

Kafka terminé du point de vue de l'entretien
Kafka est un excellent middleware de messages distribués. Kafka est utilisé dans de nombreux systèmes pour la communication de messages. Comprendre et utiliser les systèmes de messagerie distribués est presque devenu une compétence nécessaire pour un développeur backend. Aujourd'hui 码哥字节 Je vais commencer par les questions courantes d'entretien avec Kafka et vous parler de Kafka.
Parlez du middleware de messages distribués
Questions
Qu'est-ce qu'un middleware de messages distribués ? Quel est le rôle du middleware de messages ? Quels sont les scénarios d'utilisation du middleware de messages ? Sélection du middleware de messages ?

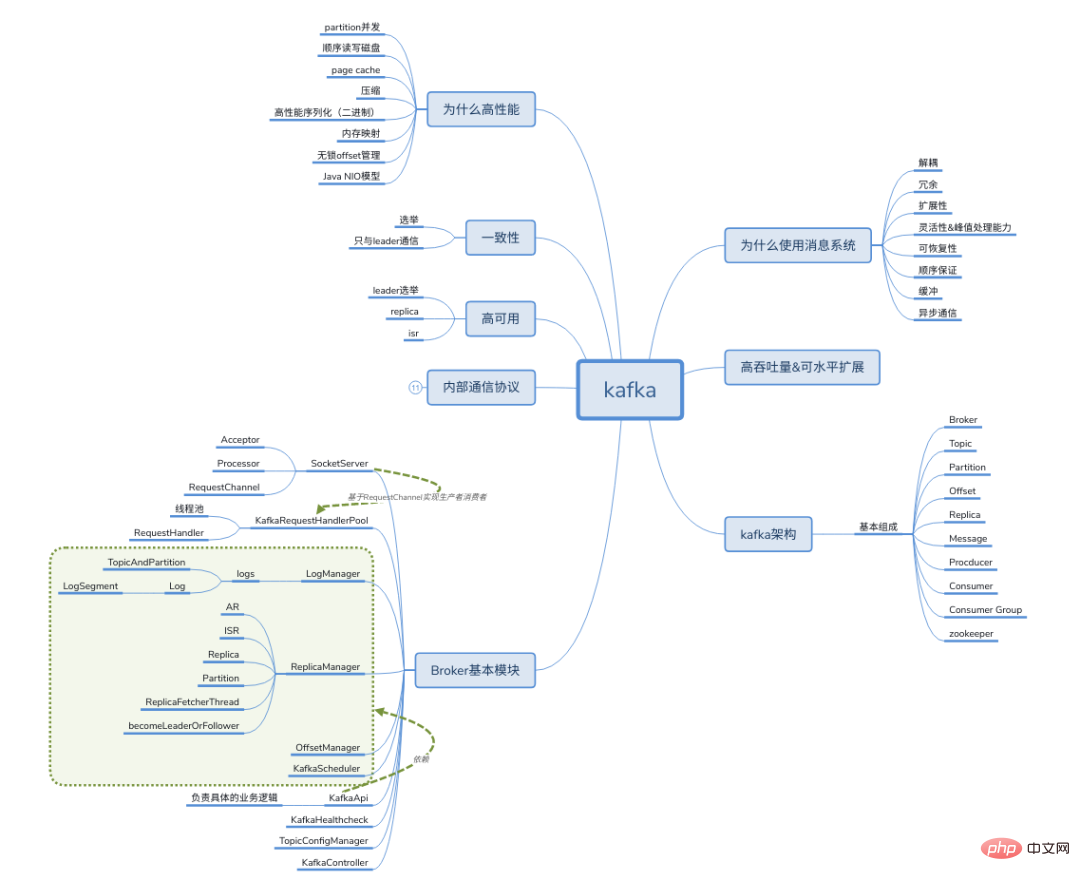
La messagerie distribuée est un mécanisme de communication contrairement à RPC, HTTP, RMI, etc., le middleware de messages utilise un agent intermédiaire distribué pour communiquer. Comme le montre la figure, après avoir utilisé le middleware de messages, le système métier en amont envoie des messages, qui sont d'abord stockés dans le middleware de messages, puis le middleware de messages distribue les messages aux applications du module métier correspondant (modèle producteur-consommateur distribué). Cette approche asynchrone réduit le couplage entre les services.
Définir le middleware de message :
Utiliser un mécanisme de transmission de messages efficace et fiable pour l'échange de données indépendant de la plate-forme Basé sur la communication de données pour intégrer des systèmes distribués En fournissant des modèles de transmission de messages et de mise en file d'attente de messages, il peut être utilisé dans un environnement distribué. communication inter-processus
Faire référence à des composants supplémentaires dans l'architecture du système augmentera inévitablement la complexité architecturale du système et la difficulté d'exploitation et de maintenance Alors Quels sont les avantages de l'utilisation d'un middleware de messagerie distribuée dans le système ? Quel est le rôle du middleware de messages dans le système ?
Découplage Redondance (stockage) Évolutivité Coupure de pointe Récupération -
Garantie de commande Buffering Communication asynchrone
Lors des entretiens, les enquêteurs se soucient souvent de la capacité de l'intervieweur à sélectionner des composants open source. Cela peut non seulement tester l'étendue des connaissances de l'intervieweur, mais également la profondeur de ses connaissances sur un certain type de système, et cela peut également être vu. que l'intervieweur a la capacité de comprendre la conception globale du système et de l'architecture du système. Il existe de nombreux systèmes de messagerie distribués open source, et différents systèmes de messagerie ont des caractéristiques différentes. Le choix d'un système de messagerie nécessite non seulement une certaine compréhension de chaque système de messagerie, mais également une compréhension claire de vos propres exigences système.
