
 développement back-end
Tutoriel Python
Comment créer une carte thermique de corrélation Seaborn en Python ?
développement back-end
Tutoriel Python
Comment créer une carte thermique de corrélation Seaborn en Python ?
Comment créer une carte thermique de corrélation Seaborn en Python ?

Dans l'ensemble de données, la force et la direction de la corrélation entre deux paires de variables sont affichées graphiquement via une carte thermique de corrélation, qui illustre la matrice de corrélation. Il s'agit d'une technique efficace pour trouver des modèles et des connexions dans des ensembles de données à grande échelle.
L'outil de visualisation de données Python Seaborn fournit des outils simples pour générer des graphiques de visualisation statistique. Les utilisateurs peuvent visualiser rapidement la matrice de corrélation d'un ensemble de données grâce à sa capacité à créer des cartes thermiques de corrélation.
Nous devons importer l'ensemble de données, calculer la matrice de corrélation des variables, puis utiliser la fonction de carte thermique Seaborn pour générer la carte thermique afin de construire la carte thermique de corrélation. Une carte thermique affiche une matrice dont les couleurs représentent le degré de corrélation entre les variables. De plus, les utilisateurs peuvent afficher les coefficients de corrélation sur des cartes thermiques.
Seaborn Correlation Heatmap est une technique de visualisation efficace pour examiner les modèles et les relations dans un ensemble de données et peut être utilisée pour identifier les variables clés pour une enquête plus approfondie.
Utilisez la fonction Heatmap()
La fonction heatmap génère une matrice codée par couleur illustrant la force de la corrélation entre deux paires de variables dans l'ensemble de données. La fonction heatmap nous oblige à fournir la matrice de corrélation des variables, qui peut être calculée à l'aide de la méthode corr de la trame de données Pandas. La fonction de carte thermique fournit un certain nombre d'options facultatives qui permettent à l'utilisateur de modifier les effets visuels de la carte thermique, notamment la palette de couleurs, l'annotation, la taille et la position du graphique.
Grammaire
import seaborn as sns sns.heatmap(data, cmap=None, annot=None)
Les données de paramètres dans la fonction ci-dessus sont la matrice de corrélation représentant l'ensemble de données d'entrée. La carte de couleurs utilisée pour colorer les cartes thermiques est appelée cmap.
La traduction chinoise deExemple 1
est :Exemple 1
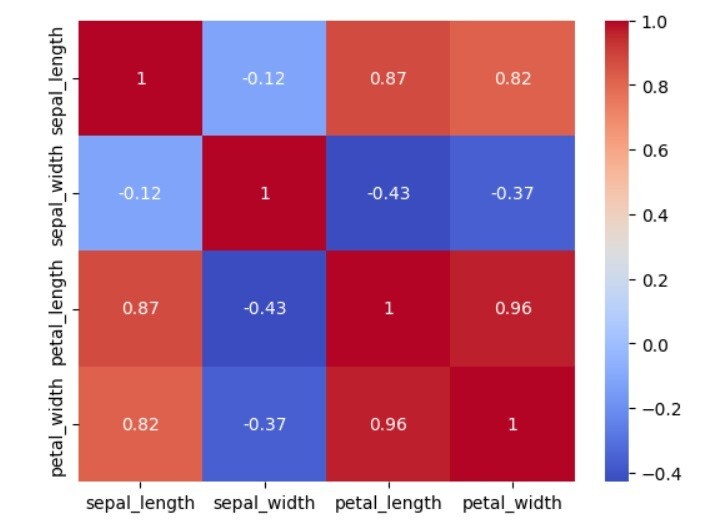
Dans cet exemple, nous créons une carte thermique de corrélation marine à l'aide de Python. Tout d'abord, nous importons les bibliothèques seaborn et matplotlib et chargeons l'ensemble de données iris à l'aide de la fonction de chargement d'ensemble de données de Seaborn. Cet ensemble de données contient les variables SepalLength, SepalWidth, PetalLength et PetalWidth. L'ensemble de données sur l'iris comprend des mesures de la longueur des sépales, de la largeur des sépales, de la longueur des pétales et de la largeur des pétales des fleurs d'iris. Voici un exemple de message -
| Numéro de série | sepal_length | sepal_width | Longueur des pétales | Largeur des pétales | Espèce | |
|---|---|---|---|---|---|---|
| 0 | 5.1 | La traduction chinoise de3.5 | est :3.5 | 1.4 | 0,2 | Soie lisse |
| 1 | 4.9 | 3.0 | 1.4 | 0,2 | Soie lisse | |
| 2 | 4.7 | 3.2 | 1.3 | 0,2 | Soie lisse | |
| 3 | 4.6 | se traduit par :4.6 | 3.1 | 1.5 | 0,2 | Soie lisse |
| 4 | 5.0 | Traduit en chinois :5.0 | 3.6 | 1.4 | 0,2 | Soie lisse |
Les utilisateurs peuvent utiliser la méthode de chargement de l'ensemble de données de Seaborn pour charger l'ensemble de données d'iris dans un Pandas DataFrame. La matrice de corrélation des variables est ensuite calculée à l'aide de la méthode corr du dataframe Pandas et enregistrée dans une variable appelée corr_matrix. Nous utilisons la méthode Heatmap de Seaborn pour générer des cartes thermiques. Nous transmettons la matrice de corrélation corr_matrix à la fonction et définissons le paramètre cmap sur "coolwarm" pour utiliser différentes couleurs pour représenter les corrélations positives et négatives. Enfin, nous utilisons la méthode show du module pyplot de matplotlib pour afficher la carte thermique.
