
 Problème commun
Solution rapide en 10 minutes | Architecture du système de commerce électronique distribué à grande échelle
Problème commun
Solution rapide en 10 minutes | Architecture du système de commerce électronique distribué à grande échelle
Solution rapide en 10 minutes | Architecture du système de commerce électronique distribué à grande échelle
Cet article est un résumé technique de l'apprentissage de l'architecture de sites Web distribués à grande échelle. Une brève description de l'architecture d'un site Web distribué performant, hautement disponible, évolutif et extensible, ainsi qu'une référence architecturale sont données. Une partie de l'article consiste à lire des notes et une partie est un résumé de l'expérience personnelle, qui a une bonne valeur de référence pour l'architecture de sites Web distribués à grande échelle.
Technologie d'architecture de sites Web distribués à grande échelle
1 Caractéristiques des sites Web à grande échelle
Beaucoup d'utilisateurs, large distribution -
Trafic important, concurrence élevée . -
Données massives, le service est hautement disponible L'environnement de sécurité est médiocre et vulnérable aux attaques réseau Fonctions multiples, développement plus rapide, versions fréquentes Développer progressivement de petit à grand Utilisateur- centré Service gratuit, expérience payante
2. Grands objectifs d'architecture de site Web
Haute performance : offrir une expérience d'accès rapide. Haute disponibilité : Le service du site Internet est toujours accessible normalement. Évolutif : augmenter/diminuer, augmenter/diminuer la puissance de traitement via le matériel. Sécurité : fournit un accès sécurisé au site Web et le cryptage des données, un stockage sécurisé et d'autres stratégies. Extensibilité : ajoutez/supprimez facilement de nouvelles fonctions/modules. Agilité : sur demande, réponse rapide

3. Modèle d'architecture de grand site Web

Layering : peut généralement être divisé en couche d'application et couche de service, données couche, couche de gestion et couche d'analyse ; segmentation : généralement divisée selon les caractéristiques métier/module/fonctionnelles, par exemple, la couche application est divisée en page d'accueil et centre utilisateur. Distribué : déployez des applications séparément (telles que plusieurs machines physiques) et travaillez ensemble via des appels à distance. Cluster : une application/un module/une fonction est déployé en plusieurs copies (telles que plusieurs machines physiques) pour fournir conjointement un accès externe via l'équilibrage de charge. Mise en cache : placez les données au plus près de l'application ou de l'utilisateur pour accélérer l'accès. Asynchrone : asynchrone les opérations synchrones. Le client envoie une demande sans attendre la réponse du serveur. Une fois le traitement terminé, le serveur utilise une notification ou une interrogation pour informer le demandeur. Désigne généralement : le mode requête-réponse-notification. Redondance : augmentez les répliques pour améliorer la disponibilité, la sécurité et les performances. Sécurité : avoir des solutions efficaces aux problèmes connus et établir des mécanismes de découverte et de défense pour les problèmes inconnus/potentiels. Automatisation : Utiliser des machines pour effectuer des tâches répétitives qui ne nécessitent pas d'intervention humaine via des outils. Agilité : Accepter activement les changements d'exigences et répondre rapidement aux besoins de développement commercial.
4. L'architecture haute performance
est centrée sur l'utilisateur et offre une expérience d'accès Web rapide. Les principaux paramètres sont un temps de réponse court, une grande capacité de traitement simultané, un débit élevé et des paramètres de performances stables.
Peut être divisé en optimisation frontale, optimisation de la couche d'application, optimisation de la couche de code et optimisation de la couche de stockage.
Optimisation du front-end : la partie avant la logique métier du site Web ; Optimisation du navigateur : réduire le nombre de requêtes HTTP, utiliser le cache du navigateur, activer la compression, la position CSS JS, JS asynchrone, réduire la transmission des cookies ; accélération, proxy inverse ; Optimisation de la couche application : le serveur qui gère les activités du site Web. Utiliser le cache, l'asynchrone, le cluster Optimisation du code : architecture raisonnable, multi-threading, réutilisation des ressources (pool d'objets, pool de threads, etc.), bonne structure de données, réglage JVM, singleton, Cache, etc. ; -
Optimisation du stockage : cache, disque SSD, transmission fibre optique, lecture et écriture optimisées, redondance des disques, stockage distribué (HDFS), NoSQL, etc.
5. Architecture haute disponibilité
Les grands sites Web doivent être accessibles à tout moment et fournir des services externes normaux. En raison de la complexité, de la distribution, des serveurs bon marché, des bases de données open source, des systèmes d'exploitation et d'autres caractéristiques des grands sites Web, il est difficile de garantir une haute disponibilité, ce qui signifie que les pannes des sites Web sont inévitables.
Comment améliorer la convivialité est un problème qui doit être résolu de toute urgence. Tout d’abord, nous devons l’envisager du point de vue architectural et tenir compte de la disponibilité lors de la planification. Dans l'industrie, plusieurs neuf sont généralement utilisés pour représenter les indicateurs de disponibilité, comme quatre neuf (99,99), et la durée d'indisponibilité autorisée dans une année est de 53 minutes.
Différentes stratégies sont utilisées à différents niveaux. La sauvegarde redondante et le basculement sont généralement utilisés pour résoudre les problèmes de haute disponibilité.
