

Retour sur l'interview Série de 25 plans de Spring Cloud
Avant-propos
Pour des raisons particulières il y a quelque temps, nos entretiens ont été interrompus d'affilée. Il est arrivé qu'un vieil homme se soit rendu à l'entretien la semaine dernière et ait été interrogé sur Spring Cloud, puis. combiné à ses commentaires, nous continuons aujourd'hui la série d'interviews SpringCloud.
Bienvenue à tous pour me suivre :
Résumé des connaissances de base de Spring Cloud
Ce qui suit est un diagramme de relation entre les composants principaux de Spring Cloud :
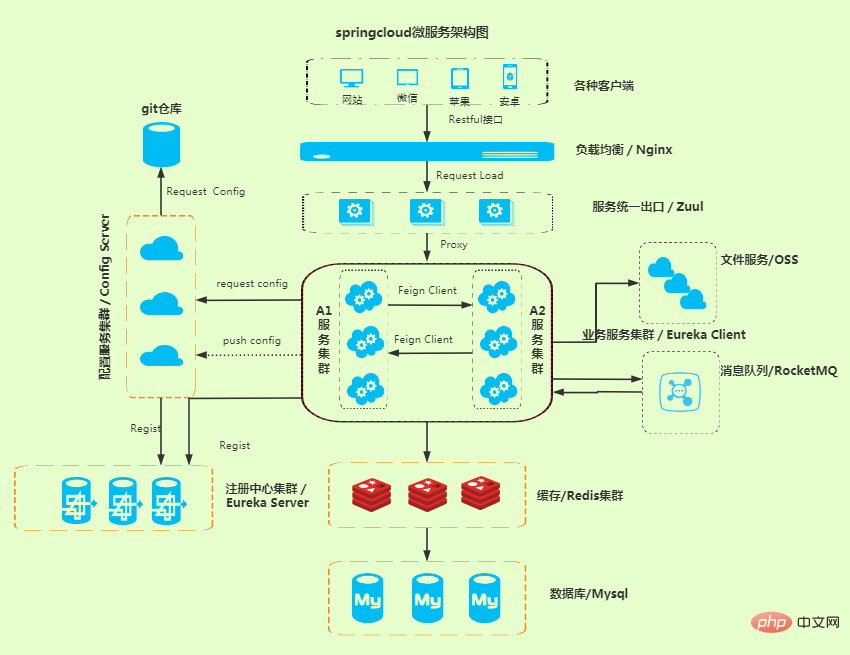
de Sur cette photo, nous pouvons en fait obtenir beaucoup d'informations, et j'espère que vous pourrez les savourer avec soin.
Ce qui suit est un résumé des Spring Cloud Netflix和Spring Cloud Alibabacomposants principaux :
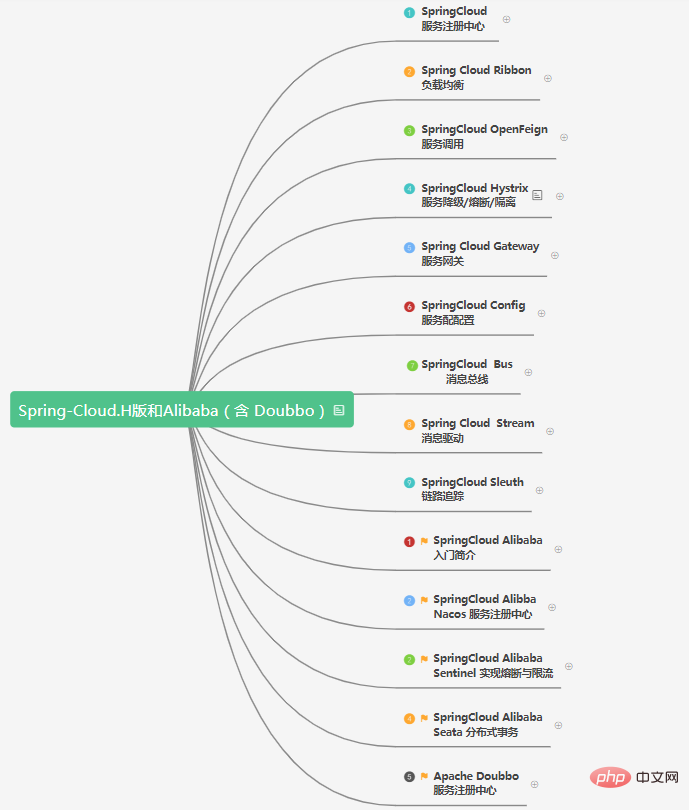
Sans plus tarder, commençons directement la série Spring Cloud.
