À propos du SQL lent, l'intervieweur et moi avons discuté pendant longtemps. L'intervieweur était également très humble et hochait toujours la tête, je pensais que ma réponse était correcte. À la fin, j'ai quand même dit "你先回去等通知吧!".
J'ai donc décidé de partager avec vous ce point technique lent du SQL. J'espère que la prochaine fois que vous rencontrerez un entretien similaire, vous pourrez obtenir l'offre que vous souhaitez en douceur et facilement.
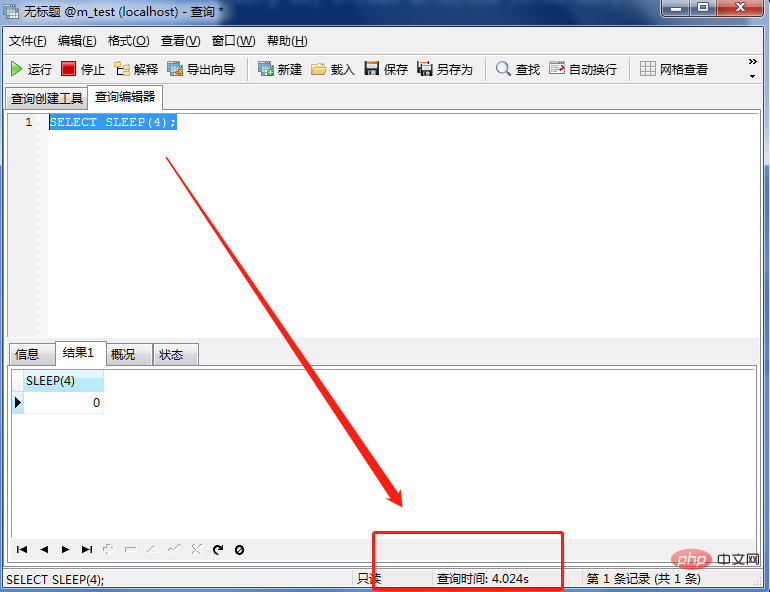
La plus grande joie dans la vie est que tout le monde dit que vous ne pouvez pas le faire, mais vous le terminez ! qui est utilisé pour enregistrer les instructions dont le temps de requête dans MySQL dépasse (supérieur à) le seuil défini (long_query_time) et les enregistre dans le journal des requêtes lentes.
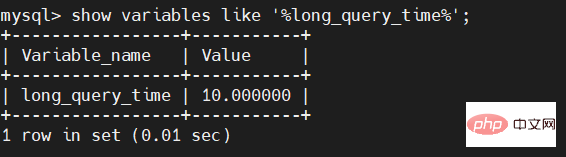
Parmi eux, la valeur par défaut de long_query_time est 10, et l'unité est la seconde. C'est-à-dire que par défaut, le temps de votre requête SQL dépasse 10 secondes, ce qui est considéré comme un SQL lent.
Comment activer le journal SQL lent ?
Dans MySQL, le journal SQL lent n'est pas activé par défaut, ce qui signifie que même si un SQL lent se produit, il ne vous le dira pas. Si vous avez besoin de savoir quel SQL est SQL lent, nous devons l'activer manuellement. journal SQL lent de. Quant à savoir si le SQL lent est activé, nous pouvons le vérifier via la commande suivante :
-- 查看慢查询日志是否开启
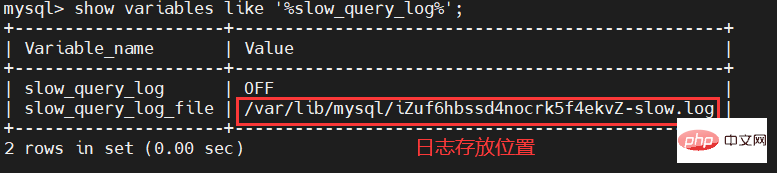
show variables like '%slow_query_log%';
Copier après la connexion
Insérer la description de l'image ici
Grâce à la commande, nous pouvons voir que l'élément slow_query_log est désactivé, indiquant que notre journal SQL lent n'est pas activé. De plus, nous pouvons également voir le répertoire où sont stockés nos journaux SQL lents et le nom du fichier journal.
