
 Périphériques technologiques
IA
Créer une application LLM : tirer parti des capacités de recherche vectorielle d'Azure Cognitive Services
Périphériques technologiques
IA
Créer une application LLM : tirer parti des capacités de recherche vectorielle d'Azure Cognitive Services
Créer une application LLM : tirer parti des capacités de recherche vectorielle d'Azure Cognitive Services

Auteur | Simon Bisson
Organisé | Ethan
L'API de recherche cognitive de Microsoft propose désormais la recherche vectorielle en tant que service à utiliser avec de grands modèles de langage dans Azure OpenAI et plus encore.
Des outils comme Semantic Core, TypeChat et LangChain permettent de créer des applications autour de technologies d'IA générative comme Azure OpenAI. En effet, ils permettent d'imposer des contraintes sur le grand modèle de langage (LLM) sous-jacent, qui peut être utilisé comme outil pour créer et exécuter des interfaces en langage naturel.
Essentiellement, un LLM est un outil pour naviguer dans des espaces sémantiques où les neurones profonds Le réseau peut prédire la syllabe suivante dans une chaîne de jetons à partir du signal initial. Si l'invite est ouverte, le LLM peut dépasser sa portée d'entrée et produire quelque chose qui semble raisonnable mais qui est en réalité complètement absurde.
Tout comme nous avons tous tendance à faire confiance aux résultats des moteurs de recherche, nous avons également tendance à faire confiance aux résultats des LLM car nous les considérons comme un autre aspect d'une technologie familière. Mais la formation de grands modèles de langage à l'aide de données fiables provenant de sites tels que Wikipedia, Stack Overflow et Reddit ne permet pas de comprendre le contenu ; elle donne simplement la possibilité de générer du texte qui suit les mêmes modèles que le texte de ces sources. Parfois, le résultat peut être correct, mais d’autres fois, il peut être erroné.
Comment pouvons-nous éviter les erreurs et les résultats dénués de sens des grands modèles linguistiques et garantir que nos utilisateurs obtiennent des réponses précises et raisonnables à leurs requêtes ?
1. Limiter les grands modèles avec des contraintes de mémoire sémantique
Ce que nous devons faire est de limiter LLM pour garantir qu'il génère uniquement du texte à partir d'ensembles de données plus petits. C'est là qu'intervient la nouvelle pile de développement basée sur LLM de Microsoft. Il fournit les outils nécessaires pour contrôler votre modèle et l'empêcher de générer des erreurs.
Vous pouvez forcer un format de sortie spécifique en utilisant des outils comme TypeChat, ou utiliser des pipelines d'orchestration comme Semantic Kernel pour traiter d'autres sources d'informations fiables, ce qui « enracine » efficacement le modèle dans un espace sémantique connu, contraignant ainsi le LLM. Ici, LLM peut faire ce qu'il fait bien, résumer l'invite construite et générer du texte basé sur cette invite, sans dépasser (ou au moins réduire considérablement la probabilité de dépassement).
Ce que Microsoft appelle « mémoire sémantique » est à la base de cette dernière méthode. La mémoire sémantique utilise la recherche vectorielle pour fournir des indices qui peuvent être utilisés pour fournir le résultat factuel du LLM. La base de données vectorielles gère le contexte de l'invite initiale, la recherche vectorielle recherche les données stockées qui correspondent à la requête initiale de l'utilisateur et le LLM génère le texte sur la base de ces données. Découvrez cette approche en action dans Bing Chat, qui utilise les outils de recherche vectorielle natifs de Bing pour créer des réponses dérivées de sa base de données de recherche.