Un pistolet en série arrive
1. Qu'est-ce que Spring Cloud ?
Spring cloud streaming application starter est une application intégrée Spring basée sur Spring Boot qui permet l'intégration avec des systèmes externes. Spring Cloud Task, un framework de microservices de courte durée permettant de créer rapidement des applications effectuant un traitement de données limité.
2. Que sont les microservices ?
L'architecture des microservices est un modèle architectural ou un style architectural. Elle préconise de diviser une seule application en un ensemble de petits services. Chaque service fonctionne selon son propre processus indépendant. Entre les services, coordonnez et coopérez les uns avec les autres pour offrir aux utilisateurs une solution ultime. valeur. Les services utilisent des mécanismes de communication légers pour communiquer entre eux (généralement une API RESTful basée sur HTTP). Chaque service est construit autour d'une activité spécifique et peut être construit indépendamment dans un environnement de production, un environnement de type production, etc. De plus, un mécanisme de gestion de services unifié et centralisé doit être évité. Pour un service spécifique, des langages et des outils appropriés doivent être sélectionnés en fonction du contexte commercial pour le construire. Il peut y avoir une gestion centralisée très légère pour coordonner ces services. , différents langages peuvent être utilisés pour écrire les services et différents magasins de données peuvent être utilisés.
En termes simples :
Un microservice est une application de service indépendante avec une seule responsabilité. Dans l'outil Intellij Idea, il existe des modules indépendants développés à l'aide de Maven. Plus précisément, il s'agit d'un petit module développé à l'aide de Springboot pour gérer une seule logique métier professionnelle.
Les microservices mettent l'accent sur la taille du service, en se concentrant sur un certain point, résolvant spécifiquement un certain problème/implémentant une application de service correspondante, qui peut être considérée comme un module dans l'idée.
3. Quels sont les avantages de Spring Cloud
Lorsque nous utilisons Spring Boot pour développer des microservices distribués, nous sommes confrontés aux problèmes suivants
Complexité associée aux systèmes distribués - Cette surcharge comprend les problèmes de réseau, la surcharge de latence, les problèmes de bande passante et les problèmes de sécurité. Service Discovery - Les outils de découverte de services gèrent la manière dont les processus et les services d'un cluster se trouvent et se parlent. Cela implique un catalogue de services, l'enregistrement des services dans ce catalogue, puis la possibilité de rechercher et de se connecter aux services de ce catalogue. Redondance - Problèmes de redondance dans les systèmes distribués. Équilibrage de charge : l'équilibrage de charge améliore la répartition des charges de travail sur plusieurs ressources informatiques, telles que les ordinateurs, les clusters d'ordinateurs, les liaisons réseau, les unités centrales de traitement ou les lecteurs de disque. Performance-Problème Problèmes de performances dus à divers frais généraux opérationnels. Complexité du déploiement - Exigences en matière de compétences Devops.
4. Comment les microservices communiquent-ils de manière indépendante ?
Communication synchrone : dobbo utilise les appels de procédure à distance RPC, springcloud utilise les appels json de l'interface REST, etc.
Asynchrone : file d'attente de messages, telle que : RabbitMq、ActiveM、Kafka et autres files d'attente de messages.
5. Qu'est-ce qu'un disjoncteur de service ? Qu’est-ce que le déclassement du service ?
Le mécanisme du disjoncteur est un mécanisme de protection des liaisons microservices pour faire face à l'effet d'avalanche. Lorsqu'un certain microservice est indisponible ou que le temps de réponse est trop long, le service sera dégradé, interrompant ainsi l'appel du microservice sur le nœud et renvoyant rapidement des informations de réponse « d'erreur ». Lorsqu'il est détecté que la réponse à l'appel du microservice du nœud est normale, la liaison d'appel est restaurée. Dans le framework Spring Cloud, le mécanisme de disjoncteur est implémenté via Hystrix. Hystrix surveillera l'état des appels entre les microservices. Lorsque les appels échoués atteignent un certain seuil, la valeur par défaut est de 20 appels dans les 5 secondes. sera activé.
Le déclassement du service est généralement pris en compte à partir de la charge globale. Autrement dit, lorsqu'un service est déconnecté, le serveur ne sera plus appelé. À ce moment, le client peut préparer un rappel de secours local et renvoyer une valeur par défaut. De cette façon, même si le niveau est réduit, il reste utilisable, ce qui est mieux que de mourir directement.
