
 développement back-end
C++
Comment utiliser le C++ pour un traitement du langage naturel haute performance et un dialogue intelligent ?
développement back-end
C++
Comment utiliser le C++ pour un traitement du langage naturel haute performance et un dialogue intelligent ?
Comment utiliser le C++ pour un traitement du langage naturel haute performance et un dialogue intelligent ?


Comment utiliser le C++ pour un traitement du langage naturel performant et un dialogue intelligent ?
Introduction :
Le traitement du langage naturel (NLP) et le dialogue intelligent sont des points chauds de recherche actuels dans le domaine de l'intelligence artificielle et sont largement utilisés dans la traduction automatique, l'analyse de texte, le service client intelligent et d'autres domaines. Cet article explique comment utiliser C++ pour un traitement du langage naturel hautes performances et un dialogue intelligent, et fournit des exemples de code.
1. Analyse lexicale
1. Outil de segmentation de mots
La segmentation du texte est la première étape du traitement du langage naturel, et vous pouvez utiliser l'outil de segmentation de mots open source en C++ pour le traitement. Par exemple, MMSEG peut être utilisé pour segmenter du texte chinois. Voici un exemple de code qui utilise MMSEG pour la segmentation des mots chinois :
#include <mmseg/segmenter.h>
void segmentText(const char* text) {
MMSeg::Segmenter segmenter;
if (segmenter.open(text)) {
MMSeg::Chunk chunk;
while (segmenter.getChunk(chunk)) {
cout << chunk.getLexemeText() << endl; // 输出每个词的结果
}
}
} 2. Marquage d'une partie du discours
Le balisage d'une partie du discours consiste à effectuer une analyse sémantique plus approfondie des résultats de la segmentation des mots afin de fournir des informations plus précises pour les versions ultérieures. traitement. Vous pouvez utiliser des outils open source de marquage de parties de discours chinois tels que ICTCLAS pour le traitement. Voici un exemple de code utilisant ICTCLAS pour le balisage d'une partie du discours :
#include <ICTCLAS50/ICTCLAS50.h>
void posTagging(const char* text) {
ICTCLAS50 ic;
if (ic.ICTCLAS_Init() != 0) {
ic.ICTCLAS_Exit();
return;
}
int len = strlen(text);
const char* result = ic.ICTCLAS_ParagraphProcess(text, len, false);
if (result) {
// 处理标注结果
cout << result << endl;
}
ic.ICTCLAS_Exit();
} 2. Analyse syntaxique
L'analyse syntaxique consiste à analyser la structure de la phrase et à mettre en œuvre une analyse sémantique basée sur les dépendances. Vous pouvez utiliser des outils d'analyse syntaxique open source tels que Harbin Institute of Technology LTP pour le traitement. Voici un exemple de code qui utilise LTP pour l'analyse syntaxique :
#include <ltp/segment_dll.h>
#include <ltp/postag_dll.h>
#include <ltp/parser_dll.h>
void syntacticParsing(const char* text) {
void * segmentor = segmentor_create_segmentor("cws.model");
std::vector<std::string> words;
segmentor_segment(segmentor, text, words);
segmentor_release_segmentor(segmentor);
void * postagger = postagger_create_postagger("pos.model");
std::vector<std::string> tags;
postagger_postag(postagger, words, tags);
postagger_release_postagger(postagger);
void * parser = parser_create_parser("parser.model");
std::vector<int> heads;
std::vector<std::string> deprels;
parser_parse(parser, words, tags, heads, deprels);
parser_release_parser(parser);
for (int i = 0; i < words.size(); ++i) {
cout << words[i] << " " << tags[i] << " " << heads[i] << " " << deprels[i] << endl;
}
} 3. Dialogue intelligent
Le dialogue intelligent est une technologie qui fournit des réponses intelligentes aux questions soulevées par les utilisateurs. Il peut être construit à l’aide de frameworks de robots conversationnels open source tels que ChatBot. Voici un exemple de code pour utiliser ChatBot pour un dialogue intelligent :
#include <ChatBot/ChatBot.h>
void chat(const char* question) {
ChatBot chatbot;
chatbot.loadModel("model.dat"); // 加载预训练模型
std::string answer = chatbot.getResponse(question);
cout << answer << endl;
}Conclusion :
Cet article explique comment utiliser C++ pour un traitement du langage naturel hautes performances et un dialogue intelligent. En utilisant des outils et des frameworks open source, vous pouvez rapidement mettre en œuvre des fonctions d'analyse lexicale, d'analyse syntaxique et de dialogue intelligent. Nous espérons que grâce à l'introduction et à l'exemple de code de cet article, les lecteurs seront en mesure de comprendre la méthode d'utilisation du C++ pour le traitement du langage naturel et le dialogue intelligent, et pourront l'appliquer et l'étendre dans des applications pratiques.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Guide du débutant sur le traitement du langage naturel en PHP