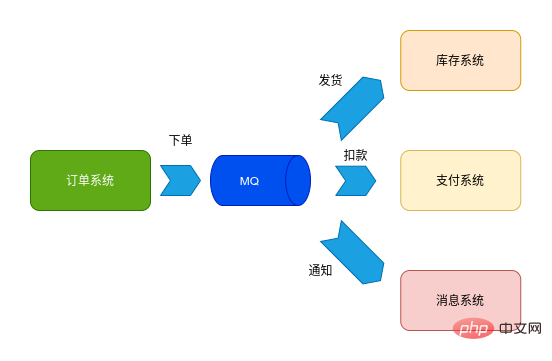
Ce qui suit est une comparaison de plusieurs systèmes de messagerie distribués courants :
Mot clé de réponse
Qu'est-ce qu'un middleware de messagerie distribuée ? Communication, file d'attente, distribuée, modèle producteur-consommateur. Quel est le rôle du middleware de messages ? Découplage, gestion des pics, communication asynchrone, mise en mémoire tampon. Quels sont les scénarios d'utilisation du middleware de messages ? Communication asynchrone, stockage et traitement des messages. Sélection du middleware de messages ? Langage, protocole, HA, fiabilité des données, performances, transaction, écologie, simplicité, mode push-pull.
Concepts de base et architecture de Kafka
Question
Parler brièvement de l'architecture de Kafka ? Kafka est-il un mode push ou un mode pull ? Quelle est la différence entre push et pull ? Comment Kafka diffuse-t-il des messages ? Les messages de Kafka sont-ils de mise ? Kafka prend-il en charge la séparation en lecture et en écriture ? Comment Kafka assure-t-il une haute disponibilité des données ? Quel est le rôle du gardien de zoo dans Kafka ? Est-ce qu'il prend en charge les transactions ? Le nombre de partitions peut-il être réduit ?
Concepts généraux dans l'architecture Kafka :
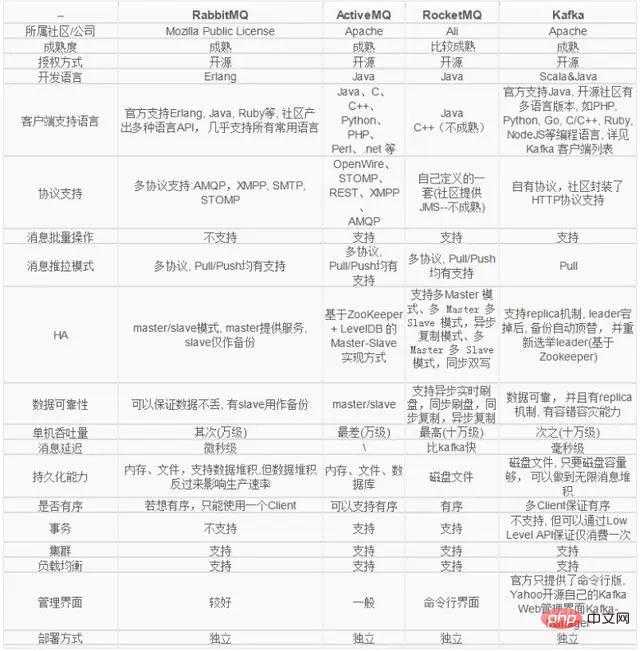
Producteur : Producteur, qui est le parti qui envoie des messages. Les producteurs sont chargés de créer des messages puis de les envoyer à Kafka. Consommateur : Consommateur, c'est-à-dire la partie qui reçoit le message. Les consommateurs se connectent à Kafka et reçoivent des messages, puis effectuent le traitement de logique métier correspondant. Groupe de consommateurs : Un groupe de consommateurs peut contenir un ou plusieurs consommateurs. L'utilisation de l'approche multipartition + multi-consommateur peut améliorer considérablement la vitesse de traitement des données en aval. Les consommateurs du même groupe de consommateurs ne consommeront pas les messages de manière répétée. De même, les messages envoyés par les consommateurs de différents groupes de consommateurs ne s'affecteront pas. Kafka implémente le mode message P2P et le mode diffusion via des groupes de consommateurs. Courtier : nœud proxy de service. Broker est le nœud de service de Kafka, c'est-à-dire le serveur de Kafka. Sujet : les messages dans Kafka sont divisés en unités de sujet. Le producteur envoie le message à un sujet spécifique, et le consommateur est responsable de s'abonner au message du sujet et de le consommer. Partition : Le sujet est un concept logique, qui peut être subdivisé en plusieurs partitions, et chaque partition n'appartient qu'à un seul sujet. Différentes partitions sous le même sujet contiennent des messages différents. La partition peut être considérée comme un fichier journal pouvant être ajouté au niveau du stockage. Lorsque des messages sont ajoutés au fichier journal de partition, un décalage spécifique leur est attribué. Offset : Offset est l'identifiant unique du message dans la partition. Kafka l'utilise pour garantir l'ordre du message dans la partition. Cependant, le décalage ne s'étend pas sur la partition. de la partition plutôt que l’ordre thématique du message. Réplication : la réplication est le moyen utilisé par Kafka pour garantir une haute disponibilité des données. Les données de la même partition Kafka peuvent avoir plusieurs copies sur plusieurs courtiers. Habituellement, seule la copie principale fournit des services de lecture et d'écriture externes lorsque le courtier est la copie principale. se bloque ou une panne de réseau se produit. De temps en temps, Kafka resélectionnera une nouvelle copie Leader pour fournir des services de lecture et d'écriture externes sous la gestion du contrôleur. Enregistrement : l'enregistrement du message qui est réellement écrit dans Kafka et peut être lu. Chaque enregistrement contient une clé, une valeur et un horodatage.
Disposition des partitions du sujet Kafka
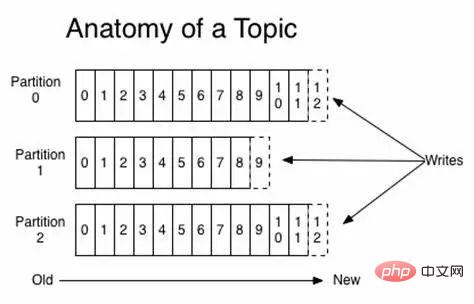
Sujet des partitions Kafka, et les partitions peuvent être lues et écrites simultanément.
