
 Périphériques technologiques
IA
Entraînement avec 7 500 données de trajectoire, CMU et Meta permettent au robot d'atteindre le niveau de salon et de cuisine polyvalents
Périphériques technologiques
IA
Entraînement avec 7 500 données de trajectoire, CMU et Meta permettent au robot d'atteindre le niveau de salon et de cuisine polyvalents
Entraînement avec 7 500 données de trajectoire, CMU et Meta permettent au robot d'atteindre le niveau de salon et de cuisine polyvalents

En s'entraînant simplement à l'aide de 7 500 données de trajectoire, ce robot peut démontrer 12 compétences opérationnelles différentes dans 38 tâches, non seulement limitées au prélèvement et à la poussée, mais incluant également la manipulation conjointe d'objets et le repositionnement d'objets. De plus, ces compétences peuvent être appliquées à des centaines de situations inconnues différentes, notamment des objets inconnus, des tâches inconnues et même des environnements de cuisine complètement inconnus. Ce genre de robot est vraiment cool !

Créer un robot capable de manipuler des objets arbitraires dans divers environnements est un objectif insaisissable depuis des décennies. L'une des raisons est le manque d'ensembles de données robotiques diversifiés pour former de tels agents, ainsi que le manque d'agents polyvalents capables de générer de tels ensembles de données
Pour surmonter ce problème, des chercheurs de l'Université Carnegie Mellon et Meta L'auteur de AI a passé deux ans à développer un RoboAgent universel. Leur objectif principal est de développer un paradigme efficace capable de former un agent général capable de compétences multiples avec des données limitées, et de généraliser ces compétences à diverses situations inconnues

RoboAgent Composé de manière modulaire de :
- RoboPen - une infrastructure robotique distribuée construite avec du matériel à usage général capable de fonctionner sans interruption à long terme
- RoboHive - un cadre unifié pour fonctionner dans des simulations et l'apprentissage de robots du monde réel dans
- RoboSet - un haut- ensemble de données de qualité représentant plusieurs compétences utilisant des objets du quotidien dans divers scénarios ;
- MT-ACT - une imitation hors ligne multitâche efficace conditionnée par le langage Le cadre d'apprentissage étend l'ensemble de données hors ligne en créant divers ensembles sémantiquement améliorés basés sur l'expérience robot existante, et adopte une nouvelle architecture politique et une méthode de représentation d'action efficace pour récupérer avec un budget de données limité. Une stratégie qui fonctionne bien.
RoboSet : ensemble de données multi-compétences, multi-tâches et multimodales
Pour construire un agent robot qui peut être généralisé dans de nombreuses situations différentes, vous avez d'abord besoin d'un ensemble de données avec une large couverture. Étant donné que les efforts de mise à l'échelle sont souvent utiles (par exemple, RT-1 a démontré des résultats sur environ 130 000 trajectoires de robots), il est nécessaire de comprendre les principes d'efficacité et de généralisation des systèmes d'apprentissage dans le contexte d'ensembles de données limités, souvent de faible niveau de données. situations. Conduira à un surapprentissage. Par conséquent, l’objectif principal des auteurs est de développer un paradigme puissant capable d’apprendre des stratégies générales généralisables dans des situations de faibles données tout en évitant les problèmes de surapprentissage.