# Required libraries
import seaborn as sns
import matplotlib.pyplot as plt
# Load the iris dataset into a Pandas dataframe
iris_data = sns.load_dataset('iris')
# Creating the correlation matrix of the iris dataset
iris_corr_matrix = iris_data.corr()
print(iris_corr_matrix)
# Create the heatmap using the `heatmap` function of Seaborn
sns.heatmap(iris_corr_matrix, cmap='coolwarm', annot=True)
# Display the heatmap using the `show` method of the `pyplot` module from matplotlib.
plt.show()
Sortie
sepal_length sepal_width petal_length petal_width sepal_length 1.000000 -0.117570 0.871754 0.817941 sepal_width -0.117570 1.000000 -0.428440 -0.366126 petal_length 0.871754 -0.428440 1.000000 0.962865 petal_width 0.817941 -0.366126 0.962865 1.000000
Exemple 2
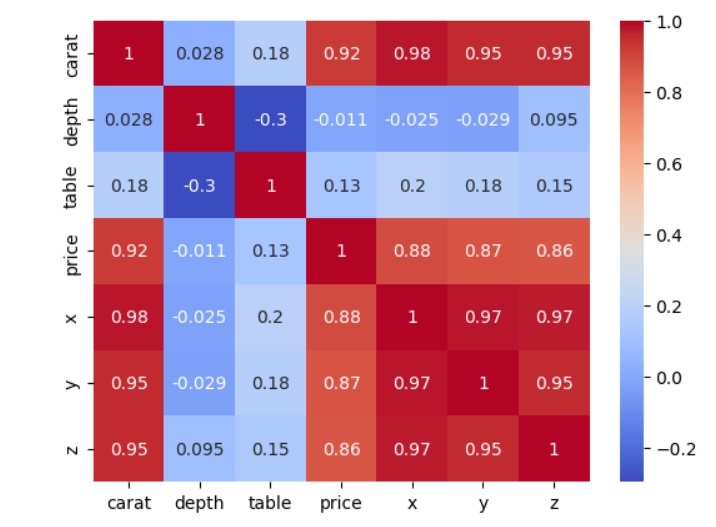
Dans cet exemple, nous utilisons à nouveau Python pour créer une carte thermique de corrélation marine. Tout d'abord, nous importons les bibliothèques seaborn et matplotlib et chargeons l'ensemble de données diamant à l'aide de la fonction de chargement de l'ensemble de données de Seaborn. L'ensemble de données sur les diamants comprend des informations détaillées sur le coût et les caractéristiques des diamants, notamment leur poids en carats, leur taille, leur couleur et leur clarté. Ceci est un exemple d'information −
| Numéro de série | carats | La traduction chinoise decut | est :cut | Couleur | Clarté | La traduction chinoise deprofondeur | est :profondeur | Table | Prix | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Idéal | se traduit par :Idéal | E | SI2 | 61,5 | 55.0 | Traduit en chinois :55.0 | 326 | La traduction chinoise de3.95 | est :3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Version Premium | E | SI1 | 59,8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 | |||
| 2 | 0.23 | Bien | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 | |||
| 3 | 0,29 | Version Premium | La traduction chinoise deI | est :I | VS2 | La traduction chinoise de62.4 | est :62.4 | 58.0 | 334 | 4.20 | 4.23 | 2,63 | |
| 4 | 0.31 | Bien | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | La traduction chinoise de2.75 | est :2.75 |
可以使用 Seaborn 的加载数据集函数将钻石数据集加载到 Pandas DataFrame 中。接下来,使用 Pandas 数据帧的 corr 方法,计算变量的相关矩阵并将其存储在名为 Diamond_corr_matrix 的变量中。为了利用不同的颜色来表示与函数的正相关和负相关,我们传递相关矩阵 corr 矩阵并将 cmap 选项设置为“coolwarm”。最后,我们使用 matplotlib 的 show 方法中的 pyplot 模块来显示热图。
# Required libraries
import seaborn as sns
import matplotlib.pyplot as plt
# Load the diamond dataset into a Pandas dataframe
diamonds_data = sns.load_dataset('diamonds')
# Compute the correlation matrix of the variables
diamonds_corr_matrix = diamonds_data.corr()
print(diamonds_corr_matrix)
# Create the heatmap using the `heatmap` function of Seaborn
sns.heatmap(diamonds_corr_matrix, cmap='coolwarm', annot=True)