Jun 11, 2023 pm 06:30 PM
Guide du débutant sur le traitement du langage naturel en PHP
Jun 11, 2023 pm 06:30 PM
Avec le développement de la technologie de l’intelligence artificielle, le traitement du langage naturel (NLP) est devenu une technologie très importante. La PNL peut nous aider à mieux comprendre et analyser le langage humain pour réaliser certaines tâches automatisées, telles que le service client intelligent, l'analyse des sentiments, la traduction automatique, etc. Dans cet article, nous aborderons les bases et les outils du traitement du langage naturel à l'aide de PHP. Qu'est-ce que le traitement du langage naturel ? Le traitement du langage naturel est une méthode qui utilise la technologie de l'intelligence artificielle pour traiter
 Technologie et applications de reconnaissance d'entités nommées et d'extraction de relations dans le traitement du langage naturel basé sur Java
Jun 18, 2023 am 09:43 AM
Technologie et applications de reconnaissance d'entités nommées et d'extraction de relations dans le traitement du langage naturel basé sur Java
Jun 18, 2023 am 09:43 AM
Avec l'avènement de l'ère Internet, une grande quantité d'informations textuelles a envahi notre champ de vision, suivie par les besoins croissants des gens en matière de traitement et d'analyse de l'information. Dans le même temps, l’ère d’Internet a également entraîné le développement rapide de la technologie de traitement du langage naturel, permettant aux utilisateurs de mieux obtenir des informations précieuses à partir de textes. Parmi eux, la technologie de reconnaissance d’entités nommées et d’extraction de relations constitue l’une des orientations de recherche importantes dans le domaine des applications de traitement du langage naturel. 1. Technologie de reconnaissance d'entités nommées Les entités nommées font référence à des personnes, des lieux, des organisations, du temps, de la monnaie, des connaissances encyclopédiques, des termes de mesure et des professions.
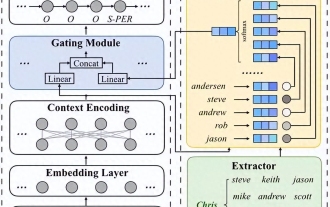 Traitement du langage naturel : permettre aux ordinateurs de comprendre et de traiter le langage humain
Sep 21, 2023 pm 03:53 PM
Traitement du langage naturel : permettre aux ordinateurs de comprendre et de traiter le langage humain
Sep 21, 2023 pm 03:53 PM
Le traitement du langage naturel (NLP) est une technologie importante et passionnante dans le domaine de l'intelligence artificielle. Son objectif est de permettre aux ordinateurs de comprendre, d'analyser et de générer le langage humain. Le développement de la PNL a fait d’énormes progrès, permettant aux ordinateurs de mieux interagir avec les humains et d’atteindre une plus large gamme d’applications. Cet article explorera les concepts, les technologies, les applications et les perspectives d'avenir du traitement du langage naturel. Le concept de traitement du langage naturel est une discipline qui étudie comment permettre aux ordinateurs de comprendre et de traiter le langage humain. La complexité et l’ambiguïté du langage humain confrontent les ordinateurs à d’énormes défis en matière de compréhension et de traitement. L'objectif de la PNL est de développer des algorithmes et des modèles permettant aux ordinateurs d'extraire des informations à partir d'un texte.
 Comment l'utilisation des fonctions Java dans le traitement du langage naturel peut-elle faciliter les interactions conversationnelles ?
Apr 30, 2024 am 08:03 AM
Comment l'utilisation des fonctions Java dans le traitement du langage naturel peut-elle faciliter les interactions conversationnelles ?
Apr 30, 2024 am 08:03 AM
Les fonctions Java sont largement utilisées en PNL pour créer des solutions personnalisées qui améliorent l'expérience des interactions conversationnelles. Ces fonctions peuvent être utilisées pour le prétraitement de texte, l'analyse des sentiments, la reconnaissance d'intention et l'extraction d'entités. Par exemple, en utilisant les fonctions Java pour l'analyse des sentiments, les applications peuvent comprendre le ton de l'utilisateur et réagir de manière appropriée, améliorant ainsi l'expérience conversationnelle.