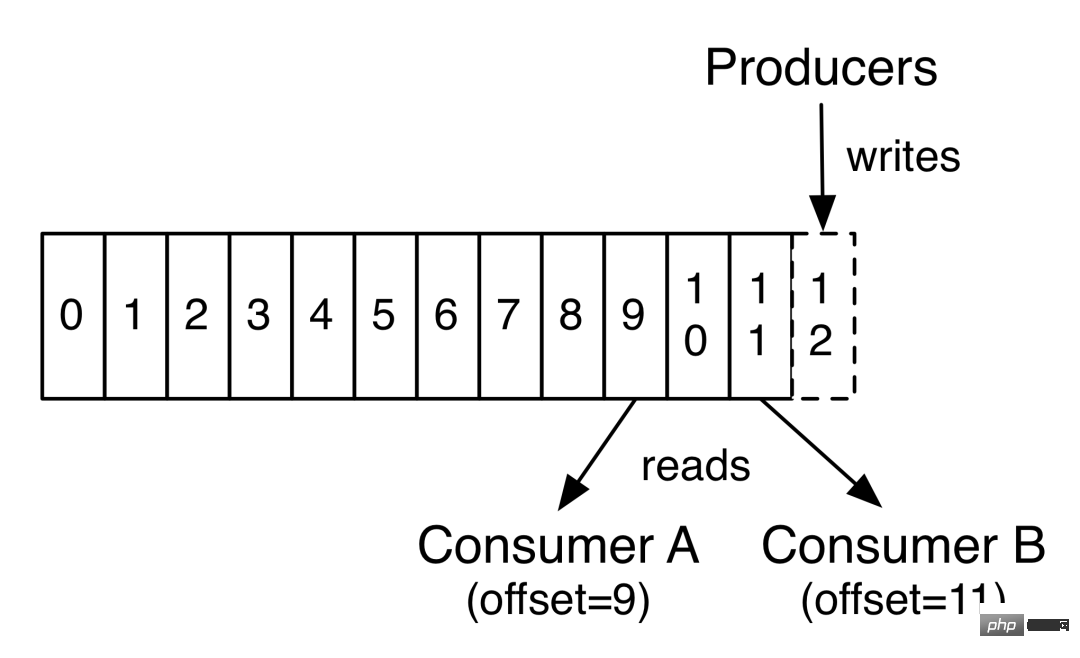
Compensation du consommateur Kafka
zookeeper
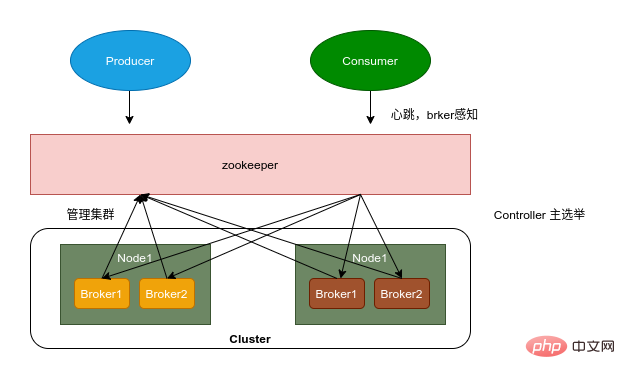
Inscription du courtier : Broker est un déploiement distribué et indépendant les uns des autres. Zookeeper est utilisé pour gérer tous les nœuds Broker enregistrés dans le cluster. Enregistrement du sujet : dans Kafka, les messages du même sujet seront divisés en plusieurs partitions et distribués sur plusieurs courtiers. Ces informations de partition et la relation correspondante avec le courtier sont également maintenues par Zookeeper Équilibrage de charge du producteur : Étant donné que le même message Topic sera partitionné et distribué sur plusieurs courtiers, le producteur doit envoyer les messages à ces courtiers distribués de manière raisonnable. Équilibrage de charge des consommateurs : à l'instar des producteurs, les consommateurs de Kafka ont également besoin d'un équilibrage de charge pour que plusieurs consommateurs puissent raisonnablement recevoir des messages du serveur Broker correspondant. Chaque groupe de consommateurs contient plusieurs consommateurs, chaque message ne sera envoyé qu'à un seul consommateur. dans le groupe, et différents groupes de consommateurs consomment des messages sous leurs propres sujets spécifiques sans interférer les uns avec les autres.
Mots clés de réponse
Parlez brièvement de l'architecture de Kafka ?
Producteur, Consommateur, Groupe de consommateurs, Sujet, Partition
Le mode push ou le mode pull de Kafka est-il différent ?
Kafka Producer utilise le mode Push pour envoyer des messages au courtier, et Consumer utilise le mode Pull pour la consommation. Le mode pull permet au consommateur de gérer lui-même le décalage, ce qui peut offrir des performances de lecture
Comment Kafka diffuse-t-il les messages ?
Groupe de consommateurs
Les messages de Kafka sont-ils de mise ?
Les niveaux de sujet ne sont pas ordonnés et les partitions sont ordonnées
Kafka prend-il en charge la séparation lecture-écriture ?
Non pris en charge, seul Leader fournit des services externes de lecture et d'écriture
Comment Kafka garantit-il une haute disponibilité des données ?
Copie, ack, HW
Le rôle du gardien de zoo dans Kafka ?
Gestion de cluster, gestion des métadonnées
Prend-il en charge les transactions ?
Après la version 0.11, les transactions sont prises en charge et peuvent être réalisées "exactement une fois"
Le nombre de partitions peut-il être réduit ?
Non, les données seront perdues
Kafka utilise
Questions
Quels sont les outils de ligne de commande pour Kafka ? Lesquels avez-vous utilisé ? Le processus d'exécution de Kafka Producer ? Quelles sont les configurations courantes de Kafka Producer ? Comment garder les messages Kafka en ordre ? Comment le producteur s'assure-t-il que les données sont envoyées sans perte ? Comment améliorer les performances de Producteur ? Si le nombre de consommateurs dans un même groupe est supérieur au nombre de pièces, comment Kafka le gère-t-il ? Kafka Consumer est-il thread-safe ? Parlez-moi du modèle de fil lorsque vous utilisez Kafka Consumer pour consommer des messages. Pourquoi est-il conçu comme ça ? Configurations courantes de Kafka Consumer ? Quand Consumer sera-t-il expulsé du cluster ? Comment Kafka réagira-t-il lorsqu'un consommateur rejoint ou quitte ? Qu'est-ce que le rééquilibrage et quand le rééquilibrage se produit-il ?