Hystrix相关注解@EnableHystrix:开启熔断 @HystrixCommand(fallbackMethod=”XXX”),声明一个失败回滚处理函数XXX,当被注解的方法执行超时(默认是1000毫秒),就会执行fallbackFonction, renvoie un message d'erreur.
6. S'il vous plaît, dites-moi la différence entre Eureka et le gardien de zoo ?
Zookeeper garantit CP et Eureka garantit AP.
A : Haute disponibilité
C : Cohérence
P : Tolérance aux pannes de partition
1. Lorsque nous interrogeons le centre d'enregistrement pour une liste de services, nous pouvons tolérer que le centre d'enregistrement renvoie des informations d'il y a quelques minutes, mais nous ne peut pas tolérer directement vers le bas et indisponible. En d'autres termes, la fonction d'enregistrement du service a des exigences relativement élevées en matière de haute disponibilité, mais il y aura une situation dans ZooKeeper lorsque le nœud maître perdra le contact avec d'autres nœuds en raison d'une défaillance du réseau, les nœuds restants rééliront le leader. Le problème est que le temps de sélection du leader est trop long, 30 ~ 120 s, et que le cluster zk n'est pas disponible pendant la période de sélection, ce qui entraînera la paralysie du service d'enregistrement pendant la période de sélection. Dans un environnement de déploiement cloud, il est fort probable que le cluster zk perde le nœud maître en raison de problèmes de réseau. Bien que le service puisse être restauré, l'indisponibilité à long terme de l'enregistrement causée par le long temps de sélection est intolérable.
2. Eureka garantit la disponibilité. Chaque nœud Eureka est égal. La panne de plusieurs nœuds n'affectera pas le travail des nœuds normaux. Si un échec de connexion se produit lorsque le client Eureka enregistre ou découvre un certain Eureka, il basculera automatiquement vers d'autres nœuds. Tant qu'un Eureka est toujours disponible, la disponibilité du service d'enregistrement peut être garantie, mais les informations trouvées peuvent ne pas l'être. le dernier. De plus, Eureka dispose également d'un mécanisme d'autoprotection. Si plus de 85 % des nœuds n'ont pas de battements de cœur normaux dans les 15 minutes, alors Eureka pensera qu'une panne de réseau s'est produite entre le client et le centre d'enregistrement. , les situations suivantes se produiront :
①. Eureka ne supprimera plus de la liste d'inscription les services qui devraient expirer car ils n'ont pas reçu de battements de cœur depuis longtemps.
②. Eureka peut toujours accepter les demandes d'inscription et de requête pour de nouveaux services, mais il ne sera pas synchronisé avec d'autres nœuds (c'est-à-dire garantir que le nœud actuel est toujours disponible)
.③ Lorsque le réseau est stable, les nouvelles informations d'enregistrement de l'instance actuelle seront synchronisées avec les autres nœuds.
Par conséquent, Eureka peut bien faire face à la situation où certains nœuds perdent le contact en raison d'une panne de réseau et ne paralysera pas l'ensemble du microservice comme Zookeeper
7. Quelle est la différence entre SpringBoot et SpringCloud ?
SpringBoot se concentre sur le développement rapide et facile de microservices individuels.
SpringCloud est un cadre de coordination et de gouvernance de microservices qui se concentre sur la situation globale. Il intègre et gère les microservices individuels développés par SpringBoot.
Fournit la gestion de la configuration, la découverte de services, les disjoncteurs et le routage pour chaque microservice, micro-agent. bus d'événements, verrouillage global, élection de décision, session distribuée et autres services intégrés
SpringBoot peut être utilisé indépendamment sans SpringCloud pour des projets de développement, mais SpringCloud ne peut pas être séparé de SpringBoot et constitue une relation de dépendance.
SpringBoot se concentre sur un développement rapide et pratique. microservices individuels, SpringCloud se concentre sur le cadre de gouvernance globale des services.
8. Quelle est la signification de l'équilibrage de charge ?
En informatique, l'équilibrage de charge améliore la répartition de la charge de travail sur plusieurs ressources informatiques telles que les ordinateurs, les clusters d'ordinateurs, les liaisons réseau, les unités centrales de traitement ou les lecteurs de disque. L'équilibrage de charge vise à optimiser l'utilisation des ressources, à maximiser le débit, à minimiser le temps de réponse et à éviter de surcharger une ressource unique. L'utilisation de plusieurs composants pour l'équilibrage de charge plutôt que d'un seul composant peut améliorer la fiabilité et la disponibilité grâce à la redondance. L'équilibrage de charge implique généralement des logiciels ou du matériel spécialisés, tels que des commutateurs multicouches ou des processus de serveur Domain Name System.