La mémoire sémantique permet aux bases de données vectorielles et aux recherches vectorielles de fournir des moyens d'application basés sur LLM. Vous pouvez choisir d'utiliser l'une des bases de données vectorielles open source, de plus en plus nombreuses, ou d'ajouter des index vectoriels à vos bases de données SQL et NoSQL familières. Un nouveau produit qui semble particulièrement utile étend la recherche cognitive Azure, en ajoutant un index vectoriel à vos données et en fournissant une nouvelle API pour interroger cet index
2. Ajouter un index vectoriel à la recherche cognitive Azure
La recherche cognitive Azure est basée sur la recherche propre de Microsoft outils. Il fournit une combinaison de requêtes Lucene familières et de ses propres outils de requête en langage naturel. Azure Cognitive Search est une plateforme Software-as-a-Service qui peut héberger des données privées et accéder au contenu à l'aide des API Cognitive Services. Récemment, Microsoft a également ajouté la prise en charge de la création et de l'utilisation d'index vectoriels, ce qui vous permet d'utiliser des recherches de similarité pour classer les résultats pertinents dans vos données et les utiliser dans des applications basées sur l'IA. Cela fait d'Azure Cognitive Search un outil idéal pour les applications LLM hébergées par Azure et construites avec Semantic Kernel et Azure OpenAI, et les plugins Semantic Kernel pour Cognitive Search pour C# et Python sont également disponibles
Comme pour les autres services Azure, Azure Cognitive Search est un outil géré. service qui fonctionne avec d’autres services Azure. Il vous permet d'indexer et de rechercher dans divers services de stockage Azure, hébergeant du texte, des images, de l'audio et de la vidéo. Les données sont stockées dans plusieurs régions, offrant une haute disponibilité et réduisant la latence et les temps de réponse. De plus, pour les applications d'entreprise, vous pouvez utiliser Microsoft Entra ID (le nouveau nom d'Azure Active Directory) pour contrôler l'accès aux données privées
3 Générer et stocker des vecteurs d'intégration pour le contenu
Il convient de noter qu'Azure Cognitive Search est. un service "apportez votre propre vecteur d'intégration". La recherche cognitive ne génère pas les intégrations vectorielles dont vous avez besoin. Vous devez donc utiliser Azure OpenAI ou l'API d'intégration OpenAI pour créer des intégrations pour votre contenu. Cela peut nécessiter le regroupement de fichiers volumineux pour garantir que vous restez dans les limites des jetons du service. Soyez prêt à créer de nouvelles tables pour indexer les données vectorielles si nécessaire
Dans la Recherche cognitive Azure, la recherche vectorielle utilise un modèle du voisin le plus proche pour renvoyer un nombre sélectionné par l'utilisateur de documents similaires à la requête d'origine. Ce processus appelle l'indexation vectorielle en utilisant l'intégration vectorielle de la requête d'origine et renvoie un contenu vectoriel et d'index similaire à partir de la base de données, prêt à être utilisé par l'invite LLM
Microsoft utilise ce magasin de vecteurs dans le cadre du modèle de conception Retrieval Augmented Generation (RAG) d'Azure Machine Learning et en conjonction avec son outil de flux d'invite. RAG exploite l'indexation vectorielle dans la recherche cognitive pour créer le contexte qui constitue la base des invites LLM. Cela vous donne un moyen low-code de créer et d'utiliser des index vectoriels, par exemple en définissant le nombre de documents similaires renvoyés par une requête Simple. Commencez par créer des ressources pour Azure OpenAI et Cognitive Search dans la même région. Cela vous permettra de charger l'index de recherche avec des intégrations avec une latence minimale. Vous devez appeler l’API Azure OpenAI et l’API Cognitive Search pour charger l’index. C’est donc une bonne idée de vous assurer que votre code peut répondre à toutes les limites de débit possibles dans le service en ajoutant du code qui gère les tentatives. Lorsque vous utilisez l'API de service, vous devez utiliser des appels asynchrones pour générer des intégrations et charger des index.
Les vecteurs sont stockés dans les index de recherche sous forme de champs vectoriels, où les vecteurs sont des nombres à virgule flottante avec des dimensions. Ces vecteurs sont cartographiés via un graphe de voisinage hiérarchique navigable de petit monde qui trie les vecteurs en voisinages de vecteurs similaires, accélérant ainsi le processus réel de recherche d'index vectoriels.
Après avoir défini le schéma d'index pour la recherche vectorielle, vous pouvez charger des données dans l'index pour la recherche cognitive. Notez que les données peuvent être associées à plusieurs vecteurs. Par exemple, si vous utilisez la recherche cognitive pour héberger les documents de l'entreprise, vous pouvez disposer d'un vecteur distinct pour les termes de métadonnées clés et le contenu du document. L'ensemble de données doit être stocké sous forme de document JSON, ce qui simplifie le processus d'utilisation des résultats pour assembler le contexte d'invite. L'index n'a pas besoin de contenir le document source car il prend en charge l'utilisation des options de stockage Azure les plus courantes
Avant d'exécuter la requête, vous devez d'abord appeler le modèle d'intégration de votre choix avec le corps de la requête. Cela renvoie un vecteur multidimensionnel que vous pouvez utiliser pour rechercher l'index de votre choix. Lorsque vous appelez l'API de recherche vectorielle, spécifiez l'index vectoriel cible, le nombre de correspondances souhaité et les champs de texte pertinents dans l'index. Choisir la mesure de similarité appropriée peut être très utile pour les requêtes, dont la plus couramment utilisée est la métrique du cosinus
5 Au-delà des simples vecteurs de texte
Les capacités vectorielles d'Azure Cognitive Search vont au-delà de la simple correspondance de texte. La recherche cognitive peut être utilisée avec des intégrations multilingues pour prendre en charge les recherches de documents dans plusieurs langues. Vous pouvez également utiliser des API plus complexes. Par exemple, vous pouvez combiner les outils de recherche sémantique Bing dans la recherche hybride pour fournir des résultats plus précis, améliorant ainsi la qualité des résultats des applications basées sur LLM.