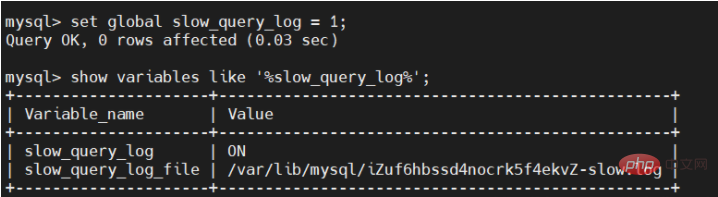
Activons le journal SQL lent et exécutons la commande suivante :
set global slow_query_log = 1;
Copier après la connexion
Il convient de noter que ce qui est activé ici est notre base de données actuelle, et elle ne sera pas valide après le redémarrage de la base de données.
Après avoir activé le journal SQL lent, vérifiez à nouveau :
slow_query_log est activé, indiquant qu'il est activé avec succès.
Comme mentionné ci-dessus, la durée par défaut de notre SQL lent est de 10 secondes. Nous pouvons voir la durée par défaut de notre SQL lent grâce à la commande suivante :
show variables like '%long_query_time%';
Copier après la connexion
Insérer la description de l'image ici
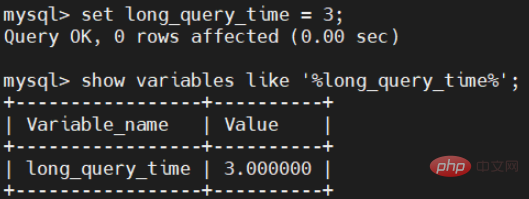
Nous ne pouvons pas toujours l'utiliser. valeur par défaut, de nombreuses entreprises peuvent nécessiter un temps plus court ou plus long, nous devons donc à ce moment modifier le temps par défaut. La commande de modification est la suivante :
set long_query_time = 3;
Copier après la connexion
Après la modification, voyons si elle a été modifiée à 3 secondes.
Quelque chose à noter ici : Si vous souhaitez que cela prenne effet de manière permanente, vous devez également modifier le fichier de configuration my.cnf sous MySQL.
Remarque : différents systèmes d'exploitation ont des configurations légèrement différentes.
Dans le système d'exploitation Linux
Ajoutez
log-slow-queries=/var/lib/mysql/slowquery.log dans le fichier de configuration mysql my.cnf (précisez l'emplacement de stockage du fichier journal, il peut être vide, le système va Un fichier par défaut host_name-slow.log)
long_query_time=2 (enregistrer le temps dépassé, la valeur par défaut est 10s)
~# mysqldumpslow --help
Usage: mysqldumpslow [ OPTS... ] [ LOGS... ]
Parse and summarize the MySQL slow query log. Options are
--verbose verbose
--debug debug
--help write this text to standard output
-v verbose
-d debug
-s ORDER what to sort by (al, at, ar, c, l, r, t), 'at' is default
al: average lock time
ar: average rows sent
at: average query time
c: count
l: lock time
r: rows sent
t: query time
-r reverse the sort order (largest last instead of first)
-t NUM just show the top n queries
-a don't abstract all numbers to N and strings to 'S'
-n NUM abstract numbers with at least n digits within names
-g PATTERN grep: only consider stmts that include this string
-h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard),
default is '*', i.e. match all
-i NAME name of server instance (if using mysql.server startup script)
-l don't subtract lock time from total time
Copier après la connexion
比较常用的参数有这么几个:
-s 指定输出的排序方式
t : 根据query time(执行时间)进行排序;
at : 根据average query time(平均执行时间)进行排序;(默认使用的方式)
l : 根据lock time(锁定时间)进行排序;
al : 根据average lock time(平均锁定时间)进行排序;
r : 根据rows(扫描的行数)进行排序;
ar : 根据average rows(扫描的平均行数)进行排序;
c : 根据日志中出现的总次数进行排序;
-t 指定输出的sql语句条数;
-a 不进行抽象显示(默认会将数字抽象为N,字符串抽象为S);
-g 满足指定条件,与grep相似;
-h 用来指定主机名(指定打开文件,通常慢查询日志名称为“主机名-slow.log”,用-h exp则表示打开exp-slow.log文件);
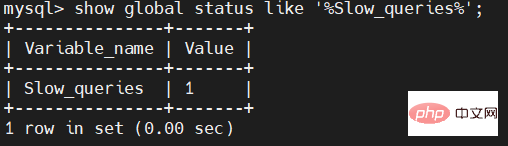