9. Qu'est-ce qu'Hystrix ? Comment atteint-il la tolérance aux pannes ?
Hystrix est une bibliothèque de latence et de tolérance aux pannes conçue pour isoler les points d'accès aux systèmes distants, aux services et aux bibliothèques tierces, arrêter les pannes en cascade lorsque les pannes sont inévitables et mettre en œuvre l'élasticité des systèmes distribués complexes.
Habituellement, pour les systèmes développés à l'aide d'une architecture de microservices, de nombreux microservices sont impliqués. Ces microservices collaborent les uns avec les autres.
Pensez aux microservices suivants
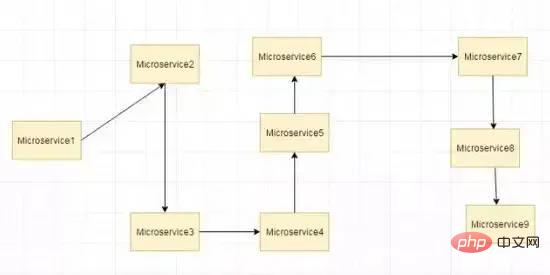
Supposons que si le microservice 9 dans l'image ci-dessus échoue, alors en utilisant les méthodes traditionnelles, nous propagerons une exception. Mais cela entraînera quand même le crash de l’ensemble du système.
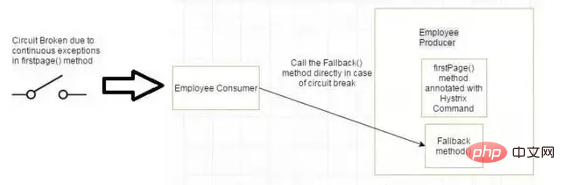
À mesure que le nombre de microservices augmente, ce problème devient plus complexe. Le nombre de microservices peut atteindre 1 000. C'est là qu'hystrix entre en jeu. Nous utiliserons la fonctionnalité Méthode de repli d'Hystrix dans ce cas. Nous avons deux services employé-consommateur qui utilisent les services exposés par employé-consommateur.
Le schéma simplifié est présenté ci-dessous

Supposons maintenant que pour une raison quelconque, le service exposé par l'employé-producteur lève une exception. Nous avons défini une méthode de repli utilisant Hystrix dans ce cas. Cette méthode de secours doit avoir le même type de retour que le service public. Si une exception se produit dans le service exposé, la méthode de secours renverra une valeur.
10. Qu'est-ce que le disjoncteur Hystrix ? En avons-nous besoin ?
Pour certaines raisons, la fonction publique salariés-consommateurs fait une exception. En utilisant Hystrix dans ce cas, nous définissons une méthode de repli. Si une exception se produit dans le service exposé, la méthode de secours renvoie une valeur par défaut.
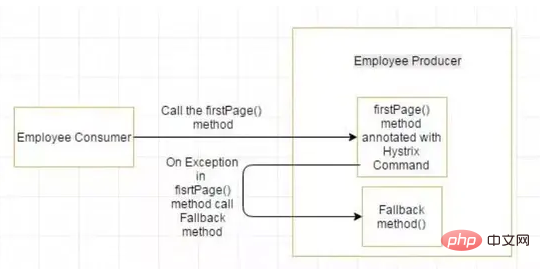
Si l'exception dans la méthode firstPage() continue de se produire, le circuit Hystrix se brisera et l'employé consommateur ignorera complètement la méthode firstPage et appellera directement la méthode de secours. L'objectif du disjoncteur est de laisser du temps à la méthode de première page ou à d'autres méthodes que la méthode de première page peut appeler et provoquer une récupération d'exception. Ce qui peut se produire, c'est que sous une charge plus légère, le problème à l'origine de l'exception a de meilleures chances de récupération.
11. Parlons du principe de mise en œuvre de RPC
Tout d'abord, il existe un module qui gère la communication de connexion réseau, qui est responsable de l'établissement, de la gestion et du message de la connexion transmission. Deuxièmement, un module de codage et de décodage est nécessaire, car les communications réseau sont toutes des bytecodes transmis et les objets que nous utilisons doivent être sérialisés et désérialisés. Le reste est constitué des parties client et serveur. Le serveur expose l'interface de service à ouvrir. Le client appelle une implémentation proxy de l'interface de service. Cette implémentation proxy est chargée de collecter les données, de les coder et de les transmettre au serveur, puis d'attendre. les résultats à restituer.