Outil de ligne de commande
L'outil de ligne de commande de Kafka se trouve dans le répertoire /bin du package Kafka, qui comprend principalement des scripts de gestion de services et de clusters, des scripts de configuration, des scripts de visualisation d'informations, des scripts de sujet, des scripts clients, etc. .
kafka-configs.sh : script de gestion de configuration kafka-console-consumer.sh : console consommateur kafka kafka-console-producer.sh : console producteur kafka kafka-consumer- groups.sh : informations relatives au groupe de consommateurs kafka kafka-delete-records.sh : supprimer les fichiers journaux de faible niveau d'eau -
kafka-log-dirs.sh : informations sur le répertoire du journal des messages kafka kafka- Mirror-maker.sh : outil de réplication de cluster Kafka dans différents centres de données kafka-preferred-replica-election.sh : déclencher l'élection de la réplique préférée kafka-producer-perf-test.sh : test de performances du producteur Kafka script kafka-reassign-partitions.sh : script de réaffectation de partition kafka-replica-verification.sh : script de vérification de la progression de la réplication kafka-server-start.sh : démarrer le service kafka kafka-server-stop.sh : arrêter le service kafka kafka-topics.sh : script de gestion des sujets -
kafka-verifiable-consumer.sh : consommateur kafka vérifiable kafka-verifiable- producteur.sh : producteur kafka vérifiable zookeeper-server-start.sh : démarrer le service zk zookeeper-server-stop.sh : arrêter le service zk -
zookeeper-shell.sh : client zk
Nous pouvons généralement utiliser kafka-console-consumer.sh和kafka-console-producer.sh脚本来测试 Kafka 生产和消费,kafka-consumer-groups.sh可以查看和管理集群中的 Topic,kafka-topics.shhabituellement utilisé pour afficher le statut du groupe de consommateurs de Kafka.
Kafka Producer
La logique de production normale du producteur Kafka comprend les étapes suivantes :
Configurer les paramètres du client producteur pour les instances de producteur courantes. Construisez le message à envoyer. Envoyer un message. Fermez l'instance du producteur.
Le processus d'envoi des messages par le producteur est illustré dans la figure ci-dessous, qui doit être envoyé au courtier par lots. 拦截器,序列化器和分区器,最终由累加器
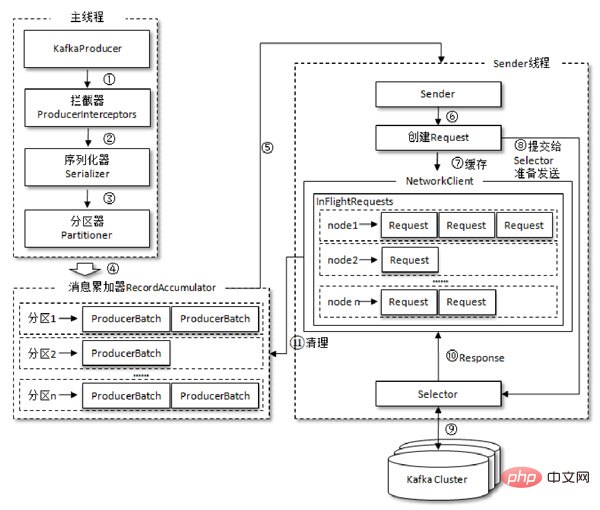 producer
producer- bootstrap.server : spécifiez l'adresse du courtier de Kafka
- key.serializer : sérialiseur de clé
- value .serializer : valeur sérialiseur
batch.num.messages Valeur par défaut : 200, le nombre de messages dans chaque lot, ne fonctionne que pour asyc.
request.required.acks Valeur par défaut : 0, 0 signifie que le producteur n'a pas besoin d'attendre la confirmation du leader, 1 signifie que le leader doit confirmer l'écriture dans son journal local et le confirmer immédiatement, -1 signifie que le producteur doit confirmer une fois toutes les sauvegardes terminées. Il ne fonctionne qu'en mode asynchrone. L'ajustement de ce paramètre est un compromis entre la perte de données et l'efficacité de la transmission. Si vous n'êtes pas sensible à la perte de données mais que vous vous souciez de l'efficacité, vous pouvez envisager de le définir sur 0, ce qui peut grandement améliorer l'efficacité de la transmission. le producteur dans l'envoi des données.
request.timeout.ms
Valeur par défaut : 10000, délai d'attente de confirmation.
partitioner.class
Valeur par défaut : kafka.producer.DefaultPartitioner, doit implémenter kafka.producer.Partitioner, fournir une stratégie de partitionnement basée sur la clé. Parfois, nous avons besoin que le même type de messages soit traité séquentiellement, nous devons donc personnaliser la stratégie d'allocation pour allouer le même type de données à la même partition.
producer.type
Valeur par défaut : sync, précise si le message est envoyé de manière synchrone ou asynchrone. Utilisez kafka.producer.AyncProducer pour l'envoi par lots asynchrone et kafka.producer.SyncProducer pour la synchronisation synchrone. L'envoi synchrone et asynchrone affecte également l'efficacité de la production de messages.
compression.topic
Valeur par défaut : aucune, compression du message, aucune compression par défaut. D'autres méthodes de compression incluent "gzip", "snappy" et "lz4". La compression des messages peut réduire considérablement le volume de transmission du réseau et les E/S du réseau, améliorant ainsi les performances globales.
compressé.topics
Valeur par défaut : null. Lorsque la compression est définie, vous pouvez spécifier une compression de sujet spécifique. Si elle n'est pas spécifiée, toute la compression sera effectuée.
message.send.max.retries
Valeur par défaut : 3, le nombre maximum de tentatives d'envoi de messages.
retry.backoff.ms
Valeur par défaut : 300, intervalle supplémentaire ajouté à chaque essai.
topic.metadata.refresh.interval.ms
Valeur par défaut : 600000, le temps d'obtenir régulièrement les métadonnées. Lorsque la partition est perdue et que le leader est indisponible, le producteur obtiendra également activement les métadonnées. S'il vaut 0, les métadonnées seront obtenues à chaque envoi du message, ce qui n'est pas recommandé. Si elles sont négatives, les métadonnées ne sont récupérées qu’en cas d’échec.
queue.buffering.max.ms
Valeur par défaut : 5000, la durée maximale de mise en cache des données dans la file d'attente du producteur, uniquement pour asyc.
queue.buffering.max.message
Valeur par défaut : 10000, le nombre maximum de messages mis en cache par le producteur, uniquement pour asyc.
queue.enqueue.timeout.ms
Valeur par défaut : -1, 0 est supprimé lorsque la file d'attente est pleine, la valeur négative est le bloc lorsque la file d'attente est pleine, la valeur positive est le temps correspondant du bloc lorsque la file d'attente est pleine, uniquement pour asyc.
