
 Périphériques technologiques
IA
ACM MM 2023 | DiffBFR : Méthode de restauration de visage avec suppression du bruit proposée conjointement par Meitu et l'Université chinoise des sciences et technologies
Périphériques technologiques
IA
ACM MM 2023 | DiffBFR : Méthode de restauration de visage avec suppression du bruit proposée conjointement par Meitu et l'Université chinoise des sciences et technologies
ACM MM 2023 | DiffBFR : Méthode de restauration de visage avec suppression du bruit proposée conjointement par Meitu et l'Université chinoise des sciences et technologies

L'objectif de Blind Face Restoration (BFR) est de restaurer des images de visage de haute qualité à partir d'images de visage de mauvaise qualité. Il s'agit d'une tâche importante dans le domaine de la vision par ordinateur et du graphisme, et elle est largement utilisée dans divers scénarios tels que la restauration d'images de surveillance, la restauration d'anciennes photos et la super-résolution d'images de visage. Cependant, cette tâche est très difficile car elle n'est pas déterministe. la dégradation endommagera la qualité de l’image et entraînera même la perte d’informations sur l’image, telles que le flou, le bruit, le sous-échantillonnage et les artefacts de compression. Les méthodes BFR précédentes s'appuient généralement sur des réseaux contradictoires génératifs (GAN) pour résoudre ces problèmes en concevant divers a priori spécifiques au visage, notamment des a priori génératifs, des a priori de référence et des a priori géométriques. Bien que ces méthodes aient atteint le niveau de pointe, elles ne peuvent toujours pas atteindre pleinement l'objectif d'obtenir des textures réalistes tout en restaurant les détails.
Dans le processus de restauration d'images, les ensembles de données d'images de visage sont généralement dispersés dans un espace de grande dimension. et distribué Les dimensions des entités présentent une distribution à longue traîne. Différentes de la distribution à longue traîne des tâches de classification d'images, les caractéristiques régionales à longue traîne dans la restauration d'images font référence à des attributs qui ont un faible impact sur l'identité mais ont un grand impact sur les effets visuels, tels que les grains de beauté, les rides, les tons, etc.
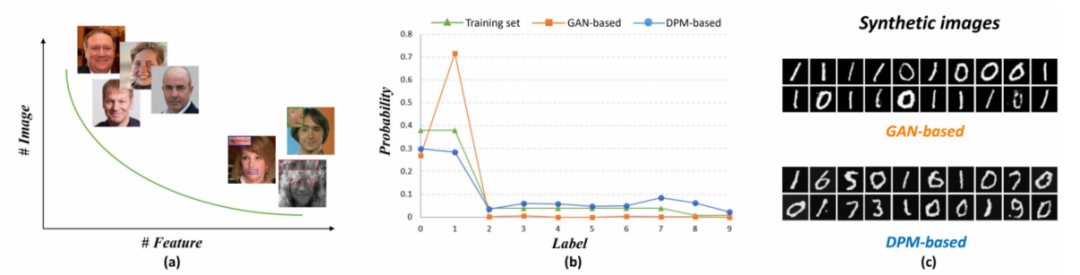
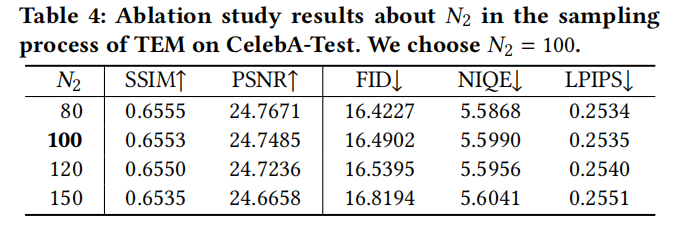
Selon la figure 1, la simplicité montrée est que afin de ne pas changer le sens original, les résultats expérimentaux doivent être réécrits en chinois. Nous pouvons constater que les anciennes méthodes basées sur le GAN ont des problèmes évidents lors du traitement des échantillons de tête et de queue. des distributions à longue traîne en même temps. Un dépassement se produira lors de la réparation de l'image et une perte de détails. La méthode basée sur les modèles probabilistes de diffusion (DPM) peut mieux s'adapter à la distribution à longue traîne et conserver les caractéristiques de la queue tout en s'adaptant à la distribution de données réelles
Meitu Imaging Research Institute (MT Lab) a collaboré avec des chercheurs de l'Université de l'Académie chinoise des sciences pour proposer une nouvelle méthode de réparation d'images de visage aveugle DiffBFR, Cette méthode est basée sur la technologie DPM et permet d'obtenir avec succès la restauration d'images de visages aveugles, la réparation d'images de visage de faible qualité (LQ) en images claires de haute qualité (HQ)
