
 développement back-end
tutoriel php
Récupération de métadonnées à l'aide de l'API du New York Times
développement back-end
tutoriel php
Récupération de métadonnées à l'aide de l'API du New York Times
Récupération de métadonnées à l'aide de l'API du New York Times

简介
上周,我写了一篇关于抓取网页以收集元数据的介绍,并提到不可能抓取《纽约时报》网站。 《纽约时报》付费墙会阻止您收集基本元数据的尝试。但有一种方法可以使用纽约时报 API 来解决这个问题。
最近我开始在 Yii 平台上构建一个社区网站,我将在以后的教程中发布该网站。我希望能够轻松添加与网站内容相关的链接。虽然人们可以轻松地将 URL 粘贴到表单中,但提供标题和来源信息却非常耗时。
因此,在今天的教程中,我将扩展我最近编写的抓取代码,以在添加《纽约时报》链接时利用《纽约时报》API 来收集头条新闻。
请记住,我参与了下面的评论主题,所以请告诉我您的想法!您还可以通过 Twitter @lookahead_io 与我联系。
开始使用
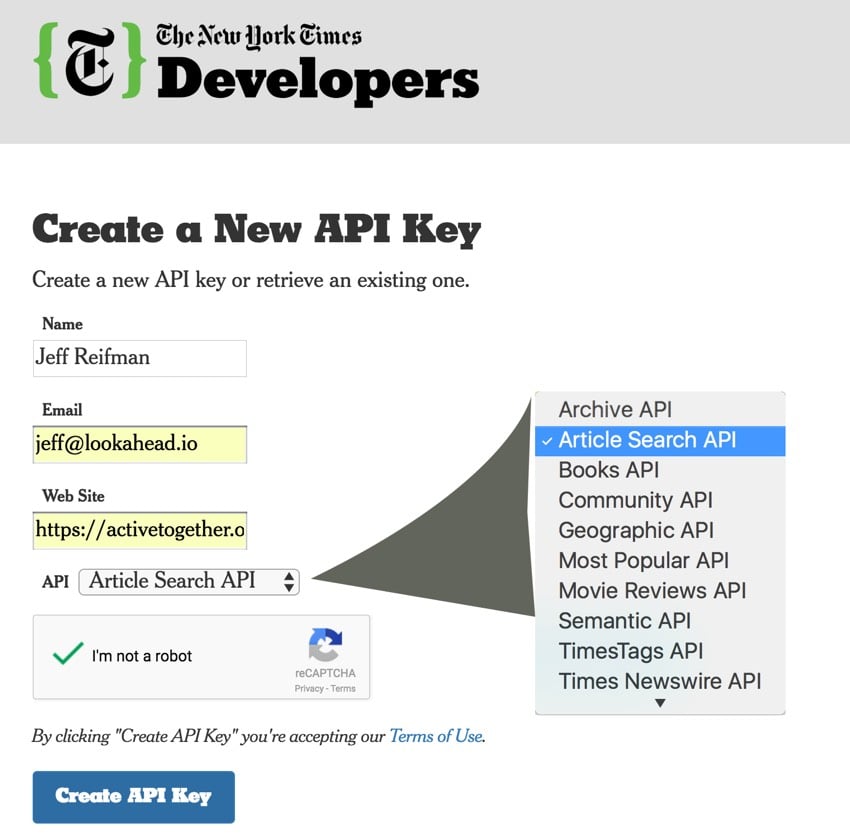
注册 API 密钥

首先,让我们注册并请求 API 密钥:
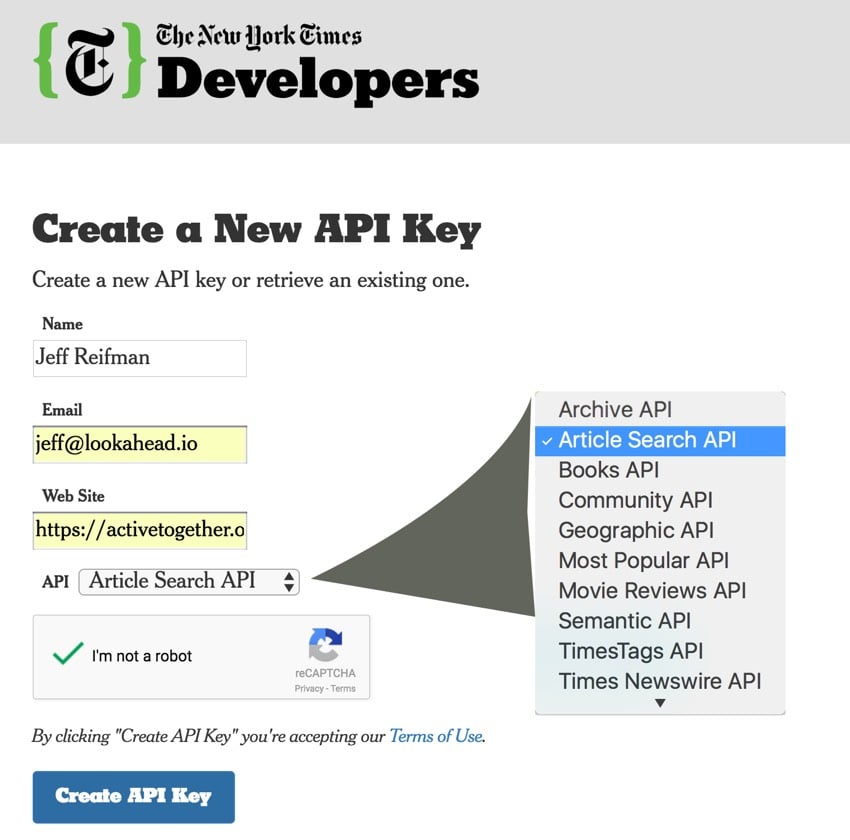
提交表单后,您将通过电子邮件收到密钥:
探索纽约时报 API

The Times 提供以下类别的 API:
- 存档
- 文章搜索
- 书籍
- 社区
- 地理
- 最受欢迎
- 电影评论
- 语义
- 泰晤士报
- 时代标签
- 头条新闻
很多。并且,在“图库”页面中,您可以单击任何主题来查看各个 API 类别文档:
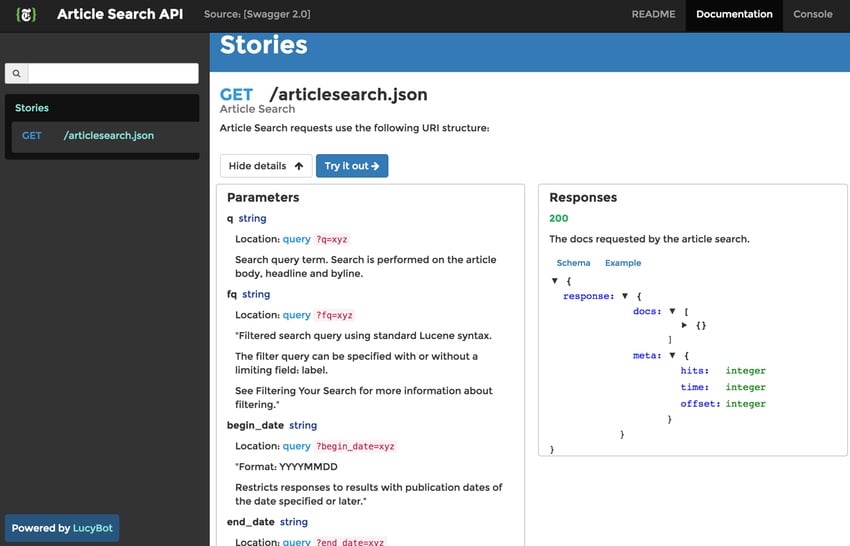