Kafka Consumer
Kafka a le concept de groupes de consommateurs. Chaque consommateur ne peut consommer que les messages de la partition attribuée, et chaque partition ne peut être consommée que par un seul consommateur dans un groupe de consommateurs consommé. Ainsi, si le nombre de consommateurs dans le même groupe de consommateurs dépasse le nombre de partitions, certains consommateurs se verront attribuer des partitions qui ne pourront pas être consommées. La relation entre les groupes de consommateurs et les consommateurs est illustrée dans la figure ci-dessous :
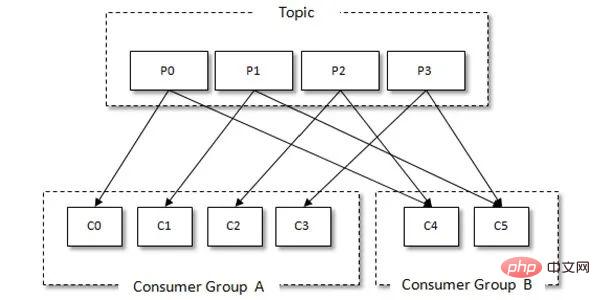
Kafka Consumer Client consommant des messages comprend généralement les étapes suivantes :
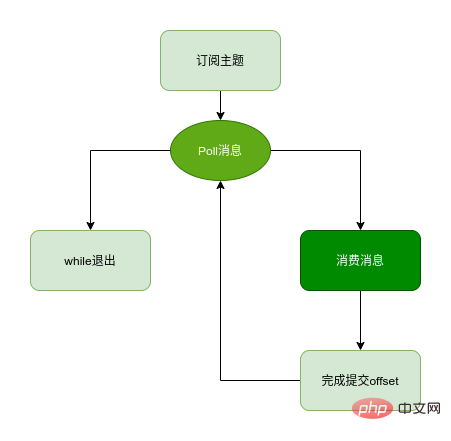
Configuration du client, création de consommateurs S'abonner à sujets -
Tirez le message et consommez Soumettez le déplacement de consommation Fermez l'instance du consommateur
Parce que le client Consumer de Kafka est thread-safe dans, afin d'assurer le fil sécurité et amélioration Pour les performances de consommation, un modèle de thread similaire à Reactor peut être utilisé du côté consommateur pour consommer des données.
"Modèle de consommation" ;rayon de bordure : 4 px ;marge droite : 2 px ;marge gauche : 2 px ;couleur d'arrière-plan : rgba(27, 31, 35, 0,05) ;famille de polices : « Operator Mono », Consolas, Monaco, Menlo, monospace ;word-break: break-all;color: rgb(0, 150, 136);">hôte:port format.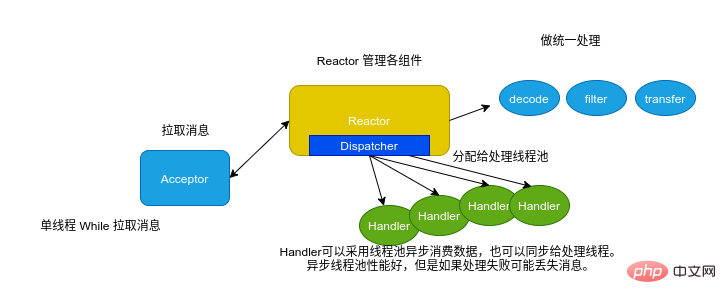
key.deserializer : key.serializer correspond à la méthode de désérialisation de key.
- value.deserializer :
host:port格式。group.id:消费者隶属的消费组。 key.deserializer:与生产者的 key.serializer对应,key 的反序列化方式。value.deserializer:与生产者的 value.serializer对应,value 的反序列化方式。session.timeout.ms:coordinator 检测失败的时间。默认 10s 该参数是 Consumer Group 主动检测 (组内成员 comsummer) 崩溃的时间间隔,类似于心跳过期时间。 auto.offset.reset:该属性指定了消费者在读取一个没有偏移量后者偏移量无效(消费者长时间失效当前的偏移量已经过时并且被删除了)的分区的情况下,应该作何处理,默认值是 latest,也就是从最新记录读取数据(消费者启动之后生成的记录),另一个值是 earliest,意思是在偏移量无效的情况下,消费者从起始位置开始读取数据。 enable.auto.commit:否自动提交位移,如果为 false,则需要在程序中手动提交位移。对于精确到一次的语义,最好手动提交位移fetch.max.bytes:单次拉取数据的最大字节数量 -
max.poll.records:单次 poll 调用返回的最大消息数,如果处理逻辑很轻量,可以适当提高该值。但是 session.timeout.ms : L'heure à laquelle la détection du coordinateur a échoué. La valeur par défaut est 10 s. Ce paramètre est l'intervalle de temps pendant lequel le groupe de consommateurs détecte activement (un membre du groupe) un crash, similaire au délai d'expiration du battement de cœur.max.poll.records 🎜auto.offset.reset : Cet attribut spécifie que le consommateur lit une partition qui n'a pas de décalage et que le décalage n'est pas valide (le décalage actuel du consommateur a expiré depuis longtemps et a expiré et supprimé) Dans dans ce cas, que faut-il faire ? La valeur par défaut est la plus récente, ce qui signifie lire les données du dernier enregistrement (l'enregistrement généré après le démarrage du consommateur). L'autre valeur est la plus ancienne, ce qui signifie que lorsque le décalage n'est pas valide, le consommateur Ou. commencez à lire les données à partir de la position de départ. 🎜🎜🎜🎜enable.auto.commit : Pas de déplacement automatique, si false, vous devez soumettre le déplacement manuellement dans le programme. Pour une sémantique exactement une fois, il est préférable de soumettre le déplacement manuellement 🎜🎜🎜🎜fetch.max.bytes : Le nombre maximum d'octets de données extraites en une seule fois 🎜🎜🎜🎜max.poll.records : Le nombre maximum de messages renvoyés par un seul appel d'interrogation. Si la logique de traitement est très légère, cette valeur peut être augmentée de manière appropriée. Maismax.poll. les données des enregistrementsdoivent être traitées dans session.timeout.ms. La valeur par défaut est 500🎜🎜🎜🎜request.timeout.ms : le temps d'attente maximum pour une réponse à une requête. Si aucune réponse n'est reçue dans le délai d'expiration, Kafka renverra le message ou échouera directement si le nombre de tentatives est dépassé.
