
 développement back-end
C++
Comment gérer les problèmes de statistiques de données dans le développement Big Data C++ ?
développement back-end
C++
Comment gérer les problèmes de statistiques de données dans le développement Big Data C++ ?
Comment gérer les problèmes de statistiques de données dans le développement Big Data C++ ?


Comment gérer les problèmes de statistiques de données dans le développement de Big Data C++ ?
Avec l'avènement de l'ère du Big Data, les statistiques de données sont devenues un élément indispensable dans divers domaines. Dans le développement de Big Data C++, nous devons souvent effectuer une analyse statistique sur de grandes quantités de données afin d'obtenir des informations et des insights utiles. Cet article présentera quelques méthodes de gestion des problèmes de statistiques de données dans le développement de Big Data C++ et fournira des exemples de code correspondants.
- Utilisez la bibliothèque STL pour les statistiques de données
La STL (Standard Template Library) de la bibliothèque standard C++ contient diverses classes et fonctions de modèles pour les conteneurs et les algorithmes, qui peuvent faciliter le stockage et le traitement des données. Voici un exemple simple qui montre comment utiliser des conteneurs vectoriels et des fonctions algorithmiques dans la bibliothèque STL pour calculer la somme, la moyenne et le maximum d'un ensemble d'entiers :
#include <iostream>
#include <vector>
#include <algorithm>
#include <numeric>
int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
int sum = std::accumulate(data.begin(), data.end(), 0); // 计算总和
double average = static_cast<double>(sum) / data.size(); // 计算平均值
int max = *std::max_element(data.begin(), data.end()); // 计算最大值
std::cout << "Sum: " << sum << std::endl;
std::cout << "Average: " << average << std::endl;
std::cout << "Max: " << max << std::endl;
return 0;
}- Utilisez des bibliothèques tierces pour des statistiques de données efficaces
Dans En plus de la bibliothèque STL, il existe de nombreuses bibliothèques tierces en C++ qui peuvent être utilisées pour effectuer des statistiques de données plus efficacement. Par exemple, la bibliothèque Boost fournit une multitude de fonctions mathématiques et statistiques permettant d'effectuer facilement divers calculs statistiques. Voici un exemple d'analyse de régression linéaire à l'aide de la bibliothèque Boost :
#include <iostream>
#include <vector>
#include <boost/math/statistics/linear_regression.hpp>
int main() {
std::vector<double> x = {1.0, 2.0, 3.0, 4.0, 5.0};
std::vector<double> y = {2.0, 4.0, 6.0, 8.0, 10.0};
boost::math::statistics::linear_regression<double> reg;
reg.add(x.begin(), x.end(), y.begin(), y.end());
double slope = reg.slope();
double intercept = reg.intercept();
std::cout << "Slope: " << slope << std::endl;
std::cout << "Intercept: " << intercept << std::endl;
return 0;
}- Le calcul parallèle accélère les statistiques de données
Dans le développement de Big Data, la quantité de données est souvent très importante et les calculs monothread peuvent être trop lents. L'utilisation de la technologie informatique parallèle peut améliorer la vitesse des statistiques de données. Il existe des bibliothèques en C++ qui permettent le calcul parallèle, comme OpenMP et TBB. Voici un exemple d'utilisation de la bibliothèque OpenMP pour la sommation parallèle :
#include <iostream>
#include <vector>
#include <omp.h>
int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
int sum = 0;
#pragma omp parallel for reduction(+:sum)
for (int i = 0; i < data.size(); ++i) {
sum += data[i];
}
std::cout << "Sum: " << sum << std::endl;
return 0;
}L'exemple ci-dessus montre comment gérer les problèmes de statistiques de données dans le développement de Big Data C++ en utilisant la bibliothèque STL, des bibliothèques tierces et la technologie de calcul parallèle. Bien sûr, ce n’est que la pointe de l’iceberg. Le C++ possède de nombreuses autres fonctionnalités et outils puissants pour les statistiques de données. J'espère que cet article pourra fournir des références et de l'inspiration aux lecteurs et aider tout le monde à résoudre plus efficacement les problèmes de statistiques de données dans le développement du Big Data C++.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Raisons pour lesquelles les tables sont verrouillées dans Oracle et comment les gérer
Mar 03, 2024 am 09:36 AM
Raisons pour lesquelles les tables sont verrouillées dans Oracle et comment les gérer
Mar 03, 2024 am 09:36 AM
Raisons du verrouillage des tables dans Oracle et comment y remédier Dans la base de données Oracle, le verrouillage des tables est un phénomène courant et il existe de nombreuses raisons pour le verrouillage des tables. Cet article explorera quelques raisons courantes pour lesquelles les tables sont verrouillées et fournira des méthodes de traitement et des exemples de code associés. 1. Types de verrous Dans la base de données Oracle, les verrous sont principalement divisés en verrous partagés (SharedLock) et verrous exclusifs (ExclusiveLock). Les verrous partagés sont utilisés pour les opérations de lecture, permettant à plusieurs sessions de lire la même ressource en même temps.