12. Quel est le mécanisme d'autoprotection d'Eureka ?
Lorsque le nœud du serveur Eureka perd les connexions à trop d'instances en peu de temps (comme une panne de réseau ou des démarrages et arrêts fréquents de clients) le nœud entrera en mode d'autoprotection, protégera les informations d'enregistrement, ne supprimera plus les données d'enregistrement et quittera automatiquement le mode d'autoprotection lorsque la récupération après panne se produit.
13. Qu'est-ce que le ruban ?
ribbon est un client d'équilibrage de charge qui peut bien contrôler certains comportements de http et tcp. feign intègre le ruban par défaut. feign默认集成了ribbon。
14,什么是 Netflix Feign?它的优点是什么?
Feign 是受到 Retrofit,JAXRS-2.0 和 WebSocket 启发的 java 客户端联编程序。
Feign 的第一个目标是将约束分母的复杂性统一到 http apis,而不考虑其稳定性。
特点:
Feign 采用的是基于接口的注解 Feign 整合了ribbon,具有负载均衡的能力 整合了Hystrix,具有熔断的能力
使用方式
添加pom依赖。 启动类添加 @EnableFeignClients定义一个接口 @FeignClient(name=“xxx”)
Le premier objectif de Feign est d'unifier la complexité des dénominateurs de contraintes en API http, quelle que soit leur stabilité. Caractéristiques : 🎜
-
Feign utilise des annotations basées sur l'interface🎜🎜 Feign intègre un ruban et possède des capacités d'équilibrage de charge🎜🎜 Hystrix intégré et a la capacité de fusionner🎜🎜🎜🎜Utiliser la méthode 🎜 Ajouter une dépendance pom. 🎜🎜 Ajout d'une classe de démarrage @EnableFeignClients🎜🎜Définir une interface @FeignClient(name="xxx")Spécifiez quel service appeler 🎜🎜🎜🎜🎜🎜15. Quelle est la différence entre Ribbon et Feindre ? 🎜🎜🎜🎜1. Ribbon appelle d'autres services, mais de différentes manières. 2. Les annotations de la classe de démarrage sont différentes. Ribbon est @RibbonClient et feign est @EnableFeignClients. 3. L'emplacement spécifié du service est différent. Ribbon est déclaré sur l'annotation @RibbonClient, tandis que Feign est déclaré à l'aide de @FeignClient dans l'interface qui définit la méthode abstraite. 4. Les méthodes d'appel sont différentes. Ribbon doit construire lui-même la requête http et simuler la requête http. 🎜16. Quels sont les composants principaux de Spring Cloud ?
Eureka : Service enregistré auprès de Discovery. Feign : sur la base du mécanisme de proxy dynamique, en fonction de l'annotation et de la machine sélectionnée, l'adresse URL de la demande est épissée et la demande est lancée. Ruban : implémentez l'équilibrage de charge et sélectionnez-en une parmi plusieurs machines pour un service. Hystrix : fournit un pool de threads. Différents services utilisent différents pools de threads, ce qui réalise l'isolation des différents appels de service et évite le problème de l'avalanche de services. Zuul : Gestion de passerelle, la passerelle Zuul transmet les requêtes aux services correspondants.
17. Parlons de la relation entre Spring Boot et Spring Cloud
Spring Boot est une solution basée sur Maven lancée par Spring pour résoudre le problème des fichiers de configuration de framework traditionnels redondants et des composants d'assemblage compliqués, visant pour créer rapidement un microservice unique Spring Cloud se concentre sur la résolution de la coordination et de la configuration entre divers microservices, de la communication entre les services, du disjoncteur, de l'équilibrage de charge, etc. Les dimensions techniques ne sont pas les mêmes et Spring Cloud dépend de Spring Boot, mais Spring Boot ne dépend pas de Spring Cloud et peut même effectuer un excellent développement intégré avec Dubbo
Summary
SpringBoot se concentre sur le développement rapide et pratique de un seul microservices individuel SpringCloud est un cadre de coordination et de gouvernance de microservices qui se concentre sur la situation globale, intègre et gère divers microservices et assure l'intégration entre chaque microservice tel que la gestion de la configuration, la découverte de services, les disjoncteurs, le routage, les bus d'événements , etc. Service Spring Boot ne dépend pas de Spring Cloud Spring Cloud dépend de Spring Boot, qui est une relation de dépendance Spring Boot se concentre sur le développement rapide et pratique de microservices individuels, et Spring Cloud se concentre. sur le cadre mondial de gouvernance des services
18. Comment les microservices communiquent-ils de manière indépendante ?
Invocation de procédure à distance (Invocation de procédure à distance)
est ce que nous appelons souvent l'enregistrement et la découverte de services. Vous pouvez accéder à d'autres services directement via des appels de procédure à distance.