value.serializercorrespond à la méthode de désérialisation de valeur. Kafka Rebalance
rebalance est essentiellement un protocole qui stipule comment tous les consommateurs d'un groupe de consommateurs peuvent parvenir à un accord pour attribuer chaque partition du sujet d'abonnement. Par exemple, il y a 20 consommateurs dans un certain groupe et celui-ci s'abonne à un sujet comportant 100 partitions. Dans des circonstances normales, Kafka alloue en moyenne 5 partitions à chaque consommateur. Ce processus d'allocation est appelé rééquilibrage.
Quand rééquilibrer ?
C'est aussi une question qui est souvent évoquée. Il existe trois conditions de déclenchement pour le rééquilibrage :
les membres du groupe changent (un nouveau consommateur rejoint le groupe, un consommateur existant quitte volontairement le groupe ou un consommateur existant plante - la différence entre les deux sera discutée plus tard) Abonnez-vous à le sujet Le nombre de partitions a changé Le nombre de partitions abonnés au sujet a changé
Comment allouer les partitions au sein du groupe ?
Kafka propose deux stratégies d'allocation par défaut : Range et Round-Robin. Bien entendu, Kafka adopte une stratégie d'allocation enfichable et vous pouvez créer votre propre allocateur pour mettre en œuvre différentes stratégies d'allocation.
Mots clés de réponse
Quels sont les outils de ligne de commande pour Kafka ? Lesquels avez-vous utilisé ? /binRépertoire, gérer le cluster kafka, gérer le sujet, produire et consommer du kafkaLe processus d'exécution de Kafka Producer ? Intercepteurs, sérialiseurs, partitionneurs et accumulateurs Quelles sont les configurations courantes de Kafka Producer ? Configuration du courtier, configuration de l'ack, paramètres réseau et d'envoi, paramètres de compression, paramètres ack Comment garder les messages Kafka en ordre ? Kafka lui-même n'est pas ordonné au niveau du sujet et n'est ordonné qu'au niveau de la partition. Par conséquent, afin de garantir l'ordre de traitement, vous pouvez personnaliser le partitionneur et envoyer les données qui doivent être traitées séquentiellement vers la même partition. s'assurer que les données sont envoyées sans problème ? Mécanisme d'accusé de réception, mécanisme de nouvelle tentative Comment améliorer les performances de Producer ? Batch, asynchrone, compression Si le nombre de consommateurs dans un même groupe est supérieur au nombre de pièces, comment Kafka le gère-t-il ? La partie redondante sera dans un état inutile et ne consommera pas de données Kafka Consumer est-il thread-safe ? Consommation dangereuse, monothread, traitement multithread Parlez-moi du modèle de thread lorsque vous utilisez Kafka Consumer pour consommer des messages. Pourquoi est-il conçu comme ça ? Séparation du tirage et du traitement Configurations courantes de Kafka Consumer ? courtier, paramètres réseau et pull, paramètres de battement de cœur Quand le consommateur sera-t-il expulsé du cluster ? Crash, anomalie du réseau, temps de traitement trop long, délai d'attente de déplacement de soumission Comment Kafka réagira-t-il lorsqu'un consommateur rejoint ou quitte ? Effectuer un rééquilibrage Qu'est-ce que le rééquilibrage et quand le rééquilibrage se produit-il ? Changements de sujet, changements de consommateurs - Haute disponibilité et performances
Questions
Comment Kafka assure-t-il la haute disponibilité ?
La sémantique de livraison de Kafka ? Que fait Replica ? Qu'est-ce qu'il y a AR, ISR ? Que sont Leader et Fleur ? Que signifient HW, LEO, LSO, LW, etc. dans Kafka ? Quel traitement Kafka a-t-il effectué pour garantir des performances supérieures ?