《纽约时报》使用 LucyBot 为其 API 文档提供支持,并且有一个有用的常见问题解答:

他们甚至向您展示如何快速获取 API 使用限制(您需要插入密钥):
curl --head
https://api.nytimes.com/svc/books/v3/lists/overview.json?api-key=<your-api-key>
2>/dev/null | grep -i "X-RateLimit"
X-RateLimit-Limit-day: 1000
X-RateLimit-Limit-second: 5
X-RateLimit-Remaining-day: 180
X-RateLimit-Remaining-second: 5
我最初很难理解该文档 - 它是基于参数的规范,而不是编程指南。不过,我在纽约时报 API GitHub 页面上发布了一些问题,这些问题很快就得到了有用的解答。
使用文章搜索
在今天的节目中,我将重点介绍如何使用《纽约时报》文章搜索。基本上,我们将扩展上一个教程中的创建链接表单:
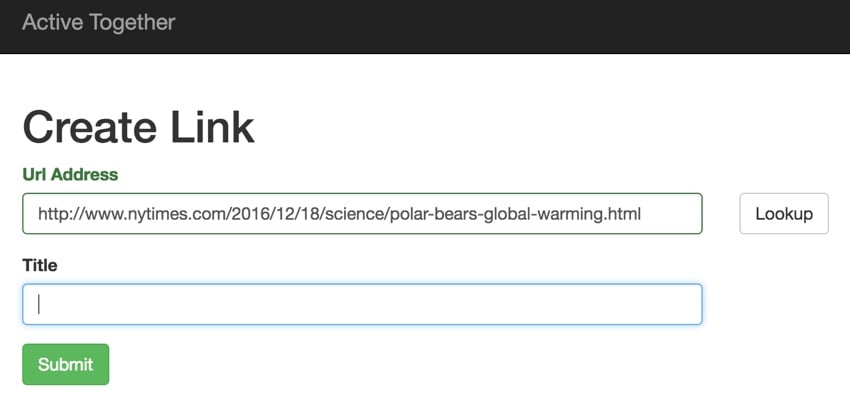
当用户点击查找时,我们将向 链接::grab($url)。这是 jQuery:
$(document).on("click", '[id=lookup]', function(event) {
$.ajax({
url: $('#url_prefix').val()+'/link/grab',
data: {url: $('#url').val()},
success: function(data) {
$('#title').val(data);
return true;
}
});
});
这是控制器和模型方法:
// Controller call via AJAX Lookup request
public static function actionGrab($url) {
Yii::$app->response->format = Response::FORMAT_JSON;
return Link::grab($url);
}
...
