
 Périphériques technologiques
IA
Une présentation technique approfondie de cinq minutes sur les modèles génératifs de GET3D
Périphériques technologiques
IA
Une présentation technique approfondie de cinq minutes sur les modèles génératifs de GET3D
Une présentation technique approfondie de cinq minutes sur les modèles génératifs de GET3D

Partie 01 ●
Avant-propos
Ces dernières années, avec l'essor des outils de génération d'images d'intelligence artificielle représentés par Midjourney et Stable Diffusion, la technologie de génération d'images d'intelligence artificielle 2D est devenue un outil auxiliaire utilisé par de nombreux concepteurs dans des projets réels. appliqué dans divers scénarios commerciaux et crée de plus en plus de valeur pratique. Dans le même temps, avec l'essor du Metaverse, de nombreuses industries s'orientent vers la création de mondes virtuels 3D à grande échelle, et un contenu 3D diversifié et de haute qualité devient de plus en plus important pour des secteurs tels que les jeux, la robotique, l'architecture, et les plateformes sociales. Cependant, la création manuelle d’actifs 3D prend du temps et nécessite des compétences artistiques et de modélisation spécifiques. L'un des principaux défis est la question de l'échelle : malgré le grand nombre de modèles 3D que l'on peut trouver sur le marché 3D, peupler un groupe de personnages ou de bâtiments qui ont tous un aspect différent dans un jeu ou un film nécessite toujours un investissement important de la part de l'artiste. temps. En conséquence, le besoin d'outils de création de contenu pouvant évoluer en termes de quantité, de qualité et de diversité du contenu 3D est devenu de plus en plus évident
 Photos
Photos
Veuillez voir la figure 1, il s'agit d'une photo de l'espace métaverse ( Source : le film "Les Mondes de Ralph 2")
Grâce au fait que les modèles génératifs 2D ont atteint une qualité réaliste dans la synthèse d'images haute résolution, ces progrès ont également inspiré la recherche sur la génération de contenu 3D. Les premières méthodes visaient à étendre directement les générateurs CNN 2D aux grilles de voxels 3D, mais l'empreinte mémoire élevée et la complexité informatique des convolutions 3D ont entravé le processus de génération à haute résolution. Comme alternative, d’autres recherches ont exploré les nuages de points, les représentations implicites ou octree. Cependant, ces travaux se concentrent principalement sur la génération de géométrie et ignorent l’apparence. Leurs représentations de sortie doivent également être post-traitées pour les rendre compatibles avec les moteurs graphiques standards.
Afin d'être pratiques pour la production de contenu, les modèles génératifs 3D idéaux doivent répondre aux exigences suivantes :
Avoir la capacité de générer des graphiques 3D avec des géométries géométriques. détails et topologie arbitraire Capacité des formes
Réécrire le contenu : (b) Le résultat doit être un maillage texturé, qui est une expression courante utilisée par les logiciels graphiques standard tels que Blender et Maya
Peut être supervisé à l'aide d'images 2D, telles qu'elles sont plus petites que des formes 3D explicites Plus généralement
Partie 02
Introduction aux modèles 3D génératifs
Pour faciliter le processus de création de contenu et permettre des applications pratiques, les réseaux 3D génératifs sont devenus un domaine de recherche actif capable de produire des actifs 3D diversifiés et de haute qualité . Chaque année, de nombreux modèles génératifs 3D sont publiés à l'ICCV, NeurlPS, ICML et d'autres conférences, y compris les modèles de pointe suivants