Avantages : Simple et courant, car il n'y a pas de proxy middleware, le système est plus simple
Inconvénients : Il ne prend en charge que le mode demande/réponse et ne prend pas en charge les autres, tels que la notification, la demande/réponse asynchrone, publication/abonnement, les réponses de publication/asynchrone réduisent la disponibilité car le client et le serveur doivent être disponibles pendant la demande.
Messages
Utilisez des messages asynchrones pour la communication interservices. Les services communiquent en échangeant des messages via des canaux de messages.
Avantages : Découplez le client et le serveur, un couplage plus lâche et améliorez la convivialité, car le middleware de message met en cache le message jusqu'à ce que le consommateur puisse le consommer et prend en charge de nombreux mécanismes de communication tels que les notifications, les demandes/réponses asynchrones, les versions/abonnement. , publication/réponse asynchrone.
Inconvénients : Le middleware de messages présente une complexité supplémentaire.
19. Comment Spring Cloud implémente-t-il l'enregistrement du service ?
Lorsque le service est publié, spécifiez le nom du service correspondant et enregistrez le service auprès du centre d'enregistrement (
Eureka, Zookeeper).Eureka 、Zookeeper)。注册中心加
Centre d'enregistrement plus@EnableEurekaServer,服务用@EnableDiscoveryClient@EnableEurekaServer, service Utilisez@EnableDiscoveryClient, puis utilisez le ruban ou feignez Effectuez une découverte directe des appels de service. Cette question est plus pratique. Cela dépend si vous avez mémorisé les questions de l'entretien. Les personnes qui ne l'ont pas pratiquée ne le sauront pas.
Dans un système distribué complexe, les appels mutuels entre microservices peuvent provoquer un blocage de service pour diverses raisons. Dans les scénarios de concurrence élevée, le blocage de service signifie le blocage de threads, ce qui entraîne l'indisponibilité du thread actuel et le blocage de tous les threads du serveur, ce qui entraîne le serveur plante. Étant donné que la relation d'appel entre les services est synchrone, cela provoquera une avalanche de services pour l'ensemble du système de microserviceAfin de résoudre le problème selon lequel le temps de réponse à l'appel d'un certain microservice est trop long ou si le système devient trop long. indisponible et consomme de plus en plus de ressources système, provoquant un effet d'avalanche, une interruption et une dégradation du service sont nécessaires. Le soi-disant disjoncteur de service fait référence à une certaine panne ou anomalie de service, qui est similaire au « fusible » dans le monde de l'affichage. Lorsqu'une condition anormale est déclenchée, l'ensemble du service est directement grillé, au lieu d'attendre le déclenchement. le service expire. Le fusible de service est équivalent au fusible de notre interrupteur électrique. Une fois qu'une avalanche de service se produit, l'ensemble du service sera fusible. En maintenant son propre pool de threads, lorsque le thread atteint le seuil, une dégradation du service sera initiée. les autres requêtes continuent d'accéder, ce sera directement Renvoyer la valeur par défaut de fallback🎜21. Comprenez-vous le mécanisme d’autoprotection d’Eureka ?
Lorsque le nœud du serveur Eureka perd les connexions à trop d'instances dans un court laps de temps (comme une panne de réseau ou des démarrages et arrêts fréquents de clients), le nœud entrera en mode d'autoprotection pour protéger les informations d'enregistrement et ne sera plus supprimé. les données d'enregistrement et la récupération après les échecs quittent automatiquement le mode d'autoprotection.
22. Connaissez-vous Spring Cloud Bus ?
spring cloud bus connecte des nœuds distribués avec un courtier de messages léger. Il peut être utilisé pour diffuser des modifications de fichiers de configuration ou pour une communication directe de service. surveillance. Si le fichier de configuration est modifié et qu'une requête est envoyée, tous les clients relisent le fichier de configuration.
23. Quelle est la fonction du disjoncteur Spring Cloud ?
Lorsqu'un service appelle un autre service et qu'il y a un problème dû à des raisons de réseau ou à ses propres raisons, l'appelant attendra la réponse de l'appelé. plus de services La demande de ces ressources entraîne davantage d'attente de requêtes, provoquant un effet de chaîne (effet d'avalanche). S'il ne peut pas être appelé un certain nombre de fois au cours d'une période donnée et qu'il n'y a aucun signe de récupération après plusieurs surveillances, alors le disjoncteur est complètement ouvert et le service ne sera pas demandé la prochaine fois.