 Le contenu qui doit être réécrit est : Lien papier : https://arxiv.org/ abs/2305.04517
Le contenu qui doit être réécrit est : Lien papier : https://arxiv.org/ abs/2305.04517
Cette étude explore l'adaptabilité de deux modèles génératifs, les réseaux contradictoires génératifs (GAN) et les modèles partiels profonds (DPM), dans le traitement des problèmes à longue traîne. En concevant un module de restauration de visage approprié, des informations détaillées plus précises peuvent être obtenues, réduisant ainsi le lissage excessif du visage qui peut survenir dans les méthodes génératives et améliorant la précision et l'exactitude de la restauration. Ce document de recherche a été accepté par l'ACM MM 2023
Méthode de réparation d'images de visage aveugle basée sur DPM - DiffBFRL'étude a révélé que le modèle de diffusion est meilleur que la méthode GAN pour éviter l'effondrement et l'ajustement du mode d'entraînement pour générer des distributions de queue. Par conséquent, DiffBFR choisit d'utiliser le modèle de probabilité de diffusion pour améliorer l'intégration des informations préalables sur les visages, et l'utilise comme cadre de base pour choisir DPM comme solution. En effet, le modèle de diffusion a la puissante capacité de produire des images de haute qualité dans une plage de distribution arbitraire
Afin de résoudre la distribution à longue traîne des caractéristiques sur l'ensemble de données faciales trouvées dans l'article et le problème de lissage excessif du passé Méthodes basées sur le GAN, cette étude a exploré une conception raisonnable pour mieux s'adapter à la distribution approximative à longue traîne et surmonter le problème de lissage excessif dans le processus de réparation. Grâce à des expériences simples de GAN et DPM avec la même taille de paramètre sur l'ensemble de données MNIST (Figure 1), l'étude a révélé que la méthode DPM peut raisonnablement s'adapter à la distribution à longue traîne, tandis que GAN accorde trop d'attention aux caractéristiques de la tête et ignore les entités de queue. Par conséquent, les entités de queue ne peuvent pas être générées. Par conséquent, DPM est choisi comme solution au BFR
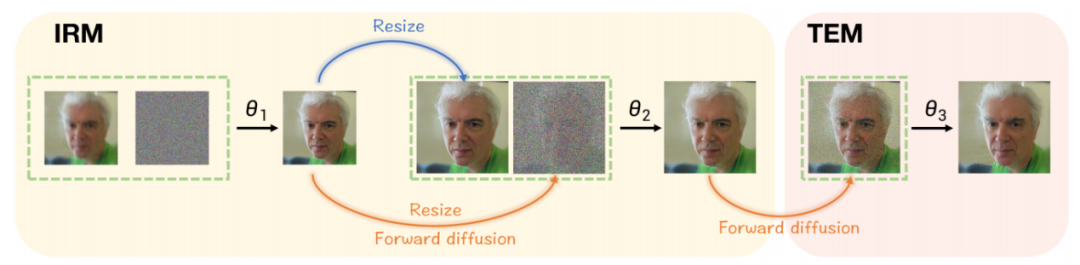
En introduisant deux variables intermédiaires, DiffBFR propose deux modules de réparation spécifiques. La conception adopte une approche en deux étapes, récupérant d'abord les informations d'identité à partir des images LQ, puis améliorant les détails de texture en fonction de la distribution des visages réels. Cette conception se compose de deux parties clés :
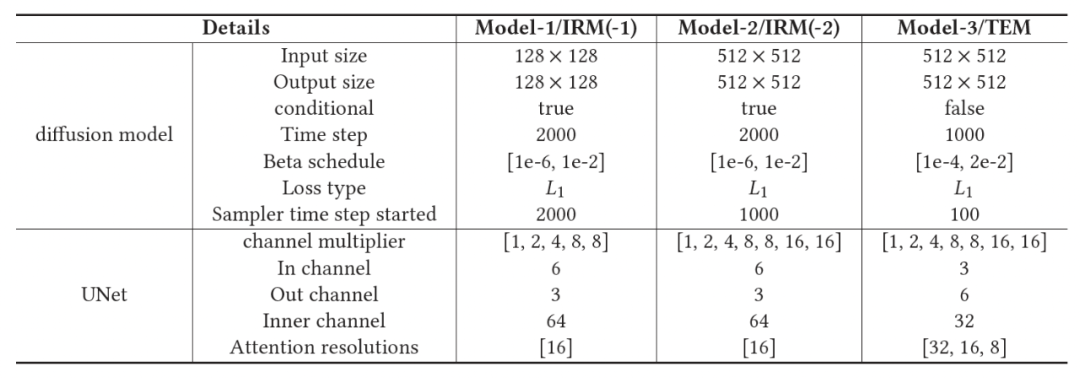
(1) Module de restauration d'identité (IRM) :Le but de ce module est de préserver les détails du visage dans les résultats. Parallèlement, une méthode d'échantillonnage tronquée est proposée, qui remplace la méthode de débruitage utilisant une distribution aléatoire gaussienne pure dans le processus inverse en ajoutant une partie du bruit à l'image de faible qualité. L'article prouve théoriquement que ce changement réduit la limite inférieure des preuves théoriques (ELBO) du DPM, rétablissant ainsi des détails plus originaux. Sur la base de preuves théoriques, deux modèles de diffusion conditionnelle en cascade avec différentes tailles d'entrée sont introduits pour améliorer l'effet d'échantillonnage et réduire la difficulté de formation liée à la génération directe d'images haute résolution. Dans le même temps, il est en outre prouvé que plus la qualité de l'entrée conditionnelle est élevée, plus elle est proche de la distribution réelle des données et plus l'image restaurée est précise. C'est aussi la raison pour laquelle DiffBFR restaure d'abord les images basse résolution