Textured3DGAN est un modèle génératif qui est une extension de la méthode convolutive de génération de maillages 3D texturés. Il est capable d'apprendre à générer des maillages de textures à partir d'images physiques à l'aide de GAN sous supervision 2D. Par rapport aux méthodes précédentes, Textured3DGAN assouplit les exigences relatives aux points clés dans l'étape d'estimation de pose et généralise la méthode aux collections d'images non étiquetées et aux nouvelles catégories/ensembles de données, tels que ImageNet
DIB-R : est un moteur de rendu différenciable basé sur l'interpolation, utilisant PyTorch. cadre d'apprentissage automatique en bas. Ce moteur de rendu a été ajouté au référentiel 3D Deep Learning PyTorch GitHub (Kaolin). Cette méthode permet le calcul analytique des dégradés pour tous les pixels de l'image. L'idée principale est de traiter la rastérisation de premier plan comme une interpolation pondérée d'attributs locaux et la rastérisation d'arrière-plan comme une agrégation de géométrie globale basée sur la distance. De cette façon, il peut prédire des informations telles que la forme, la texture et la lumière à partir d'une seule image
PolyGen : PolyGen est un modèle génératif autorégressif basé sur l'architecture Transformer pour modéliser directement des maillages. Le modèle prédit tour à tour les sommets et les faces du maillage. Nous avons formé le modèle à l'aide de l'ensemble de données ShapeNet Core V2, et les résultats sont déjà très proches des modèles de maillage construits par l'homme
SurfGen : synthèse de forme 3D contradictoire avec un discriminateur de surface explicite. Le modèle entraîné de bout en bout est capable de générer des formes 3D haute fidélité avec différentes topologies.
GET3D est un modèle génératif capable de générer des formes texturées 3D de haute qualité en apprenant des images. Son cœur est la modélisation de surface différenciable, le rendu différenciable et les réseaux contradictoires génératifs 2D. En s'entraînant sur une collection d'images 2D, GET3D peut générer directement des maillages 3D explicitement texturés avec une topologie complexe, des détails géométriques riches et des textures haute fidélité
 images
images
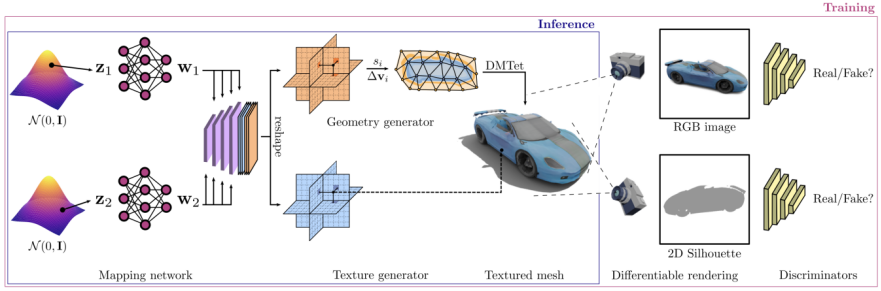
Ce qui doit être réécrit est : Figure 2 Modèle de génération GET3D (Source : site officiel du papier GET3D https://nv-tlabs.github.io/GET3D/)
GET3D est un modèle génératif 3D récemment proposé qui utilise plusieurs modèles avec des géométries complexes telles que ShapeNet, Turbosquid et Renderpeople Catégories telles que. des chaises, des motos, des voitures, des personnes et des bâtiments, démontrant des performances de pointe dans une génération illimitée de formes 3D
Partie 03
L'architecture et les caractéristiques de GET3D
 Pictures
Pictures
L'architecture GET3D provient du site officiel du papier GET3D. La figure 3 montre l'architecture
Un SDF 3D (champ de distance dirigé) est généré via deux encodages potentiels. et un champ de texture, puis utilisez DMTet (Deep Marching Tetrahedra) pour extraire le maillage de surface 3D de SDF et interrogez le champ de texture dans le nuage de points de surface pour obtenir la couleur. L'ensemble du processus est entraîné à l'aide d'une perte contradictoire définie sur des images 2D. En particulier, les images et les contours RVB sont obtenus à l'aide d'un moteur de rendu différenciable basé sur la rastérisation. Enfin, deux discriminateurs 2D sont utilisés, chacun pour les images RVB et les contours, pour distinguer si l'entrée est réelle ou fausse. L'ensemble du modèle peut être entraîné de bout en bout