Demi-ouverture : il y a des signes de rétablissement dans un court laps de temps. Le disjoncteur enverra des demandes au service. Lorsqu'il est appelé normalement, le disjoncteur est fermé. Fermé : lorsque le service est toujours dans un état normal et peut être appelé normalement.
24. Connaissez-vous Spring Cloud Config ?
Dans un système distribué, en raison du grand nombre de services, afin de faciliter la gestion unifiée et la mise à jour en temps réel des fichiers de configuration des services, un centre de configuration distribué composant est nécessaire. Dans Spring Cloud, il existe un composant de centre de configuration distribué
Spring Cloud Config, qui prend en charge le placement du service de configuration dans la mémoire du service de configuration (c'est-à-dire local), et prend également en charge le placement dans le référentiel Git distant.Spring Cloud Config,它支持配置服务放在配置服务的内存中(即本地),也支持放在远程Git仓库中。在
DansSpring Cloud ConfigSpring Cloud Configcomposant, Là Il y a deux rôles, l'un est le serveur de configuration et l'autre est le client de configuration. Comment utiliser : 🎜Add Pom Dependency add Configuration pertinente dans le fichier de configuration add annotation @enableConfigServer vers la classe de démarrage
25. Cloud Gateway est le framework de passerelle de deuxième génération officiellement lancé par Spring Cloud qui remplace la passerelle Zuul. En tant que contrôleur de trafic, les passerelles jouent un rôle très important dans les systèmes de microservices. Les fonctions courantes des passerelles incluent le routage et le transfert, la vérification des autorisations et le contrôle de limitation de courant. Un bean RouteLocatorBuilder est utilisé pour créer des routes, en plus de créer des routes, RouteLocatorBuilder vous permet d'ajouter divers prédicats et filtres. La signification des assertions de prédicats, comme son nom l'indique, doit être traitée par des routes spécifiques selon des règles de requête spécifiques. Les filtres sont chacun un filtre utilisé pour effectuer divers jugements et modifications des demandes.
Référence ; http://1pgqu.cn/M0NZo
RésuméSpring Cloud est actuellement très populaire, et c'est presque l'une des compétences nécessaires pour les développeurs Java. Il est normal qu’on pose cette question lors de l’entretien. De nombreuses personnes l’utilisent depuis longtemps mais échouent à l’entretien sans en comprendre les principes. La mémorisation des questions du test reste très utile à un large niveau. Mais dans une perspective à long terme, j’espère que tout le monde apprendra et pratiquera à un niveau plus profond. Ce n'est que lorsque vous le maîtriserez vraiment que vous pourrez l'appeler NB.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Retour sur l'interview Série de 25 plans de Spring Cloud
Aug 24, 2023 pm 03:57 PM
Retour sur l'interview Série de 25 plans de Spring Cloud
Aug 24, 2023 pm 03:57 PM
Spring Cloud est actuellement très populaire et constitue presque l'une des compétences nécessaires pour les développeurs Java. Il est normal qu’on pose cette question lors de l’entretien. De nombreuses personnes l’utilisent depuis longtemps mais échouent à l’entretien sans en comprendre les principes.
 Guide de comparaison et de sélection : comparaison des fonctions de Spring Cloud et Spring Boot
Dec 29, 2023 pm 06:36 PM
Guide de comparaison et de sélection : comparaison des fonctions de Spring Cloud et Spring Boot
Dec 29, 2023 pm 06:36 PM
SpringCloud et SpringBoot sont actuellement les frameworks open source les plus populaires dans le domaine Java. Ils fournissent respectivement un ensemble complet d'architectures de microservices et de solutions pour créer rapidement des applications. Cet article comparera leurs fonctions et donnera un guide de sélection pour aider les lecteurs à comprendre leurs avantages et les scénarios applicables. SpringBoot est un framework de développement d'applications Java. Il fournit un processus de développement simplifié et intègre un grand nombre de fonctions et de composants couramment utilisés, réduisant ainsi la charge de travail du développeur.