Couche Application : Généralement conçue pour être apatride, elle n'a aucun impact sur le serveur utilisé pour traiter chaque requête. Généralement, la technologie d'équilibrage de charge (qui doit résoudre le problème de synchronisation de session) est utilisée pour atteindre une haute disponibilité. Couche de service : équilibrage de charge, gestion hiérarchique, panne rapide (paramètre de timeout), appels asynchrones, dégradation de service, conception idempotente, etc. Couche de données : sauvegarde redondante (sauvegarde à froid, à chaud [synchrone, asynchrone], sauvegarde à chaud), failover (confirmation, transfert, restauration). La célèbre base théorique de la haute disponibilité des données est la théorie CAP (persistance, disponibilité, cohérence des données [forte cohérence, cohérence utilisateur, cohérence éventuelle])
6 Architecture évolutive
L'évolutivité fait référence sans changer la. Conception d'architecture originale, les capacités de traitement du système peuvent être augmentées ou diminuées en ajoutant/réduisant du matériel (serveurs).
Couche d'application : divisez l'application verticalement ou horizontalement. Ensuite, équilibrez la charge par rapport à une seule fonction (DNS, HTTP [proxy inverse], IP, couche de liaison). Couche de service : similaire à la couche d'application ; Couche de données : sous-base de données, sous-table, NoSQL, etc. ; algorithme de hachage couramment utilisé ;
7. Architecture évolutive
peut facilement ajouter/supprimer des modules de fonction et offrir une bonne évolutivité au niveau du code/module.
Modularisation et composantisation : cohésion élevée, faible couplage, réutilisabilité et évolutivité améliorées. Interface stable : Définissez une interface stable. Tant que l'interface reste inchangée, la structure interne peut changer "à volonté". Modèle de conception : appliquez des idées et des principes orientés objet, utilisez des modèles de conception pour concevoir au niveau du code. Message Queue : Un système modulaire qui interagit via des files d'attente de messages pour découpler les dépendances entre les modules. Services distribués : les modules publics sont orientés services pour permettre une utilisation par d'autres systèmes, améliorant ainsi la réutilisabilité et l'évolutivité.
8. Architecture de sécurité
Avoir des solutions efficaces aux problèmes connus et établir des mécanismes de découverte et de défense pour les problèmes inconnus/potentiels. Pour les problèmes de sécurité, nous devons d'abord améliorer la sensibilisation à la sécurité et établir un mécanisme de sécurité efficace pour garantir cela au niveau politique et organisationnel. Par exemple, les mots de passe des serveurs ne peuvent pas être divulgués, les mots de passe sont mis à jour mensuellement et ne peuvent pas être répétés trois fois par semaine. analyses de sécurité, etc. Renforcer la construction du système de sécurité de manière institutionnalisée. Dans le même temps, il convient de prêter attention à tous les aspects liés à la sécurité. Les questions de sécurité ne peuvent être ignorées, notamment la sécurité des infrastructures, la sécurité des systèmes applicatifs, la confidentialité et la sécurité des données, etc.
Sécurité des infrastructures : achat de matériel, sécurité du système d'exploitation et de l'environnement réseau. En règle générale, utilisez les canaux formels pour acheter des produits de haute qualité, choisissez un système d'exploitation sûr, corrigez les vulnérabilités en temps opportun et installez un logiciel antivirus et des pare-feu. Protégez-vous contre les virus et les portes dérobées. Définissez des politiques de pare-feu, établissez des systèmes de défense DDOS, utilisez des systèmes de détection d'attaques et effectuez une isolation de sous-réseau. Sécurité du système d'application : pendant le développement du programme, utilisez les méthodes correctes pour résoudre les problèmes courants connus au niveau du code. Empêchez les attaques de script intersite (XSS), les attaques par injection, la falsification de requêtes intersite (CSRF), les messages d'erreur, les commentaires HTML, les téléchargements de fichiers, la traversée de chemin, etc. Vous pouvez également utiliser un pare-feu d'application Web (tel que ModSecurity) pour effectuer une analyse des vulnérabilités de sécurité et d'autres mesures visant à renforcer la sécurité au niveau des applications. Confidentialité et sécurité des données : sécurité du stockage (stockage dans un équipement fiable, sauvegarde en temps réel et programmée), sécurité de la conservation (conservation cryptée des informations importantes, sélection du personnel approprié pour la conservation et la détection complexes, etc.), sécurité de la transmission (prévention du vol et de la falsification des données)
Algorithmes de cryptage et de décryptage couramment utilisés (cryptage à hachage unique [MD5, SHA], cryptage symétrique [DES, 3DES, RC]), cryptage asymétrique [RSA], etc.
9. Agilité
La conception architecturale et la gestion de l'exploitation et de la maintenance du site Web doivent s'adapter aux changements et offrir une grande évolutivité et évolutivité. Faites face facilement au développement rapide des affaires, à l’augmentation soudaine de l’accès à fort trafic et à d’autres exigences.
En plus des éléments architecturaux introduits ci-dessus, il est également nécessaire d'introduire les idées de gestion agile et de développement agile. Unifiez les activités, les produits, la technologie, l’exploitation et la maintenance, adaptez-vous aux besoins et réagissez rapidement.