![Tutoriel [Python NLTK] : Démarrez facilement et amusez-vous avec le traitement du langage naturel](https://img.php.cn/upload/article/000/465/014/170882721469561.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) Tutoriel [Python NLTK] : Démarrez facilement et amusez-vous avec le traitement du langage naturel
Feb 25, 2024 am 10:13 AM
Tutoriel [Python NLTK] : Démarrez facilement et amusez-vous avec le traitement du langage naturel
Feb 25, 2024 am 10:13 AM
1. Introduction à NLTK NLTK est une boîte à outils de traitement du langage naturel pour le langage de programmation Python, créée en 2001 par Steven Bird et Edward Loper. NLTK fournit une large gamme d'outils de traitement de texte, notamment le prétraitement de texte, la segmentation de mots, le marquage de parties du discours, l'analyse syntaxique, l'analyse sémantique, etc., qui peuvent aider les développeurs à traiter facilement les données en langage naturel. 2.Installation de NLTK NLTK peut être installé via la commande suivante : fromnltk.tokenizeimportWord_tokenizetext="Bonjour tout le monde ! Thisisasampletext."tokens=word_tokenize(te
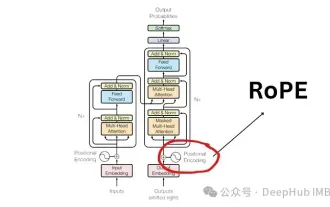 Explication détaillée du codage de position de rotation RoPE couramment utilisé dans les grands modèles de langage : pourquoi est-il meilleur que le codage de position absolue ou relative ?
Apr 01, 2024 pm 08:19 PM
Explication détaillée du codage de position de rotation RoPE couramment utilisé dans les grands modèles de langage : pourquoi est-il meilleur que le codage de position absolue ou relative ?
Apr 01, 2024 pm 08:19 PM
L'architecture Transformer est la pierre angulaire du domaine du traitement du langage naturel (NLP) depuis l'article « AttentionIsAllYouNeed » publié en 2017. Sa conception est restée pratiquement inchangée depuis des années, 2022 marquant un développement majeur dans le domaine avec l'introduction du Rotary Position Encoding (RoPE). L'intégration de position avec rotation est la technique d'intégration de position PNL de pointe. Les modèles linguistiques à grande échelle les plus populaires (tels que Llama, Llama2, PaLM et CodeGen) l'utilisent déjà. Dans cet article, nous examinerons en profondeur ce que sont les codages de position de rotation et comment ils combinent parfaitement les avantages des intégrations de position absolue et relative. La nécessité d'un codage positionnel pour comprendre Ro
 Traitement du langage naturel et analyse de texte à l'aide du langage Go
Nov 30, 2023 am 10:15 AM
Traitement du langage naturel et analyse de texte à l'aide du langage Go
Nov 30, 2023 am 10:15 AM
Le traitement du langage naturel (NLP) est un domaine interdisciplinaire impliquant l'informatique, l'intelligence artificielle, la linguistique et d'autres disciplines. Son objectif est d'aider l'ordinateur à comprendre, interpréter et générer un langage naturel. L'analyse de texte (TextAnalysis) est l'une des directions importantes de la PNL. Son objectif principal est d'extraire des informations significatives à partir de grandes quantités de données textuelles pour prendre en charge des scénarios d'application tels que la prise de décision commerciale, la recherche linguistique et l'analyse de l'opinion publique. Allez en langue
 Comment configurer le traitement du langage naturel à l'aide d'IntelliJ IDEA sur les systèmes Linux
Jul 05, 2023 pm 10:45 PM
Comment configurer le traitement du langage naturel à l'aide d'IntelliJ IDEA sur les systèmes Linux
Jul 05, 2023 pm 10:45 PM
Méthode de configuration pour l'utilisation d'IntelliJIDEA pour le traitement du langage naturel sur les systèmes Linux IntelliJIDEA est un puissant environnement de développement intégré (IDE) adapté à plusieurs langages de programmation. Cet article explique comment configurer IntelliJIDEA sur un système Linux pour faciliter le développement du traitement du langage naturel (NLP). Étape 1 : Téléchargez et installez IntelliJIDEA Tout d'abord, nous devons nous rendre sur le site officiel https://www.