 Méthodes de traitement JSON et implémentation en C++
Aug 21, 2023 pm 11:58 PM
Méthodes de traitement JSON et implémentation en C++
Aug 21, 2023 pm 11:58 PM
JSON est un format d'échange de données léger, facile à lire et à écrire, ainsi qu'à analyser et à générer par les machines. L'utilisation du format JSON facilite le transfert de données entre différents systèmes. En C++, il existe de nombreuses bibliothèques JSON open source pour le traitement JSON. Cet article présentera certaines méthodes de traitement JSON et implémentations couramment utilisées en C++. Méthodes de traitement JSON en C++ RapidJSON RapidJSON est un analyseur/générateur C++ JSON rapide qui fournit DOM, SAX et
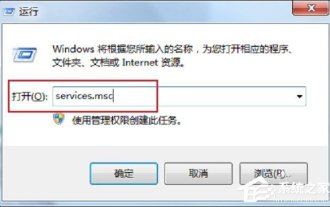 Comment gérer le serveur RPC indisponible dans le système Win7
Jul 19, 2023 pm 04:57 PM
Comment gérer le serveur RPC indisponible dans le système Win7
Jul 19, 2023 pm 04:57 PM
Dans le processus d'utilisation des ordinateurs, nous rencontrons souvent des problèmes, dont certains peuvent submerger les gens. Certains utilisateurs rencontrent ce problème. Lorsqu'ils allument l'ordinateur et utilisent l'imprimante, un message indiquant que le serveur RPC n'est pas disponible apparaît. Ce qui s'est passé? que dois-je faire? En réponse à ce problème, partageons la solution à l'indisponibilité du serveur Win7rpc. 1. Appuyez sur les touches Win+R pour ouvrir Exécuter et entrez services.msc dans la zone de saisie Exécuter. 2. Après avoir entré la liste des services, recherchez le service RemoteProcedureCall(RPC)Locator. 3. Sélectionnez le service et double-cliquez. L'état par défaut est le suivant : 4. Modifiez le type de démarrage du service RPCLoader en automatique.
 Comment gérer les problèmes de tableau hors limites dans le développement C++
Aug 21, 2023 pm 10:04 PM
Comment gérer les problèmes de tableau hors limites dans le développement C++
Aug 21, 2023 pm 10:04 PM
Comment gérer le problème de tableau hors limites dans le développement C++ Dans le développement C++, le tableau hors limites est une erreur courante, qui peut entraîner des plantages de programmes, une corruption de données et même des vulnérabilités de sécurité. Par conséquent, la gestion correcte des problèmes de tableau hors limites est un élément important pour garantir la qualité du programme. Cet article présentera quelques méthodes de traitement courantes et des suggestions pour aider les développeurs à éviter les problèmes de matrice hors limites. Tout d’abord, il est essentiel de comprendre la cause du problème de dépassement des limites du tableau. Un tableau hors limites fait référence à un index qui dépasse sa plage de définition lors de l'accès à un tableau. Cela se produit généralement dans le scénario suivant : Des nombres négatifs sont utilisés lors de l'accès à la baie.