10. Exemples d'architecture à grande échelle
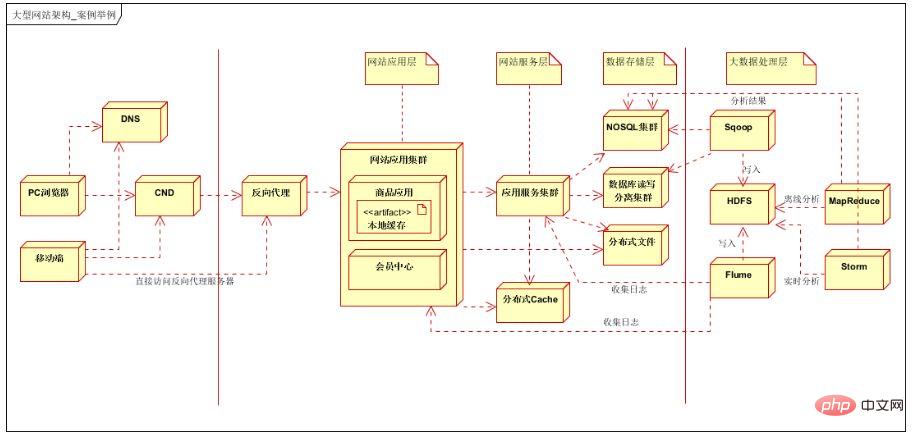
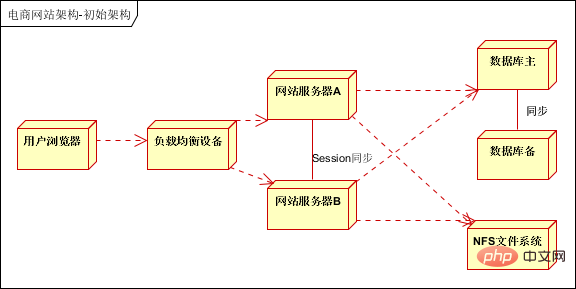
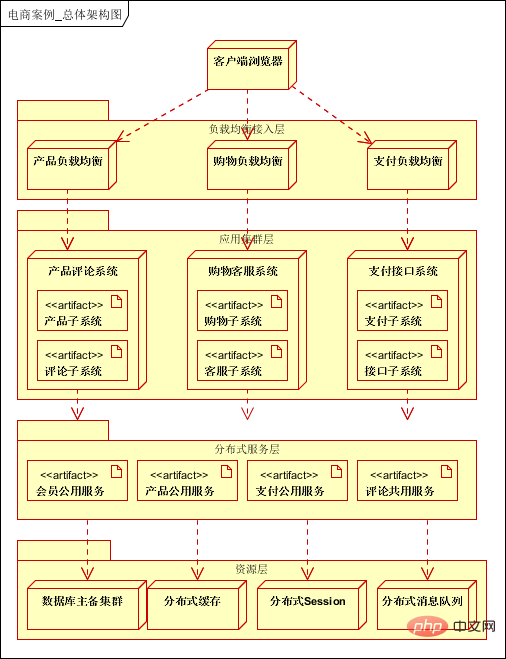
Ce qui précède utilise une architecture logique à sept couches, la première couche est la couche client, la deuxième couche est la couche d'optimisation frontale, la troisième La couche est la couche d'application, la quatrième couche est la couche de service et la cinquième couche est la couche de stockage de données, la sixième couche est la couche de stockage de Big Data et la septième couche est la couche de traitement du Big Data.
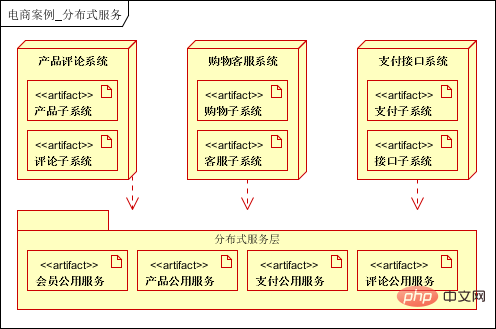
Couche client : prend en charge le navigateur PC et l'application mobile. La différence est que l'application mobile est accessible directement via IP et un serveur proxy inverse. Couche frontale : utilisation de l'équilibrage de charge DNS, de l'accélération locale CDN et des services de proxy inverse ; Couche d'application : cluster d'applications de sites Web divisé verticalement en fonction des activités, telles que les applications de produits, les centres de membres, etc. ; -
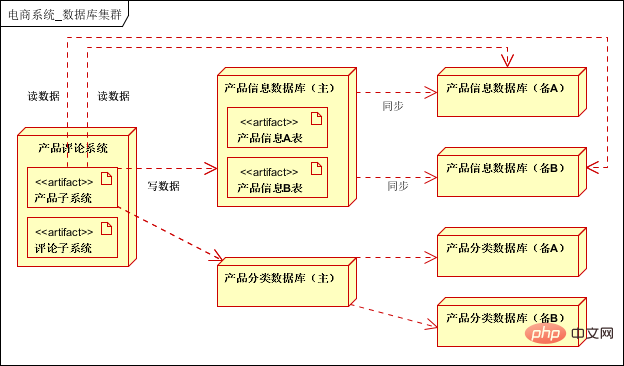
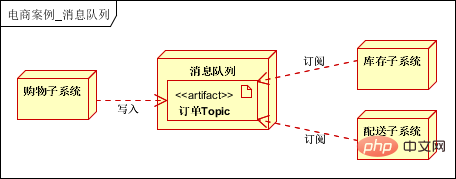
Couche de service : fournit des services publics, tels que les services aux utilisateurs, les services de commande, les services de paiement, etc. ; Couche de données : prend en charge les clusters de bases de données relationnelles (prend en charge la séparation en lecture-écriture), les clusters NOSQL, le système de fichiers distribué clusters ; et cache distribué ; Couche de stockage de données volumineuses : prend en charge la collecte de données de journaux dans la couche application et la couche de service, la collecte de données structurées et semi-structurées dans les bases de données relationnelles et les bases de données NOSQL ; hors ligne via l'analyse des données Mapreduce ou l'analyse des données en temps réel Storm, et les données traitées sont stockées dans une base de données relationnelle. (En utilisation réelle, les données hors ligne et les données en temps réel seront classées et traitées selon les exigences de l'entreprise et stockées dans différentes bases de données pour être utilisées par la couche application ou la couche service).
