

Utiliser le module Requêtes en Python

Requests est un module Python qui peut être utilisé pour envoyer diverses requêtes HTTP. Il s'agit d'une bibliothèque facile à utiliser avec de nombreuses fonctionnalités, allant de la transmission de paramètres dans les URL à l'envoi d'en-têtes personnalisés et à la vérification SSL. Dans ce tutoriel, vous apprendrez à utiliser cette bibliothèque pour envoyer des requêtes HTTP simples en Python.
Vous pouvez utiliser des requêtes dans les versions 2.6 à 2.7 et 3.3 à 3.6 de Python. Avant de continuer, sachez que Requests est un module externe, vous devez donc l'installer avant d'essayer les exemples de ce tutoriel. Vous pouvez l'installer en exécutant la commande suivante dans Terminal :
pip install requests
Après avoir installé le module, vous pouvez importer le module à l'aide de la commande suivante pour vérifier s'il a été installé avec succès :
import requests
Si l'installation réussit, vous ne verrez aucun message d'erreur.
Faites une demande GET
L'envoi de requêtes HTTP est très simple avec Requests. Vous importez d’abord le module, puis effectuez la demande. Voici un exemple :
import requests
req = requests.get('https://tutsplus.com/')
Toutes les informations concernant notre demande sont désormais stockées dans un attribut appelé req 的响应对象中。例如,您可以使用 req.encoding 属性获取网页的编码。您还可以使用 req.status_code qui obtient le code de statut de la demande.
req.encoding # returns 'utf-8' req.status_code # returns 200
Vous pouvez utiliser la valeur req.cookies 访问服务器发回的 cookie。同样,您可以使用 req.headers 获取响应标头。 req.headers 属性返回响应标头的不区分大小写的字典。这意味着 req.headers['Content-Length']、req.headers['content-length'] 和 req。 headers['CONTENT-LENGTH'] 都会返回 'Content-Length' de l'en-tête de réponse.
Vous pouvez vérifier si la réponse est une redirection HTTP bien formée en utilisant l'attribut req.is_redirect 属性自动处理。它将根据响应返回 True 或 False 。您还可以使用 req.elapsed pour obtenir le temps écoulé entre l'envoi de la demande et l'obtention de la réponse.
Vous transmettez initialement l'attribut get() 函数的 URL 可能与响应的最终 URL 不同。要查看最终的响应 URL,您可以使用 req.url pour un certain nombre de raisons (y compris les redirections).
import requests
req = requests.get('https://www.tutsplus.com/')
req.encoding # returns 'utf-8'
req.status_code # returns 200
req.elapsed # returns datetime.timedelta(0, 1, 666890)
req.url # returns 'https://tutsplus.com/'
req.history
# returns [<Response [301]>, <Response [301]>]
req.headers['Content-Type']
# returns 'text/html; charset=utf-8'
C'est formidable d'avoir toutes ces informations sur la page Web que vous visitez, mais vous souhaiterez probablement accéder au contenu réel. Si le contenu auquel vous accédez est du texte, vous pouvez utiliser l'attribut req.text 属性来访问它。然后内容被解析为 unicode。您可以使用 req.encoding pour transmettre l'encodage utilisé pour décoder le texte.
Pour les réponses non textuelles, vous pouvez utiliser req.content 以二进制形式访问它们。该模块将自动解码 gzip 和 deflate 传输编码。当您处理媒体文件时,这会很有帮助。同样,您可以使用 req.json() pour accéder au contenu codé en json de la réponse (le cas échéant).
Vous pouvez également utiliser req.raw 从服务器获取原始响应。请记住,您必须在请求中传递 stream=True pour obtenir la réponse originale.
Certains fichiers que vous téléchargez depuis Internet à l'aide du module de requête peuvent être volumineux. Dans ce cas, il n’est pas judicieux de charger immédiatement l’intégralité de la réponse ou du fichier en mémoire. Vous pouvez télécharger des fichiers en morceaux ou en morceaux en utilisant la méthode iter_content(chunk_size = 1,decode_unicode=False).