(2) Module d'amélioration de texture (TEM) :La méthode utilisée pour texturer les images consiste à introduire un modèle de diffusion inconditionnel. Ce modèle est totalement indépendant des images de faible qualité, ce qui rend les résultats restaurés plus proches des données d'image réelles. L'article prouve théoriquement qu'un modèle de diffusion inconditionnelle formé sur des images purement de haute qualité contribue à la distribution correcte de l'image de sortie dans l'espace au niveau des pixels. Autrement dit, après avoir utilisé ce modèle, la distribution des images peintes a un FID inférieur à celui d'avant son utilisation et est globalement plus similaire à la distribution d'images de haute qualité. Plus précisément, les informations d'identité sont conservées en tronquant l'échantillonnage au pas de temps et la texture au niveau des pixels est peaufinée. Les étapes d'inférence d'échantillonnage de DiffBFR sont illustrées à la figure 2, et le diagramme schématique du processus d'inférence d'échantillonnage est illustré à la figure. 3. Le contenu qui doit être réécrit est : La figure 3 montre le diagramme schématique du processus d'inférence d'échantillonnage de la méthode DiffBFR
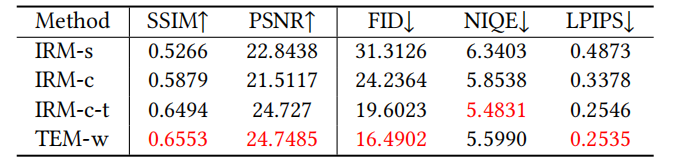
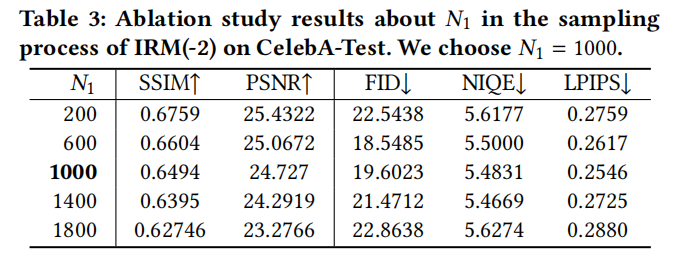
Les effets de visualisation de la méthode BFR basée sur GAN et de la méthode basée sur DPM sont comparés , comme le montre la figure 4 Pour la figure 5, les performances de la méthode SOTA pour le BFR sont comparées La comparaison de visualisation de la méthode BFR est présentée dans la figure 6 Dans le modèle, nous pouvons comparer les performances de l'IRM et du TEM grâce à la visualisation Dans le modèle, les performances de l'IRM et du TEM sont comparées, comme le montre la figure 8 Le contenu qui doit être réécrit est le suivant : Comparez les performances IRM de la figure 9 sous différents paramètres Pour la figure 10, nous devons comparer les performances de différents paramètres Le contenu qui a besoin à réécrire est : La figure 11 montre les paramètres de chaque module de DiffBFR Cet article propose un modèle de restauration d'images faciales par dégradation aveugle DiffBFR basé sur le modèle de diffusion pour résoudre les problèmes des méthodes de formation précédentes basées sur le GAN. crash de mode et problèmes de disparition de longue traîne. En intégrant des connaissances préalables dans le modèle de diffusion, des images restaurées claires et de haute qualité peuvent être générées à partir d’images de visages aléatoires gravement dégradées. Plus précisément, cette étude propose deux modules, IRM et TEM, qui servent respectivement à restaurer la réalité et à restaurer les détails. Grâce à la dérivation théorique et à la démonstration d'images expérimentales, la supériorité du modèle est démontrée et des comparaisons qualitatives et quantitatives sont effectuées avec les méthodes de pointe existantes Ce qui doit être réécrit est : Équipe de recherche Cet article a été proposé conjointement par des chercheurs du Meitu Imaging Research Institute (MT Lab) et de l'Université de l'Académie chinoise des sciences. Le Meitu Imaging Research Institute (MT Lab) a été créé en 2010. Il s'agit d'une équipe de Meitu qui se concentre sur la recherche d'algorithmes, le développement technique