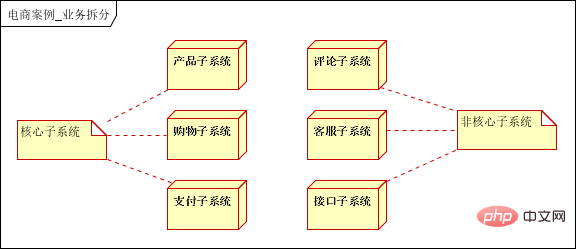
L'architecture système d'un site Web mature à grande échelle (comme Taobao, Tmall, Tencent, etc.) n'est pas conçue avec des performances élevées dès le début, une haute disponibilité, une évolutivité élevée et d'autres caractéristiques. Il a progressivement évolué et amélioré avec l'augmentation du nombre d'utilisateurs et l'expansion des fonctions commerciales. Dans ce processus, le modèle de développement, l'architecture technique et. les idées de conception ont également subi de grands changements. Même le personnel technique est passé de quelques personnes à un département ou même une ligne de produits. Ainsi, l'architecture système mature s'améliore progressivement avec l'expansion de l'entreprise, et cela ne se fait pas du jour au lendemain ; les systèmes avec des caractéristiques commerciales différentes auront leur propre objectif, comme Taobao, qui doit résoudre la recherche, la commande et le traitement des des informations massives sur les produits. Tencent, par exemple, doit gérer la transmission de messages en temps réel pour des centaines de millions d'utilisateurs ; Baidu doit gérer des demandes de recherche massives.