Une itération de cette méthode chunk_size 字节数中的响应数据。当请求上设置了 stream=True 时,此方法将避免一次将整个文件读入内存以获得大量响应。 chunk_size 参数可以是整数,也可以是 None。当设置为整数值时,chunk_size détermine le nombre d'octets qui doivent être lus en mémoire.
Lorsque chunk_size 设置为 None 且 stream 设置为 True 时,数据将被读取为无论收到的块大小如何,它都会到达。当 chunk_size 设置为 None 且 stream 设置为 False , toutes les données seront renvoyées en un seul morceau.
Utilisons le module de requêtes pour télécharger quelques images de champignons. Voici l'image réelle :

Voici le code dont vous avez besoin :
import requests
req = requests.get('path/to/mushrooms.jpg', stream=True)
req.raise_for_status()
with open('mushrooms.jpg', 'wb') as fd:
for chunk in req.iter_content(chunk_size=50000):
print('Received a Chunk')
fd.write(chunk)
'path/to/mushrooms.jpg' 是实际的图像 URL。您可以将任何其他图像的 URL 放在这里来下载其他内容。给定的图像文件大小为 162kb,并且您已将 chunk_size 设置为 50,000 字节。这意味着“Received a Chunk”消息应在终端中打印四次。最后一个块的大小将仅为 32350 字节,因为前三次迭代后仍待接收的文件部分为 32350 字节。
您还可以用类似的方式下载视频。我们可以简单地将其值设置为 None,而不是指定固定的 chunk_size,然后视频将以提供的任何块大小下载。以下代码片段将从 Mixkit 下载高速公路的视频:
import requests
req = requests.get('path/to/highway/video.mp4', stream=True)
req.raise_for_status()
with open('highway.mp4', 'wb') as fd:
for chunk in req.iter_content(chunk_size=None):
print('Received a Chunk')
fd.write(chunk)
尝试运行代码,您将看到视频作为单个块下载。
如果您决定使用 stream 参数,则应记住以下几点。响应正文的下载会被推迟,直到您使用 content 属性实际访问其值。这样,如果某些标头值之一看起来不正确,您就可以避免下载文件。
另请记住,在将流的值设置为 True 时启动的任何连接都不会关闭,除非您消耗所有数据或使用 close() 方法。确保连接始终关闭的更好方法是在 with 语句中发出请求,即使您部分读取了响应,如下所示:
import requests
with requests.get('path/to/highway/video.mp4', stream=True) as rq:
with open('highway.mp4', 'wb') as fd:
for chunk in rq.iter_content(chunk_size=None):
print('Received a Chunk')
fd.write(chunk)
由于我们之前下载的图片文件比较小,您也可以使用以下代码一次性下载:
import requests
req = requests.get('path/to/mushrooms.jpg')
req.raise_for_status()
with open('mushrooms.jpg', 'wb') as fd:
fd.write(req.content)
我们跳过了设置 stream 参数的值,因此默认设置为 False。这意味着所有响应内容将立即下载。借助 content 属性,将响应内容捕获为二进制数据。
请求还允许您在 URL 中传递参数。当您在网页上搜索某些结果(例如特定图像或教程)时,这会很有帮助。您可以使用 GET 请求中的 params 关键字将这些查询字符串作为字符串字典提供。这是一个例子:
import requests
query = {'q': 'Forest', 'order': 'popular', 'min_width': '800', 'min_height': '600'}
req = requests.get('https://pixabay.com/en/photos/', params=query)
req.url