Rows=90884.0 (42170176) : La première valeur représente le nombre moyen de lignes analysées (-s ar), et la valeur entre parenthèses représente le nombre total de lignes analysées (-s r).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration de ce site Web
Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn
HQL et SQL sont comparés dans le framework Hibernate : HQL (1. Syntaxe orientée objet, 2. Requêtes indépendantes de la base de données, 3. Sécurité des types), tandis que SQL exploite directement la base de données (1. Normes indépendantes de la base de données, 2. Exécutable complexe requêtes et manipulation de données).
"Utilisation de l'opération de division dans OracleSQL" Dans OracleSQL, l'opération de division est l'une des opérations mathématiques courantes. Lors de l'interrogation et du traitement des données, les opérations de division peuvent nous aider à calculer le rapport entre les champs ou à dériver la relation logique entre des valeurs spécifiques. Cet article présentera l'utilisation de l'opération de division dans OracleSQL et fournira des exemples de code spécifiques. 1. Deux méthodes d'opérations de division dans OracleSQL Dans OracleSQL, les opérations de division peuvent être effectuées de deux manières différentes.
Oracle et DB2 sont deux systèmes de gestion de bases de données relationnelles couramment utilisés, chacun possédant sa propre syntaxe et ses propres caractéristiques SQL. Cet article comparera et différera la syntaxe SQL d'Oracle et de DB2, et fournira des exemples de code spécifiques. Connexion à la base de données Dans Oracle, utilisez l'instruction suivante pour vous connecter à la base de données : CONNECTusername/password@database Dans DB2, l'instruction pour vous connecter à la base de données est la suivante : CONNECTTOdataba.
Interprétation des balises SQL dynamiques MyBatis : explication détaillée de l'utilisation des balises Set MyBatis est un excellent cadre de couche de persistance. Il fournit une multitude de balises SQL dynamiques et peut construire de manière flexible des instructions d'opération de base de données. Parmi elles, la balise Set est utilisée pour générer la clause SET dans l'instruction UPDATE, qui est très couramment utilisée dans les opérations de mise à jour. Cet article expliquera en détail l'utilisation de la balise Set dans MyBatis et démontrera ses fonctionnalités à travers des exemples de code spécifiques. Qu'est-ce que Set tag Set tag est utilisé dans MyBati
Qu'est-ce que l'identité en SQL ? Des exemples de code spécifiques sont nécessaires. En SQL, l'identité est un type de données spécial utilisé pour générer des nombres à incrémentation automatique. Il est souvent utilisé pour identifier de manière unique chaque ligne de données dans une table. La colonne Identité est souvent utilisée conjointement avec la colonne clé primaire pour garantir que chaque enregistrement possède un identifiant unique. Cet article détaillera comment utiliser Identity et quelques exemples de code pratiques. La manière de base d'utiliser Identity consiste à utiliser Identit lors de la création d'une table.