Ils ont tous leurs propres caractéristiques commerciales et l'architecture du système est également différente. Malgré cela, nous pouvons également trouver des technologies communes à ces différents contextes de sites Web. Ces technologies et méthodes sont largement utilisées dans l'architecture des systèmes de sites Web à grande échelle. Comprenons ces technologies et méthodes en introduisant le processus d'évolution des systèmes de sites Web à grande échelle. moyens.
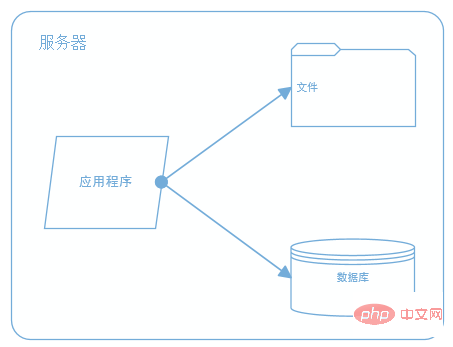
L'architecture initiale du site Web
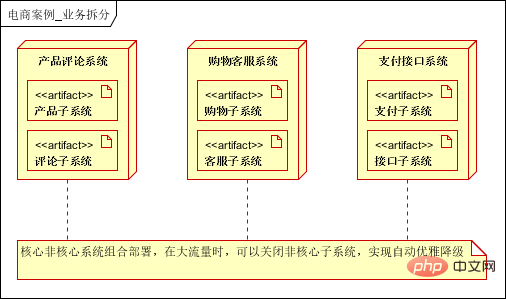
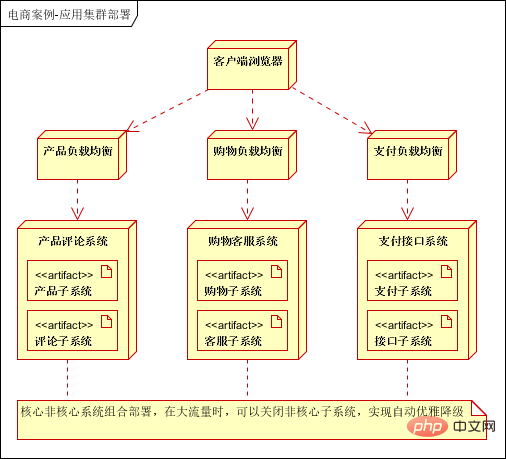
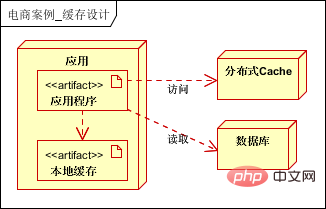
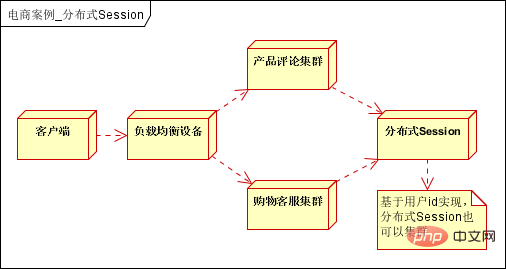
L'architecture initiale, les applications, les bases de données et les fichiers sont tous déployés sur un serveur, comme le montre l'image :
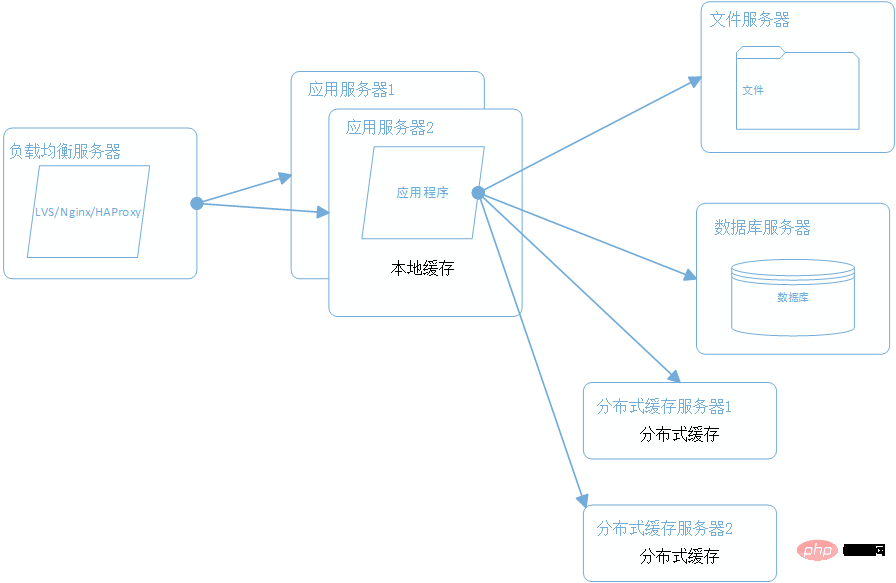
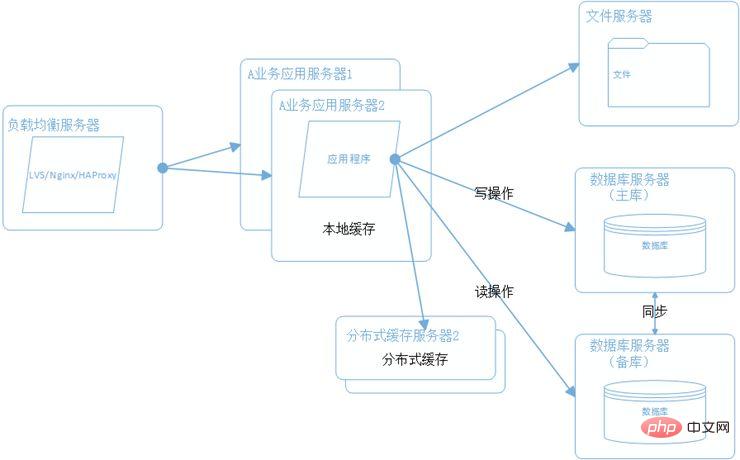
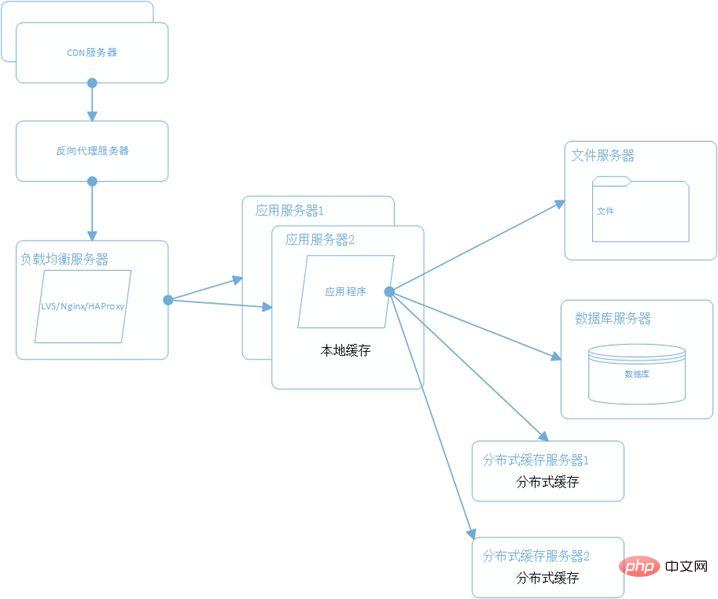