# returns 'https://pixabay.com/en/photos/?order=popular&min_height=600&q=Forest&min_width=800'
发出 POST 请求
发出 POST 请求与发出 GET 请求一样简单。您只需使用 post() 方法而不是 get() 即可。当您自动提交表单时,这会很有用。例如,以下代码将向 httpbin.org 域发送 post 请求,并将响应 JSON 作为文本输出。
import requests
req = requests.post('https://httpbin.org/post', data = {'username': 'monty', 'password': 'something_complicated'})
req.raise_for_status()
print(req.text)
'''
{
"args": {},
"data": "",
"files": {},
"form": {
"password": "something_complicated",
"username": "monty"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "45",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-63ad437e-67f5db6a161314861484f2eb"
},
"json": null,
"origin": "YOUR.IP.ADDRESS",
"url": "https://httpbin.org/post"
}
'''
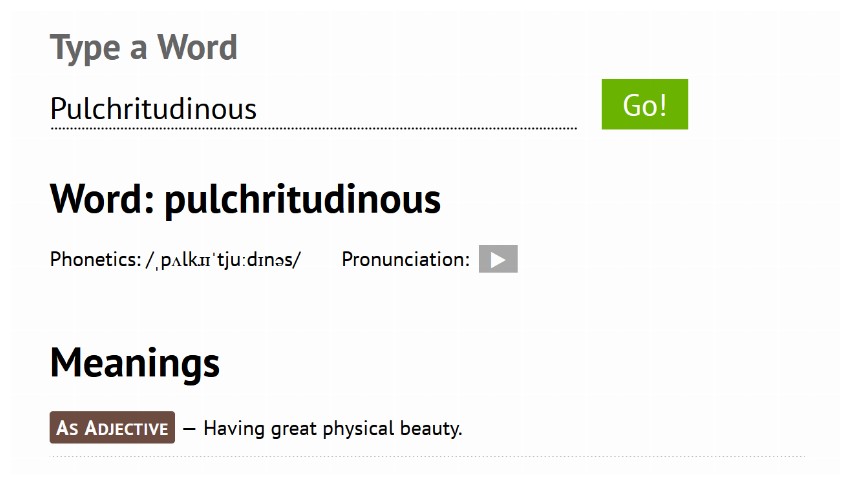
您可以将这些 POST 请求发送到任何可以处理它们的 URL。举个例子,我的一位朋友创建了一个网页,用户可以在其中输入单词并使用 API 获取其含义以及发音和其他信息。我们可以用我们查询的单词向URL发出POST请求,然后将结果保存为HTML页面,如下所示:
import requests
word = 'Pulchritudinous'
filename = word.lower() + '.html'
req = requests.post('https://tutorialio.com/tools/dictionary.php', data = {'query': word})
req.raise_for_status()
with open(filename, 'wb') as fd:
fd.write(req.content)
执行上面的代码,它会返回一个包含该单词信息的页面,如下图所示。
发送 Cookie 和标头
如前所述,您可以使用 req.cookies 和 req.headers 访问服务器发回给您的 cookie 和标头。请求还允许您通过请求发送您自己的自定义 cookie 和标头。当您想要为您的请求设置自定义用户代理时,这会很有帮助。
要将 HTTP 标头添加到请求中,您只需将它们通过 dict 传递到 headers 参数即可。同样,您还可以使用传递给 cookies 参数的 dict 将自己的 cookie 发送到服务器。
import requests
url = 'http://some-domain.com/set/cookies/headers'
headers = {'user-agent': 'your-own-user-agent/0.0.1'}
cookies = {'visit-month': 'February'}
req = requests.get(url, headers=headers, cookies=cookies)
Cookie 也可以在 Cookie Jar 中传递。它们提供了更完整的界面,允许您通过多个路径使用这些 cookie。这是一个例子:
import requests
jar = requests.cookies.RequestsCookieJar()
jar.set('first_cookie', 'first', domain='httpbin.org', path='/cookies')
jar.set('second_cookie', 'second', domain='httpbin.org', path='/extra')
jar.set('third_cookie', 'third', domain='httpbin.org', path='/cookies')
url = 'http://httpbin.org/cookies'
req = requests.get(url, cookies=jar)
req.text
# returns '{ "cookies": { "first_cookie": "first", "third_cookie": "third" }}'
会话对象
有时,在多个请求中保留某些参数很有用。 Session 对象正是这样做的。例如,它将在使用同一会话发出的所有请求中保留 cookie 数据。 Session 对象使用 urllib3 的连接池。这意味着底层 TCP 连接将被重复用于向同一主机发出的所有请求。这可以显着提高性能。您还可以将 Requests 对象的方法与 Session 对象一起使用。
