
 base de données
tutoriel mysql
Interview Meituan : Quels pièges avez-vous rencontrés en utilisant MySQL ?
base de données
tutoriel mysql
Interview Meituan : Quels pièges avez-vous rencontrés en utilisant MySQL ?
Interview Meituan : Quels pièges avez-vous rencontrés en utilisant MySQL ?
Intervieweur : Vous maîtrisez encore assez bien le verrouillage.
Rookie moi : (souriant légèrement pour exprimer sa réponse)
Intervieweur : Après avoir utilisé MySQL pendant tant d'années, quels sont les pièges que vous n'oublierez jamais.
Rookie me : Balabala commence à parler (j'ai déjà préparé ce genre de question d'entretien avant l'entretien, alors saupoudrez-la d'eau)
Ci-dessous, j'ai compilé quelques utilisations standardisées du développement de bases de données basées sur mon expérience réelle d'utilisation. 6 "Eviter" pour résumer. 避免”来概括。
1、避免在数据库中做运算
有句话叫做“别让脚趾头想事情,那是脑瓜子的职责”,用在数据库开发中,说的就是避免让数据库做她不擅长的事情。MySQL
1. Évitez de faire des calculs dans la base de données
Il y a un dicton appelé "Ne laissez pas vos orteils réfléchir, c'est la responsabilité de votre cerveau", utilisé dans le développement de bases de données, signifie éviter de laisser la base de données faire des choses qu'elle n'est pas bon à. MySQL n'est pas doué pour les opérations mathématiques et logiques jugements, essayez donc de ne pas faire de calculs dans la base de données, et les calculs complexes peuvent être déplacés vers le processeur côté programme. 🎜🎜🎜2. Évitez de faire des opérations sur les colonnes d'index🎜🎜 🎜🎜🎜Une fois, un collègue m'a demandé de regarder un SQL, disant qu'il est très rapide d'interroger au premier plan, mais lorsque le SQL est retiré et exécuté dans la base de données, aucun résultat n'est sorti après 10 minutes d'exécution. Après avoir regardé le SQL, j'ai finalement localisé une sous-requête dans une vue. Le texte SQL de cette sous-requête est le suivant : 🎜## 以下SQL来源于网络
SELECT acinv_07.id_item ,
SUM(acinv_07.dec_endqty) dec_endqty
FROM acinv_07
WHERE acinv_07.fiscal_year * 100 + acinv_07.fiscal_period
= ( SELECT DISTINCT
ctlm1101.fiscal_year * 100 + ctlm1101.fiscal_period
FROM ctlm1101 WHERE flag_curr = 'Y'
AND id_oprcode = 'acinv'
AND acinv_07.id_wh = ctlm1101.id_table)
GROUP BY acinv_07.id_itemLes colonnes fiscal_year et la colonne fiscal_period de la table acinv_07 sont indexées. Cependant, si des opérations sont effectuées sur les colonnes d'index, l'index ne sera pas disponible pour celles qui auraient pu être indexées. Je l'ai donc réécrit dans le SQL suivant :
## 以下SQL来源于网络
SELECT id_item ,
SUM(dec_qty) dec_qty
FROM dpurreq_03
GROUP BY id_item
) a ,
( SELECT a.id_item ,
SUM(a.dec_endqty) dec_endqty
FROM acinv_07 a ,
( SELECT DISTINCT
ctlm1101.fiscal_year ,
ctlm1101.fiscal_period ,
id_table
FROM ctlm1101
WHERE flag_curr = 'Y'
AND id_oprcode = 'acinv'
) b
WHERE a.fiscal_year = b.fiscal_year
AND a.fiscal_period = b.fiscal_period
AND a.id_wh = b.id_table
GROUP BY a.id_itemEnsuite, exécutez-le, et les résultats seront disponibles dans environ 4 secondes. En général, lors de l'écriture de SQL, n'effectuez pas de calculs sur les colonnes d'index, sauf en cas d'absolue nécessité.
3. Évitez count(*)
Lors de l'exécution de requêtes de pagination, certaines personnes sont toujours habituées à utiliser select count() pour obtenir le nombre total d'enregistrements. En fait, ce n'est pas efficace. , parce que les données ont été interrogées une fois auparavant, select count() équivaut à interroger la même instruction deux fois, et la surcharge sur la base de données sera naturellement importante. Nous devrions utiliser l'API fournie avec la base de données ou le système. variables pour faire le travail.