GET3D est également très flexible sous d'autres aspects et peut être facilement adapté à d'autres tâches en plus d'exprimer des maillages explicites en sortie, notamment :
Implémentation séparée de la géométrie et de la texture : bon découplage entre la géométrie et la texture est obtenue, permettant une interpolation significative des codes latents de géométrie et des codes latents de texture
En effectuant une marche aléatoire dans l'espace latent, lors de la génération de transitions douces entre différentes classes de formes, et en générant des formes 3D correspondantes pour réaliser
Générer de nouvelles formes : cela peut être perturbé en ajoutant un petit bruit au code latent local, générant ainsi des formes qui se ressemblent mais sont légèrement différentes localement
Génération de matériaux non supervisée : via Combiné avec DIBR++, générez des matériaux de manière totalement non supervisée et produisez effets d'éclairage significatifs dépendant de la vue
Génération de formes guidée par texte : en combinant StyleGAN NADA, en exploitant les images 2D rendues par ordinateur et le texte fourni par l'utilisateur. En utilisant la perte CLIP directionnelle pour affiner le générateur 3D, les utilisateurs peuvent générer un grand nombre de formes via des invites de texte
 Images
Images
Veuillez vous référer à la figure 4, qui montre le processus de génération de formes basées sur du texte. La source de cette figure est le site officiel de l'article GET3D, l'URL est https://nv-tlabs.github.io/GET3D/
Part 04
Summary
Bien que GET3D ait fait un pas vers une 3D pratique modèle de génération de forme de texture. Une étape importante, mais qui présente encore certaines limites. En particulier, le processus de formation repose toujours sur la connaissance des silhouettes 2D et des répartitions de caméras. Par conséquent, actuellement GET3D ne peut être évalué que sur la base de données synthétiques. Une extension prometteuse consiste à exploiter les progrès de la segmentation des instances et de l'estimation de la pose de la caméra pour atténuer ce problème et étendre GET3D aux données du monde réel. GET3D n'est actuellement formé qu'en fonction des catégories et sera étendu à plusieurs catégories à l'avenir pour mieux représenter la diversité entre les catégories. Espérons que cette recherche rapprochera les gens de l’utilisation de l’intelligence artificielle pour la création gratuite de contenu 3D
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 En savoir plus sur les emojis 3D Fluent dans Microsoft Teams
Apr 24, 2023 pm 10:28 PM
En savoir plus sur les emojis 3D Fluent dans Microsoft Teams
Apr 24, 2023 pm 10:28 PM
N'oubliez pas, surtout si vous êtes un utilisateur de Teams, que Microsoft a ajouté un nouveau lot d'émojis 3DFluent à son application de visioconférence axée sur le travail. Après que Microsoft a annoncé des emojis 3D pour Teams et Windows l'année dernière, le processus a en fait permis de mettre à jour plus de 1 800 emojis existants pour la plate-forme. Cette grande idée et le lancement de la mise à jour des emoji 3DFluent pour les équipes ont été promus pour la première fois via un article de blog officiel. La dernière mise à jour de Teams apporte FluentEmojis à l'application. Microsoft affirme que les 1 800 emojis mis à jour seront disponibles chaque jour.
