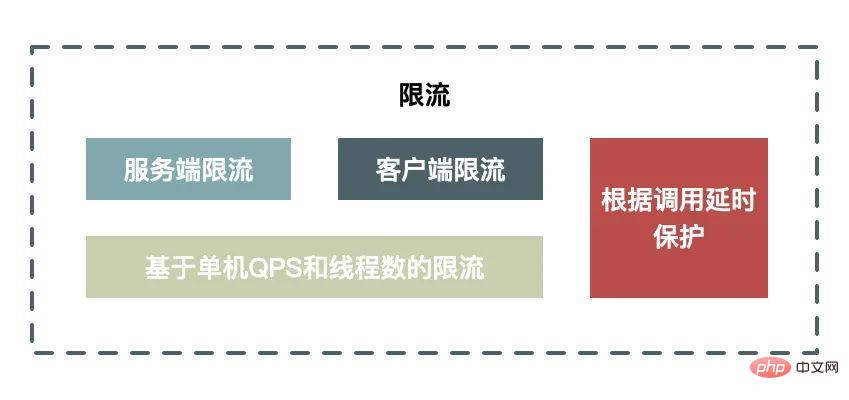
La limitation de courant signifie que lorsque la capacité du système atteint le goulot d'étranglement, nous devons protéger le système en limitant une partie du trafic, et pouvons non seulement effectuer une commutation manuelle, mais également prendre en charge une protection automatisée mesures.
Avantages et inconvénients de la limitation de courant côté client et de la limitation de courant côté serveur :
La limitation de courant côté client a l'avantage de limiter l'émission de requêtes et de réduire la consommation du système en réduisant l'émission de requêtes inutiles. L'inconvénient est que lorsque les clients sont dispersés, il est impossible de définir un seuil de limitation de courant raisonnable : si le seuil est trop petit, le client sera restreint avant que le serveur n'atteigne le goulot d'étranglement ; s'il est trop grand, il ne le sera pas ; être capable de Le rôle des restrictions.
L'avantage de la limitation de courant côté serveur est qu'un seuil raisonnable peut être défini en fonction des performances du serveur. L'inconvénient est que les requêtes restreintes sont des requêtes invalides et que le traitement lui-même de ces requêtes invalides consommera également des ressources du serveur.
Algorithme de compteur (fenêtre fixe)
L'algorithme de compteur utilise un compteur pour accumuler le nombre de visites dans un cycle Lorsque la valeur limite de courant définie est atteinte, le courant. une stratégie de limitation est déclenchée. Au début du cycle suivant, il est effacé et recompté.
Cet algorithme est très simple à implémenter dans un environnement autonome ou distribué. Il peut être facilement implémenté en utilisant l'auto-incrémentation atomique incr et la sécurité des threads de redis.
Algorithme de fenêtre coulissante
L'algorithme de fenêtre glissante divise la période de temps en N petites périodes, enregistre le nombre de visites dans chaque petite période et supprime les petites périodes expirées en fonction du glissement temporel. Cet algorithme peut bien résoudre le problème critique de l’algorithme à fenêtre fixe.
Algorithme de compartiment qui fuit
L'algorithme de compartiment qui fuit consiste à placer directement la demande d'accès dans le compartiment qui fuit lorsqu'elle arrive. Si la capacité actuelle a atteint la limite supérieure (valeur limite actuelle), elle sera rejetée (déclenchant le courant). politique de limite). Le compartiment qui fuit libère les demandes d'accès (c'est-à-dire que les demandes sont acceptées) à un rythme fixe jusqu'à ce que le compartiment qui fuit soit vide.
Algorithme de seau de jetons
L'algorithme de seau de jetons est que le programme ajoute des jetons au seau de jetons à un taux de r (r = période de temps/valeur limite actuelle) jusqu'à ce que le seau de jetons soit plein, et ajoute des jetons au jeton. bucket lorsque la demande arrive Jeton de demande de bucket, si le jeton est obtenu, la demande sera transmise, sinon la politique de limitation actuelle sera déclenchée
Si la limitation actuelle ne peut pas résoudre le problème, le dernier recours est pour refuser directement le service. Lorsque la charge du système atteint un certain seuil, par exemple, l'utilisation du processeur atteint 90 % ou la valeur de charge du système atteint 2*cœurs de processeur, le système rejette directement toutes les requêtes. Cette méthode est la méthode de protection du système la plus violente mais aussi la plus efficace. . Par exemple, pour le système de vente flash, nous concevons une protection contre les surcharges dans les aspects suivants :
Définissez une protection contre les surcharges sur le front-end Nginx Lorsque la charge de la machine atteint une certaine valeur, la requête HTTP sera directement rejetée et une erreur 503. le code sera renvoyé. La même chose peut être faite au niveau de la couche Java. Conçu avec une protection contre les surcharges.