以下是使用和不使用会话发送的多个请求的示例:
import requests
reqOne = requests.get('https://tutsplus.com/')
reqOne.cookies['_tuts_session']
#returns 'cc118d94a84f0ea37c64f14dd868a175'
reqTwo = requests.get('https://code.tutsplus.com/tutorials')
reqTwo.cookies['_tuts_session']
#returns '3775e1f1d7f3448e25881dfc35b8a69a'
ssnOne = requests.Session()
ssnOne.get('https://tutsplus.com/')
ssnOne.cookies['_tuts_session']
#returns '4c3dd2f41d2362108fbb191448eab3b4'
reqThree = ssnOne.get('https://code.tutsplus.com/tutorials')
reqThree.cookies['_tuts_session']
#returns '4c3dd2f41d2362108fbb191448eab3b4'
正如您所看到的,会话cookie在第一个和第二个请求中具有不同的值,但当我们使用Session对象时它具有相同的值。当您尝试此代码时,您将获得不同的值,但在您的情况下,使用会话对象发出的请求的 cookie 将具有相同的值。
当您想要在所有请求中发送相同的数据时,会话也很有用。例如,如果您决定将 cookie 或用户代理标头与所有请求一起发送到给定域,则可以使用 Session 对象。这是一个例子:
import requests
ssn = requests.Session()
ssn.cookies.update({'visit-month': 'February'})
reqOne = ssn.get('http://httpbin.org/cookies')
print(reqOne.text)
# prints information about "visit-month" cookie
reqTwo = ssn.get('http://httpbin.org/cookies', cookies={'visit-year': '2017'})
print(reqTwo.text)
# prints information about "visit-month" and "visit-year" cookie
reqThree = ssn.get('http://httpbin.org/cookies')
print(reqThree.text)
# prints information about "visit-month" cookie
如您所见,"visit-month" 会话 cookie 随所有三个请求一起发送。但是, "visit-year" cookie 仅在第二次请求期间发送。第三个请求中也没有提及 "vist-year" cookie。这证实了单个请求上设置的 cookie 或其他数据不会与其他会话请求一起发送。
结论
本教程中讨论的概念应该可以帮助您通过传递特定标头、cookie 或查询字符串来向服务器发出基本请求。当您尝试抓取网页以获取信息时,这将非常方便。现在,一旦您找出 URL 中的模式,您还应该能够自动从不同的网站下载音乐文件和壁纸。
学习 Python
无论您是刚刚入门还是希望学习新技能的经验丰富的程序员,都可以通过我们完整的 Python 教程指南学习 Python。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Cet article expliquera comment améliorer les performances du site Web en analysant les journaux Apache dans le système Debian. 1. Bases de l'analyse du journal APACH LOG enregistre les informations détaillées de toutes les demandes HTTP, y compris l'adresse IP, l'horodatage, l'URL de la demande, la méthode HTTP et le code de réponse. Dans Debian Systems, ces journaux sont généralement situés dans les répertoires /var/log/apache2/access.log et /var/log/apache2/error.log. Comprendre la structure du journal est la première étape d'une analyse efficace. 2.