 Analyse de l'instance de test d'utilisation SpringCloud-Spring Boot Starter
May 16, 2023 am 11:10 AM
Analyse de l'instance de test d'utilisation SpringCloud-Spring Boot Starter
May 16, 2023 am 11:10 AM
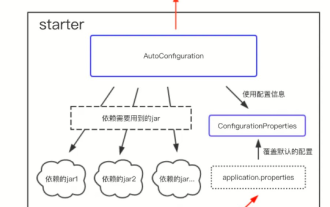
Qu’est-ce que SpringBootStarter ? SpringBootStarter est un concept proposé dans le composant SpringBoot, qui simplifie de nombreuses configurations lourdes. En introduisant divers packages SpringBootStarter, vous pouvez rapidement créer l'échafaudage d'un projet. Par exemple, certains de ceux que nous utilisons souvent : spring-boot-starter-web : spring-boot-starter-data-redis : spring-boot-starter-data-mongodb : spring-boot-starter-data-jpa : spring -b
 Quels sont les cinq composants principaux de springcloud
Jun 12, 2023 pm 03:51 PM
Quels sont les cinq composants principaux de springcloud
Jun 12, 2023 pm 03:51 PM
Les cinq composants principaux de springcloud sont : 1. Eureka, qui implémente la gouvernance des services ; 2. Ribbon, qui fournit des algorithmes d'équilibrage de charge logiciel côté client ; 3. Disjoncteur Hystrix, qui empêche une application d'essayer d'effectuer une opération plusieurs fois ; 4. Zuul, qui dispose d'une passerelle API, de routage, d'équilibrage de charge et d'autres fonctions ; 5. Config, pour la gestion de la configuration ;
 Comparaison et analyse des méthodes d'application de SpringCloud et SpringBoot dans le domaine des microservices
Dec 29, 2023 pm 03:45 PM
Comparaison et analyse des méthodes d'application de SpringCloud et SpringBoot dans le domaine des microservices
Dec 29, 2023 pm 03:45 PM
Ces dernières années, avec l’essor du cloud computing et de l’architecture distribuée, l’application de l’architecture de microservices est devenue de plus en plus répandue. En tant que frameworks importants dans le développement Java, Spring Cloud et Spring Boot jouent un rôle important dans la mise en œuvre des microservices. Cependant, de nombreuses personnes ont encore quelques doutes sur leurs différentes méthodes d’application dans le domaine des microservices. Cet article explorera l'application de Spring Cloud et Spring Boot dans les microservices sous différents angles. Tout d’abord, découvrons Spri
 Idée Quelles sont les méthodes courantes de chargement et de débogage à chaud de Springboot SpringCloud ?
May 18, 2023 pm 05:43 PM
Idée Quelles sont les méthodes courantes de chargement et de débogage à chaud de Springboot SpringCloud ?
May 18, 2023 pm 05:43 PM
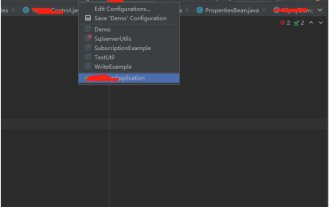
Description du scénario Pendant le processus de développement du projet, lorsque vous devez modifier et déboguer, vous devez souvent redémarrer le projet à chaque fois, ce qui fait perdre du temps. Voici deux méthodes couramment utilisées que j'ai compilées. La première consiste à modifier la méthode de configuration de démarrage. (principalement pour le mode débogage). Cliquez sur Configuration de démarrage = 》 modifier les configurations... Modifier les classes de mise à jour et l'action de mise à jour sous la configuration : mettre à jour les touches de raccourci lorsque l'utilisateur effectue activement des mises à jour : Ctrl+F9 sur la désactivation du cadre : lorsque la fenêtre d'édition perd le focus.
 La différence entre SpringCloud et SpringBoot d'un point de vue architectural
Dec 29, 2023 pm 04:13 PM
La différence entre SpringCloud et SpringBoot d'un point de vue architectural
Dec 29, 2023 pm 04:13 PM
La différence entre Spring Cloud et Spring Boot d'un point de vue architectural Introduction : À l'ère d'Internet d'aujourd'hui, la création d'un système distribué est devenue une exigence nécessaire. SpringBoot et SpringCloud sont nés pour répondre à ce besoin. Bien qu'il s'agisse de deux solutions fournies par le framework Spring, il existe des différences importantes d'un point de vue architectural. Cet article commencera d'un point de vue architectural et analysera SpringBoot et SpringCl.
 Quelle est la différence entre springcloud et springboot
Dec 28, 2023 pm 03:34 PM
Quelle est la différence entre springcloud et springboot
Dec 28, 2023 pm 03:34 PM
La différence entre springcloud et springboot : 1. Fonction ; 2. Utilisation ; 3. Objectif initial ; 5. Intégration ; 7. Complexité ; et l'exploitation et l'entretien. Introduction détaillée : 1. Fonction. La fonction principale de Spring Boot est de fournir un moyen rapide de développement de microservices, de simplifier les fichiers de configuration et d'améliorer l'efficacité du travail. Spring Cloud est un cadre de gestion complet utilisé pour fournir un cadre de gestion complet pour la gestion des microservices. cadre, etc