// Link::grab() method
public static function grab($url) {
//clean up url for hostname
$source_url = parse_url($url);
$source_url = $source_url['host'];
$source_url=str_ireplace('www.','',$source_url);
$source_url = trim($source_url,' \\');
// use the NYT API when hostname == nytimes.com
if ($source_url=='nytimes.com') {
...
接下来,让我们使用 API 密钥发出文章搜索请求:
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com
/svc/search/v2/articlesearch.json?fl=headline&fq=web_url:%22'.
$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
$title = $result->response->docs[0]->headline->main;
} else {
// not NYT, use the standard metatag scraper from last episode
...
}
}
return $title;
}
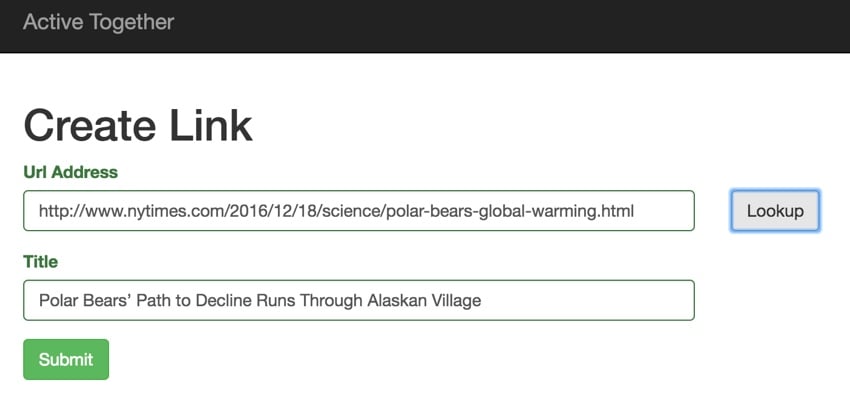
它的工作原理非常简单 - 这是生成的标题(顺便说一句,气候变化正在杀死北极熊,我们应该关心):
如果您想了解 API 请求的更多详细信息,只需向 ?fl 添加其他参数即可=headline 请求例如 关键字 和 lead_paragraph:
Yii::$app->response->format = Response::FORMAT_JSON; $nytKey=Yii::$app->params['nytapi']; $curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'. 'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey; $curl = curl_init(); curl_setopt($curl, CURLOPT_RETURNTRANSFER, true); curl_setopt($curl, CURLOPT_URL,$curl_dest); $result = json_decode(curl_exec($curl)); var_dump($result);
结果如下:

也许我会在接下来的剧集中编写一个 PHP 库来更好地解析 NYT API,但此代码打破了关键字和引导段落:
Yii::$app->response->format = Response::FORMAT_JSON;
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'.
'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
echo $result->response->docs[0]->headline->main.'<br />'.'<br />';
echo $result->response->docs[0]->lead_paragraph.'<br />'.'<br />';
foreach ($result->response->docs[0]->keywords as $k) {
echo $k->value.'<br/>';
}
以下是本文显示的内容:
Polar Bears’ Path to Decline Runs Through Alaskan Village The bears that come here are climate refugees, on land because the sea ice they rely on for hunting seals is receding. Polar Bears Greenhouse Gas Emissions Alaska Global Warming Endangered and Extinct Species International Union for Conservation of Nature National Snow and Ice Data Center Polar Bears International United States Geological Survey
希望这能开始扩展您对如何使用这些 API 的想象力。现在可能实现的事情非常令人兴奋。
结束中
纽约时报 API 非常有用,我很高兴看到他们向开发者社区提供它。通过 GitHub 获得如此快速的 API 支持也令人耳目一新——我只是没想到会这样。请记住,它适用于非商业项目。如果您有一些赚钱的想法,请给他们留言,看看他们是否愿意与您合作。出版商渴望新的收入来源。
J'espère que vous trouverez ces extraits de web scraping utiles et que vous les mettrez en œuvre dans vos projets. Si vous souhaitez regarder l'émission d'aujourd'hui, vous pouvez essayer du web scraping sur mon site Web Active Together .