et la mise en œuvre de produits dans les domaines de la vision par ordinateur, de l'apprentissage profond, de la réalité augmentée et d'autres domaines. Depuis sa création, l'équipe s'est engagée à explorer la recherche dans le domaine de la vision par ordinateur et a commencé à déployer l'apprentissage profond en 2013 pour fournir un support technique aux produits logiciels et matériels de Meitu. Dans le même temps, ils fournissent également des services SaaS ciblés pour plusieurs domaines verticaux du secteur de l'imagerie et promeuvent le développement écologique des produits d'intelligence artificielle de Meitu grâce à une technologie d'imagerie de pointe. Ils ont participé à des compétitions internationales de premier plan telles que CVPR, ICCV et ECCV, ont remporté plus de dix championnats et finalistes et ont publié plus de 48 articles de conférences universitaires internationales de premier plan. Le Meitu Imaging Research Institute (MT Lab) s'engage depuis longtemps dans la recherche et le développement dans le domaine de l'imagerie, a accumulé de riches réserves techniques et possède une riche expérience de mise en œuvre de technologies dans les domaines de l'image, de la vidéo, du design et du numérique
 Afin de ne pas changer le sens original, les résultats expérimentaux doivent être réécrits en chinois
Afin de ne pas changer le sens original, les résultats expérimentaux doivent être réécrits en chinois



 Le résumé consiste à combiner les informations ou le processus de reformulation des idées de manière concise et claire. Cela ne change pas le sens original mais présente la même idée en utilisant un vocabulaire et une structure de phrase différents. Le but d’un résumé est de fournir une présentation plus claire et concise afin que le lecteur puisse plus facilement comprendre et digérer les informations véhiculées. Les résumés sont utiles dans diverses situations, que ce soit dans des articles universitaires, des rapports commerciaux ou des communications quotidiennes, pour transmettre des idées et des conclusions importantes. En bref, le résumé est un outil de communication important qui peut nous aider à transmettre et à comprendre les informations plus efficacement
Le résumé consiste à combiner les informations ou le processus de reformulation des idées de manière concise et claire. Cela ne change pas le sens original mais présente la même idée en utilisant un vocabulaire et une structure de phrase différents. Le but d’un résumé est de fournir une présentation plus claire et concise afin que le lecteur puisse plus facilement comprendre et digérer les informations véhiculées. Les résumés sont utiles dans diverses situations, que ce soit dans des articles universitaires, des rapports commerciaux ou des communications quotidiennes, pour transmettre des idées et des conclusions importantes. En bref, le résumé est un outil de communication important qui peut nous aider à transmettre et à comprendre les informations plus efficacement
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Le système de conduite intelligent Qiankun ADS3.0 de Huawei sera lancé en août et sera lancé pour la première fois sur Xiangjie S9
Jul 30, 2024 pm 02:17 PM
Le système de conduite intelligent Qiankun ADS3.0 de Huawei sera lancé en août et sera lancé pour la première fois sur Xiangjie S9
Jul 30, 2024 pm 02:17 PM