Le panorama des compétences et des données dans l'apprentissage des robots est un domaine important. Dans l’apprentissage robotique, les compétences font référence aux capacités qu’un robot acquiert grâce à l’apprentissage et à la formation et qui peuvent être utilisées pour effectuer des tâches spécifiques. Le développement de ces compétences ne peut être dissocié du support de grandes quantités de données. Les données constituent la base de l’apprentissage des robots. En analysant et en traitant les données, les robots peuvent en tirer des leçons et améliorer leurs compétences. Les compétences et les données sont donc deux aspects indispensables de l’apprentissage des robots. Ce n'est qu'en apprenant et en acquérant continuellement de nouvelles données que les robots pourront continuer à améliorer leurs niveaux de compétences et faire preuve d'une intelligence et d'une efficacité supérieures dans diverses tâches
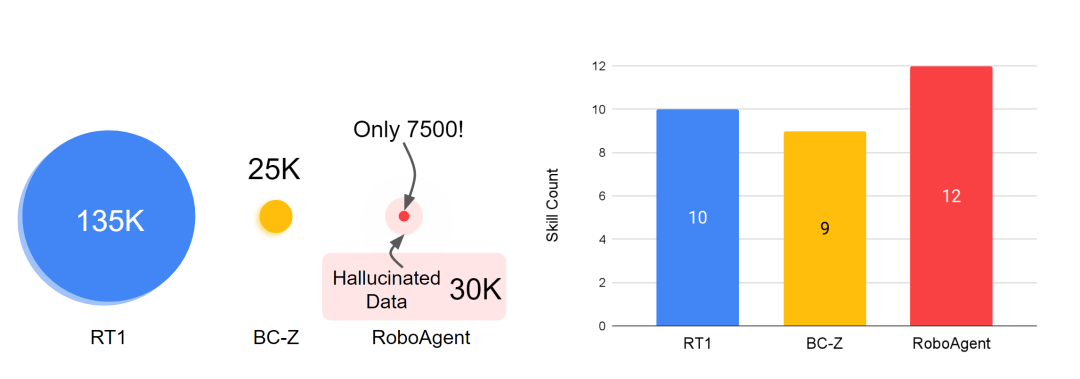
L'ensemble de données utilisé pour entraîner RoboAgent, RoboSet (MT-ACT), ne comprend que 7 500 trajectoires (18 fois moins que les données de RT-1). Cet ensemble de données est collecté au préalable et reste figé. L'ensemble de données se compose de trajectoires de haute qualité collectées lors de téléopérations humaines à l'aide de matériel robotique standard (robot Franka-Emika équipé de la pince Robotiq) pour plusieurs tâches et scénarios. RoboSet (MT-ACT) couvre peu 12 compétences uniques dans plusieurs contextes différents. Les données ont été collectées en divisant les activités quotidiennes de cuisine (par exemple préparer le thé, cuisiner) en différentes sous-tâches, chacune représentant une compétence unique. L'ensemble de données comprend des compétences communes de sélection et de placement, mais également des compétences riches en contacts telles que l'essuyage, l'operculage et des compétences impliquant des objets articulés. Contenu réécrit : L'ensemble de données utilisé pour entraîner RoboAgent, RoboSet (MT-ACT), ne comprend que 7 500 trajectoires (18 fois moins que les données de RT-1). Cet ensemble de données est collecté au préalable et reste figé. L'ensemble de données se compose de trajectoires de haute qualité collectées lors de téléopérations humaines à l'aide de matériel robotique standard (robot Franka-Emika équipé de la pince Robotiq) pour plusieurs tâches et scénarios. RoboSet (MT-ACT) couvre peu 12 compétences uniques dans plusieurs contextes différents. Les données ont été collectées en divisant les activités quotidiennes de cuisine (par exemple préparer le thé, cuisiner) en différentes sous-tâches, chacune représentant une compétence unique. L'ensemble de données comprend des compétences communes de sélection et de placement, mais également des compétences riches en contacts telles que l'essuyage, le bouchage et des compétences impliquant des objets articulés. apprend des stratégies générales dans des situations de faibles données sur la base de deux informations clés. Il utilise la connaissance préalable du modèle de base pour éviter l'effondrement des modes et adopte une représentation stratégique nouvelle et efficace pour pouvoir ingérer des données hautement multimodales
 Le contenu qui doit être réécrit est : 1. Amélioration sémantique : RoboAgent En améliorant sémantiquement RoboSet (MT-ACT), une connaissance préalable du monde à partir du modèle de base existant y est injectée. L'ensemble de données résultant combine l'expérience du robot avec une connaissance préalable du monde sans coûts humains/robot supplémentaires. Utilisez SAM pour segmenter les objets cibles et les améliorer sémantiquement en termes de changements de forme, de couleur et de texture.
Contenu réécrit : 1. Amélioration sémantique : RoboAgent injecte les connaissances mondiales antérieures du modèle de base existant dans RoboSet (MT-ACT) en l'améliorant sémantiquement. De cette manière, l'expérience du robot et sa connaissance préalable du monde peuvent être combinées sans coûts humains/robot supplémentaires. Utilisez SAM pour segmenter les objets cibles et effectuer une amélioration sémantique en termes de changements de forme, de couleur et de texture
Le contenu qui doit être réécrit est : 1. Amélioration sémantique : RoboAgent En améliorant sémantiquement RoboSet (MT-ACT), une connaissance préalable du monde à partir du modèle de base existant y est injectée. L'ensemble de données résultant combine l'expérience du robot avec une connaissance préalable du monde sans coûts humains/robot supplémentaires. Utilisez SAM pour segmenter les objets cibles et les améliorer sémantiquement en termes de changements de forme, de couleur et de texture.