 Comment utiliser les fonctions PHP pour traiter de grandes quantités de données
Jun 16, 2023 am 10:45 AM
Comment utiliser les fonctions PHP pour traiter de grandes quantités de données
Jun 16, 2023 am 10:45 AM
Avec le développement d’Internet, nous sommes quotidiennement exposés à de grandes quantités de données, qui doivent être stockées, traitées et analysées. PHP est un langage de script côté serveur largement utilisé aujourd'hui et également utilisé pour le traitement de données à grande échelle. Lors du traitement de données à grande échelle, il est facile de faire face à un débordement de mémoire et à des goulots d'étranglement en termes de performances. Cet article explique comment utiliser les fonctions PHP pour traiter de grandes quantités de données. 1. Activer la limite de mémoire Par défaut, la taille limite de mémoire de PHP est de 128 Mo, ce qui peut devenir un problème lors du traitement de grandes quantités de données. Pour gérer des plus gros
 Que faire si l'erreur de connexion MySQL 1017 se produit ?
Jun 30, 2023 am 11:57 AM
Que faire si l'erreur de connexion MySQL 1017 se produit ?
Jun 30, 2023 am 11:57 AM
Comment gérer l’erreur de connexion MySQL 1017 ? MySQL est un système de gestion de bases de données relationnelles open source largement utilisé dans le développement de sites Web et le stockage de données. Cependant, lorsque vous utilisez MySQL, vous pouvez rencontrer diverses erreurs. L'une des erreurs courantes est l'erreur de connexion 1017 (code d'erreur MySQL 1017). L'erreur de connexion 1017 indique un échec de connexion à la base de données, généralement provoqué par un nom d'utilisateur ou un mot de passe incorrect. Lorsque MySQL ne parvient pas à s'authentifier à l'aide du nom d'utilisateur et du mot de passe fournis
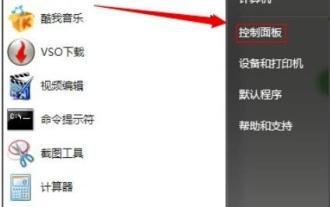 Étapes pour résoudre le problème de l'utilisation élevée de la mémoire dans Win7
Dec 27, 2023 pm 10:27 PM
Étapes pour résoudre le problème de l'utilisation élevée de la mémoire dans Win7
Dec 27, 2023 pm 10:27 PM
L'espace mémoire de l'ordinateur dépend de la fluidité du fonctionnement de l'ordinateur. Au fil du temps, la mémoire deviendra pleine et l'utilisation sera trop élevée, ce qui entraînera un retard de l'ordinateur. Alors, comment résoudre ce problème ? Jetons un coup d'œil aux solutions ci-dessous. Que faire si l'utilisation de la mémoire Win7 est trop élevée : Méthode 1. Désactivez les mises à jour automatiques 1. Cliquez sur "Démarrer" pour ouvrir le "Panneau de configuration" 2. Cliquez sur "Windows Update" 3. Cliquez sur "Modifier les paramètres" à gauche 4. Sélectionnez le Méthode « Ne jamais rechercher les mises à jour » 2. Suppression de logiciels : désinstallez tous les logiciels inutiles. Méthode 3 : fermez les processus et mettez fin à tous les processus inutiles, sinon de nombreuses publicités en arrière-plan rempliront la mémoire. Méthode 4 : Désactiver les services De nombreux services inutiles du système sont également fermés, ce qui garantit non seulement la sécurité mais permet également d'économiser de l'espace.
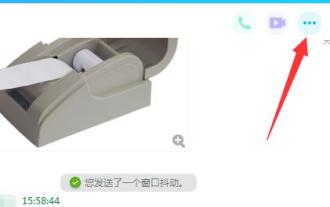 Comment résoudre les problèmes de connexion au bureau à distance QQ
Dec 26, 2023 am 11:55 AM
Comment résoudre les problèmes de connexion au bureau à distance QQ
Dec 26, 2023 am 11:55 AM
QQ est un logiciel de chat produit par Tencent. Presque tout le monde possède un compte QQ et peut se connecter et fonctionner à distance lorsqu'il discute. Cependant, certains utilisateurs rencontrent le problème de ne pas pouvoir se connecter, alors que doivent-ils faire ? Jetons un coup d'oeil ci-dessous. Que faire si QQ Remote Desktop ne parvient pas à se connecter : 1. Ouvrez l'interface de discussion, cliquez sur l'icône "..." dans le coin supérieur droit 2. Sélectionnez l'icône rouge de l'ordinateur et cliquez sur "Paramètres" 3. Cliquez sur "Définir les autorisations—> Bureau à distance" 4. Cochez "Autoriser le Bureau à distance à se connecter à cet ordinateur"