 Python: jeux, GUIS, et plus
Apr 13, 2025 am 12:14 AM
Python: jeux, GUIS, et plus
Apr 13, 2025 am 12:14 AM
Python excelle dans les jeux et le développement de l'interface graphique. 1) Le développement de jeux utilise Pygame, fournissant des fonctions de dessin, audio et d'autres fonctions, qui conviennent à la création de jeux 2D. 2) Le développement de l'interface graphique peut choisir Tkinter ou Pyqt. Tkinter est simple et facile à utiliser, PYQT a des fonctions riches et convient au développement professionnel.
 PHP et Python: comparaison de deux langages de programmation populaires
Apr 14, 2025 am 12:13 AM
PHP et Python: comparaison de deux langages de programmation populaires
Apr 14, 2025 am 12:13 AM
PHP et Python ont chacun leurs propres avantages et choisissent en fonction des exigences du projet. 1.Php convient au développement Web, en particulier pour le développement rapide et la maintenance des sites Web. 2. Python convient à la science des données, à l'apprentissage automatique et à l'intelligence artificielle, avec syntaxe concise et adaptée aux débutants.
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Python et temps: tirer le meilleur parti de votre temps d'étude
Apr 14, 2025 am 12:02 AM
Python et temps: tirer le meilleur parti de votre temps d'étude
Apr 14, 2025 am 12:02 AM
Pour maximiser l'efficacité de l'apprentissage de Python dans un temps limité, vous pouvez utiliser les modules DateTime, Time et Schedule de Python. 1. Le module DateTime est utilisé pour enregistrer et planifier le temps d'apprentissage. 2. Le module de temps aide à définir l'étude et le temps de repos. 3. Le module de planification organise automatiquement des tâches d'apprentissage hebdomadaires.
 Certificat NGINX SSL Mise à jour du tutoriel Debian
Apr 13, 2025 am 07:21 AM
Certificat NGINX SSL Mise à jour du tutoriel Debian
Apr 13, 2025 am 07:21 AM
Cet article vous guidera sur la façon de mettre à jour votre certificat NGINXSSL sur votre système Debian. Étape 1: Installez d'abord CERTBOT, assurez-vous que votre système a des packages CERTBOT et Python3-CERTBOT-NGINX installés. Si ce n'est pas installé, veuillez exécuter la commande suivante: Sudoapt-getUpDaSuDoapt-GetInstallCertBotpyThon3-Certerbot-Nginx Étape 2: Obtenez et configurez le certificat Utilisez la commande Certbot pour obtenir le certificat LETSCRYPT et configure
 Comment configurer le serveur HTTPS dans Debian OpenSSL
Apr 13, 2025 am 11:03 AM
Comment configurer le serveur HTTPS dans Debian OpenSSL
Apr 13, 2025 am 11:03 AM
La configuration d'un serveur HTTPS sur un système Debian implique plusieurs étapes, notamment l'installation du logiciel nécessaire, la génération d'un certificat SSL et la configuration d'un serveur Web (tel qu'Apache ou Nginx) pour utiliser un certificat SSL. Voici un guide de base, en supposant que vous utilisez un serveur Apacheweb. 1. Installez d'abord le logiciel nécessaire, assurez-vous que votre système est à jour et installez Apache et OpenSSL: SudoaptupDaSuDoaptupgradeSudoaptinsta
 Guide de développement du plug-in de Gitlab sur Debian
Apr 13, 2025 am 08:24 AM
Guide de développement du plug-in de Gitlab sur Debian
Apr 13, 2025 am 08:24 AM
Développer un plugin Gitlab sur Debian nécessite des étapes et des connaissances spécifiques. Voici un guide de base pour vous aider à démarrer avec ce processus. Installation de GitLab Tout d'abord, vous devez installer GitLab sur votre système Debian. Vous pouvez vous référer au manuel d'installation officiel de Gitlab. Obtenez un jeton d'accès API avant d'effectuer l'intégration de l'API, vous devez d'abord obtenir le jeton d'accès API de GitLab. Ouvrez le tableau de bord GitLab, recherchez l'option "AccessTokens" dans les paramètres utilisateur et générez un nouveau jeton d'accès. Sera généré