Contenu réécrit : 1. Amélioration sémantique : RoboAgent injecte les connaissances mondiales antérieures du modèle de base existant dans RoboSet (MT-ACT) en l'améliorant sémantiquement. De cette manière, l'expérience du robot et sa connaissance préalable du monde peuvent être combinées sans coûts humains/robot supplémentaires. Utilisez SAM pour segmenter les objets cibles et effectuer une amélioration sémantique en termes de changements de forme, de couleur et de texture
2. Représentation efficace des politiques : l'ensemble de données résultant est extrêmement multimodal et contient une grande variété de compétences, de tâches et de scénarios. . Nous appliquons la méthode de segmentation des actions à un environnement multitâche et développons une représentation politique nouvelle et efficace – MT-ACT – capable d'acquérir des ensembles de données hautement multimodaux avec de petites quantités de données tout en évitant le problème
. Résultats expérimentaux
L'efficacité des échantillons de RoboAgent est supérieure à celle des méthodes existantes

La figure ci-dessous compare la représentation politique MT-ACT proposée par l'auteur avec plusieurs architectures d'apprentissage par imitation . L'auteur utilise uniquement les changements d'environnement, y compris les changements de pose d'objet et les changements d'éclairage partiel. Semblable aux études précédentes, les auteurs attribuent cela à la généralisation L1. Il ressort clairement des résultats de RoboAgent que l'utilisation du découpage d'actions pour modéliser des sous-trajectoires surpasse considérablement toutes les méthodes de base, prouvant ainsi l'efficacité de la représentation politique proposée par l'auteur dans un apprentissage efficace par échantillon
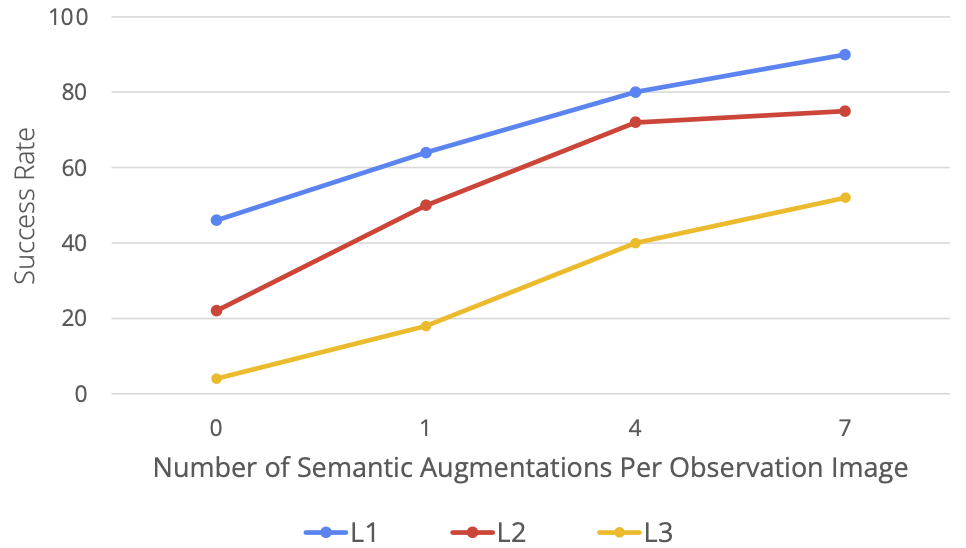
RoboAgent excelle à plusieurs niveaux d'abstraction
La figure suivante montre les résultats des méthodes de test de l'auteur à différents niveaux de généralisation. Dans le même temps, le niveau de généralisation est également démontré par la visualisation, où L1 représente les changements de pose des objets, L2 représente divers arrière-plans de bureau et facteurs de distraction, et L3 représente de nouvelles combinaisons compétence-objet. Ensuite, les auteurs montrent comment chaque méthode fonctionne à ces niveaux de généralisation. Dans des études d'évaluation rigoureuses, MT-ACT a obtenu des résultats nettement meilleurs que les autres méthodes, en particulier au niveau de généralisation plus difficile (L3). d'amélioration sémantique dans une activité de 5 compétences. Comme le montre la figure ci-dessous, à mesure que les données augmentent (c'est-à-dire que le nombre d'améliorations par image augmente), les performances s'améliorent considérablement à tous les niveaux de généralisation. Il est particulièrement intéressant de noter que dans la tâche la plus difficile (généralisation L3), l'amélioration des performances est plus évidente

RoboAgent est capable de démontrer ses compétences dans une variété d'activités différentes

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 Comment l'IA peut-elle rendre les robots plus autonomes et adaptables ?