Lorsque Springboot+Mybatis-plus n'utilise pas d'instructions SQL pour effectuer des opérations d'ajout de plusieurs tables, les problèmes que j'ai rencontrés sont décomposés en simulant la réflexion dans l'environnement de test : Créez un objet BrandDTO avec des paramètres pour simuler le passage des paramètres en arrière-plan. qu'il est extrêmement difficile d'effectuer des opérations multi-tables dans Mybatis-plus. Si vous n'utilisez pas d'outils tels que Mybatis-plus-join, vous pouvez uniquement configurer le fichier Mapper.xml correspondant et configurer le ResultMap malodorant et long, puis. écrivez l'instruction SQL correspondante Bien que cette méthode semble lourde, elle est très flexible et nous permet de
Solution : 1. Vérifiez si l'utilisateur connecté dispose des autorisations suffisantes pour accéder ou utiliser la base de données, et assurez-vous que l'utilisateur dispose des autorisations appropriées ; 2. Vérifiez si le compte du service SQL Server est autorisé à accéder au fichier spécifié ou ; dossier et assurez-vous que le compte dispose des autorisations suffisantes pour lire et écrire le fichier ou le dossier ; 3. Vérifiez si le fichier de base de données spécifié a été ouvert ou verrouillé par d'autres processus, essayez de fermer ou de libérer le fichier et réexécutez la requête ; . Essayez en tant qu'administrateur, exécutez Management Studio en tant que etc.
Comment utiliser les instructions SQL pour l'agrégation de données et les statistiques dans MySQL ? L'agrégation des données et les statistiques sont des étapes très importantes lors de l'analyse des données et des statistiques. En tant que puissant système de gestion de bases de données relationnelles, MySQL fournit une multitude de fonctions d'agrégation et de statistiques, qui peuvent facilement effectuer des opérations d'agrégation de données et de statistiques. Cet article présentera la méthode d'utilisation des instructions SQL pour effectuer l'agrégation de données et les statistiques dans MySQL, et fournira des exemples de code spécifiques. 1. Utilisez la fonction COUNT pour compter. La fonction COUNT est la plus couramment utilisée.

 base de données
base de données

















 Quelle est la différence entre HQL et SQL dans le framework Hibernate ?
Apr 17, 2024 pm 02:57 PM
Quelle est la différence entre HQL et SQL dans le framework Hibernate ?
Apr 17, 2024 pm 02:57 PM
 Utilisation de l'opération de division dans Oracle SQL
Mar 10, 2024 pm 03:06 PM
Utilisation de l'opération de division dans Oracle SQL
Mar 10, 2024 pm 03:06 PM
 Comparaison et différences de syntaxe SQL entre Oracle et DB2
Mar 11, 2024 pm 12:09 PM
Comparaison et différences de syntaxe SQL entre Oracle et DB2
Mar 11, 2024 pm 12:09 PM
 Explication détaillée de la fonction Définir la balise dans les balises SQL dynamiques MyBatis
Feb 26, 2024 pm 07:48 PM
Explication détaillée de la fonction Définir la balise dans les balises SQL dynamiques MyBatis
Feb 26, 2024 pm 07:48 PM
 Que signifie l'attribut d'identité dans SQL ?
Feb 19, 2024 am 11:24 AM
Que signifie l'attribut d'identité dans SQL ?
Feb 19, 2024 am 11:24 AM
 Comment implémenter Springboot+Mybatis-plus sans utiliser d'instructions SQL pour ajouter plusieurs tables
Jun 02, 2023 am 11:07 AM
Comment implémenter Springboot+Mybatis-plus sans utiliser d'instructions SQL pour ajouter plusieurs tables
Jun 02, 2023 am 11:07 AM
 Comment résoudre l'erreur 5120 dans SQL
Mar 06, 2024 pm 04:33 PM
Comment résoudre l'erreur 5120 dans SQL
Mar 06, 2024 pm 04:33 PM
 Comment utiliser les instructions SQL pour l'agrégation de données et les statistiques dans MySQL ?
Dec 17, 2023 am 08:41 AM
Comment utiliser les instructions SQL pour l'agrégation de données et les statistiques dans MySQL ?
Dec 17, 2023 am 08:41 AM