4. Évitez d'utiliser des champs NULL
Tout le monde devrait essayer d'ajouter NOT NULL DEFAULT' lors de la conception des champs de table de base de données. L'utilisation de champs NULL aura de nombreux effets néfastes, tels que : il est difficile d'optimiser les requêtes, l'ajout d'index aux colonnes NULL nécessite de l'espace supplémentaire et les index composés contenant NULL ne sont pas valides...
Regardez le cas suivant :
数据初始化:
create table table1 (
`id` INT (11) NOT NULL,
`name` varchar(20) NOT NULL
)
create table table2 (
`id` INT (11) NOT NULL,
`name` varchar(20)
)
insert into table1 values (4,"tianweichang"),(2,"zhangsan"),(3,"lisi")
insert into table2 values (1,"tianweichang"),(2, null)(1) La sous-requête NOT IN renvoie des résultats toujours vides lorsqu'il y a une valeur NULL, et la requête est sujette aux erreurs
select name from table1 where name not in (select name from table2 where id!=1)
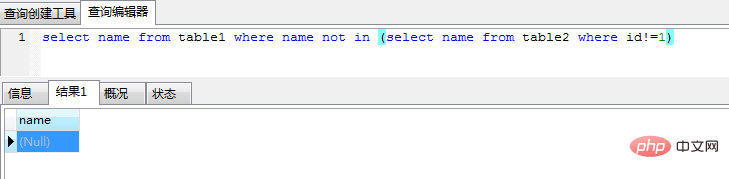
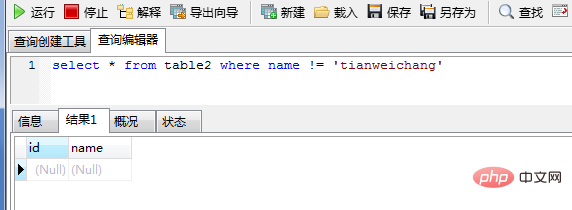
(2) Valeurs de colonne sont autorisés à être vides, l'index ne stocke pas les valeurs nulles et ces enregistrements ne seront pas inclus dans le jeu de résultats.
select * from table2 where name != 'tianweichang'
select * from table2 where name != 'zhaoyun1'
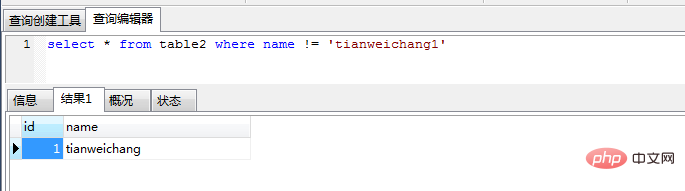
(3) Lorsque vous utilisez concatsplicing, vous devez d'abord faire un jugement non nul sur chaque champ, sinon tant qu'un champ est vide, le résultat de l'épissage sera nul
select concat("1", null) from dual;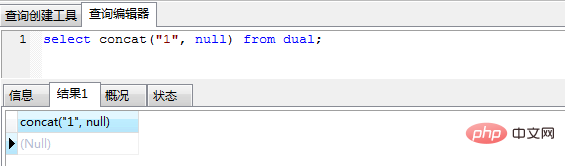
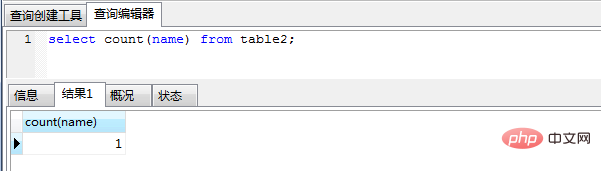
(4) 当计算count时候,name为null 的不会计入统计
select count(name) from table2;
5、避免select
使用 select *可能会返回不使用的列的数据。它在MySQL数据库服务器和应用程序之间产生不必要的I/O磁盘和网络流量。如果明确指定列,则结果集更可预测并且更易于管理。想象一下,当您使用 select *并且有人通过添加更多列来更改表格数据时,将会得到一个与预期不同的结果集。使用 select *可能会将敏感信息暴露给未经授权的用户。
6、避免在数据库里存图片
图片确实是可以存储到数据库里的,例如通过二进制流将图片存到数据库中。
但是,强烈不建议把图片存储到数据库中!!!!首先对数据库的读/写的速度永远都赶不上文件系统处理的速度,其次数据库备份变的巨大,越来越耗时间,最后对文件的访问需要穿越你的应用层和数据库层。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
Dans la base de données MySQL, la relation entre l'utilisateur et la base de données est définie par les autorisations et les tables. L'utilisateur a un nom d'utilisateur et un mot de passe pour accéder à la base de données. Les autorisations sont accordées par la commande Grant, tandis que le tableau est créé par la commande Create Table. Pour établir une relation entre un utilisateur et une base de données, vous devez créer une base de données, créer un utilisateur, puis accorder des autorisations.
 MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL convient aux débutants car il est simple à installer, puissant et facile à gérer les données. 1. Installation et configuration simples, adaptées à une variété de systèmes d'exploitation. 2. Prise en charge des opérations de base telles que la création de bases de données et de tables, d'insertion, d'interrogation, de mise à jour et de suppression de données. 3. Fournir des fonctions avancées telles que les opérations de jointure et les sous-questionnaires. 4. Les performances peuvent être améliorées par l'indexation, l'optimisation des requêtes et le partitionnement de la table. 5. Prise en charge des mesures de sauvegarde, de récupération et de sécurité pour garantir la sécurité et la cohérence des données.
 Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Navicat lui-même ne stocke pas le mot de passe de la base de données et ne peut récupérer que le mot de passe chiffré. Solution: 1. Vérifiez le gestionnaire de mots de passe; 2. Vérifiez la fonction "Remember Motway" de Navicat; 3. Réinitialisez le mot de passe de la base de données; 4. Contactez l'administrateur de la base de données.
 L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
1. Utilisez l'index correct pour accélérer la récupération des données en réduisant la quantité de données numérisées SELECT * FROMMLOYEESEESHWHERELAST_NAME = 'SMITH'; Si vous recherchez plusieurs fois une colonne d'une table, créez un index pour cette colonne. If you or your app needs data from multiple columns according to the criteria, create a composite index 2. Avoid select * only those required columns, if you select all unwanted columns, this will only consume more server memory and cause the server to slow down at high load or frequency times For example, your table contains columns such as created_at and updated_at and timestamps, and then avoid selecting * because they do not require inefficient query se
 Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Créez une base de données à l'aide de NAVICAT Premium: Connectez-vous au serveur de base de données et entrez les paramètres de connexion. Cliquez avec le bouton droit sur le serveur et sélectionnez Créer une base de données. Entrez le nom de la nouvelle base de données et le jeu de caractères spécifié et la collation. Connectez-vous à la nouvelle base de données et créez le tableau dans le navigateur d'objet. Cliquez avec le bouton droit sur le tableau et sélectionnez Insérer des données pour insérer les données.
 Comment copier des tables dans MySQL
Apr 08, 2025 pm 07:24 PM
Comment copier des tables dans MySQL
Apr 08, 2025 pm 07:24 PM
La copie d'une table dans MySQL nécessite la création de nouvelles tables, l'insertion de données, la définition de clés étrangères, la copie des index, les déclencheurs, les procédures stockées et les fonctions. Les étapes spécifiques incluent: la création d'une nouvelle table avec la même structure. Insérez les données de la table d'origine dans une nouvelle table. Définissez la même contrainte de clé étrangère (si le tableau d'origine en a un). Créer le même index. Créez le même déclencheur (si le tableau d'origine en a un). Créez la même procédure ou fonction stockée (si la table d'origine est utilisée).
 Comment afficher le mot de passe de la base de données dans NAVICAT pour MARIADB?
Apr 08, 2025 pm 09:18 PM
Comment afficher le mot de passe de la base de données dans NAVICAT pour MARIADB?
Apr 08, 2025 pm 09:18 PM
NAVICAT pour MARIADB ne peut pas afficher directement le mot de passe de la base de données car le mot de passe est stocké sous forme cryptée. Pour garantir la sécurité de la base de données, il existe trois façons de réinitialiser votre mot de passe: réinitialisez votre mot de passe via Navicat et définissez un mot de passe complexe. Affichez le fichier de configuration (non recommandé, haut risque). Utilisez des outils de ligne de commande système (non recommandés, vous devez être compétent dans les outils de ligne de commande).
 Comment voir Mysql
Apr 08, 2025 pm 07:21 PM
Comment voir Mysql
Apr 08, 2025 pm 07:21 PM
Affichez la base de données MySQL avec la commande suivante: Connectez-vous au serveur: MySQL -U Username -P mot de passe Exécuter les bases de données Afficher les bases de données; Commande pour obtenir toutes les bases de données existantes Sélectionnez la base de données: utilisez le nom de la base de données; Tableau de vue: afficher des tables; Afficher la structure de la table: décrire le nom du tableau; Afficher les données: sélectionnez * dans le nom du tableau;