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Paint 3D sous Windows 11 : guide de téléchargement, d'installation et d'utilisation
Apr 26, 2023 am 11:28 AM
Paint 3D sous Windows 11 : guide de téléchargement, d'installation et d'utilisation
Apr 26, 2023 am 11:28 AM
Lorsque les rumeurs ont commencé à se répandre selon lesquelles le nouveau Windows 11 était en développement, chaque utilisateur de Microsoft était curieux de savoir à quoi ressemblerait le nouveau système d'exploitation et ce qu'il apporterait. Après de nombreuses spéculations, Windows 11 est là. Le système d'exploitation est livré avec une nouvelle conception et des modifications fonctionnelles. En plus de quelques ajouts, il s’accompagne de fonctionnalités obsolètes et supprimées. L'une des fonctionnalités qui n'existe pas dans Windows 11 est Paint3D. Bien qu'il propose toujours Paint classique, idéal pour les dessinateurs, les griffonneurs et les griffonneurs, il abandonne Paint3D, qui offre des fonctionnalités supplémentaires idéales pour les créateurs 3D. Si vous recherchez des fonctionnalités supplémentaires, nous recommandons Autodesk Maya comme le meilleur logiciel de conception 3D. comme
 Obtenez une femme virtuelle en 3D en 30 secondes avec une seule carte ! Text to 3D génère un humain numérique de haute précision avec des détails de pores clairs, se connectant de manière transparente à Maya, Unity et d'autres outils de production.
May 23, 2023 pm 02:34 PM
Obtenez une femme virtuelle en 3D en 30 secondes avec une seule carte ! Text to 3D génère un humain numérique de haute précision avec des détails de pores clairs, se connectant de manière transparente à Maya, Unity et d'autres outils de production.
May 23, 2023 pm 02:34 PM
ChatGPT a injecté une dose de sang de poulet dans l’industrie de l’IA, et tout ce qui était autrefois impensable est devenu aujourd’hui une pratique de base. Le Text-to-3D, qui continue de progresser, est considéré comme le prochain point chaud dans le domaine de l'AIGC après la diffusion (images) et le GPT (texte), et a reçu une attention sans précédent. Non, un produit appelé ChatAvatar a été mis en version bêta publique discrète, recueillant rapidement plus de 700 000 vues et attention, et a été présenté sur Spacesoftheweek. △ChatAvatar prendra également en charge la technologie Imageto3D qui génère des personnages stylisés en 3D à partir de peintures originales à perspective unique/multi-perspective générées par l'IA. Le modèle 3D généré par la version bêta actuelle a reçu une large attention.
 Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Lien du projet écrit devant : https://nianticlabs.github.io/mickey/ Étant donné deux images, la pose de la caméra entre elles peut être estimée en établissant la correspondance entre les images. En règle générale, ces correspondances sont 2D à 2D et nos poses estimées sont à échelle indéterminée. Certaines applications, telles que la réalité augmentée instantanée, à tout moment et en tout lieu, nécessitent une estimation de pose des métriques d'échelle, elles s'appuient donc sur des estimateurs de profondeur externes pour récupérer l'échelle. Cet article propose MicKey, un processus de correspondance de points clés capable de prédire les correspondances métriques dans l'espace d'une caméra 3D. En apprenant la correspondance des coordonnées 3D entre les images, nous sommes en mesure de déduire des métriques relatives.
 Une interprétation approfondie de l'algorithme de perception visuelle 3D pour la conduite autonome
Jun 02, 2023 pm 03:42 PM
Une interprétation approfondie de l'algorithme de perception visuelle 3D pour la conduite autonome
Jun 02, 2023 pm 03:42 PM
Pour les applications de conduite autonome, il est finalement nécessaire de percevoir des scènes 3D. La raison est simple : un véhicule ne peut pas conduire sur la base des résultats de perception obtenus à partir d’une image. Même un conducteur humain ne peut pas conduire sur la base d’une image. Étant donné que la distance de l'objet et les informations sur la profondeur de la scène ne peuvent pas être reflétées dans les résultats de perception 2D, ces informations sont la clé permettant au système de conduite autonome de porter des jugements corrects sur l'environnement. De manière générale, les capteurs visuels (comme les caméras) des véhicules autonomes sont installés au-dessus de la carrosserie du véhicule ou sur le rétroviseur intérieur. Peu importe où elle se trouve, la caméra obtient la projection du monde réel dans la vue en perspective (PerspectiveView) (du système de coordonnées mondiales au système de coordonnées de l'image). Cette vue est très similaire au système visuel humain,