Partition et réplique
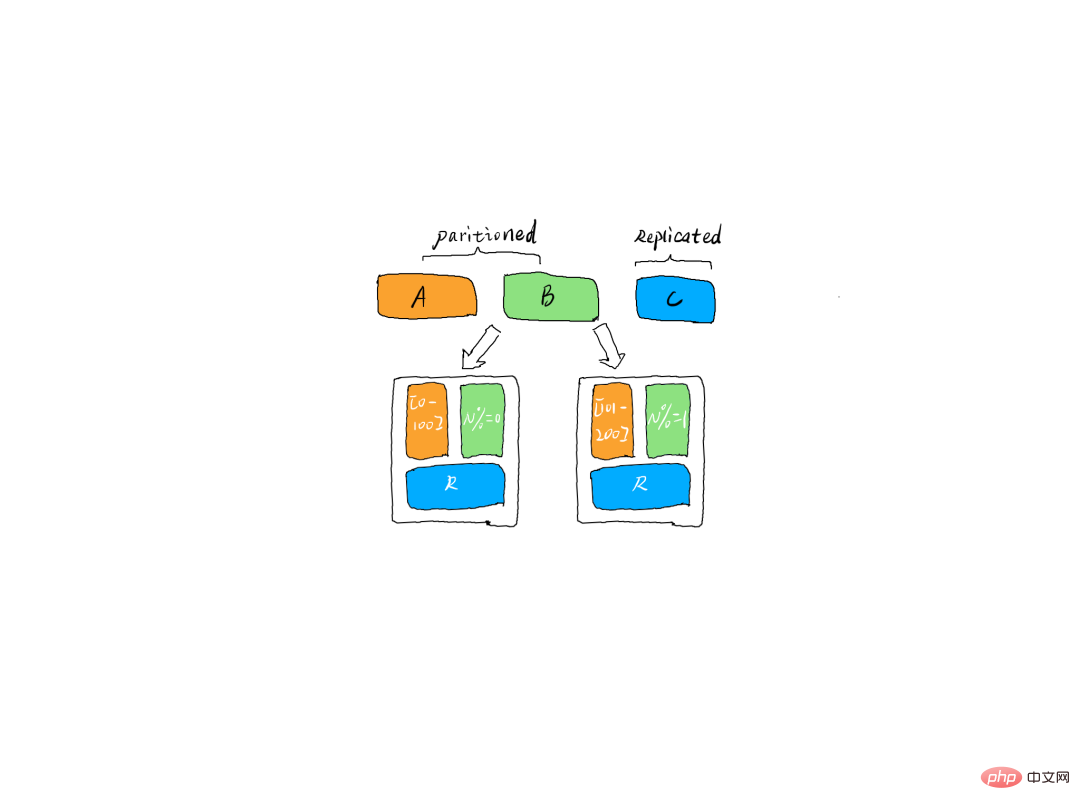
Dans les systèmes de données distribués, les partitions sont généralement utilisées pour améliorer la capacité de traitement du système et assurer la haute disponibilité des données via des répliques. Le partitionnement multiple signifie la possibilité de traiter simultanément parmi ces multiples copies, une seule est la copie leader et les autres sont les copies suiveuses. Seule la copie leader peut fournir des services au monde extérieur. Plusieurs copies suiveuses sont généralement stockées dans des courtiers différents de la copie leader. Grâce à ce mécanisme, une haute disponibilité est atteinte. Lorsqu'une machine raccroche, les autres copies suiveuses peuvent rapidement « revenir à la normale » et commencer à fournir des services au monde extérieur.
Pourquoi la copie suiveuse ne fournit-elle pas de service de lecture ?
Ce problème est essentiellement un compromis entre performances et cohérence. Imaginez, que se passerait-il si la copie suiveuse fournissait également des services au monde extérieur ? Tout d’abord, les performances seront définitivement améliorées. Mais en même temps, toute une série de problèmes vont surgir. Semblable à la lecture fantôme et à la lecture sale dans les transactions de base de données. Par exemple, si vous écrivez une donnée dans le sujet Kafka a, le consommateur b consomme les données du sujet a, mais constate qu'il ne peut pas les consommer car le dernier message n'a pas été écrit sur la copie de partition lue par le consommateur b. À ce moment-là, un autre consommateur c peut consommer les dernières données car il consomme la copie principale. Kafka utilise la gestion de WH et Offset pour déterminer quelles données le consommateur peut consommer et les données actuellement écrites.
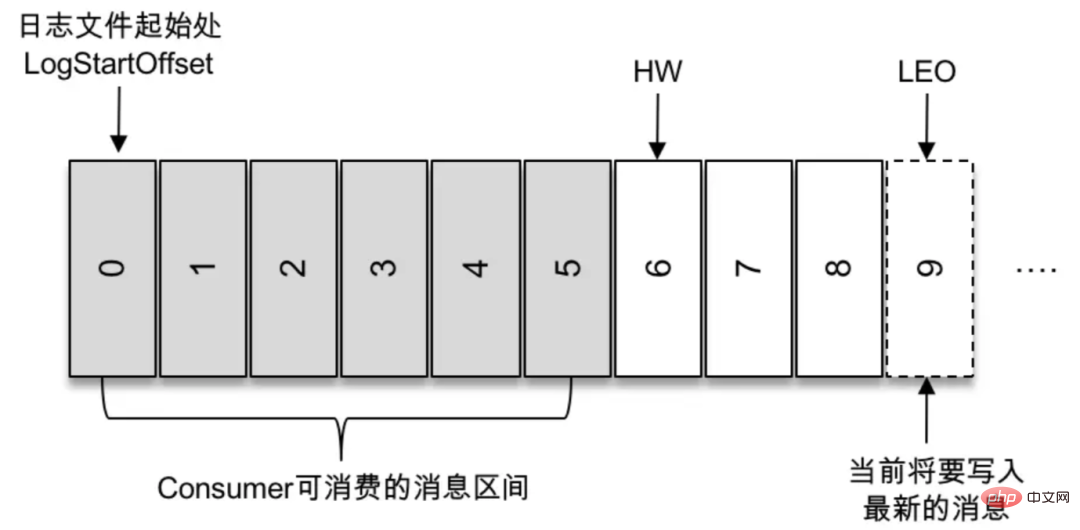
Seul le leader peut fournir des services de lecture externes, donc comment élire le leader
kafka placera les répliques synchronisées avec la réplique leader dans le jeu de répliques ISR. Bien entendu, la copie leader existe toujours dans l'ensemble de copies ISR. Dans certains cas particuliers, il n'y a même qu'une seule copie du leader dans la copie ISR. Lorsque le leader échoue, Kakfa détecte cette situation par l'intermédiaire du gardien de zoo, sélectionne une nouvelle copie dans la copie ISR pour devenir le leader et fournit des services au monde extérieur. Mais cela pose un autre problème : comme mentionné précédemment, il est possible qu'il n'y ait que le leader dans le jeu de répliques ISR. Lorsque la réplique leader meurt, l'ensemble ISR sera vide. À ce stade, si le paramètre unclean.leader.election.enable est défini sur true, Kafka sélectionnera une réplique pour devenir le leader en mode asynchrone, c'est-à-dire une réplique qui ne fait pas partie du jeu de répliques ISR.
L'existence d'une copie entraînera des problèmes de synchronisation de copie
Kafka maintient une liste de répliques disponibles (ISR) dans toutes les répliques allouées (AR) Lorsque le producteur envoie un message au courtier, il gérera la synchronisation des données entre la fleur et le leader en fonction du service ack配置来确定需要等待几个副本已经同步了消息才相应成功,Broker 内部会ReplicaManager.