# Display the heatmap using the `show` method of the `pyplot` module from matplotlib.
plt.show()
输出
carat depth table price x y z carat 1.000000 0.028224 0.181618 0.921591 0.975094 0.951722 0.953387 depth 0.028224 1.000000 -0.295779 -0.010647 -0.025289 -0.029341 0.094924 table 0.181618 -0.295779 1.000000 0.127134 0.195344 0.183760 0.150929 price 0.921591 -0.010647 0.127134 1.000000 0.884435 0.865421 0.861249 x 0.975094 -0.025289 0.195344 0.884435 1.000000 0.974701 0.970772 y 0.951722 -0.029341 0.183760 0.865421 0.974701 1.000000 0.952006 z 0.953387 0.094924 0.150929 0.861249 0.970772 0.952006 1.000000
热图是一种有益的图形表示形式,seaborn 使其变得简单易用。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: Une base de données Python évolutive de haut niveau légère HaDIDB (HaDIDB) est une base de données légère écrite en Python, avec un niveau élevé d'évolutivité. Installez HaDIDB à l'aide de l'installation PIP: PiPinStallHaDIDB User Management Créer un utilisateur: CreateUser () pour créer un nouvel utilisateur. La méthode Authentication () authentifie l'identité de l'utilisateur. FromHadidb.OperationMportUserUser_OBJ = User ("Admin", "Admin") User_OBJ.
 MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL peut s'exécuter sans connexions réseau pour le stockage et la gestion des données de base. Cependant, la connexion réseau est requise pour l'interaction avec d'autres systèmes, l'accès à distance ou l'utilisation de fonctionnalités avancées telles que la réplication et le clustering. De plus, les mesures de sécurité (telles que les pare-feu), l'optimisation des performances (choisissez la bonne connexion réseau) et la sauvegarde des données sont essentielles pour se connecter à Internet.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 MySQL Workbench peut-il se connecter à MariaDB
Apr 08, 2025 pm 02:33 PM
MySQL Workbench peut-il se connecter à MariaDB
Apr 08, 2025 pm 02:33 PM
MySQL Workbench peut se connecter à MARIADB, à condition que la configuration soit correcte. Sélectionnez d'abord "MariADB" comme type de connecteur. Dans la configuration de la connexion, définissez correctement l'hôte, le port, l'utilisateur, le mot de passe et la base de données. Lorsque vous testez la connexion, vérifiez que le service MARIADB est démarré, si le nom d'utilisateur et le mot de passe sont corrects, si le numéro de port est correct, si le pare-feu autorise les connexions et si la base de données existe. Dans une utilisation avancée, utilisez la technologie de mise en commun des connexions pour optimiser les performances. Les erreurs courantes incluent des autorisations insuffisantes, des problèmes de connexion réseau, etc. Lors des erreurs de débogage, analysez soigneusement les informations d'erreur et utilisez des outils de débogage. L'optimisation de la configuration du réseau peut améliorer les performances
 MySQL a-t-il besoin d'un serveur
Apr 08, 2025 pm 02:12 PM
MySQL a-t-il besoin d'un serveur
Apr 08, 2025 pm 02:12 PM
Pour les environnements de production, un serveur est généralement nécessaire pour exécuter MySQL, pour des raisons, notamment les performances, la fiabilité, la sécurité et l'évolutivité. Les serveurs ont généralement un matériel plus puissant, des configurations redondantes et des mesures de sécurité plus strictes. Pour les petites applications à faible charge, MySQL peut être exécutée sur des machines locales, mais la consommation de ressources, les risques de sécurité et les coûts de maintenance doivent être soigneusement pris en considération. Pour une plus grande fiabilité et sécurité, MySQL doit être déployé sur le cloud ou d'autres serveurs. Le choix de la configuration du serveur approprié nécessite une évaluation en fonction de la charge d'application et du volume de données.