Le 29 juillet, lors de la cérémonie de lancement de la 400 000e nouvelle voiture d'AITO Wenjie, Yu Chengdong, directeur général de Huawei, président de Terminal BG et président de la BU Smart Car Solutions, a assisté et prononcé un discours et a annoncé que les modèles de la série Wenjie seraient sera lancé cette année En août, la version Huawei Qiankun ADS 3.0 a été lancée et il est prévu de pousser successivement les mises à niveau d'août à septembre. Le Xiangjie S9, qui sortira le 6 août, lancera le système de conduite intelligent ADS3.0 de Huawei. Avec l'aide du lidar, la version Huawei Qiankun ADS3.0 améliorera considérablement ses capacités de conduite intelligente, disposera de capacités intégrées de bout en bout et adoptera une nouvelle architecture de bout en bout de GOD (identification générale des obstacles)/PDP (prédictive prise de décision et contrôle), fournissant la fonction NCA de conduite intelligente d'une place de stationnement à l'autre et mettant à niveau CAS3.0
 Une autre tablette Snapdragon 8Gen3 ~ OPPOPad3 exposée
Jul 29, 2024 pm 04:26 PM
Une autre tablette Snapdragon 8Gen3 ~ OPPOPad3 exposée
Jul 29, 2024 pm 04:26 PM
Le mois dernier, OnePlus a sorti la première tablette équipée de Snapdragon 8 Gen3 : OnePlus Tablet Pro. Selon les dernières nouvelles, la version « bébé de remplacement » de cette tablette, OPPOPad3, sera également disponible prochainement. L'image ci-dessus montre OPPOPad2. Selon Digital Chat Station, l'apparence et la configuration de l'OPPOPad3 sont exactement les mêmes que celles de la OnePlus Tablet Pro. Couleur : or, bleu (différent de la version verte et gris foncé de OnePlus : 8). /12/16 Go+512 Go Date de sortie : Nouveaux produits pour la même période au quatrième trimestre de cette année (octobre-décembre) : Rechercher.
 Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Dans la fabrication moderne, une détection précise des défauts est non seulement la clé pour garantir la qualité des produits, mais également la clé de l’amélioration de l’efficacité de la production. Cependant, les ensembles de données de détection de défauts existants manquent souvent de précision et de richesse sémantique requises pour les applications pratiques, ce qui rend les modèles incapables d'identifier des catégories ou des emplacements de défauts spécifiques. Afin de résoudre ce problème, une équipe de recherche de premier plan composée de l'Université des sciences et technologies de Hong Kong, Guangzhou et de Simou Technology a développé de manière innovante l'ensemble de données « DefectSpectrum », qui fournit une annotation à grande échelle détaillée et sémantiquement riche des défauts industriels. Comme le montre le tableau 1, par rapport à d'autres ensembles de données industrielles, l'ensemble de données « DefectSpectrum » fournit le plus grand nombre d'annotations de défauts (5 438 échantillons de défauts) et la classification de défauts la plus détaillée (125 catégories de défauts).
 Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
La communauté ouverte LLM est une époque où une centaine de fleurs fleurissent et s'affrontent. Vous pouvez voir Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 et bien d'autres. excellents interprètes. Cependant, par rapport aux grands modèles propriétaires représentés par le GPT-4-Turbo, les modèles ouverts présentent encore des lacunes importantes dans de nombreux domaines. En plus des modèles généraux, certains modèles ouverts spécialisés dans des domaines clés ont été développés, tels que DeepSeek-Coder-V2 pour la programmation et les mathématiques, et InternVL pour les tâches de langage visuel.
 Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Pour l’IA, l’Olympiade mathématique n’est plus un problème. Jeudi, l'intelligence artificielle de Google DeepMind a réalisé un exploit : utiliser l'IA pour résoudre la vraie question de l'Olympiade mathématique internationale de cette année, l'OMI, et elle n'était qu'à un pas de remporter la médaille d'or. Le concours de l'OMI qui vient de se terminer la semaine dernière comportait six questions portant sur l'algèbre, la combinatoire, la géométrie et la théorie des nombres. Le système d'IA hybride proposé par Google a répondu correctement à quatre questions et a marqué 28 points, atteignant le niveau de la médaille d'argent. Plus tôt ce mois-ci, le professeur titulaire de l'UCLA, Terence Tao, venait de promouvoir l'Olympiade mathématique de l'IA (AIMO Progress Award) avec un prix d'un million de dollars. De manière inattendue, le niveau de résolution de problèmes d'IA s'était amélioré à ce niveau avant juillet. Posez les questions simultanément sur l'OMI. La chose la plus difficile à faire correctement est l'OMI, qui a la plus longue histoire, la plus grande échelle et la plus négative.
 Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Editeur | KX À ce jour, les détails structurels et la précision déterminés par cristallographie, des métaux simples aux grandes protéines membranaires, sont inégalés par aucune autre méthode. Cependant, le plus grand défi, appelé problème de phase, reste la récupération des informations de phase à partir d'amplitudes déterminées expérimentalement. Des chercheurs de l'Université de Copenhague au Danemark ont développé une méthode d'apprentissage en profondeur appelée PhAI pour résoudre les problèmes de phase cristalline. Un réseau neuronal d'apprentissage en profondeur formé à l'aide de millions de structures cristallines artificielles et de leurs données de diffraction synthétique correspondantes peut générer des cartes précises de densité électronique. L'étude montre que cette méthode de solution structurelle ab initio basée sur l'apprentissage profond peut résoudre le problème de phase avec une résolution de seulement 2 Angströms, ce qui équivaut à seulement 10 à 20 % des données disponibles à la résolution atomique, alors que le calcul ab initio traditionnel
 Le point de vue de la nature : les tests de l'intelligence artificielle en médecine sont dans le chaos. Que faut-il faire ?
Aug 22, 2024 pm 04:37 PM
Le point de vue de la nature : les tests de l'intelligence artificielle en médecine sont dans le chaos. Que faut-il faire ?
Aug 22, 2024 pm 04:37 PM
Editeur | ScienceAI Sur la base de données cliniques limitées, des centaines d'algorithmes médicaux ont été approuvés. Les scientifiques se demandent qui devrait tester les outils et comment le faire au mieux. Devin Singh a vu un patient pédiatrique aux urgences subir un arrêt cardiaque alors qu'il attendait un traitement pendant une longue période, ce qui l'a incité à explorer l'application de l'IA pour réduire les temps d'attente. À l’aide des données de triage des salles d’urgence de SickKids, Singh et ses collègues ont construit une série de modèles d’IA pour fournir des diagnostics potentiels et recommander des tests. Une étude a montré que ces modèles peuvent accélérer les visites chez le médecin de 22,3 %, accélérant ainsi le traitement des résultats de près de 3 heures par patient nécessitant un examen médical. Cependant, le succès des algorithmes d’intelligence artificielle dans la recherche ne fait que le vérifier.
 Bai Jian annonce la nouvelle du nouveau téléphone NIO et explique pourquoi NIO insiste pour fabriquer des téléphones mobiles
Jul 25, 2024 pm 01:14 PM
Bai Jian annonce la nouvelle du nouveau téléphone NIO et explique pourquoi NIO insiste pour fabriquer des téléphones mobiles
Jul 25, 2024 pm 01:14 PM
Le nouveau NIO NIO Phone (NIOPhone 2) sortira le 27 juillet. À l'approche de la date de sortie, le 24 juillet, Bai Jian, vice-président de NIO Technology (Anhui) Co., Ltd., a répondu à deux des questions les plus fréquemment posées par les internautes sur NIO Phone. NIOPhone « Pourquoi NIO insiste-t-il pour fabriquer des téléphones mobiles ? » Des questions similaires apparaissent dans presque toutes les zones de commentaires liées au nouveau NIOPhone. Bai Jian a répondu que Weilai avait commencé très tôt à réfléchir et à planifier la fabrication de téléphones portables. Ce n'était pas un caprice, encore moins comme certains l'ont dit, car certaines marques de téléphones portables ont commencé à fabriquer des voitures. Bai Jian a annoncé la nouvelle du nouveau NIOPhone « voiture intelligente et téléphone portable »