Microsoft produit rapidement les outils et la technologie qu'il a utilisés pour créer son propre moteur de recherche Bing basé sur GPT-4, ainsi que divers Copilots. Les moteurs d’orchestration tels que Semantic Kernel et le flux d’invites d’Azure AI Studio sont au cœur de l’approche de Microsoft en matière de travail avec de grands modèles de langage. Maintenant que ces bases ont été posées, nous voyons l’entreprise déployer davantage de technologies habilitantes nécessaires. La recherche de vecteurs et l'indexation de vecteurs sont essentielles pour fournir des réponses précises. En créant des outils familiers pour fournir ces services, Microsoft nous aidera à minimiser les coûts et les courbes d'apprentissage
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



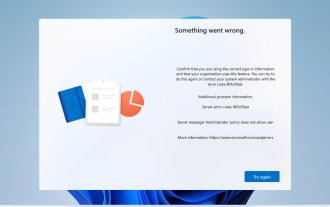 Code d'erreur 801c03ed : Comment le réparer sous Windows 11
Oct 04, 2023 pm 06:05 PM
Code d'erreur 801c03ed : Comment le réparer sous Windows 11
Oct 04, 2023 pm 06:05 PM
L'erreur 801c03ed est généralement accompagnée du message suivant : La stratégie de l'administrateur n'autorise pas cet utilisateur à rejoindre l'appareil. Ce message d'erreur vous empêchera d'installer Windows et de rejoindre un réseau, vous empêchant ainsi d'utiliser votre ordinateur. Il est donc important de résoudre ce problème dès que possible. Qu'est-ce que le code d'erreur 801c03ed ? Il s'agit d'une erreur d'installation de Windows qui se produit pour la raison suivante : la configuration d'Azure n'autorise pas les nouveaux utilisateurs à se joindre. Les objets d’appareil ne sont pas activés sur Azure. Échec du hachage matériel dans le panneau Azure. Comment corriger le code d'erreur 03c11ed sous Windows 801 ? 1. Vérifiez les paramètres Intune. Connectez-vous au portail Azure. Accédez à Appareils et sélectionnez Paramètres de l'appareil. Changez "Les utilisateurs peuvent
 Guide étape par étape pour utiliser Groq Llama 3 70B localement
Jun 10, 2024 am 09:16 AM
Guide étape par étape pour utiliser Groq Llama 3 70B localement
Jun 10, 2024 am 09:16 AM
Traducteur | Bugatti Review | Chonglou Cet article décrit comment utiliser le moteur d'inférence GroqLPU pour générer des réponses ultra-rapides dans JanAI et VSCode. Tout le monde travaille à la création de meilleurs grands modèles de langage (LLM), tels que Groq, qui se concentre sur le côté infrastructure de l'IA. Une réponse rapide de ces grands modèles est essentielle pour garantir que ces grands modèles réagissent plus rapidement. Ce didacticiel présentera le moteur d'analyse GroqLPU et comment y accéder localement sur votre ordinateur portable à l'aide de l'API et de JanAI. Cet article l'intégrera également dans VSCode pour nous aider à générer du code, à refactoriser le code, à saisir la documentation et à générer des unités de test. Cet article créera gratuitement notre propre assistant de programmation d’intelligence artificielle. Introduction au moteur d'inférence GroqLPU Groq
 Les Chinois de Caltech utilisent l'IA pour renverser les preuves mathématiques ! Accélérer 5 fois a choqué Tao Zhexuan, 80% des étapes mathématiques sont entièrement automatisées
Apr 23, 2024 pm 03:01 PM
Les Chinois de Caltech utilisent l'IA pour renverser les preuves mathématiques ! Accélérer 5 fois a choqué Tao Zhexuan, 80% des étapes mathématiques sont entièrement automatisées
Apr 23, 2024 pm 03:01 PM
LeanCopilot, cet outil mathématique formel vanté par de nombreux mathématiciens comme Terence Tao, a encore évolué ? Tout à l'heure, Anima Anandkumar, professeur à Caltech, a annoncé que l'équipe avait publié une version étendue de l'article LeanCopilot et mis à jour la base de code. Adresse de l'article image : https://arxiv.org/pdf/2404.12534.pdf Les dernières expériences montrent que cet outil Copilot peut automatiser plus de 80 % des étapes de preuve mathématique ! Ce record est 2,3 fois meilleur que le précédent record d’Esope. Et, comme auparavant, il est open source sous licence MIT. Sur la photo, il s'agit de Song Peiyang, un garçon chinois.