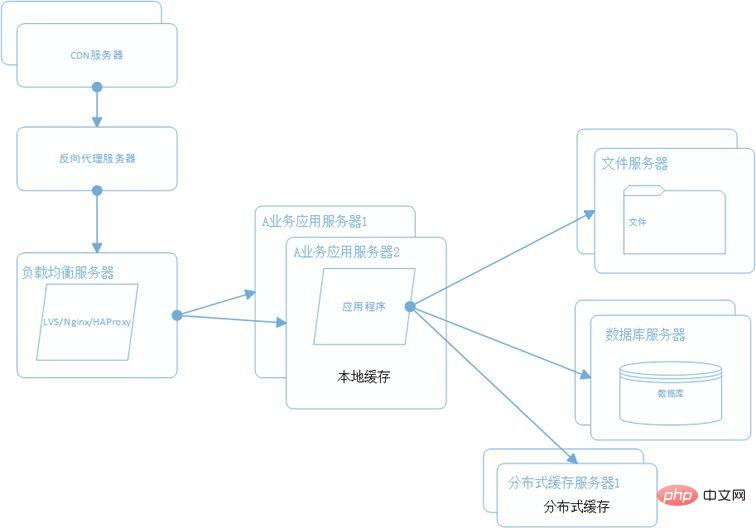
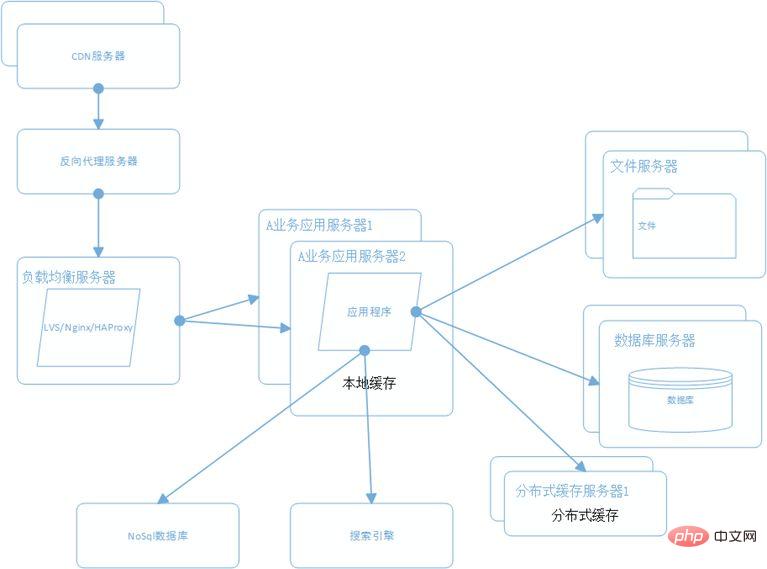
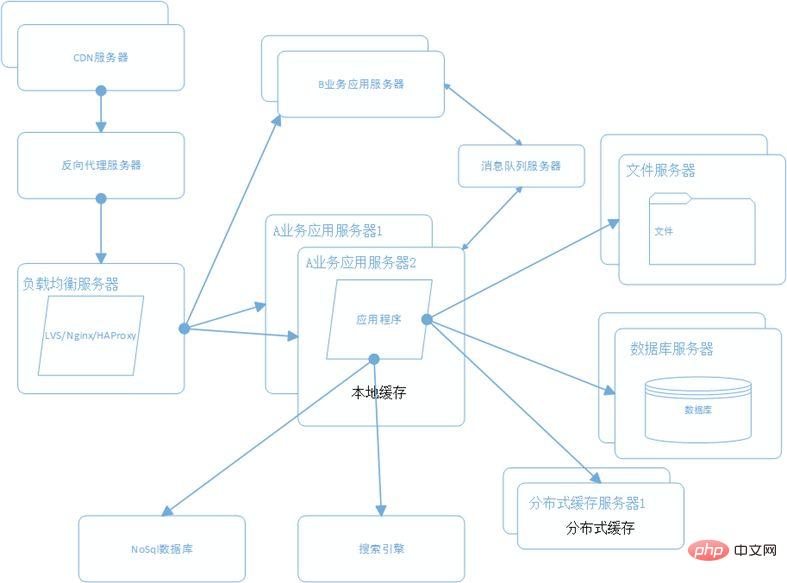
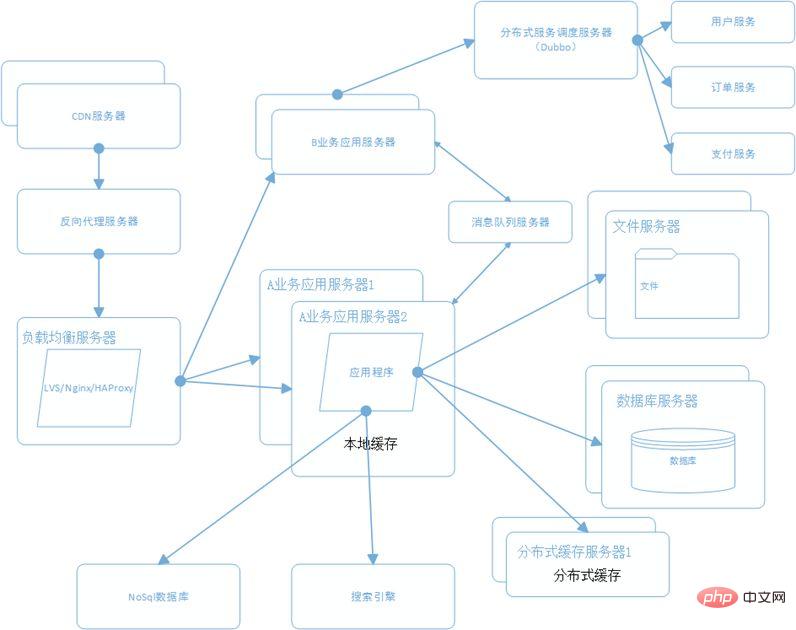
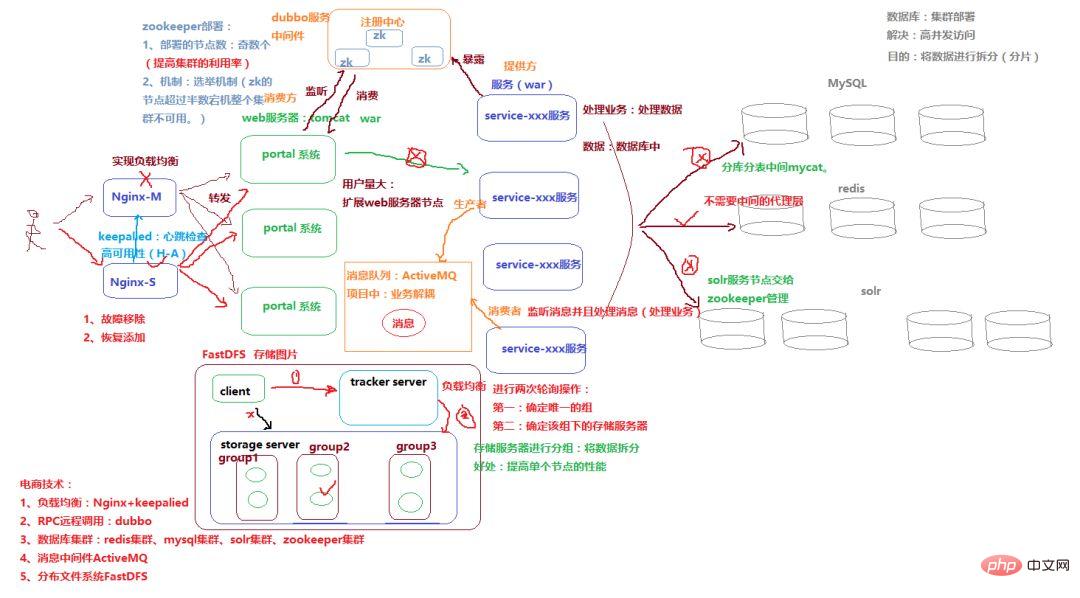
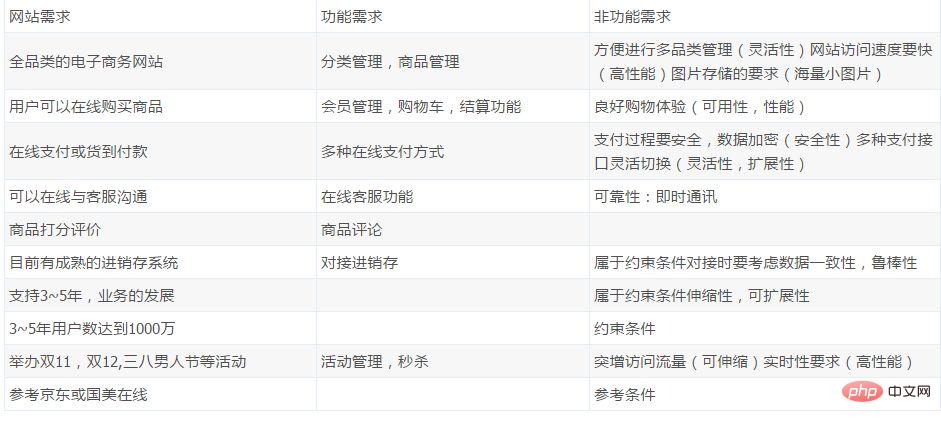
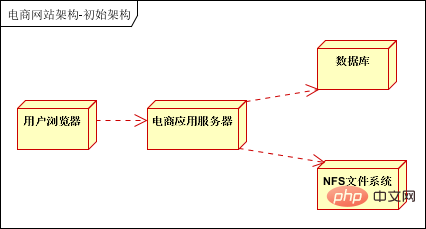
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Solution rapide en 10 minutes | Architecture du système de commerce électronique distribué à grande échelle
Aug 23, 2023 pm 03:03 PM
Solution rapide en 10 minutes | Architecture du système de commerce électronique distribué à grande échelle
Aug 23, 2023 pm 03:03 PM
Cet article est un résumé technique de l’apprentissage de l’architecture de sites Web distribués à grande échelle. Il fournit une brève description de l'architecture d'un site Web distribué haute performance, haute disponibilité, évolutif et extensible, et donne une référence architecturale. Une partie de l'article consiste à lire des notes et une partie est un résumé de l'expérience personnelle, qui a une bonne valeur de référence pour l'architecture de sites Web distribués à grande échelle.
 Partage d'expérience en développement C# : architecture et conception de systèmes à grande échelle
Nov 22, 2023 am 09:16 AM
Partage d'expérience en développement C# : architecture et conception de systèmes à grande échelle
Nov 22, 2023 am 09:16 AM
Partage d'expériences en développement C# : architecture et conception de systèmes à grande échelle En tant qu'ingénieur de développement C#, j'ai eu la chance de participer au développement et à la conception d'architecture de plusieurs systèmes à grande échelle et d'accumuler une expérience et des leçons précieuses. Dans cet article, je partagerai certaines de mes expériences en matière d'architecture et de conception de systèmes à grande échelle, dans l'espoir d'être utile à des amis qui sont actuellement engagés ou intéressés à s'engager dans le développement C#. Premièrement, la conception architecturale des systèmes à grande échelle doit pleinement prendre en compte l’évolutivité du système. Dès le début de la conception du système, il est nécessaire de considérer l’expansion future à laquelle le système pourrait être confronté.