Veuillez partager vos réflexions et commentaires dans les commentaires. Vous pouvez également me contacter directement sur Twitter @lookahead_io à tout moment. N'oubliez pas de consulter ma page d'instructeur et d'autres séries : Construire votre startup avec PHP et Programmation avec Yii2.
Liens connexes
- Bibliothèque API du New York Times
- Spécification de l'API publique du New York Times sur GitHub
- Comment récupérer les métadonnées des pages Web (Envato Tuts+)
- Comment gratter des pages Web à l'aide de Node.js et jQuery (Envato Tuts+)
- Construisez votre premier Web Scraper dans Ruby (Envato Tuts+)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Récupération de métadonnées à l'aide de l'API du New York Times
Sep 02, 2023 pm 10:13 PM
Récupération de métadonnées à l'aide de l'API du New York Times
Sep 02, 2023 pm 10:13 PM
Introduction La semaine dernière, j'ai écrit une introduction sur le scraping de pages Web pour collecter des métadonnées, et j'ai mentionné qu'il était impossible de scraper le site Web du New York Times. Le paywall du New York Times bloque vos tentatives de collecte de métadonnées de base. Mais il existe un moyen de résoudre ce problème en utilisant l'API du New York Times. Récemment, j'ai commencé à créer un site Web communautaire sur la plateforme Yii, que je publierai dans un prochain tutoriel. Je souhaite pouvoir ajouter facilement des liens pertinents par rapport au contenu du site. Même si les utilisateurs peuvent facilement coller des URL dans des formulaires, fournir des informations sur le titre et la source prend du temps. Ainsi, dans le didacticiel d'aujourd'hui, je vais étendre le code de scraping que j'ai récemment écrit pour tirer parti de l'API du New York Times afin de collecter les titres lors de l'ajout d'un lien vers le New York Times. Rappelez-vous, je suis impliqué
 Accédez aux métadonnées de divers fichiers audio et vidéo à l'aide de Python
Sep 05, 2023 am 11:41 AM
Accédez aux métadonnées de divers fichiers audio et vidéo à l'aide de Python
Sep 05, 2023 am 11:41 AM
Nous pouvons accéder aux métadonnées des fichiers audio en utilisant Mutagen et le module eyeD3 en Python. Pour les métadonnées vidéo, nous pouvons utiliser des films et la bibliothèque OpenCV en Python. Les métadonnées sont des données qui fournissent des informations sur d'autres données, telles que des données audio et vidéo. Les métadonnées des fichiers audio et vidéo incluent le format de fichier, la résolution du fichier, la taille du fichier, la durée, le débit binaire, etc. En accédant à ces métadonnées, nous pouvons gérer les médias plus efficacement et analyser les métadonnées pour obtenir des informations utiles. Dans cet article, nous examinerons certaines des bibliothèques ou modules fournis par Python pour accéder aux métadonnées des fichiers audio et vidéo. Accéder aux métadonnées audio Certaines bibliothèques permettant d'accéder aux métadonnées des fichiers audio utilisent la mutagenèse
 Comment explorer et traiter les données en appelant l'interface API dans un projet PHP ?
Sep 05, 2023 am 08:41 AM
Comment explorer et traiter les données en appelant l'interface API dans un projet PHP ?
Sep 05, 2023 am 08:41 AM
Comment explorer et traiter les données en appelant l'interface API dans un projet PHP ? 1. Introduction Dans les projets PHP, nous devons souvent explorer les données d'autres sites Web et traiter ces données. De nombreux sites Web fournissent des interfaces API et nous pouvons obtenir des données en appelant ces interfaces. Cet article explique comment utiliser PHP pour appeler l'interface API afin d'explorer et de traiter les données. 2. Obtenez l'URL et les paramètres de l'interface API Avant de commencer, nous devons obtenir l'URL de l'interface API cible et les paramètres requis.