 De « humain + RPA » à « humain + IA générative + RPA », comment le LLM affecte-t-il l'interaction homme-machine RPA ?
Jun 05, 2023 pm 12:30 PM
De « humain + RPA » à « humain + IA générative + RPA », comment le LLM affecte-t-il l'interaction homme-machine RPA ?
Jun 05, 2023 pm 12:30 PM
Source de l'image@visualchinesewen|Wang Jiwei De « humain + RPA » à « humain + IA générative + RPA », comment le LLM affecte-t-il l'interaction homme-machine RPA ? D'un autre point de vue, comment le LLM affecte-t-il la RPA du point de vue de l'interaction homme-machine ? La RPA, qui affecte l'interaction homme-machine dans le développement de programmes et l'automatisation des processus, sera désormais également modifiée par le LLM ? Comment le LLM affecte-t-il l’interaction homme-machine ? Comment l’IA générative modifie-t-elle l’interaction homme-machine de la RPA ? Apprenez-en davantage dans un article : L'ère des grands modèles arrive, et l'IA générative basée sur LLM transforme rapidement l'interaction homme-machine RPA ; l'IA générative redéfinit l'interaction homme-machine, et LLM affecte les changements dans l'architecture logicielle RPA. Si vous demandez quelle est la contribution de la RPA au développement et à l’automatisation des programmes, l’une des réponses est qu’elle a modifié l’interaction homme-machine (HCI, h).
 Plaud lance l'enregistreur portable NotePin AI pour 169 $
Aug 29, 2024 pm 02:37 PM
Plaud lance l'enregistreur portable NotePin AI pour 169 $
Aug 29, 2024 pm 02:37 PM
Plaud, la société derrière le Plaud Note AI Voice Recorder (disponible sur Amazon pour 159 $), a annoncé un nouveau produit. Surnommé NotePin, l’appareil est décrit comme une capsule mémoire AI, et comme le Humane AI Pin, il est portable. Le NotePin est
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Visualisez l'espace vectoriel FAISS et ajustez les paramètres RAG pour améliorer la précision des résultats
Mar 01, 2024 pm 09:16 PM
Visualisez l'espace vectoriel FAISS et ajustez les paramètres RAG pour améliorer la précision des résultats
Mar 01, 2024 pm 09:16 PM
À mesure que les performances des modèles de langage open source à grande échelle continuent de s'améliorer, les performances d'écriture et d'analyse du code, des recommandations, du résumé de texte et des paires questions-réponses (QA) se sont toutes améliorées. Mais lorsqu'il s'agit d'assurance qualité, le LLM ne répond souvent pas aux problèmes liés aux données non traitées, et de nombreux documents internes sont conservés au sein de l'entreprise pour garantir la conformité, les secrets commerciaux ou la confidentialité. Lorsque ces documents sont interrogés, LLM peut halluciner et produire un contenu non pertinent, fabriqué ou incohérent. Une technique possible pour relever ce défi est la génération augmentée de récupération (RAG). Cela implique le processus d'amélioration des réponses en référençant des bases de connaissances faisant autorité au-delà de la source de données de formation pour améliorer la qualité et la précision de la génération. Le système RAG comprend un système de récupération permettant de récupérer des fragments de documents pertinents du corpus
 GraphRAG amélioré pour la récupération de graphes de connaissances (implémenté sur la base du code Neo4j)
Jun 12, 2024 am 10:32 AM
GraphRAG amélioré pour la récupération de graphes de connaissances (implémenté sur la base du code Neo4j)
Jun 12, 2024 am 10:32 AM
La génération améliorée de récupération de graphiques (GraphRAG) devient progressivement populaire et est devenue un complément puissant aux méthodes de recherche vectorielles traditionnelles. Cette méthode tire parti des caractéristiques structurelles des bases de données graphiques pour organiser les données sous forme de nœuds et de relations, améliorant ainsi la profondeur et la pertinence contextuelle des informations récupérées. Les graphiques présentent un avantage naturel dans la représentation et le stockage d’informations diverses et interdépendantes, et peuvent facilement capturer des relations et des propriétés complexes entre différents types de données. Les bases de données vectorielles sont incapables de gérer ce type d'informations structurées et se concentrent davantage sur le traitement de données non structurées représentées par des vecteurs de grande dimension. Dans les applications RAG, la combinaison de données graphiques structurées et de recherche de vecteurs de texte non structuré nous permet de profiter des avantages des deux en même temps, ce dont discutera cet article. structure