 Évolution de l'architecture du système de commerce électronique Autohome et pratique de l'architecture de la plate-forme
Apr 12, 2023 pm 04:01 PM
Évolution de l'architecture du système de commerce électronique Autohome et pratique de l'architecture de la plate-forme
Apr 12, 2023 pm 04:01 PM
★ Contenu ★01 Avant-propos 02 Évolution de l'architecture 2.1 Étape de démarrage 2.2 Étape du microservice 2.3 Étape des données de base 2.4 Étape de l'architecture de la plate-forme 03 Pratique de l'architecture de la plate-forme 3.1 Identité d'entreprise 3.2 Orchestration des services 3.3 Configuration commerciale 3.4 Outils de développement 3.5 Visualisation des données 3.6 Précipitation des connaissances 04 Épilogue 4.1 Explorer de nouveaux commerces de détail 4.2 Préface de mise à niveau de l'architecture Le système de commerce électronique Autohome est né en 2014 et s'est développé de 2016 à 2019. Il a connu le test de pointe des parties Double 11 et 818 pendant de nombreuses années et a accumulé une capacité de transaction en ligne stable, fiable et excellente. Avec la montée de la vague de construction de plates-formes intermédiaires, 2019 est entrée dans la phase de construction de plates-formes intermédiaires, exportant ses cinq années d'expérience dans le domaine du commerce électronique automobile.
 Comment implémenter une architecture système à haute disponibilité et d'équilibrage de charge en Java
Oct 10, 2023 pm 01:25 PM
Comment implémenter une architecture système à haute disponibilité et d'équilibrage de charge en Java
Oct 10, 2023 pm 01:25 PM
Comment implémenter une architecture système à haute disponibilité et d'équilibrage de charge en Java Avec le développement rapide d'Internet, la haute disponibilité et l'équilibrage de charge sont devenus des considérations importantes dans la construction d'un système stable et fiable. En Java, il existe de nombreuses façons d’obtenir une haute disponibilité et une architecture système à charge équilibrée. Cet article présentera les méthodes d’implémentation courantes et fournira des exemples de code correspondants. 1. Implémentation de la haute disponibilité Tolérance aux pannes de service Lors de la construction d'un système à haute disponibilité, la tolérance aux pannes de service est une méthode de mise en œuvre courante. Ceci peut être réalisé en utilisant le mode disjoncteur. Le mode disjoncteur peut être utilisé en service
 Quelles sont les architectures système ?
Nov 14, 2023 am 11:09 AM
Quelles sont les architectures système ?
Nov 14, 2023 am 11:09 AM
Les types d'architecture système comprennent : 1. Architecture de base de données unique et architecture d'application unique ; 2. Architecture de distribution de contenu ; 3. Architecture de séparation en lecture-écriture ; 5. Architecture de cache multi-niveaux ; -architecture de table, etc.
 Comment implémenter une architecture système basée sur une file d'attente de messages en Java
Oct 09, 2023 am 08:45 AM
Comment implémenter une architecture système basée sur une file d'attente de messages en Java
Oct 09, 2023 am 08:45 AM
Comment implémenter une architecture système basée sur une file d'attente de messages en Java Avec le développement rapide d'Internet, de nombreuses entreprises sont confrontées à un grand nombre d'exigences en matière de traitement de données et de communication. Afin de répondre à ces besoins, de nombreuses entreprises ont commencé à utiliser des files d'attente de messages pour créer des architectures système hautement disponibles et hautement évolutives. Les files d'attente de messages peuvent aider à découpler les expéditeurs et les destinataires de messages, à fournir un mécanisme de livraison de messages asynchrone et à alléger la pression pendant les périodes de pointe. Cet article explique comment implémenter une architecture système basée sur une file d'attente de messages en Java et fournit des exemples de code spécifiques. Tout d'abord, je
 Construire une architecture système hautement évolutive : explication détaillée du modèle Golang Facade
Sep 27, 2023 pm 10:01 PM
Construire une architecture système hautement évolutive : explication détaillée du modèle Golang Facade
Sep 27, 2023 pm 10:01 PM
Construire une architecture système hautement évolutive : explication détaillée du modèle GolangFacade Introduction : Dans le processus de développement logiciel, la conception de l'architecture système est un maillon crucial. L'architecture du système peut déterminer la stabilité, l'évolutivité et la maintenabilité de l'ensemble du système logiciel. Cet article présentera en détail un modèle de conception couramment utilisé - le modèle de façade, et donnera des exemples de code spécifiques combinés avec le langage de programmation Golang pour aider les lecteurs à comprendre et à appliquer ce modèle. 1. Qu'est-ce que le mode Façade 1.1 Présentation du mode Façade
 L'architecture du système ThePaper OS de Xiaomi est exposée pour la première fois, reconstruisant la technologie sous-jacente
Oct 23, 2023 pm 07:57 PM
L'architecture du système ThePaper OS de Xiaomi est exposée pour la première fois, reconstruisant la technologie sous-jacente
Oct 23, 2023 pm 07:57 PM
Le 23 octobre, Xiaomi a annoncé qu'elle était sur le point de lancer un nouveau système d'exploitation très attendu par les passionnés de numérique et les utilisateurs de Xiaomi, appelé Xiaomi Pascal OS. Cette nouvelle passionnante sera publiée avec la série Xiaomi 14 le 26 octobre. Xiaomi a officiellement dévoilé l'architecture système du système d'exploitation Xiaomi ThePaper pour la première fois aujourd'hui. Cette version marque une mise à niveau sous-jacente complète. Il est entendu que Xiaomi ThePaper OS intégrera les technologies Linux et Xiaomi Vela pour reconstruire les modules de base du noyau. Le nouveau système introduit également huit nouveaux sous-systèmes, visant à créer une plate-forme intermédiaire système active, intelligente, performante et sécurisée. Xiaomi ThePaper OS introduit également un nouveau cadre d'interconnexion entre terminaux, permettant aux appareils de se mettre en réseau de manière dynamique et de réaliser un travail collaboratif transparent. La structure du système comprend la couche application,