Jun 03, 2024 pm 07:18 PM
Comment l'IA peut-elle rendre les robots plus autonomes et adaptables ?
Jun 03, 2024 pm 07:18 PM
Dans le domaine de la technologie de l’automatisation industrielle, il existe deux points chauds récents qu’il est difficile d’ignorer : l’intelligence artificielle (IA) et Nvidia. Ne changez pas le sens du contenu original, affinez le contenu, réécrivez le contenu, ne continuez pas : « Non seulement cela, les deux sont étroitement liés, car Nvidia ne se limite pas à son unité de traitement graphique d'origine (GPU ), il étend son GPU. La technologie s'étend au domaine des jumeaux numériques et est étroitement liée aux technologies émergentes d'IA "Récemment, NVIDIA a conclu une coopération avec de nombreuses entreprises industrielles, notamment des sociétés d'automatisation industrielle de premier plan telles qu'Aveva, Rockwell Automation, Siemens. et Schneider Electric, ainsi que Teradyne Robotics et ses sociétés MiR et Universal Robots. Récemment, Nvidiahascoll
 Après 2 mois, le robot humanoïde Walker S peut plier les vêtements
Apr 03, 2024 am 08:01 AM
Après 2 mois, le robot humanoïde Walker S peut plier les vêtements
Apr 03, 2024 am 08:01 AM
Rédacteur en chef du Machine Power Report : Wu Xin La version domestique de l'équipe robot humanoïde + grand modèle a accompli pour la première fois la tâche d'exploitation de matériaux flexibles complexes tels que le pliage de vêtements. Avec le dévoilement de Figure01, qui intègre le grand modèle multimodal d'OpenAI, les progrès connexes des pairs nationaux ont attiré l'attention. Hier encore, UBTECH, le « stock numéro un de robots humanoïdes » en Chine, a publié la première démo du robot humanoïde WalkerS, profondément intégré au grand modèle de Baidu Wenxin, présentant de nouvelles fonctionnalités intéressantes. Maintenant, WalkerS, bénéficiant des capacités de grands modèles de Baidu Wenxin, ressemble à ceci. Comme la figure 01, WalkerS ne se déplace pas, mais se tient derrière un bureau pour accomplir une série de tâches. Il peut suivre les commandes humaines et plier les vêtements
 Le premier robot capable d'accomplir de manière autonome des tâches humaines apparaît, avec cinq doigts flexibles et rapides, et de grands modèles prennent en charge l'entraînement dans l'espace virtuel
Mar 11, 2024 pm 12:10 PM
Le premier robot capable d'accomplir de manière autonome des tâches humaines apparaît, avec cinq doigts flexibles et rapides, et de grands modèles prennent en charge l'entraînement dans l'espace virtuel
Mar 11, 2024 pm 12:10 PM
Cette semaine, FigureAI, une entreprise de robotique investie par OpenAI, Microsoft, Bezos et Nvidia, a annoncé avoir reçu près de 700 millions de dollars de financement et prévoit de développer un robot humanoïde capable de marcher de manière autonome au cours de la prochaine année. Et l’Optimus Prime de Tesla a reçu à plusieurs reprises de bonnes nouvelles. Personne ne doute que cette année sera celle de l’explosion des robots humanoïdes. SanctuaryAI, une entreprise canadienne de robotique, a récemment lancé un nouveau robot humanoïde, Phoenix. Les responsables affirment qu’il peut accomplir de nombreuses tâches de manière autonome, à la même vitesse que les humains. Pheonix, le premier robot au monde capable d'accomplir des tâches de manière autonome à la vitesse d'un humain, peut saisir, déplacer et placer avec élégance chaque objet sur ses côtés gauche et droit. Il peut identifier des objets de manière autonome
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