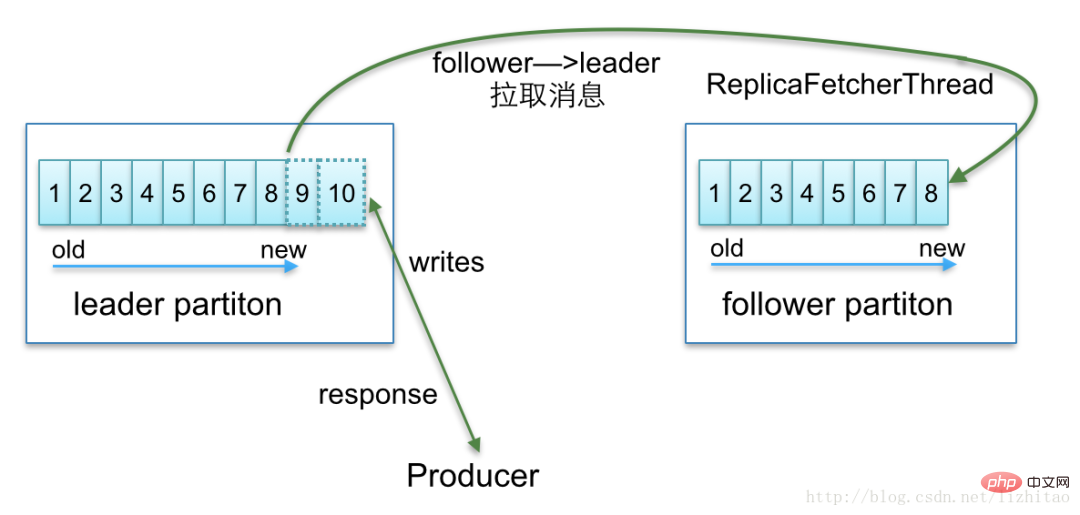
Optimisation des performances
Concurrence de partition Lecture et écriture séquentielles sur le disque Cache de page : lecture et écriture par page -
Pré-lecture : Kafka sera Les messages consommés sont lus en mémoire à l'avance. Batch : lecture et écriture par lots - Compression : compression des messages, compression du stockage, réduction de la surcharge du réseau et des E/S
- Concurrence des partitions
- D'une part, puisque différentes partitions peuvent être situées sur différentes machines , vous pouvez profiter pleinement des avantages du cluster, Réaliser un traitement parallèle entre les machines. D'un autre côté, étant donné que la partition correspond physiquement à un dossier, même si plusieurs partitions sont situées sur le même nœud, différentes partitions sur le même nœud peuvent être configurées pour être placées sur différents lecteurs de disque afin d'obtenir un traitement parallèle entre les disques. de plusieurs disques.
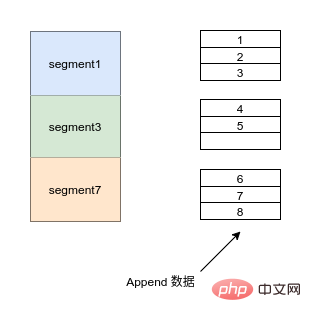
- Lecture et écriture séquentielles
- Les fichiers Kafka dans chaque répertoire de partition sont découpés uniformément en fichiers de données de taille égale (la taille du fichier par défaut est de 500 Mo, qui peut être définie manuellement).
Chaque fichier de données est appelé fichier de segment et chaque segment utilise l'ajout pour ajouter des données.

Ajouter des données Mot clé de réponse
Comment Kafka assure-t-il la haute disponibilité ?
Assurer la haute disponibilité des données via des répliques, un accusé de réception du producteur, une nouvelle tentative, l'élection automatique du leader, l'auto-équilibrage du consommateur
La sémantique de livraison de Kafka ?
La sémantique de livraison a généralement
at least once、at most once和exactly once. Kafka implémente les deux premiers via la configuration ack.Que fait Replica ?
Atteindre une haute disponibilité des données
Que sont l'AR et l'ISR ?
AR : répliques attribuées. AR est l'ensemble de réplicas alloués lors de la création de la partition après la création du sujet. Le nombre de réplicas est déterminé par le facteur de réplication. ISR : réplicas synchronisés. Un concept particulièrement important dans Kafka fait référence à l'ensemble des répliques en AR qui sont synchronisées avec le Leader. La réplique dans l'AR peut ne pas être dans l'ISR, mais la réplique Leader est naturellement incluse dans l'ISR. Concernant l'ISR, une autre question courante lors d'un entretien est de savoir comment déterminer si une copie doit appartenir à un ISR. Le jugement actuel est basé sur la question de savoir si le temps pendant lequel le LEO du réplica suiveur est en retard par rapport au LEO du leader dépasse la valeur du paramètre côté courtier replique.lag.time.max.ms. En cas de dépassement, la réplique est supprimée de l'ISR.
Que sont Leader et Fleur ?
Que signifie HW dans Kafka ?
Filigrane élevée. Il s'agit d'un champ important qui contrôle la portée du message que le consommateur peut lire. Un consommateur ordinaire ne peut « voir » que tous les messages sur la réplique Leader entre Log Start Offset et HW (exclusif). Les messages au-dessus du niveau de l’eau sont invisibles pour les consommateurs.
Quel traitement Kafka a-t-il effectué pour garantir des performances supérieures ?
Concurrence de partition, lecture et écriture séquentielles sur le disque, compression du cache de pages, sérialisation hautes performances (binaire), gestion des décalages sans verrouillage du mappage mémoire, modèle Java NIO
Cet article n'entre pas dans l'implémentation Les détails et l'analyse du code source de Kafka, mais Kafka est en effet un excellent système open source. De nombreuses conceptions architecturales et conceptions de code source élégantes méritent d'être apprises. Il est fortement recommandé aux étudiants intéressés d'avoir une compréhension plus approfondie de ce système open source. les capacités de conception architecturale, les capacités de codage et l’optimisation des performances seront d’une grande aide.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Générateur de nombres aléatoires en Java
Aug 30, 2024 pm 04:27 PM
Générateur de nombres aléatoires en Java
Aug 30, 2024 pm 04:27 PM
Guide du générateur de nombres aléatoires en Java. Nous discutons ici des fonctions en Java avec des exemples et de deux générateurs différents avec d'autres exemples.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