 Microsoft lance un nouveau langage de définition de modèle tabulaire pour Power BI
Apr 13, 2023 pm 04:13 PM
Microsoft lance un nouveau langage de définition de modèle tabulaire pour Power BI
Apr 13, 2023 pm 04:13 PM
Microsoft a annoncé la date de fin de support de Power BI Desktop sur Windows 8.1. Récemment, la première plate-forme d’analyse de données du géant de la technologie a également introduit la prise en charge de TypeScript et d’autres nouvelles fonctionnalités. Aujourd'hui, un nouveau langage de définition de modèle tabulaire (TMDL) pour Power BI a été lancé et est désormais disponible en préversion publique. TMDL est requis en raison des fichiers BIM très complexes extraits de l'énorme modèle de données sémantiques créé à l'aide de Power BI. Contenant traditionnellement des métadonnées de modèle en Tabular Model Scripting Language (TMSL), ce fichier est considéré comme difficile à traiter davantage. De plus, avec plusieurs développeurs travaillant sur
 Résumé de l'expérience de développement Vue : conseils pour optimiser le référencement et l'exploration des moteurs de recherche
Nov 22, 2023 am 10:56 AM
Résumé de l'expérience de développement Vue : conseils pour optimiser le référencement et l'exploration des moteurs de recherche
Nov 22, 2023 am 10:56 AM
Résumé de l'expérience de développement Vue : Conseils pour optimiser le référencement et l'exploration des moteurs de recherche Avec le développement rapide d'Internet, le référencement des sites Web (SearchEngineOptimization, optimisation des moteurs de recherche) est devenu de plus en plus important. Pour les sites Web développés avec Vue, l’optimisation du référencement et de l’exploration des moteurs de recherche est cruciale. Cet article résumera une expérience de développement de Vue et partagera quelques conseils pour optimiser le référencement et l'exploration des moteurs de recherche. Utilisation de la technologie de prérendu Vue
 Comment ajouter des métadonnées à un DataFrame ou une série à l'aide de Pandas en Python ?
Aug 19, 2023 pm 08:33 PM
Comment ajouter des métadonnées à un DataFrame ou une série à l'aide de Pandas en Python ?
Aug 19, 2023 pm 08:33 PM
Une fonctionnalité clé de Pandas est la capacité de gérer des métadonnées qui peuvent fournir des informations supplémentaires sur les données présentes dans un DataFrame ou une série. Pandas est une bibliothèque puissante et largement utilisée en Python pour la manipulation et l'analyse de données. Dans cet article, nous explorerons comment ajouter des métadonnées à un DataFrame ou une série en Python à l'aide de Pandas. Que sont les métadonnées dans Pandas ? Les métadonnées sont des informations sur les données d'un DataFrame ou d'une série. Il peut inclure le type de données sur la colonne, l'unité de mesure ou toute autre information importante et pertinente pour fournir un contexte sur les données fournies. Vous pouvez utiliser Pandas pour
 Comment utiliser la bibliothèque de classes PHP Goutte pour l'exploration Web et l'extraction de données ?
Aug 09, 2023 pm 02:16 PM
Comment utiliser la bibliothèque de classes PHP Goutte pour l'exploration Web et l'extraction de données ?
Aug 09, 2023 pm 02:16 PM
Comment utiliser la bibliothèque de classes PHPGoutte pour l'exploration Web et l'extraction de données ? Présentation : Dans le processus de développement quotidien, nous avons souvent besoin d'obtenir diverses données sur Internet, telles que les classements de films, les prévisions météorologiques, etc. L'exploration du Web est l'une des méthodes courantes pour obtenir ces données. Dans le développement PHP, nous pouvons utiliser la bibliothèque de classes Goutte pour implémenter des fonctions d'exploration Web et d'extraction de données. Cet article explique comment utiliser la bibliothèque de classes PHPGoutte pour explorer des pages Web et extraire des données, ainsi que joindre des exemples de code. Qu'est-ce que la goutte
 Comment utiliser Scrapy pour explorer les livres Douban et leurs notes et commentaires ?
Jun 22, 2023 am 10:21 AM
Comment utiliser Scrapy pour explorer les livres Douban et leurs notes et commentaires ?
Jun 22, 2023 am 10:21 AM
Avec le développement d’Internet, les gens ont de plus en plus recours à Internet pour obtenir des informations. Pour les amateurs de livres, Douban Books est devenu une plateforme indispensable. En outre, Douban Books propose également une multitude d'évaluations et de critiques de livres, permettant aux lecteurs de comprendre un livre de manière plus complète. Cependant, obtenir manuellement ces informations revient à chercher une aiguille dans une botte de foin. À l'heure actuelle, nous pouvons utiliser l'outil Scrapy pour explorer les données. Scrapy est un framework de robot d'exploration open source basé sur Python, qui peut nous aider efficacement