Le déni de service peut être considéré comme une solution de dernier recours pour éviter que le pire des cas ne se produise et empêcher le serveur d'être complètement incapable de fournir des services pendant une longue période en raison d'une surcharge du serveur. Bien qu'une telle protection contre les surcharges du système ne puisse pas fournir de services en cas de surcharge, le système peut toujours fonctionner et peut facilement récupérer lorsque la charge chute. Par conséquent, chaque système et chaque liaison doivent configurer ce plan de sauvegarde pour préparer le système au pire des cas. sous protection.
Les données ne sont pas chargées dans le cache, ou le cache échoue dans une grande zone en même temps, ce qui oblige toutes les requêtes à rechercher la base de données, provoquant la base de données, le processeur et surcharge de mémoire, voire temps d'arrêt.
Un processus d'avalanche simple :
1) Échec à grande échelle du cluster Redis ;
2) Échec de la mise en cache, mais il y a encore un grand nombre de demandes d'accès au service de cache Redis ;
3) Après un grand nombre de demandes ; des échecs de requêtes Redis, les requêtes sont détournées vers la base de données ;
4) Les requêtes de base de données augmentent fortement, provoquant la destruction de la base de données
5) Étant donné que la plupart de vos services d'application dépendent de la base de données et des services Redis, ce sera bientôt le cas ; provoquer une avalanche du cluster de serveurs, et finalement tout le système s'effondrera complètement.
Solution :
Au préalable : Cache hautement disponible
Le cache hautement disponible permet d'éviter toute défaillance du cache. Même si des nœuds individuels, des machines ou même des salles informatiques sont arrêtés, le système peut toujours fournir des services, et Redis Sentinel et Redis Cluster peuvent atteindre une haute disponibilité.
En cours : Rétrogradation du cache (support temporaire)
Comment pouvons-nous nous assurer que le service est toujours disponible lorsqu'une forte augmentation des visites entraîne des problèmes avec le service. Hystrix, largement utilisé en Chine, utilise trois méthodes : la fusion, le déclassement et la limitation de courant pour réduire les pertes après avalanches. Tant que la base de données n'est pas morte, le système peut toujours répondre aux demandes. N'est-ce pas ainsi que nous venons ici à chaque Fête du Printemps 12306 ? Tant que vous pouvez encore répondre, vous avez au moins une chance d’obtenir un ticket.
Après l'événement : sauvegarde Redis et préchauffage rapide
1) Sauvegarde et restauration des données Redis
2) Préchauffage rapide du cache
La panne du cache signifie que le stockage des données du point d'accès expire, plusieurs threads demandent des données de point d'accès en même temps. Étant donné que le cache vient d'expirer, toutes les requêtes simultanées seront envoyées à la base de données pour interroger les données.
Solution :
En fait, dans la plupart des scénarios commerciaux réels, la panne du cache se produit en temps réel, mais cela ne causera pas trop de pression sur la base de données, car dans les affaires générales d'une entreprise, le niveau de concurrence ne sera pas aussi important. haut . Bien sûr, si vous avez le malheur que cela se produise, vous pouvez définir ces clés de point d'accès pour qu'elles n'expirent jamais. Une autre méthode consiste à utiliser un verrou mutex pour contrôler l'accès des threads à la base de données de requêtes, mais cela entraînera une diminution du débit du système et devra être utilisé dans des situations réelles.
La pénétration du cache fait référence à l'interrogation de données qui n'existent certainement pas. Parce qu'il n'y a aucune information sur les données dans le cache, elles iront directement à la couche de base de données pour une interrogation au niveau du système. comme la pénétration. La couche de cache atteint directement la base de données, ce qui est appelé pénétration du cache, ce type de requête pour des données qui ne doivent pas exister peut constituer un danger pour le système si quelqu'un utilise ces données de manière malveillante. Il ne doit pas exister de requêtes fréquentes adressées au système, non, pour être précis, d'attaques sur le système, les requêtes atteindront la couche de base de données, provoquant une paralysie de la base de données et une panne du système.
Solution :
Les solutions dans le secteur de la pénétration du cache sont relativement matures. Les principales couramment utilisées sont les suivantes :
Étant donné que cet article est un article théorique, il n'y a pas une seule ligne de code dans tout l'article, mais ce qui est proposé dans l'article est essentiellement ce qui s'est passé dans le système de vente flash, et les problèmes qui peuvent survenir dans chaque système sont différents.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment résoudre le problème selon lequel Ethernet ne peut pas se connecter à Internet
Comment résoudre le problème selon lequel Ethernet ne peut pas se connecter à Internet
 Comment supprimer des données dans MongoDB
Comment supprimer des données dans MongoDB
 Causes et solutions des erreurs d'exécution
Causes et solutions des erreurs d'exécution
 Comment installer le pilote d'imprimante sous Linux
Comment installer le pilote d'imprimante sous Linux
 Comment résoudre 400mauvaises requêtes
Comment résoudre 400mauvaises requêtes
 centos7 fermer le pare-feu
centos7 fermer le pare-feu
 Comment supprimer la dernière page vierge dans Word
Comment supprimer la dernière page vierge dans Word
 Oracle ajoute une méthode de déclenchement
Oracle ajoute une méthode de déclenchement








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



